图文深度解析Linux内存碎片整理实现机制以及源码。
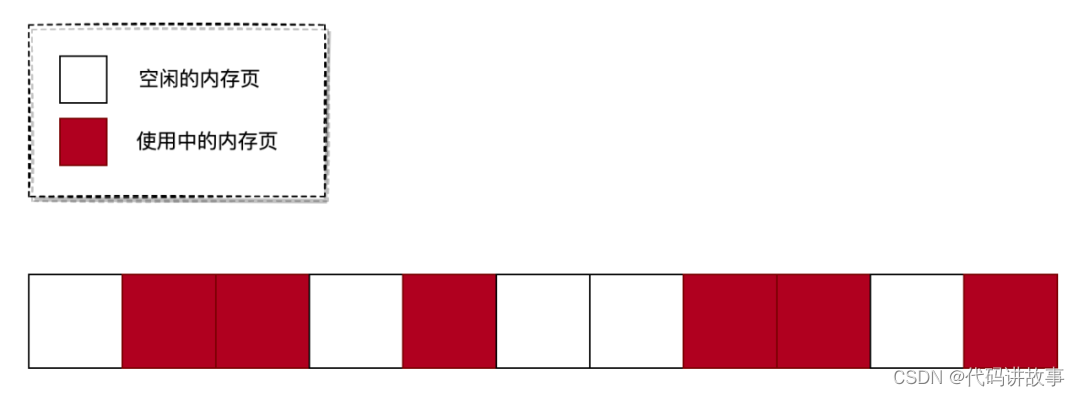
物理内存是以页为单位进行管理的,每个内存页大小默认是4K(大页除外)。申请物理内存时,一般都是按顺序分配的,但释放内存的行为是随机的。随着系统运行时间变长后,将会出现以下情况:
在多道程序当中,如果要让我们的程序运行,必须先创建进程。而创建进程的第一步便是要将程序和对应的数据装入内存。把用户的源程序变成可执行的程序要经历 编译 - 链接 - 装入 三个过程。
第一种:单一连续分配方式
适用于单用户、单任务的操作系统。没什么好讲的。
第二种:固定分区分配
此种分配方式把内存空间分为固定大小的区域,每个分区允许一个作业被装入。分区大小可以不相同。通常会建立一张分区使用表来记录每个分区的起始地址、分区大小、状态。没有足够大的分区则拒绝分配内存。此种分配方式是最早的多道程序的存储管理方式。
缺点:限制了进程的数目,内存空间利用率比较低。
第三种:动态分区分配
此种方式涉及到相应的数据结构(分区表、分区链),分区分配算法和回收操作。
分区分配算法有:首次适应算法 ( 以链表结构为例,下同。从链首开始顺序查找,找到一个符合条件的分区即可进行相应的分配,没有符合条件的则分配失败 ) 、循环首次适应算法(从上一次符合条件的分区进行循环查找 ) 、最佳适应算法(首先需要把空闲分区链表按容量排序 [ 排序的目的是为了加速查找,否则就要遍历整个链表 ] ,然后从链首进行顺序查找 ) 、最坏适应算法( 选择最大的空闲分区,然后进



![[附源码]JAVA毕业设计-心理健康管理-(系统+LW)](https://img-blog.csdnimg.cn/7444b85f87c84c4f90a1716b06b6193b.png)