MySql系列整体栏目
| 内容 | 链接地址 |
|---|---|
| 【一】深入理解mysql索引本质 | https://blog.csdn.net/zhenghuishengq/article/details/121027025 |
| 【二】深入理解mysql索引优化以及explain关键字 | https://blog.csdn.net/zhenghuishengq/article/details/128273593 |
| 【三】深入理解mysql的索引分类,覆盖索引(失效),回表,MRR | https://blog.csdn.net/zhenghuishengq/article/details/124552080 |
| 【四】深入理解mysql事务本质 | https://blog.csdn.net/zhenghuishengq/article/details/127753772 |
| 【五】深入理解mvcc机制 | https://blog.csdn.net/zhenghuishengq/article/details/127889365 |
| 【六】深入理解mysql执行的底层机制 | https://blog.csdn.net/zhenghuishengq/article/details/128100377 |
| 【七】深入理解mysql集群的高可用机制 | https://blog.csdn.net/zhenghuishengq/article/details/126239652 |
深入理解mysql的索引分类,覆盖索引,回表,MRR
- 一,索引
- 1,聚簇索引和非聚簇索引
- 2,辅助索引和二级索引
- 3,回表
- 4, MRR(重点)
- 5,联合索引
- 6,哈希索引
- 7,密集索引和稀疏索引
- 8,覆盖索引
- 9,覆盖索引失效问题
一,索引
在阅读本文之前,最好先了解上面栏目中的一,二,六这三篇,先理解索引的本质,explain关键字的使用,以及六里面的 bufferpool 的缓存机制以及数据的加载机制。
1,聚簇索引和非聚簇索引
在innodb 中,mysql主要是通过索引这种数据结构增加查询效率,索引主要由聚簇索引和非聚簇索引所构成。聚簇索引主要是通过显式id的来存储,如果表中有id,并且给这个id加一个键,那么这个id就作为主键(聚簇)索引;如果没有定义一个id,那么就会去表中找是否存在 唯一键,如果有唯一键那么这个唯一索引作为主键索引,如果也没有唯一索键,那么就会通过一个隐式的id来存储。
如下,在一张 user 用户表中没有id,然后给表中的 name 字段一个唯一键
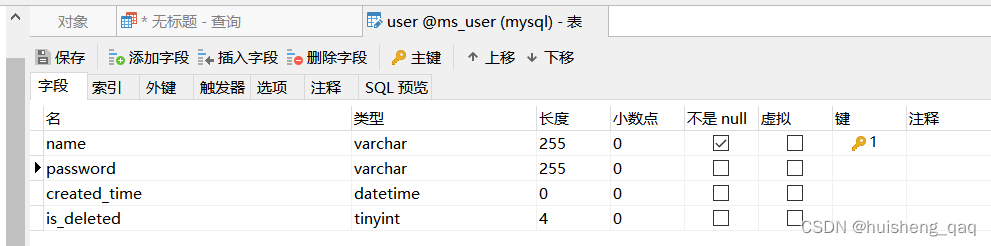
通过查看表中的索引可知,如下图,是将name这个字段的这一列作为一个主键索引的。
show keys from user;

如果表中没有id字段,也没有字段上面有唯一键,那么innodb存储引擎会使用一个隐式的id作为主键索引的。
2,辅助索引和二级索引
除了聚簇索引,那么就是一些非聚簇索引,如一些辅助索引和二级索引。这里就涉及到一个 回表问题 ,比如说给库存表中的 sku_code商品码加一个索引,那么就需要先从这个 sku_code 的这列所对应的 b+ 树中先找到他的值,于此同时需要返回他的主键值,通过他的主键值再去主键(聚簇)索引对应的那棵b+树中找到对应的信息,因为表中所有的信息都存储在聚簇索引的叶子节点上,这个就称为回表,需要通过两次的IO进行获取数据。
3,回表
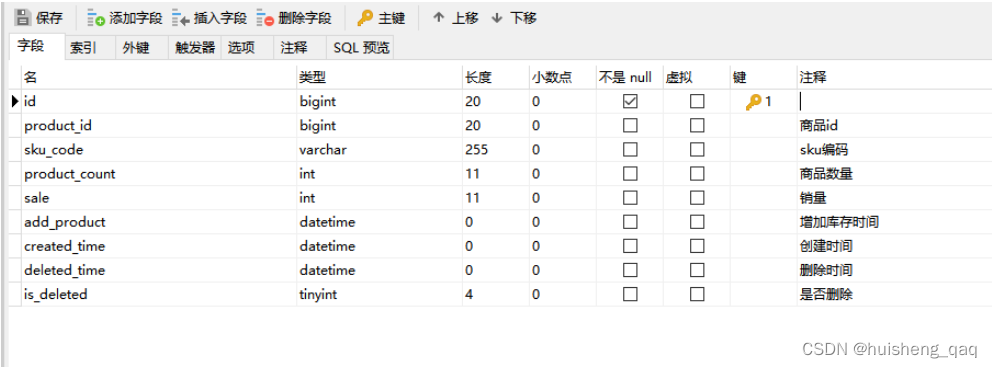
接下来详细的描述一下到底什么是回表。如上图,一张库存表,如果在 sku_code 这里建一个普通的索引,
create index idx_sku_code on stock (sku_code) ;
如下图,那么如果在通过这个查 sku_code 这个字段获取创建时间时,需要先走这个普通索引对应的B+树,即sku_code列对应的B+树,将值查找出
select cteated_time from stock where sku_code = 'zhs01';
由于B+树的值都存储在叶子结点上面,因此在这里也会找到叶子结点为 sku_code = ‘zhs01’ 的这个值。此时叶子结点中存了key值和value值,key值对应的就是这个sku_code的值zhs01,value对应的就是这个主键索引的值。后面需要通过这个主键值回表到主键索引对应的B+树中,再次定位到该值的叶子节点。(绿色部分为二级索引的B+树,橙色部分为主键索引的B+树)
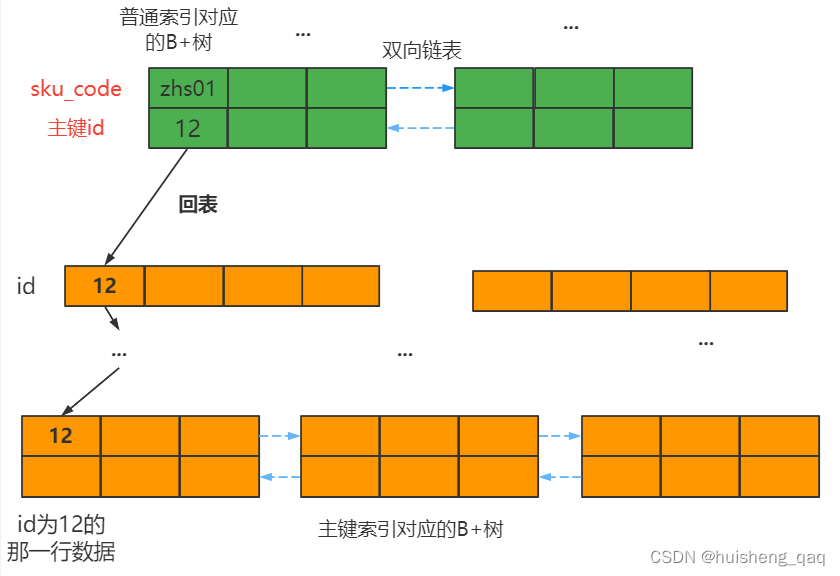
获取到这个id之后,再通过 主键所对应的B+树 ,在叶子节点上获取key为id = 12的结点,该节点对应的value值就表中那一行所对应的的值。
总而言之就是:普通索引就是为了更好的更快的找到主键索引。
4, MRR(重点)
由于索引是以页为单位的,一页的大小为16k。在回表的时候,需要返回主键索引的id,就会产生一个问题,就是在读取数据的时候,可能会产生一个 随机IO 。由于在读取磁盘的数据时,假设磁盘的扇区只有一个,每次可以读取磁盘的512个字节,那么读取一页数据就需要读取 16 × 1024 ÷ 512 = 32 次。
而索引存储在磁盘上,每个回表携带一个id,假设数据都是第一次读取,在不考虑bufferpool的情况下,那么就需要从磁盘中读取一页数据,那么每一个回表的数据就要与磁盘交互32多次,而如果存在多个回表的的主键id不在一个目录页上面,那么就需要 32乘以回表的个数,这样就大大的降低了查询的效率。
这就解释了为什么有时候发现一条sql语句在该字段加了索引,where后面也有这个字段,但是通过explain执行发现他不走索引,而是走的全表扫描,这主要就是因为再回表时产生的这个 随机IO 的原因
MRR:Disk-Sweep Multi-Range Read (MRR,多范围读取),其原理就是先读取一部分二级索引记录,将它们的主键值排好序之后再统一执行回表操作,这样就可以减少磁盘的交互次数,并且磁盘内一页的数据大小是按顺序排好的,那么在通过这个有序的页查数据时,就可以将这种 随机IO 转换成 顺序IO。
举个例子
假设某段时间内有10个回表的操作,并且数据的页目录有10页,此时由于10个回表操作那么会产生10个主键id值,那么在正常的情况下,假设值都分布在在页目录的随机位置,因此需要的回表次数是 10 次,如果此时数据都不在bufferpool的情况下,需要进行磁盘的IO次数就是 10×32 = 320 次io。
但是在引入MRR之后,会先将这10个回表的id先进行一个排序,然后排好序之后进行一次回表操作。这样就可以通过排好序的最大值和最小值获取到这些分别分布在哪些页上面,因为页与页之间也是有一个双向链表,其值都是排好顺序的,如果发现这两个值分别在同一个页目录上面,或者相邻的两个页面,那么这个十个值就都会在同一个页目录上或者相邻的两个页目录上。如果最大值和最小值刚好就是在一个页目录上,那么只需要回表这一次就可以了,其十个值都可以在这一个页目录上面找到,数据不在bufferpool的情况下,其需要的磁盘IO次数为 32 次;如果最大和最小值分别是在相邻的两个页目录上面,那么个也是只需要加载两次页目录就可以将这10个值找到,即只需要回表两次,两个页目录的数据不在bufferpool的情况下,其需要的磁盘IO次数为 2×32 = 64,其后面的照推之,这样就可以发现这个顺序IO的磁盘读写次数是小于上面的随机IO了。 这主要是为了减少回表的次数,如果bufferpool中不存在这些或者某些数据,那么同时也减少了随机IO,减少磁盘的交互数,但是并不能完全减少,如果这些id分别存在不同的页目录下面,那么这样加MRR和不加MRR的效率就一样了。
顺序IO大约是随机IO的40-100倍,这样就大大的提升了查询的效率。
总结就是一句话:如果数据已经加载在bufferpool中,那么MRR主要是为了减少这个回表的次数,如果数据在bufferpool中不存在,那么不仅仅减少了回表的次数,同时也减少了随机IO,减少磁盘的交互数
5,联合索引
就是由多个字段组合起来的一个联合索引。根据B+的底层,在一个联合索引中,必须前面的字段一样,才能对后面的字段进行比较,如果使用范围查询,那么范围后面的字段值就会失效。即须遵守最左前缀原则。这个比较简单就不多说了。
6,哈希索引
在innodb中,不仅存在B+树索引,同时也存在一个 自适应的hash索引 。在innodb这个存储引擎中,存在一个对热点数据的一个监控,如果某个表或者某一列对应的索引使用的特别频繁,那么就会将这个值加入到这个缓存里面,后面查询就可以直接利用这个hash算法直接定位到需要查询的值。其缓存的底层结构和hashMap的底层一样,由数组 + 链表组成,如果发生哈希碰撞,那么就由数组转成链表。
但是由于hash索引不能支持范围查询,因此mysql的索引最终是选择的B+树作为索引,而这个自适应索引是内部的一条命令,不提供外部使用,当然可以开启和禁用它。
7,密集索引和稀疏索引
密集索引:如果索引里面即存储了key,又存储了value,那么这个索引就是密集索引。如主键索引
稀疏索引:如果索引里面只存储key,不存储value,那么这个索引就是稀疏索引。所有的二级索引都是稀疏索引,myIsam中的索引都是稀疏索引
8,覆盖索引
什么是覆盖索引,在此之前,需要先理解上面的回表问题,就是查完二级索引之后,又要去主键索引中查询一级索引,这样就需要回表。那么这里就可以利用到覆盖索引了。覆盖索引一般针对的是辅助索引,整个查询结果只通过辅助索引就能拿到结果,不需要通过辅助索引树找到主键,再通过主键去主键索引树里获取其它字段值
再回到上面的这个sql,已知在 sku_code 这个字段加了索引,目前需要查找这个创建时间时间,这样执行下去的话,就需要先在 sku_code 这一列的B+树上面先找到这一列的id,然后通过回表携带这个id去主键索引对应的B+树里面去查询这一条数据,那么这样就会产生一个回表的时间。
select cteated_time from stock where sku_code = 'zhs01';
但是,如果将之前的单值索引变成联合索引,如下
create index idx_sku_code_created_time on stock (sku_code,created_time) ;
那么这个联合索引对应的B+树就是下面这个样子,那么就是在找到sku_code的值的时候,那么这个created_time的这个值也跟随着找出了。这个就是覆盖索引。这样就不需要携带这个id去回表,通过回表的方式从主键(聚簇)索引中获取这个值了。

再通过explain查看这条sql语句,如下图,发现这个type为ref,这条语句中走了非唯一索引,通过key的值,得知走的索引就是刚刚创建的二级索引,而最终通过这个Extra这个关键字,里面的值为Using index ,可以得知是走了覆盖索引的。这个具体的值的详解可以查看我之前的写的一篇博客https://blog.csdn.net/zhenghuishengq/article/details/124552080
explain select sku_code,created_time from stock where sku_code = 'zhs01';

9,覆盖索引失效问题
由上图可以覆盖索引是为了解决回表的次数带来的查询效率问题,但是在实际开发中也可能出现覆盖索引失效的问题,如下面这句,覆盖索引肯定是会失效的,因为表中还有其他的值要查询出其他字段,其他字段不能通过这个覆盖索引查出,那么肯定会通过回表的方式,在聚簇索引中将那一列数据查出,这样也增加了回表的次数
select * from stock where sku_code = 'zhs01';
还有下面的多一个字段问题,也是会出现这个回表问题的,那么也会出现索引覆盖失效
select sku_code,created_time,sale from stock where sku_code = 'zhs01';
这里可以发现这里是走索引的,但是由于这个Extra的这个值为NUll,不是Using index,可知这个覆盖索引是失效的,那必然是通过回表来查询所有的值的。并且这联合索引的字段需要遵循最左前缀原则,否则就不仅仅是覆盖索引失效了,而是整个联合索引直接失效。

所以为了解决这种覆盖索引失效的问题,就是尽量少用select * ,尽量用覆盖索引中已有的字段,不要用覆盖索引中不存在的字段。
![[附源码]Python计算机毕业设计SSM基于的民宿租赁系统(程序+LW)](https://img-blog.csdnimg.cn/28c3f30715b94c0c8ca2dc7ea1ce9fdb.png)



](https://img-blog.csdnimg.cn/img_convert/32e4e5eb993fe0514c9785a254e84e88.jpeg)