EVD-PCA
PCA推导:PCA主成分分析法浅理解

具体数值如10304×10304是我机器学习课程实验的数据集参数,这里关注数字量级即可。
code
% EVD-PCA数据降维
% input: D×N output:K×N
function [Z, K] = EVD_PCA(X, K, weight)
fprintf('Running EVD-PCA dimensionality reduction...\n');
if exist('eigenData.mat', 'file') == 0
[~, N] = size(X);
%% Step 1: Center the data
% mu = mean(X);
% X = X - mu; !err
mu = mean(X, 2);
X = X - mu * ones(1, N);
%% Step 2: Compute the covariance matrix
S = X * X' / N; % D×D
% size(S)
%% Step 3: Do an eigendecomposition of S
[V, D] = eig(S); % !time-consuming
% S*V=V*D,其中D为特征值的对角矩阵,V对应列为特征向量
% (D×D)*(D×E)=(D×E)*(E×E),其中E为特征值个数,D为原数据维度(区分对角矩阵D)
%% Step 4: Take first K leading eigenvector
eigenVal = diag(D); % 特征值序列
[~, sortedIndex] = sort(eigenVal, 'descend');
eigenVec = V(:, sortedIndex); % 对应特征向量构筑矩阵
eigenVal = eigenVal(sortedIndex);
save('eigenData.mat', 'eigenVec', 'eigenVal');
else
load('eigenData.mat');
end
%% 检查是否传入有效K,否则基于weight动态定义K
% 前K个特征值之和占特征值之和的比例达到weight
if K < 0
sumVal = sum(eigenVal);
for i = 1 : length(eigenVal)
newRate = sum(eigenVal(1 : i), 1) / sumVal;
if newRate >= weight
K = i; break;
end
end
fprintf('Dynamically define K to %d\n', K);
end
U = eigenVec(:, 1 : K); % (D×K)
%% Step 5: Calc the final K dim. projection of data
Z = U' * X; % (K×N)=(K×D)*(D×N)
fprintf('EVD-PCA done\n');
end
SVD-PCA

以上是我发现的一个小技巧,并通过测试发现,SVD-PCA方法准确率和标准EVD-PCA方法几乎相同,而效率大大提升!
code
% SVD-PCA数据降维
% input: D×N output:K×N
function [Z] = SVD_PCA(X, K)
fprintf('Running SVD-PCA dimensionality reduction...\n');
[D, N] = size(X); % D:feature dimension
%% Step 1: Center the data
mu = mean(X, 2);
X = X - mu * ones(1, N);
%% Step 2: Compute the A^{T}A
Mat = X' * X;
%% Step 3: Do an eigendecomposition of A^{T}A
% 利用左奇异值矩阵U进行特征维度压缩,即减少X的行数
[V, S] = eig(Mat); % N×N
%% Step 4: Take first K leading eigenvector of A^{T}A then build
%% Left single matrix U
S = diag(S);
[S, si] = sort(S, 'descend');
eigenVec = zeros(N, K);
eigenVal = zeros(1, K);
for i = 1 : K
eigenVec(:, i) = V(:, si(i));
eigenVal(i) = S(i);
end
rU = zeros(D, K); % reconstructed matrix U
for i = 1 : K
rU(:, i) = X * eigenVec(:, i) / sqrt(eigenVal(i)); % 奇异值≈sqrt(特征值)
end
% save('svdData', 'eigenVec', 'eigenVal', 'rU');
%% Step 5: Calc the final K dim. projection of data
Z = rU' * X; % (K×N)=(K×D)*(D×N)
fprintf('SVD-PCA done\n');
end
Comparison
Accuracy
| K值 | SVD-PCA(×100%) | EVD-PCA(×100%) |
|---|---|---|
| 1 | 0.160000000000000 | 0.175000000000000 |
| 2 | 0.385000000000000 | 0.368750000000000 |
| 4 | 0.740000000000000 | 0.756250000000000 |
| 8 | 0.930000000000000 | 0.918750000000000 |
| 16 | 0.960000000000000 | 0.937500000000000 |
| 32 | 0.970000000000000 | 0.975000000000000 |
| 48 | 0.965000000000000 | 0.975000000000000 |
| 64 | 0.955000000000000 | 0.981250000000000 |
| 80 | 0.950000000000000 | 0.975000000000000 |
| 96 | 0.955000000000000 | 0.968750000000000 |
Time consumption
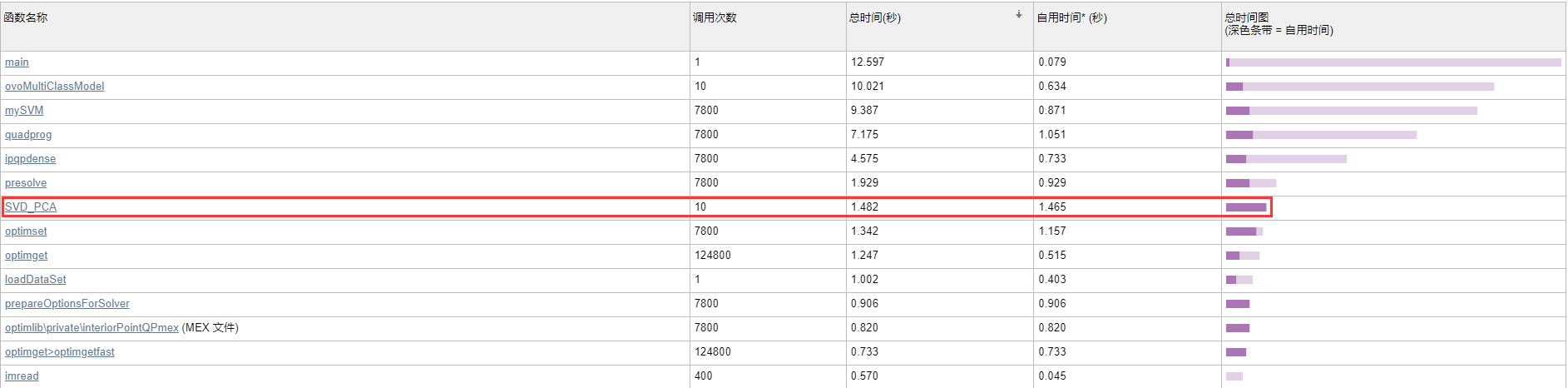
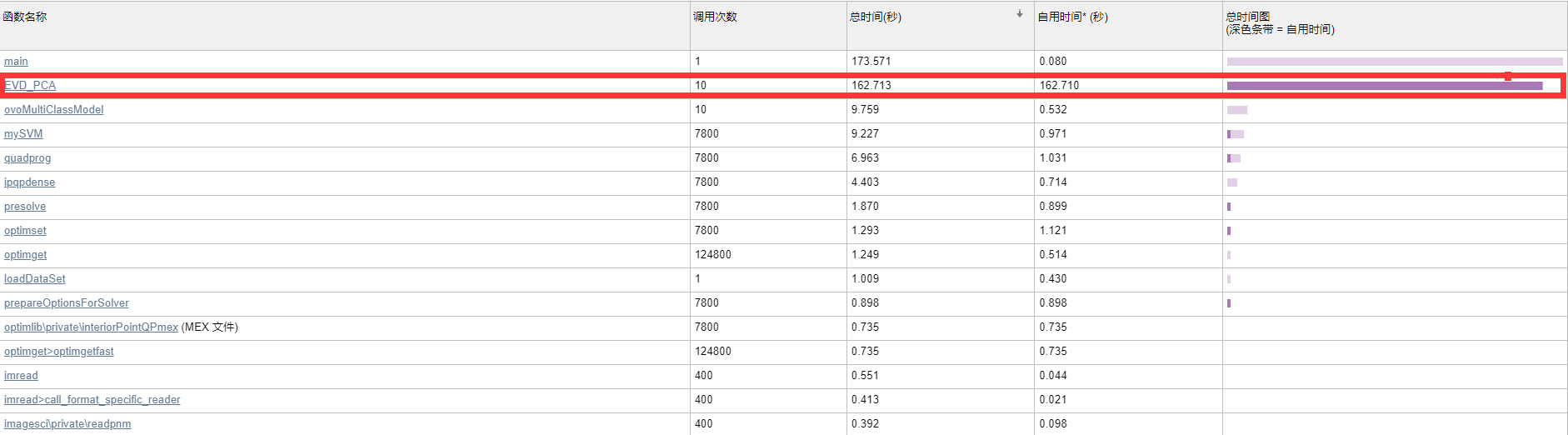
可以看到两种方法10次不同K值PCA部分的总用时分别为1.482s和162.713s,而且实际上后者利用了文件存储的结果。效率的差异源于对两个不同矩阵(10304×10304 vs. 400×400)做evd.
Conclusion
由于测试集大小在120-200之间,以上准确率可以认为几乎相同。因此我们可以得出结论:SVD-PCA在该人脸数据集表现更优。
或者说在
D
≫
N
D\gg N
D≫N的情况下通过SVD做协方差矩阵
S
S
S的特征值分解是可行的。







![[附源码]JAVA毕业设计-心理健康管理-(系统+LW)](https://img-blog.csdnimg.cn/7444b85f87c84c4f90a1716b06b6193b.png)