目录
Spark Standalone集群环境
修改配置文件
【workers】
【spark-env.sh】
【配置spark应用日志】
【log4j.properties】
分发到其他机器
启动spark Standalone
启动方式1:集群启动和停止
启动方式2:单独启动和停止
连接集群
【spark-shell 连接】
编辑
【pyspark 连接】
Spark Standalone集群环境
Standalone模式是Spark自带的一种集群模式,不同于前面本地模式启动多个进程来模拟集群的环境,Standalone模式是真实地在多个机器之间搭建Spark集群的环境,完全可以利用该模式搭建多机器集群,用于实际的大数据处理。
| 节点 | 主节点(master) | 从节点(worker) | 历史服务(history server) |
| node1 | 是 | 是 | 是 |
| node2 | 否 | 是 | 否 |
| node3 | 否 | 是 | 否 |
修改配置文件
说明: 直接对local模型下的spark进行更改为standalone模式
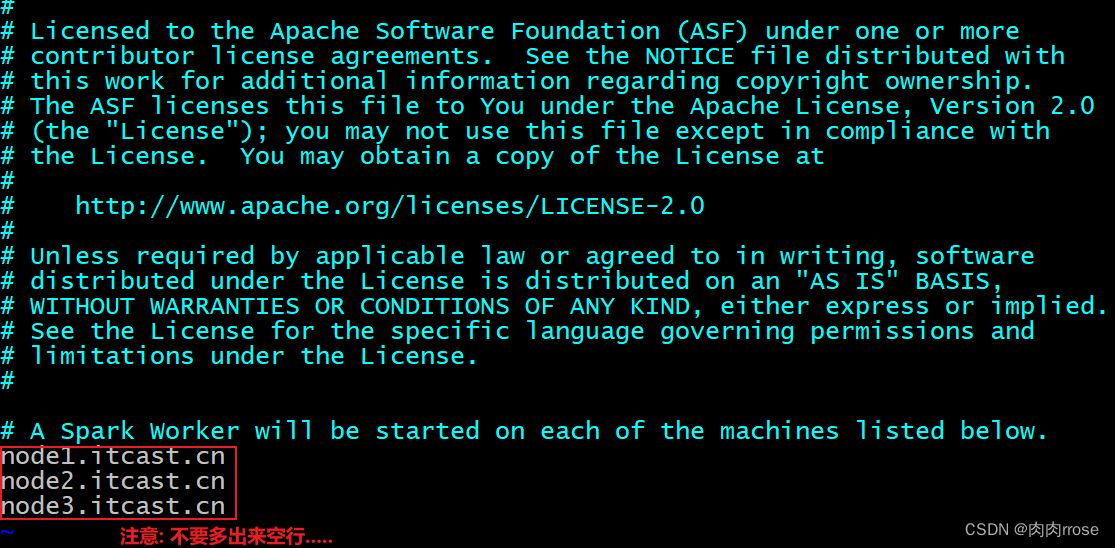
【workers】
| cd /export/server/spark/conf/ cp workers.template workers vim workers 添加以下内容: node1.itcast.cn node2.itcast.cn node3.itcast.cn |
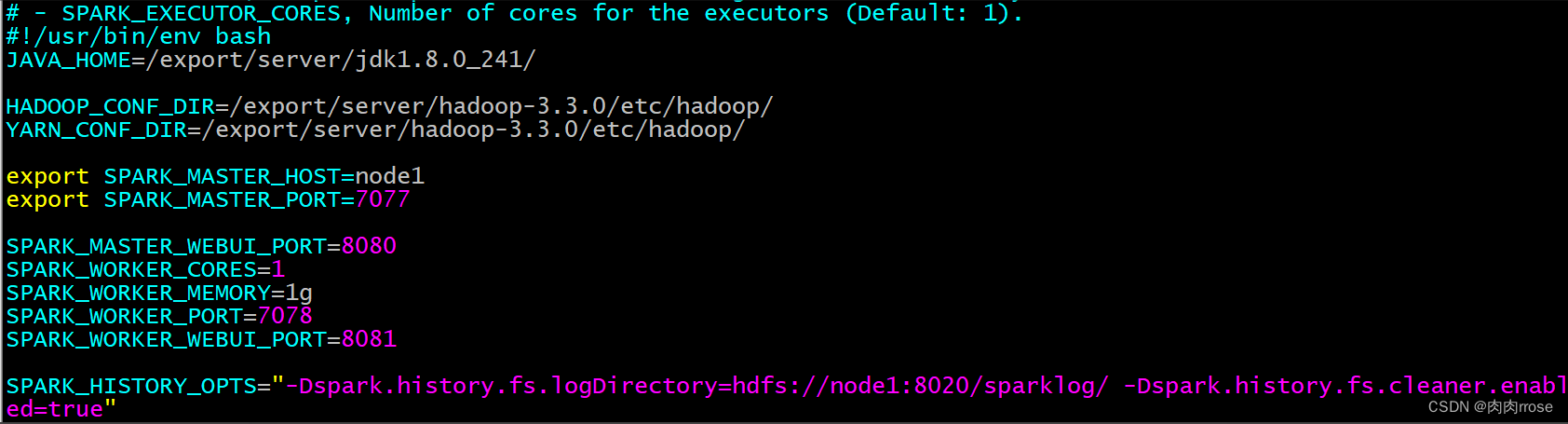
【spark-env.sh】
| cd /export/server/spark/conf cp spark-env.sh.template spark-env.sh vim spark-env.sh 增加如下内容: JAVA_HOME=/export/server/jdk1.8.0_241/ HADOOP_CONF_DIR=/export/server/hadoop-3.3.0/etc/hadoop/ YARN_CONF_DIR=/export/server/hadoop-3.3.0/etc/hadoop/ export SPARK_MASTER_HOST=node1 export SPARK_MASTER_PORT=7077 SPARK_MASTER_WEBUI_PORT=8080 SPARK_WORKER_CORES=1 SPARK_WORKER_MEMORY=1g SPARK_WORKER_PORT=7078 SPARK_WORKER_WEBUI_PORT=8081 SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://node1:8020/sparklog/ -Dspark.history.fs.cleaner.enabled=true" |
注意:
Jdk,hadoop, yarn的路径, 需要配置为自己的路径(可能与此位置不一致)
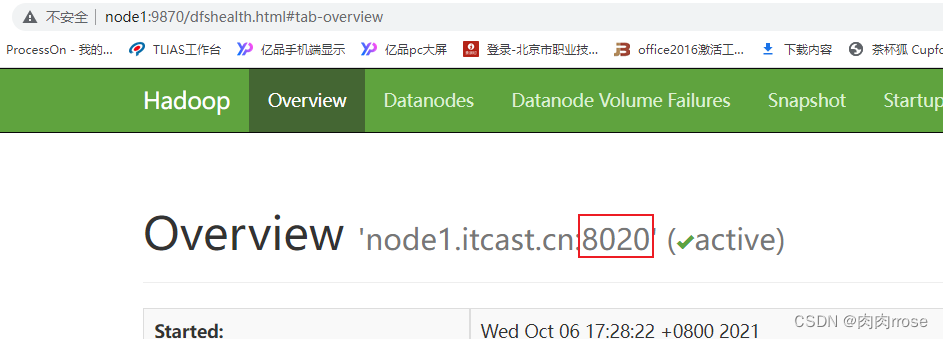
History配置中, 需要指定hdfs的地址, 其中端口号为8020或者9820, 大家需要参考hdfs上对应namenode的通信端口号
【配置spark应用日志】
| 第一步: 在HDFS上创建应用运行事件日志目录: hdfs dfs -mkdir -p /sparklog/ 第二步: 配置spark-defaults.conf cd /export/server/spark/conf cp spark-defaults.conf.template spark-defaults.conf vim spark-defaults.conf 添加以下内容: spark.eventLog.enabled true spark.eventLog.dir hdfs://node1:8020/sparklog/ spark.eventLog.compress true |
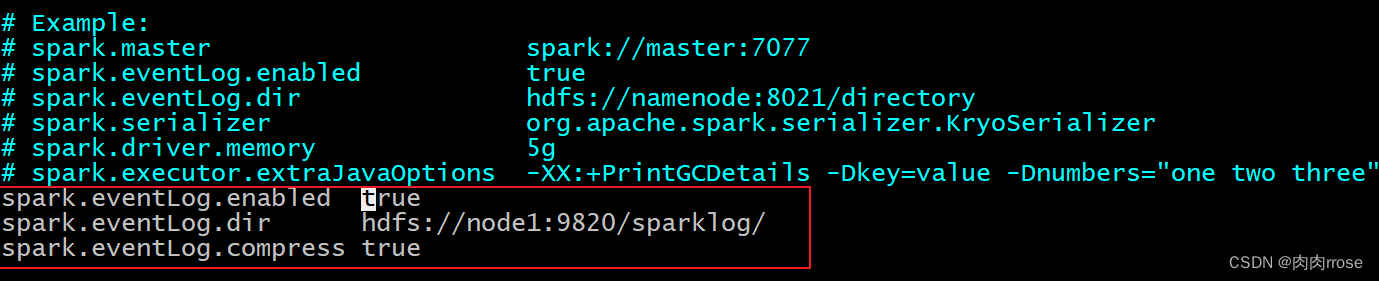
其中HDFS的地址, 8020 还是9820 需要查看HDFS的界面显示
【log4j.properties】
| cd /export/server/spark/conf cp log4j.properties.template log4j.properties vim log4j.properties #改变日志级别
|

分发到其他机器
将配置好的将 Spark 安装包分发给集群中其它机器,命令如下:
| cd /export/server/ scp -r spark-3.1.2-bin-hadoop3.2/ node2:$PWD scp -r spark-3.1.2-bin-hadoop3.2/ node3:$PWD ##分别在node2, 和node3中创建软连接 ln -s /export/server/spark-3.1.2-bin-hadoop3.2/ /export/server/spark |
启动spark Standalone
启动方式1:集群启动和停止
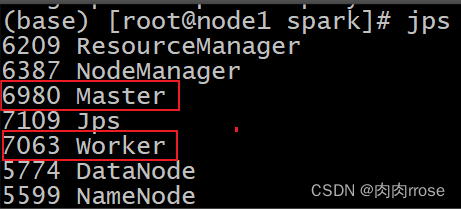
在主节点上启动spark集群
| cd /export/server/spark sbin/start-all.sh
sbin/start-history-server.sh
|
在主节点上停止spark集群
| /export/server/spark/sbin/stop-all.sh |
启动方式2:单独启动和停止
在 master 安装节点上启动和停止 master:
| start-master.sh stop-master.sh |
在 Master 所在节点上启动和停止worker(work指的是slaves 配置文件中的主机名)
| start-slaves.sh stop-slaves.sh |
- WEB UI页面
| http://node1:8080/ |
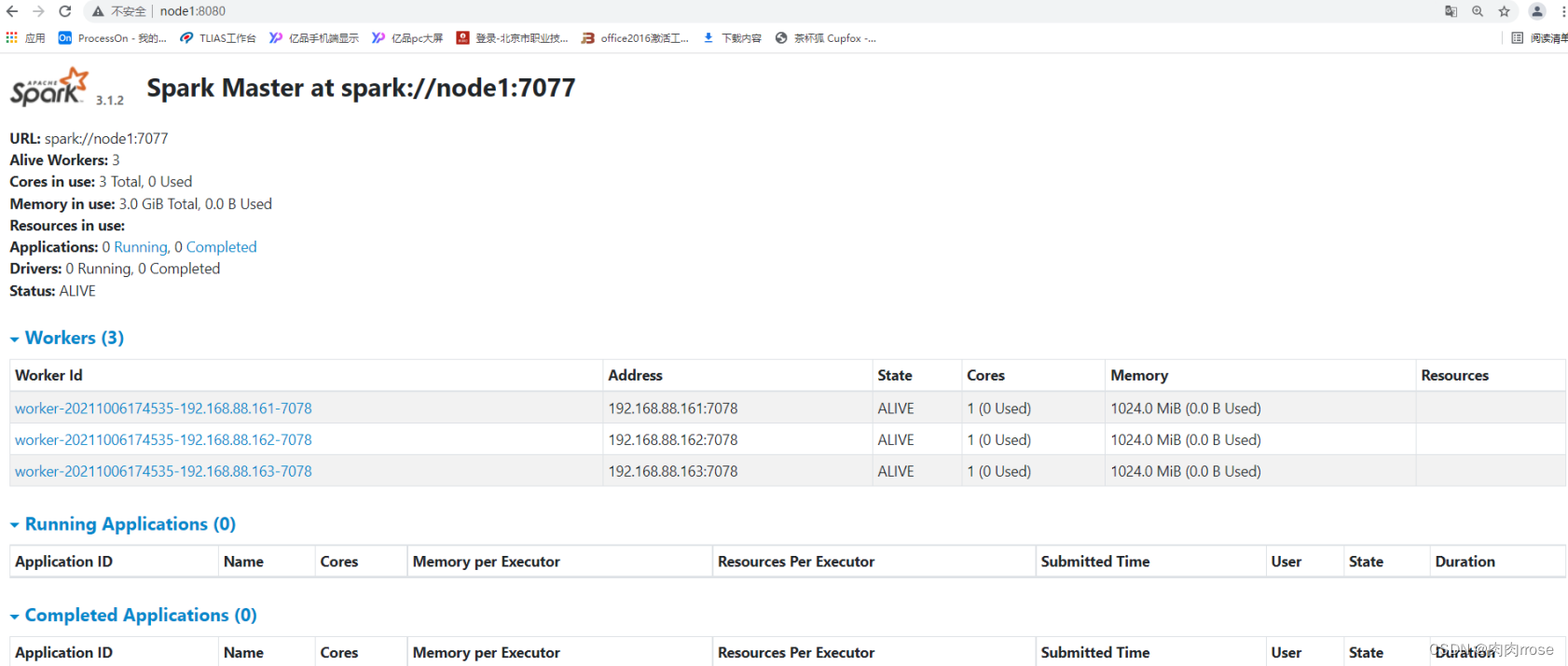
可以看出,配置了3个Worker进程实例,每个Worker实例为1核1GB内存,总共是3核 3GB 内存。目前显示的Worker资源都是空闲的,当向Spark集群提交应用之后,Spark就会分配相应的资源给程序使用,可以在该页面看到资源的使用情况。
- 历史服务器HistoryServer:
| /export/server/spark/sbin/start-history-server.sh |
WEB UI页面地址:http://node1:18080
连接集群
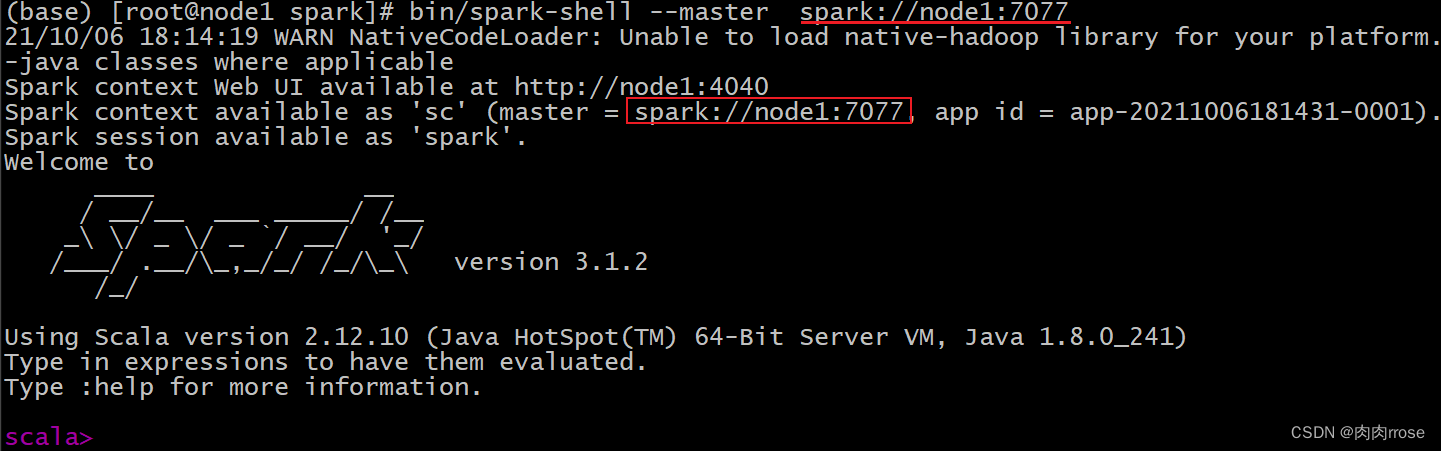
【spark-shell 连接】
| cd /export/server/spark bin/spark-shell --master spark://node1:7077 |
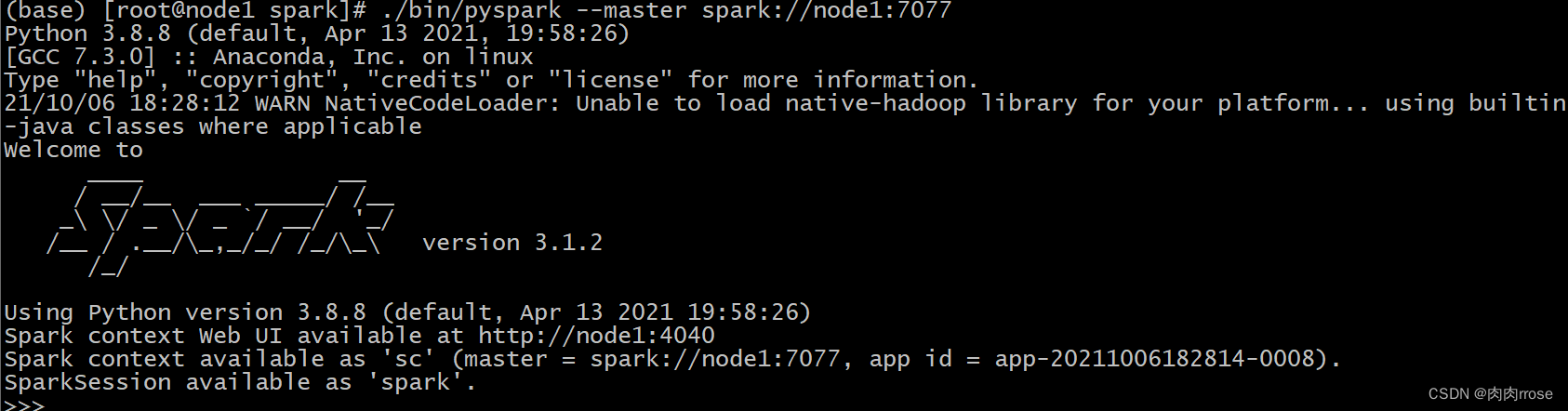
【pyspark 连接】
| cd /export/server/spark ./bin/pyspark --master spark://node1:7077 |