👏作者简介:大家好,我是爱敲代码的小王,CSDN博客博主,Python小白
📕系列专栏:python入门到实战、Python爬虫开发、Python办公自动化、Python数据分析、Python前后端开发
📧如果文章知识点有错误的地方,请指正!和大家一起学习,一起进步👀
🔥如果感觉博主的文章还不错的话,请👍三连支持👍一下博主哦
🍂博主正在努力完成2023计划中:以梦为马,扬帆起航,2023追梦人
🔥🔥🔥 python入门到实战专栏:从入门到实战
🔥🔥🔥 Python爬虫开发专栏:从入门到实战
🔥🔥🔥 Python办公自动化专栏:从入门到实战
🔥🔥🔥 Python数据分析专栏:从入门到实战
🔥🔥🔥 Python前后端开发专栏:从入门到实战
目录
列表元素访问和计数
切片操作
列表的遍历
复制列表所有的元素到新列表对象
多维列表
元组tuple
列表元素访问和计数

通过索引直接访问元素
我们可以通过索引直接访问元素。索引的区间在 [0, 列表长度-1] 这个范 围。超过这个范围则会抛出异常。
a = [10,20,30,40,50,20,30,20,30]
print(a[2]) #结果:30
print(a[10]) #报错:IndexError: list index out of range
index()获得指定元素在列表中首次出现的索引
index() 可以获取指定元素首次出现的索引位置。语法是: index(value,[start, [end]]) 。其中, start 和 end 指定了搜索的范围。
>>> a = [10,20,30,40,50,20,30,20,30]
>>> a.index(20) #结果:1
>>> a.index(20,3) #结果:5 从索引位置3开始往后搜索的第一个20
>>> a.index(30,5,7) #结果:6 从索引位置5到7这个区间,第一次出现30元素的位置count()获得指定元素在列表中出现的次数
count()可以返回指定元素在列表中出现的次数。
>>> a = [10,20,30,40,50,20,30,20,30]
>>> a.count(20)
3len()返回列表长度
len()返回列表长度,即列表中包含元素的个数。
>>> a = [10,20,30]
>>> len(a)
3成员资格判断
判断列表中是否存在指定的元素,我们可以使用 count() 方法,返回0 则表示不存在,返回大于0则表示存在。但是,一般我们会使用更加简洁的 in 关键字来判断,直接返回 True 或 False
>>> a = [10,20,30,40,50,20,30,20,30]
>>> 20 in a
True
>>> 100 not in a
True
>>> 30 not in a
False实时效果反馈
1. 判断 a = [10,20,30,40,50,20,30,20,30] 是否包含元素 20 ,如下代码错误的是:
A 20 in a
B 0<=a.index(20)<=len(a)-1
C a.count(20)==0
D a[20] is not None
切片操作
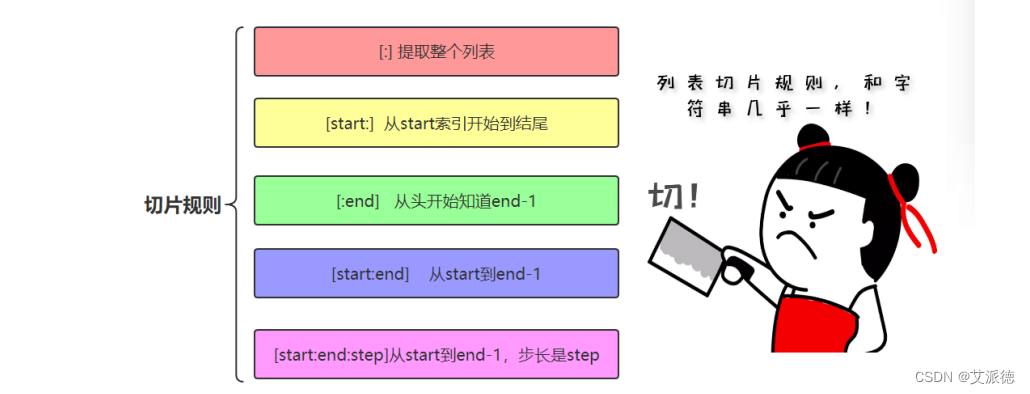
类似字符串的切片操作,对于列表的切片操作和字符串类似。
切片是Python序列及其重要的操作,适用于列表、元组、字符串等等。 切片slice操作可以让我们快速提取子列表或修改。标准格式为:
[起始偏移量start:终止偏移量end[:步长step]]
典型操作(三个量为正数的情况)如下:
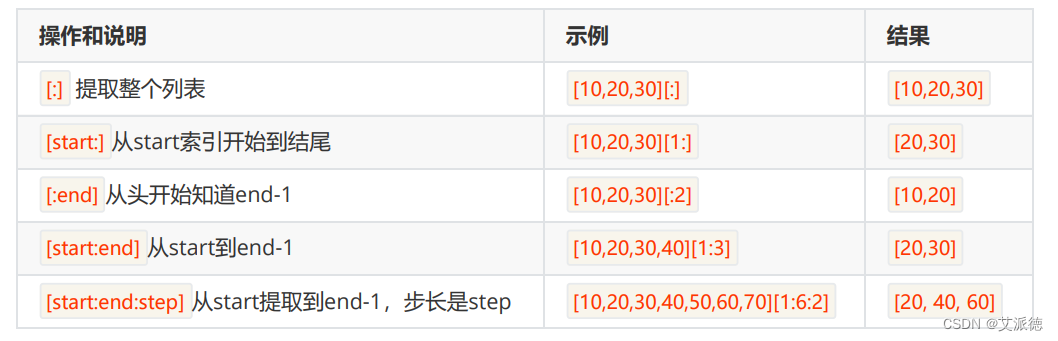
其他操作(三个量为负数)的情况:

切片操作时,起始偏移量和终止偏移量不在 [0,字符串长度-1] 这个范 围,也不会报错。起始偏移量 小于0 则会当做 0 ,终止偏移量 大于 “长度-1” 会被当成 ”长度-1” 。例如: [10,20,30,40][1:30] 结果: [20, 30, 40] 我们发现正常输出了结果,没有报错。
实时效果反馈
1. 如下代码,执行结果的是:
[10,20,30,40][1:3]
A [20, 30]
B [10, 20, 30]
C [20, 30, 40]
D [40]
2. 如下代码,执行结果的是:
[10,20,30,40,50,60,70][::-1]A [70]
B [50]
C [10]
D [70, 60, 50, 40, 30, 20, 10]
列表的遍历
a = [10,20,30,40]
for obj in a: #obj是临时变量名称,随意起
print(obj)复制列表所有的元素到新列表对象
如下代码实现列表元素的复制了吗?
list1 = [30,40,50] list2 = list1只是将list2也指向了列表对象,也就是说list2和list2持有地址值是相同的,列表对象本身的元素并没有复制。
我们可以通过如下简单方式,实现列表元素内容的复制:
list1 = [30,40,50]
list2 = [] + list1 #生成了新列表对象注:我们后面也会学习copy模块,使用浅复制或深复制实现我 们的复制操作。
列表排序
修改原列表,不建新列表的排序
>>> a = [20,10,30,40]
>>> id(a)
46017416
>>> a.sort() #默认是升序排列
>>> a
[10, 20, 30, 40]
>>> a = [10,20,30,40]
>>> a.sort(reverse=True) #降序排列
>>> a
[40, 30, 20, 10]
>>> import random
>>> random.shuffle(a) #打乱顺序
>>> a
[20, 40, 30, 10]建新列表的排序
我们也可以通过内置函数sorted()进行排序,这个方法返回新列表, 不对原列表做修改。
>>> a = [20,10,30,40]
>>> id(a)
46016008
>>> b = sorted(a) #默认升序
>>> b
[10, 20, 30, 40]
>>> id(b)
45907848
>>> c = sorted(a,reverse=True) #降序
>>> c
[40, 30, 20, 10]
通过上面操作,我们可以看出,生成的列表对象b和c都是完全新的列表对象。
reversed()返回迭代器
内置函数reversed()也支持进行逆序排列,与列表对象reverse()方 法不同的是,内置函数reversed()不对原列表做任何修改,只是返回一个逆序排列的迭代器对象。
>>> a = [20,10,30,40]
>>> c = reversed(a)
>>> c
<list_reverseiterator object at 0x0000000002BCCEB8>
>>> list(c)
[40, 30, 10, 20]
>>> list(c)
[]我们打印输出c发现提示是:list_reverseiterator。也就是一个迭代对象。同时,我们使用list(c)进行输出,发现只能使用一次。第一次输出了元素,第二次为空。那是因为迭代对象在第一次时已经遍历结束了,第二次不能再使用。
⚠️关于迭代对象的使用,后续章节会进行详细讲解。
列表相关的其他内置函数汇总
max和min
用于返回列表中最大和最小值。
>>> a = [3,10,20,15,9]
>>> max(a)
20
>>> min(a)
3sum
对数值型列表的所有元素进行求和操作,对非数值型列表运算则会报错。
>>> a = [3,10,20,15,9]
>>> sum(a)
57实时效果反馈
1. 如下代码,说法正确的是:
list1 = [30,40,50]
list2 = [] + list1 A list2是一个新的列表对象
B list2和list1是同一个对象
C list2不是一个新对象
D list2是一个空的列表对象
多维列表

二维列表
一维列表可以帮助我们存储一维、线性的数据。
二维列表可以帮助我们存储二维、表格的数据。例如下表的数据:
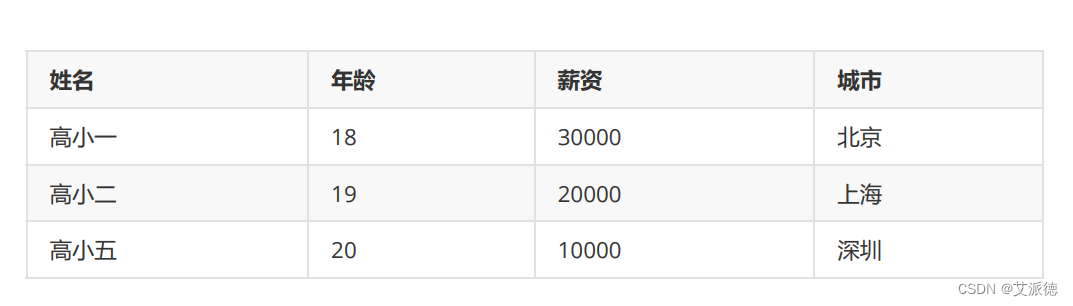
源码:
a = [
["高小一",18,30000,"北京"],
["高小二",19,20000,"上海"],
["高小五",20,10000,"深圳"],
]
内存结构图:

>>> print(a[1][0],a[1][1],a[1][2])
高小二 19 20000嵌套循环打印二维列表所有的数据(由于没有学循环,照着敲一遍即可):
a = [
["高小一",18,30000,"北京"],
["高小二",19,20000,"上海"],
["高小一",20,10000,"深圳"],
]
for m in range(3):
for n in range(4):
print(a[m][n],end="\t")
print() #打印完一行,换行运行结果:
高小一 18 30000 北京
高小二 19 20000 上海
高小一 20 10000 深圳
实时效果反馈
1. 如下列表,想访问到"深圳",正确的是:
a = [
["高小一",18,30000,"北京"],
["高小二",19,20000,"上海"],
["高小一",20,10000,"深圳"]
]A a[1][3]
B a[2][3]
C a[3][3]
D a[3][2]
元组tuple
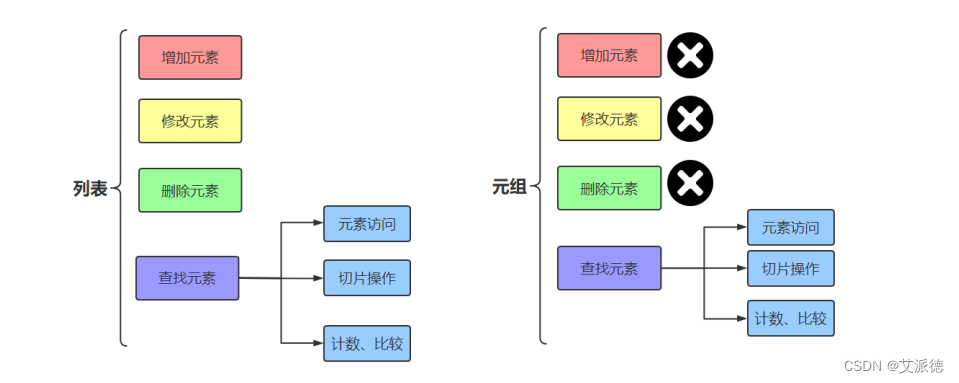
列表属于可变序列,可以任意修改列表中的元素。
元组属于不可变序列,不能修改元组中的元素。 因此,元组没有增加元素、修改元素、删除元素相关的方法。
因此,我们只需学元组的创建和删除,元素的访问和计数即可。元组支持如下操作:
1 索引访问
2 切片操作
3 连接操作
4 成员关系操作
5 比较运算操作
6 计数:元组长度len()、最大值max()、最小值min()、求和sum()等
元组的创建
a = (10,20,30) 或者 a = 10,20,30如果元组只有一个元素,则必须后面加逗号。这是因为解释 器会把(1)解释为整数1,(1,)解释为元组。
a = 10>>> a = (1) >>> type(a) <class 'int'> >>> a = (1,) #或者 a = 1, >>> type(a) <class 'tuple'>
2、 通过tuple()创建元组
tuple(可迭代的对象)
a = tuple() #创建一个空元组对象
b = tuple("abc")
c = tuple(range(3))
d = tuple([2,3,4])总结:
1 tuple()可以接收列表、字符串、其他序列类型、迭代器等生成元组。
2 list()可以接收元组、字符串、其他序列类型、迭代器等生成列表。
实时效果反馈
1. 关于元组,如下说法错误的是:
A 元组属于不可变序列,不能修改元组中的元素。
B 元组没有增加元素、修改元素、删除元素相关的方法
C a = (1) 定义的是一个元组
D a = (1,) 定义的是一个元组
元组的元素访问和计数
1、元组的元素不能修改
>>> a = (20,10,30,9,8)
>>> a[3]=33
Traceback (most recent call last):
File "<pyshell#313>", line 1, in
<module>
a[3]=33
TypeError: 'tuple' object does not support
item assignment2、元组的元素访问、index()、count()、切片等操作,和列表一 样。
>>> a = (20,10,30,9,8)
>>> a[1]
10
>>> a[1:3]
(10, 30)
>>> a[:4]
(20, 10, 30, 9)
3、 列表关于排序的方法list.sorted()是修改原列表对象,元组没有该方法。如果要对元组排序,只能使用内置函数 sorted(tupleObj),并生成新的列表对象。
a = (20,10,30,9,8)
b = sorted(a) #b是新对象,内容是:[8, 9,10, 20, 30]
zip
zip(列表1,列表2,...)将多个列表对应位置的元素组合成为元组, 并返回这个zip对象。
如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同
a = [10,20,30]
b = [40,50,60]
c = [70,80,90,100]
d = zip(a,b,c)
print(d) #zip object
e = list(d) #列表:[(10, 40, 70), (20, 50, 80), (30, 60, 90)]
print(e)
实时效果反馈
1. 如下关于元组 a = (20,10,30,9,8) 的代码,会报错的是:
A print(a[1:3])
B b = sorted(a)
C a[3]=33
D b = list(a)









![[oeasy]python0073_进制转化_eval_evaluate_衡量_oct_octal_八进制](https://img-blog.csdnimg.cn/img_convert/e29c1ebfd55d9cdc17b4a3c857cb0e1f.png)