目录
一.单链表的定义
二.单链表的分类
2.1.不带头结点的单链表
2.2.带头结点的单链表
三.单链表的功能实现
3.1.单链表的定义
3.2.单链表的打印
3.3.单链表的结点的创建
3.4.单链表的尾插
3.5.单链表的头插
3.6.单链表的尾删
3.7.单链表的头删
3.8.单链表的查找
3.9.单链表的在pos位置之前插入数据
3.10.单链表的删除pos位置之前的结点
3.11.单链表的在pos位置之后插入
3.12.单链表的删除pos位置之后的结点
3.13.单链表的销毁
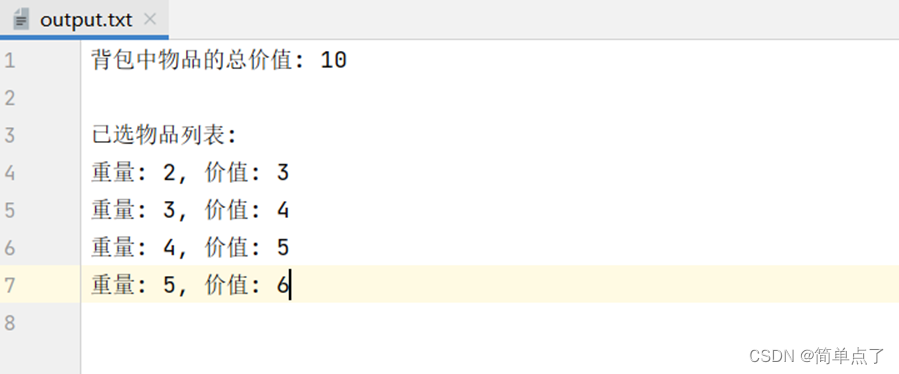
3.14.完整程序
SList.h
SList.c
test.c
四.链表面试题
题一:移除链表元素
题二:反转链表
题三:链表的中间结点
题四:链表中倒数第k个结点
题五:合并两个有序链表
题六:链表分割
题七:链表的回文结构
题八:相交链表
题九:环形链表①
题十:环形链表②
题十一:复制带随机指针的链表
一.单链表的定义

链表是一种物理存储结构上非连续,非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。

采用这种存储方式要找到某一个位序的结点,只能从第一个结点开始利用指针的信息依次往后寻找直到找到我们想要的那个结点。因此单链表这种实现方式不支持随机存取。

二.单链表的分类
用代码定义一个单链表:
typedef int SLTDataType;
typedef struct SListNode
{
SLTDataType data;
struct SListNode* next;
}SLTNode,*SLT;
//强调这是一个单链表使用STL,强调这是一个结点用SLTNode*,实际上STL和STLNode*是等价的要表示一个单链表时,只需声明一个头指针L,指向单链表的第一个结点。
SLT L;//声明一个指向单链表第一个结点的指针
2.1.不带头结点的单链表
typedef int SLTDataType;
typedef struct SListNode
{
SLTDataType data;
struct SListNode* next;
}SLTNode, * SLT;
//初始化一个空的单链表
bool InitList(SLT* L)
{
L = NULL;//空表,暂时还没有结束,防止脏数据
return true;
}
//判空操作
bool Empty(SLT L)
{
if (L == NULL)
return true;
else
return false;
}
void test()
{
SLT L;//声明一个指向单链表的指针,注意此处并没有创建一个结点
//初始化一个空表
InitList(L);
}2.2.带头结点的单链表
typedef int SLTDataType;
typedef struct SListNode
{
SLTDataType data;
struct SListNode* next;
}SLTNode, * SLT;
//初始化一个空的单链表
bool InitList(SLT* L)
{
L = (SLTNode*)malloc(sizeof(SLTNode));//分配一个结点
if (L == NULL)//内存不足,分配失败
return false;
L->next = NULL;//头结点不存储数据,头结点之后暂时没有结点
return true;
}
//判空操作
bool Empty(SLT L)
{
if (L->next == NULL)
return true;
else
return false;
}
void test()
{
SLT L;//声明一个指向单链表的指针,注意此处并没有创建一个结点
//初始化一个空表
InitList(L);
}不带头结点与带头结点对比:

三.单链表的功能实现
3.1.单链表的定义
typedef int SLTDataType;
typedef struct SListNode
{
SLTDataType data;
struct SListNode* next;
}SLTNode;3.2.单链表的打印
//打印
void SListPrint(SLTNode* phead)
{
SLTNode* cur = phead;//phead指向头结点
while (cur != NULL)
{
printf("%d->",cur->data);
cur = cur->next;
}
printf("NULL\n");
}单链表的头指针phead标识着整个单链表的开始,习惯上用头指针代表单链表。给定单链表的头指针phead,即可顺着每个结点的next指针域得到单链表中的每个元素。因此对于整个单链表的操作必须从头开始。
调试分析:
void test()
{
SLTNode* n1 = (SLTNode*)malloc(sizeof(SLTNode));
assert(n1);
SLTNode* n2 = (SLTNode*)malloc(sizeof(SLTNode));
assert(n2);
SLTNode* n3 = (SLTNode*)malloc(sizeof(SLTNode));
assert(n3);
SLTNode* n4 = (SLTNode*)malloc(sizeof(SLTNode));
assert(n4);
n1->data = 1;
n2->data = 2;
n3->data = 3;
n4->data = 4;
n1->next = n2;
n2->next = n3;
n3->next = n4;
n4->next = NULL;
SLTNode* plist = n1;
//打印
SListPrint(n1);
}
int main()
{
test();
return 0;
}运行结果:
![]()
3.3.单链表的结点的创建
SLTNode* BuySListNode(SLTDataType x)
{
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
assert(newnode);
newnode->data = x;
newnode->next = NULL;
return newnode;
}单链表是由一个个结点组成,而每个结点都是通过调用malloc函数来进行开辟的,同时返回一个该类型的指针。
调试分析:
void test()
{
SLTNode* n1 = (SLTNode*)malloc(sizeof(SLTNode));
assert(n1);
SLTNode* n2 = (SLTNode*)malloc(sizeof(SLTNode));
assert(n2);
SLTNode* n3 = (SLTNode*)malloc(sizeof(SLTNode));
assert(n3);
SLTNode* n4 = (SLTNode*)malloc(sizeof(SLTNode));
assert(n4);
//创建结点
SLTNode* n5 = BuySListNode(5);
n1->data = 1;
n2->data = 2;
n3->data = 3;
n4->data = 4;
n1->next = n2;
n2->next = n3;
n3->next = n4;
n4->next = n5;
SLTNode* plist = n1;
//打印
SListPrint(n1);
}
int main()
{
test();
return 0;
}运行结果:
![]()
3.4.单链表的尾插
void SListPushBack(SLTNode** pphead, SLTDataType x)
{
assert(pphead);
SLTNode* newnode = BuySListNode(x);
if (*pphead == NULL)//链表为空
{
*pphead = newnode;//直接插入
}
else
{
SLTNode* tail = *pphead;
//找尾结点
while (tail->next != NULL)
{
tail = tail->next;
}
//插入
tail->next = newnode;
}
}在对单链表进行尾插操时,我们要分两种情况进行讨论:第一,当*pphead==NULL,也就是当单链表为空时,我们直接创建一个新结点newnode,并让头指针*pphead指向该结点;第二,当*pphead!=NULL,也就是当链表不为空时,我们通过while循环,查找到链表的最后一个结点tail,并将新创建的结点newnode插入到尾结点tail的后面,此时链表的尾结点变为newnode。
这里还需要特别说明的一点是,我们此时传入的是二级指针,而非一级指针。在指针变量定义语句SLTNode* pphead中,将pphead定义为指向SLTNode类型的指针变量,这里的pphead是一级指针,可以通过->来访问结构体成员变量;在指针变量定义语句SLTNode** pphead中,pphead是指向单链表的头结点的指针,用来接收主程序中待初始化单链表的的头指针变量的地址,*pphead相当于主程序中待初始化单链表的头指针变量,这里的*pphead是一级指针。我们要想通过函数传参来实现对单链表的修改,如果此时传入一级指针,也就相当于传值,是现实不了对单链表的修改的,因为形参的存储空间是函数被调用时才分配的,调用开始,系统为形参开辟一个临时的存储区,然后将各实参传递给形参,这时形参就得到了实参的值,任何的修改都是在副本形参上作用,没有作用在原来的实参上,在函数调用完毕之后,形参会立即释放所占用的内存空间,因此它并不会把修改后的值传递给实参;如果此时传入二级指针,也就相当于传地址,此时是可以实现对单链表的修改的,它把实参的存储地址传送给形参,使得形参指针和实参指针指向同一块地址。因此,被调用函数中对形参指针所指向的地址中内容的任何改变都会影响到实参。
调试分析:
void test()
{
SLTNode* n1 = (SLTNode*)malloc(sizeof(SLTNode));
assert(n1);
SLTNode* n2 = (SLTNode*)malloc(sizeof(SLTNode));
assert(n2);
SLTNode* n3 = (SLTNode*)malloc(sizeof(SLTNode));
assert(n3);
SLTNode* n4 = (SLTNode*)malloc(sizeof(SLTNode));
assert(n4);
n1->data = 1;
n2->data = 2;
n3->data = 3;
n4->data = 4;
n1->next = n2;
n2->next = n3;
n3->next = n4;
n4->next = NULL;
SLTNode* plist = n1;
//尾插
SListPushBack(&plist, 5);
SListPushBack(&plist, 6);
SListPushBack(&plist, 7);
SListPushBack(&plist, 8);
//打印
SListPrint(n1);
}
int main()
{
test();
return 0;
}运行结果:
![]()
3.5.单链表的头插
void SListPushFront(SLTNode** pphead, SLTDataType x)
{
assert(pphead);
SLTNode* newnode = BuySListNode(x);
newnode->next = *pphead;
*pphead = newnode;
}在进行头插之前要调用BuySListNode函数来创建一个新结点newnode,并让新结点的next指针指向头结点*pphead,最后把新结点赋值给*pphead,使其变为链表新的头结点。
调试分析:

3.6.单链表的尾删
void SListPopBack(SLTNode** pphead)
{
//地址不为空
assert(pphead);
//链表不为空
assert(*pphead != NULL);
//只有一个结点
if ((*pphead)->next == NULL)
{
//释放该结点
free(*pphead);
*pphead = NULL;
}
else
{
//有多个结点
/*
SLTNode* tailPrev = NULL;
SLTNode* tail = *pphead;
while (tail->next != NULL)
{
tailPrev = tail;
tail = tail->next;
}
free(tail);
tailPrev->next = NULL;
*/
SLTNode* tail = *pphead;
while (tail->next->next != NULL)//查找倒数第二个结点
{
tail = tail->next;
}
free(tail->next);//释放掉倒数第一个结点
tail->next = NULL;//tail变为新的尾结点
}
}在进行尾删之前,需要进行一定的条件判断。其一:当链表为空时,此时无法进行尾删,强制删除会报错,这时需要进行assert断言,判断链表是否为空,避免错误的发生;其二:当链表只包含一个结点时,则直接调用free函数释放该结点,并将释放后的结点置为NULL;其三:当链表中包含两个以上结点时,这时要通过循环查找到倒数第二个结点tail,然后调用free函数释放掉尾结点tail->next,这时尾结点变为tail,直接将其next指针域置为NULL即可。
调试分析:

运行结果:
![]()
3.7.单链表的头删
void SListPopFront(SLTNode** pphead)
{
assert(pphead);
//判断链表是否为空
/*
//温柔检查
if (*pphead == NULL)
{
return;
}
*/
//暴力检查
assert(*pphead != NULL);
SLTNode* cur = *pphead;
SLTNode* next =cur->next;//保存头结点的下一个结点
free(cur);//释放头结点
*pphead = next;//将新结点变为头结点
}在进行头删之前,需要进行一定的条件判断。其一:当链表为空时,此时无法进行尾删,强制删除会报错,这时需要进行assert断言,判断链表是否为空,避免错误的发生;其二:当链表中包含一个及以上结点时,首先将头结点指向的第二个结点保存在next中,然后调用free函数释放掉头结点,最后将新结点变为头结点。
调试分析:

运行结果:
![]()
3.8.单链表的查找
SLTNode* SListFind(SLTNode* phead, SLTDataType x)
{
SLTNode* cur = phead;
while (cur)//cur!=NULL
{
if (cur->data == x)
{
return cur;//返回对应的结点
}
cur = cur->next;
}
//若没找到则返回NULL
return NULL;
}因为查找不涉及对链表的修改,所以只需要传入一级指针即可。
通过while循环遍历整个链表,然后返回链表中数据域为x且首次出现的某一结点。若整个单链表中没有数据域为x的结点,则返回NULL。
调试分析:
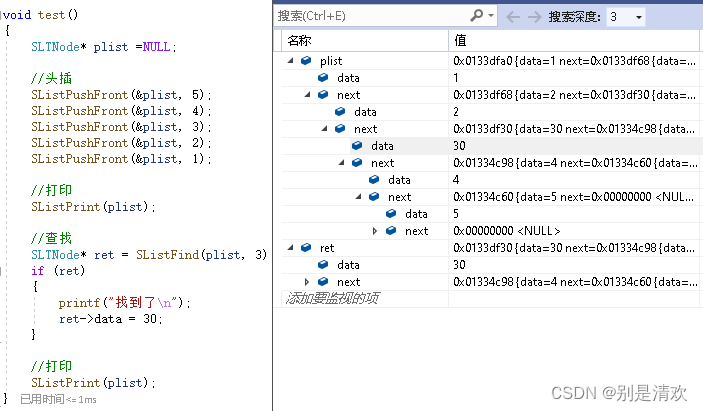
运行结果:

3.9.单链表的在pos位置之前插入数据
void SListInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{
//地址不为空
assert(pphead);
//pos位置合法性判断
assert(pos);
//头插
if (pos == *pphead)
{
SListPushFront(pphead, x);
}
else
{
SLTNode* pre = *pphead;
while (pre->next != pos)//找到pos结点的前一个结点
{
pre = pre->next;
}
//开辟一个新结点
SLTNode* newnode = BuySListNode(x);
//将新结点插入到pre结点和pos结点中间,此时的newnode处在新的pos位置
pre->next = newnode;
newnode->next = pos;
}
}该函数的功能是:在结点pos之前插入一个新结点,新结点的数据域为x。
在插入之前,首先要对结点pos进行断言,判断其位置是否合法,若合法则可以插入新结点。当pos为头结点时,此时进行的是头插,直接调用函数SListPushFront(pphead, x)进行新结点的插入;当pos为链表中任意位置处的结点,此时要通过while循环找到pos结点的前一个结点pre,然后开辟一个新结点newnode,并将新结点插入到pre和pos中间,此时的newnode取代pos,成为新的pos位置上的结点。
调试分析:

运行结果:
![]()
3.10.单链表的删除pos位置之前的结点
void SListErase(SLTNode** pphead, SLTNode* pos)
{
//地址不为空
assert(pphead);
//pos位置合法性判断
assert(pos);
//头删
if (*pphead == pos)
{
SListPopFront(pphead);
}
else
{
SLTNode* pre = *pphead;
while (pre->next != pos)//找到pos结点的前一个结点pre
{
pre = pre->next;
}
pre->next = pos->next;//将pre的next指针指向pos的后一个结点
free(pos);//释放pos结点
}
}
该函数的功能是:删除结点pos之前的一个结点。
在删除之前,首先要对结点pos进行断言,判断其位置是否合法,若合法则可以删除结点。当pos为头结点时,此时进行的是头删,直接调用函数SListPopFront(pphead)将头结点进行删除;当pos为链表中任意位置处的结点,此时要通过while循环找到pos结点的前一个结点pre,然后将pre的next指针指向pos的后一个结点,并调用free函数释放pos结点。
调试分析:

运行结果:
![]()
3.11.单链表的在pos位置之后插入
void SListInsertAfter(SLTNode* pos, SLTDataType x)
{
assert(pos);
/*
//法一
SLTNode* newnode = BuySListNode(x);
//先把pos后面节点的地址交给newnode->next,再将newnode的地址交给pos->next,两者不能颠倒
newnode->next = pos->next;
pos->next = newnode;
*/
//法二
SLTNode* newnode = BuySListNode(x);
SLTNode* next = pos->next;//next为pos的下一个结点
pos->next = newnode;
newnode->next = next;
}该函数的功能是:在结点pos之后插入一个新结点,新结点的数据域为x。
在插入之前,首先要对结点pos进行断言,判断其位置是否合法,若合法则可以插入新结点。首先要开辟一个新结点newnode,然后将pos之后的下一个结点保存在next当中,接着将pos结点指向newnode,最后再将newnode结点指向next。
调试分析:

运行结果:
![]()
3.12.单链表的删除pos位置之后的结点
void SListEraseAfter(SLTNode* pos)
{
//pos位置合法性判断
assert(pos);
//只有pos一个结点
if (pos->next == NULL)
{
return;
}
SLTNode* del = pos->next;//将pos的后一个结点保存在del中
//pos->next = pos->next->next;
pos->next = del->next;//将pos指向del的后一个结点
free(del);//释放结点del
}该函数的功能是:删除结点pos之后的一个结点。
在删除之前,首先要对结点pos进行断言,判断其位置是否合法,若合法则可以删除结点。当链表只包含一个结点pos时,则无法进行删除;当pos为链表中任意位置处的结点时,首先将pos的后一个结点保存在del中,然后将结点pos指向del的下一个结点,最后再调用free函数释放掉结点del。
调试分析:

运行结果:
![]()
3.13.单链表的销毁
void SListDestry(SLTNode** pphead)
{
SLTNode* cur = *pphead;
while (cur)
{
SLTNode* nextnode = cur->next;
free(cur);
cur = nextnode;
}
*pphead = NULL;
}在使用完链表之后,要将链表进行销毁,对内存空间进行回收。这里主要通过对链表的遍历,实现对链表的逐一销毁,最后要将头结点置为NULL。
调试分析:
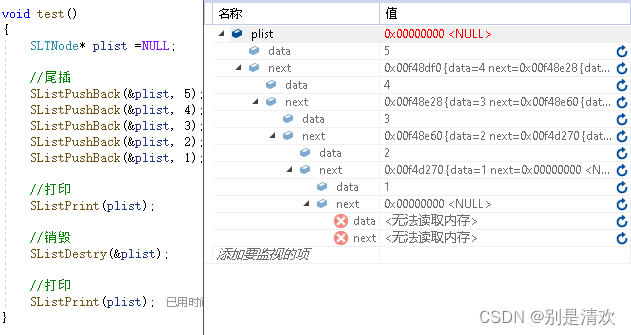
运行结果:
![]()
3.14.完整程序
SList.h
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
typedef int SLTDataType;
typedef struct SListNode
{
SLTDataType data;
struct SListNode* next;
}SLTNode;
//打印
void SListPrint(SLTNode* phead);
//创建结点
SLTNode* BuySListNode(SLTDataType x);
//尾插
void SListPushBack(SLTNode** pphead, SLTDataType x);//要传地址,对一级指针的修改,需要二级指针来接收
//头插
void SListPushFront(SLTNode** pphead, SLTDataType x);
//尾删
void SListPopBack(SLTNode** pphead);
//头删
void SListPopFront(SLTNode** pphead);
//查找
SLTNode* SListFind(SLTNode* phead, SLTDataType x);
//在pos位置之前插入
void SListInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x);
//删除pos位置之前的结点
void SListErase(SLTNode** pphead, SLTNode* pos);
//在pos位置之后插入
void SListInsertAfter(SLTNode* pos, SLTDataType x);
//删除pos位置之后的结点
void SListEraseAfter(SLTNode* pos);
//销毁
void SListDestry(SLTNode** pphead);SList.c
#define _CRT_SECURE_NO_WARNINGS 1
#include"SList.h"
//打印
void SListPrint(SLTNode* phead)
{
SLTNode* cur = phead;//phead指向头结点
while (cur != NULL)
{
printf("%d->",cur->data);
cur = cur->next;
}
printf("NULL\n");
}
//创建结点
SLTNode* BuySListNode(SLTDataType x)
{
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
assert(newnode);
newnode->data = x;
newnode->next = NULL;
return newnode;
}
//尾插
void SListPushBack(SLTNode** pphead, SLTDataType x)
{
assert(pphead);
SLTNode* newnode = BuySListNode(x);
if (*pphead == NULL)//链表为空
{
*pphead = newnode;//直接插入
}
else
{
SLTNode* tail = *pphead;
//找尾结点
while (tail->next != NULL)
{
tail = tail->next;
}
//插入
tail->next = newnode;
}
}
//头插
void SListPushFront(SLTNode** pphead, SLTDataType x)
{
assert(pphead);
SLTNode* newnode = BuySListNode(x);
newnode->next = *pphead;
*pphead = newnode;
}
//尾删
void SListPopBack(SLTNode** pphead)
{
//地址不为空
assert(pphead);
//链表不为空
assert(*pphead != NULL);
//只有一个结点
if ((*pphead)->next == NULL)
{
//释放该结点
free(*pphead);
*pphead = NULL;
}
else
{
//有多个结点
/*
SLTNode* tailPrev = NULL;
SLTNode* tail = *pphead;
while (tail->next != NULL)
{
tailPrev = tail;
tail = tail->next;
}
free(tail);
tailPrev->next = NULL;
*/
SLTNode* tail = *pphead;
while (tail->next->next != NULL)//查找倒数第二个结点
{
tail = tail->next;
}
free(tail->next);//释放掉倒数第一个结点
tail->next = NULL;//tail变为新的尾结点
}
}
//头删
void SListPopFront(SLTNode** pphead)
{
assert(pphead);
//判断链表是否为空
/*
//温柔检查
if (*pphead == NULL)
{
return;
}
*/
//暴力检查
assert(*pphead != NULL);
SLTNode* cur = *pphead;
SLTNode* next =cur->next;//保存头结点的下一个结点
free(cur);//释放头结点
*pphead = next;//将新结点变为头结点
}
//查找
SLTNode* SListFind(SLTNode* phead, SLTDataType x)
{
SLTNode* cur = phead;
while (cur)//cur!=NULL
{
if (cur->data == x)
{
return cur;//返回对应的结点
}
cur = cur->next;
}
//若没找到则返回NULL
return NULL;
}
//在pos位置之前插入
void SListInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{
//地址不为空
assert(pphead);
//pos位置合法性判断
assert(pos);
//头插
if (pos == *pphead)
{
SListPushFront(pphead, x);
}
else
{
SLTNode* pre = *pphead;
while (pre->next != pos)//找到pos结点的前一个结点
{
pre = pre->next;
}
//开辟一个新结点
SLTNode* newnode = BuySListNode(x);
//将新结点插入到pre结点和pos结点中间,此时的newnode处在新的pos位置
pre->next = newnode;
newnode->next = pos;
}
}
//删除pos位置之前的结点
void SListErase(SLTNode** pphead, SLTNode* pos)
{
//地址不为空
assert(pphead);
//pos位置合法性判断
assert(pos);
//头删
if (*pphead == pos)
{
SListPopFront(pphead);
}
else
{
SLTNode* pre = *pphead;
while (pre->next != pos)//找到pos结点的前一个结点pre
{
pre = pre->next;
}
pre->next = pos->next;//将pre的next指针指向pos的后一个结点
free(pos);//释放pos结点
}
}
//在pos位置之后插入
void SListInsertAfter(SLTNode* pos, SLTDataType x)
{
assert(pos);
/*
//法一
SLTNode* newnode = BuySListNode(x);
//先把pos后面节点的地址交给newnode->next,再将newnode的地址交给pos->next,两者不能颠倒
newnode->next = pos->next;
pos->next = newnode;
*/
//法二
SLTNode* newnode = BuySListNode(x);
SLTNode* next = pos->next;//next为pos的下一个结点
pos->next = newnode;
newnode->next = next;
}
//删除pos位置之后的结点
void SListEraseAfter(SLTNode* pos)
{
//pos位置合法性判断
assert(pos);
//只有pos一个结点
if (pos->next == NULL)
{
return;
}
SLTNode* del = pos->next;//将pos的后一个结点保存在del中
//pos->next = pos->next->next;
pos->next = del->next;//将pos指向del的后一个结点
free(del);//释放结点del
}
//销毁
void SListDestry(SLTNode** pphead)
{
SLTNode* cur = *pphead;
while (cur)
{
SLTNode* nextnode = cur->next;
free(cur);
cur = nextnode;
}
*pphead = NULL;
}test.c
#define _CRT_SECURE_NO_WARNINGS 1
//顺序表的优缺点
//优点:
//1.物理空间连续
//2.下标随机访问
//缺点:
//1.空间不够,需要扩容。扩容有一定性能消耗,其次一般是扩容2倍,存在一定的空间浪费
//2.头部或者中间位置插入或删除效率较低
#include"SList.h"
void test()
{
SLTNode* plist =NULL;
//尾插
SListPushBack(&plist, 5);
SListPushBack(&plist, 4);
SListPushBack(&plist, 3);
SListPushBack(&plist, 2);
SListPushBack(&plist, 1);
//打印
SListPrint(plist);
//销毁
SListDestry(&plist);
//打印
SListPrint(plist);
}
int main()
{
test();
return 0;
}四.链表面试题
题一:移除链表元素
题目描述:
给你一个链表的头结点head和一个整数val,请你删除链表中所有满足Node.val==val的结点,并返回新的头结点。
分析:
法一:
设置两个结点cur和pre,cur用于遍历整个链表,pre用于保存cur的前一个结点,两个结点同时向后移动。
在遍历链表时,需要分情况进行讨论,当头结点为所要删除的结点时,此时要做单独处理;当头结点不为所要删除的结点时,此时将pre的next指向cur的next,然后释放掉cur,并将pre的next重新赋值给cur。
这里不用二级指针的原因:因为这里返回了一个新的头
实现:
struct ListNode
{
int val;
struct ListNode* next;
};
struct ListNode* removeElements(struct ListNode* head, int val)
{
struct ListNode* pre = NULL;
struct ListNode* cur = head;
while (cur)
{
if (cur->val == val)
{
//头删,用于解决都是相同元素的情况,比如7 7 7 7 7
if (cur == head || pre == NULL)
{
head = cur->next;
free(cur);
cur = head;
}
else
{
//删除
pre->next = cur->next;
free(cur);
cur = pre->next;
}
}
else
{
pre = cur;
cur = cur->next;
}
}
return head;
}法二:
遍历原链表,把不是val的结点拿出来进行尾插到新链表。
实现:
struct ListNode
{
int val;
struct ListNode* next;
};
struct ListNode* removeElements(struct ListNode* head, int val)
{
struct ListNode* tail = NULL;//用于标记新链表的尾
struct ListNode* cur = head;//用于遍历原链表
//防止野指针,当所有元素均为7 7 7 7 7,而val恰好为7,在删除所有结点之后,head依旧指向第一个结点7的位置,此时head就会变为一个野指针
head = NULL;
while (cur)
{
//删除等于val的结点
if (cur->val == val)
{
struct ListNode* del = cur;
cur = cur->next;
free(del);
}
else
{
//尾插到新链表
if (tail == NULL)//新链表为空则直接插入
{
head = tail = cur;
}
else
{
tail->next = cur;
tail = tail->next;//更新tail,重新指向尾
}
cur = cur->next;
}
}
if (tail)//当链表不为空时,将链表尾结点的next置为空,防止原链表最后一个结点为所要删除的结点,删除后前一个结点变为尾结点,但它的next依旧指向被删除的结点,此时就会变成一个野指针
{
tail->next = NULL;
}
return head;
}法三:
使用带哨兵的头结点,遍历原链表,把不是val的结点拿出来进行尾插到新链表。
实现:
struct ListNode
{
int val;
struct ListNode* next;
};
struct ListNode* removeElements(struct ListNode* head, int val)
{
struct ListNode* tail = NULL;
struct ListNode* cur = head;
//带哨兵位的头结点
head = tail = (struct ListNode*)malloc(sizeof(struct ListNode));
tail->next = NULL;
while (cur)
{
//删除
if (cur->val == val)
{
struct ListNode* del = cur;
cur = cur->next;
free(del);
}
else
{
tail->next = cur;
tail = tail->next;
cur = cur->next;
}
}
//将尾结点tail的next置为NULL
tail->next = NULL;
//删除带哨兵位的头结点,让head重新指向第一个结点
struct ListNode* del = head;
head = head->next;
free(del);
return head;
}题二:反转链表
题目描述:
给你单链表的头结点head,请你反转链表,并返回反转后的链表。
分析:
法一:
依次取出原链表的各个结点,然后以头插的方式插入到新链表。
实现:
struct ListNode
{
int val;
struct ListNode* next;
};
struct ListNode* reverseList(struct ListNode* head)
{
struct ListNode* newhead = NULL;
struct ListNode* cur = head;
while (cur)
{
struct ListNode* next = cur->next;//保存cur所指向的下一个结点
//头插
cur->next = newhead;//将cur指向newhead
newhead = cur;//将newhead变为新的头
cur = next;//回到原链表的下一个结点的位置
}
return newhead;
}法二:
颠倒指针,也就是把指针的方向颠倒。
实现:
struct ListNode
{
int val;
struct ListNode* next;
};
struct ListNode* reverseList(struct ListNode* head)
{
if (head == NULL)
return NULL;
struct ListNode* n1, * n2, * n3 = NULL;
//起始状态
n1 = NULL;
n2 = head;
n3 = n2->next;//用于保存n2的下一个结点
while (n2)//n2为空,则循环结束
{
//颠倒方向,让n2的next指向n1
n2->next = n1;
//迭代,即n1,n2和n3分别向后移动一次
n1 = n2;
n2 = n3;
if (n3)//n3为空,则不继续往后移动
n3 = n3->next;
}
return n1;//n1变为链表的头
}题三:链表的中间结点
题目描述:
给定一个头结点为head的非空单链表,返回链表的中间结点。如果有两个中间结点,则返回第二个中间结点。
分析:
快慢指针:定义一个慢指针slow,定义一个快指针fast,慢指针一次走一步,快指针一次走两步,当快指针走到尾的时候,慢指针就是中间结点。
奇数个元素有唯一的中间结点,偶数个元素有两个中间结点,取第二个结点为中间结点。
实现:
struct ListNode
{
int val;
struct ListNode* next;
};
struct ListNode* middleNode(struct ListNode* head)
{
struct ListNode* slow, * fast;
slow = fast = head;
while (fast && fast->next)//分别对应奇数个元素和偶数个元素
{
slow = slow->next;
fast = fast->next->next;
}
return slow;
}题四:链表中倒数第k个结点
题目描述:
输入一个链表,输出该链表中倒数第k个结点。
分析:
快慢指针:定义一个慢指针slow,定义一个快指针fast,快指针先走k步,使快慢指针之间相差k步,然后快慢指针同时走。当快指针fast为NULL,慢指针slow所在的位置就是链表中倒数第k个结点。
实现:
struct ListNode
{
int val;
struct ListNode* next;
};
struct ListNode* FindkthToTail(struct ListNode* pListHead, int k)
{
struct ListNode* slow, * fast;
slow = fast = pListHead;
//fast先走k步
while (k--)
{
//fast还没走完k步,就已经走到头,说明链表并没有k步长,也就是k大于链表的长度
if (fast == NULL)
return NULL;
fast = fast->next;
}
//快慢指针同时走
while (fast)
{
slow = slow->next;
fast = fast->next;
}
return slow;
}题五:合并两个有序链表
题目描述:
将两个升序链表合并为一个新的升序链表并返回。新链表是通过拼接给定的两个链表的所有结点组成的。
分析:
设置两个指针,分别指向两个链表的第一个结点,从头开始依次比较,取小的尾插到新链表,若相等则任选一个插入。当其中一个走到空,就结束比较,并将另一个链表剩余的元素插入到新链表的尾部。
法一:
不带哨兵位。
实现:
struct ListNode
{
int val;
struct ListNode* next;
};
//不带哨兵位
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2)
{
//list1为空链表
if (list1 == NULL)
return list2;
//list2为空链表
if (list2 == NULL)
return list1;
struct ListNode* head, * tail;
head = tail = NULL;
while (list1 && list2)//当list1和list2有一个走完,则结束
{
if (list1->val < list2->val)
{
//插入第一个结点时,需要判断链表是否为空
if (tail == NULL)
{
head = tail = list1;
}
else
{
//链表不为空
tail->next = list1;
tail = tail->next;//更新tail
}
//list1向后走一步
list1 = list1->next;
}
else
{
//插入第一个结点时,需要判断链表是否为空
if (tail == NULL)
{
head = tail = list2;
}
else
{
//链表不为空
tail->next = list2;
tail = tail->next;//更新tail
}
//list2向后走一步
list2 = list2->next;
}
}
//list2为空,list1不为空
if (list1)
tail->next = list1;//将list1剩余的部分连接到新链表的尾部
//list1为空,list2不为空
if (list2)
tail->next = list2;//将list2剩余的部分连接到新链表的尾部
return head;
}法二:
带哨兵位。
实现:
//带哨兵位
//带哨兵位的头结点可以方便尾插
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2)
{
struct ListNode* head, * tail;
head = tail = (struct ListNode*)malloc(sizeof(struct ListNode));//哨兵位的头结点不存储有效数据
tail->next = NULL;
while (list1 && list2)
{
if (list1->val < list2->val)
{
tail->next = list1;
tail = tail->next;
list1 = list1->next;
}
else
{
tail->next = list2;
tail = tail->next;
list2 = list2->next;
}
}
if (list1)
tail->next = list1;
if (list2)
tail->next = list2;
struct ListNode* list = head->next;
free(head);
return list;
}题六:链表分割
题目描述:
现有一链表的头指针ListNode* pHead,给一定值x,编写一段代码将所有小于x的结点排在其余结点之前,且不能改变原来的数据顺序,返回重新排列后的链表的头指针。
分析:
定义两个带有哨兵位的链表,一个叫greaterhead,一个叫lesshead,比x小的尾插到链表lesshead,比x大的尾插到链表greaterhead。
分类讨论:结点都比x小,结点都比x大,结点有比x大有比x小(容易产生环)。
案例一:5 3 2 8 1 6,此时x=4,比x小的为3 2 1,比x大的为5 8 6,两链表进行链接得3 2 1 5 8 6,但由于6的next本来就为NULL,此时不会产生环;
案例二:5 3 2 8 1 6,此时x=7,比x小的为5 3 2 1 6,bix大的为8,两链表进行链接得5 3 2 1 6 8,但由于8的next仍旧指向1,此时会在1 6 8之间产生环。
实现:
struct ListNode
{
int val;
struct ListNode* next;
};
//带哨兵位:一般用于尾插的场合
struct ListNode* partition(struct ListNode* pHead, int x)
{
struct ListNode* greaterhead, * greatertail, * lesshead, * lesstail;
greaterhead = greatertail = (struct ListNode*)malloc(sizeof(struct ListNode));
lesshead = lesstail = (struct ListNode*)malloc(sizeof(struct ListNode));
//头结点的next置为NULL
greatertail->next = NULL;
lesstail->next = NULL;
struct ListNode* cur = pHead;
while (cur)//遍历链表
{
//比x小的尾插到链表lesshead
if (cur->val < x)
{
lesstail->next = cur;
lesstail = lesstail->next;
}
else
{
//比x大的尾插到链表greaterhead
greatertail->next = cur;
greatertail = greatertail->next;
}
cur = cur->next;
}
//将链表lesshead的尾结点lesstail链接到链表greaterhead的第一个元素greaterhead->next处
lesstail->next = greaterhead->next;
//避免出现环,直接将尾结点的next置为NULL
greatertail->next = NULL;
struct ListNode* head = lesshead->next;
free(greaterhead);
free(lesshead);
return head;//返回不带哨兵位的头结点
}题七:链表的回文结构
题目描述:
对于一个链表,请设计一个时间复杂度为O(N),额外空间复杂度为O(1)的算法,判断其是否为回文结构。
给定一个链表的头指针A,请返回一个bool值,代表其是否为回文结构,保证链表长度小于等于900。
分析:
用快慢指针找到中间结点,然后将包含中间结点在内的后半段链表进行逆置,原链表从头结点开始,逆置后的新链表也头结点开始,两者进行逐一比较,若全都相等则为回文结构,否则不是。
若结点个数为奇数:head和rhead同时走到头。比如1 2 3 2 1,逆置得1 2 1 2 3,head从第一个1开始,rhead从第二个1开始,当它们比较完2时,此时两个2的next均为3(因为第一个2的next在原链表中指向3,所以它们都指向同一个3),所以最终head和rhead同时走到头。
若结点个数为偶数:rhead先走到头。比如1 2 2 1,逆置得1 2 1 2,head从第一个1开始,rhead从第二个1开始,当它们比较完2时,此时第一个2的next在原链表中指向第二个2,而第二个2的next为NULL,因而rhead先结束,所以rhead先走到头。
实现:
struct ListNode
{
int val;
struct ListNode* next;
};
//寻找中间结点
struct ListNode* middleNode(struct ListNode* head)
{
struct ListNode* slow, * fast;
slow = fast = head;
while (fast && fast->next)//分别对应奇数个元素和偶数个元素
{
slow = slow->next;
fast = fast->next->next;
}
return slow;
}
//逆置链表
struct ListNode* reverseList(struct ListNode* head)
{
if (head == NULL)
return NULL;
struct ListNode* n1, * n2, * n3 = NULL;
n1 = NULL;
n2 = head;
n3 = n2->next;
while (n2)
{
//颠倒方向
n2->next = n1;
//迭代
n1 = n2;
n2 = n3;
if (n3)
n3 = n3->next;
}
return n1;
}
//判断
bool chkPalindrome(struct ListNode* A)
{
struct ListNode* head = A;
struct ListNode* mid = middleNode(head);
struct ListNode* rhead = reverseList(mid);
while (head && rhead)
{
if (head->val != rhead->val)
{
return false;
}
else
{
head = head->next;
rhead = rhead->next;
}
}
return true;
}题八:相交链表
题目描述:
给你两个单链表的头结点headA和headB,请你找出并返回两个单链表相交的起始结点。如果两个链表不存在相交结点,返回NULL。
分析:
求出链表headA的长度,再求出链表headB的长度,然后求出两个链表表长相减后的绝对值gap。让长的链表先走gap步,然后两链表同时走并逐一结点进行比较,若不相等,则两链表同时往后走,若相等,则找到相交的结点。
实现:
struct ListNode
{
int val;
struct ListNode* next;
};
struct ListNode* getIntersectionNode(struct ListNode* headA, struct ListNode* headB)
{
//判断两链表是否为空
if (headA == NULL || headB == NULL)
{
return NULL;
}
struct ListNode* curA = headA, * curB = headB;
//求两链表长度
int lenA = 1, lenB = 1;
while (curA->next)
{
curA = curA->next;
lenA++;
}
while (curB->next)
{
curB = curB->next;
lenB++;
}
//判断是否相交,若不相交则返回NULL
if (curA != curB)
{
return NULL;
}
//若相交,求第一个交点
struct ListNode* shortList = headA, *longList = headB;
//比较两链表长短
if (lenA > lenB)
{
shortList = headB;
longList = headA;
}
//求出两个链表表长的绝对值gap
int gap = abs(lenA - lenB);
//长的先走gap步
while (gap--)
{
longList = longList->next;
}
//若相等则停止比较,若不相等则继续
while (shortList != longList)
{
shortList = shortList->next;
longList = longList->next;
}
return shortList;
}题九:环形链表①
题目描述:
给你一个链表的头结点head,判断链表中是否有环。
如果链表中有某个结点,可以通过连续跟踪next指针再次到达,则链表中存在环,为了表示给定链表中的环,评测系统内部使用整数pos来表示链表尾连接到链表中的位置(索引从0开始)。
如果链表中存在环,则返回true,否则,返回false。
分析:
快慢指针:慢指针一次走一步,快指针一次走两步,在入环前的一段,当慢指针走一半时,快指针已经准备进环。当快慢指针都已进环,此时就变成快慢指针的追击问题。当快指针追上慢指针时,则表示有环,否则表示无环。

实现:
struct ListNode
{
int val;
struct ListNode* next;
};
bool hasCycle(struct ListNode* head)
{
struct ListNode* fast = head, * slow = head;
while (fast && fast->next)//如果不带环,元素个数可能为奇数个或偶数个
{
slow = slow->next;//一次走一步
fast = fast->next->next;//一次走两步
//快慢指针相遇
if (slow == fast)
return true;
}
return false;
}拓展问题:
为什么快指针每次走两步,慢指针每次走一步就可以追上?
分析:
假设slow刚进环时,fast与slow的距离是N。这时fast真正开始追击slow,fast一次走两步,slow一次走一步,每追击一次它们之间的距离缩小1,依次递减,N,N-1,...,2,1,0,当距离缩小为0时,则表示追上。
若fast一次走三步,slow一次走一步,能否追得上?
若fast一次走三步,slow一次走一步,则不一定能追上。假设slow进环以后,fast与slow的距离是N
这时fast真正开始追击slow,fast一次走三步,slow一次走一步,每追击一次它们之间的距离缩小2;若距离N是偶数,依次递减N,N-2,...2,0,当距离缩小为0时,则表示追上;若距离N是奇数,依次递减N,N-2,...3,1,-1,此时它们的距离变成了C-1(假设C是环的大小),若C-1是奇数则追不上,若C-1是偶数则可以追上。

题十:环形链表②
题目描述:
给定一个链表的头结点head,返回链表开始入环的第一个结点。如果链表无环,则返回NULL。不允许修改链表。
分析:
slow进环以后,fast在两圈之内,一定会追上slow,因为追击过程它们距离每次缩小1,不可能会错过,它们的相对距离最多是1圈,slow最多走一圈,fast最多走两圈。
假设环的大小是C,未进环之前的距离为L,假设slow进环前,fast在环里面转了N圈(N>=1)
slow走的路程:L+X
fast走的路程:L+N*C+X
fast走的路程是slow的二倍
公式:2*(L+X)=L+N*C+X,即L=N*C-X=(N-1)*C+C-X
结论:一个指针从相遇点meet开始走,一个指针从head开始走,它们会在入口点相遇

法一:
先采用快慢指针fast和slow找到两指针相遇点meet,再让两指针meet和head分别从相遇结点与链表表头同时出发,每次走一步,这两个指针初次相遇的结点就是环的起点。
实现:
struct ListNode
{
int val;
struct ListNode* next;
};
struct ListNode* detectCycle(struct ListNode* head)
{
struct ListNode* fast = head, * slow = head;
while (fast && fast->next)//对应奇数个元素和偶数个元素
{
slow = slow->next;
fast = fast->next->next;
//若相遇
if (slow == fast)
{
struct ListNode* meet = slow;//meet为相遇点
//一个指针从meet开始走,一个指针从head开始走,它们会在入口点相遇
while (meet != head)
{
meet = meet->next;
head = head->next;
}
//相等点,即为入口点
return meet;
}
}
return NULL;
}法二:
在相遇结点meet的下一个位置开辟一个新结点newhead作为头,然后把meet作为尾。此时转换为链表相交问题:head链表和newhead链表相交,求交点。
题十一:复制带随机指针的链表
题目描述:
给你一个长度为n的链表,每个结点包含一个额外增长的随机指针random,该指针可指向链表中的任何结点或空结点。
构造这个链表的深拷贝。深拷贝应该正好由n个全新结点组成,其中每个新结点的值都设为其对应的原结点的值。新结点的next指针和random指针也都应指向复制链表中的新结点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。
复制链表中的指针都不应指向原链表中的结点。
分析:
1.将每个copy结点链接在原结点cur的后面;

2.如果原结点的random是空,则copy结点的random就是空;如果原结点的random不为空,则copy结点的random等于原结点cur的random的next:copy->random=cur->random->next;

3.把拷贝结点copy解下来,链接到一起,恢复原链表。
![]()

实现:
struct Node
{
int val;
struct Node* next;
struct Node* random;
};
struct Node* copyRandomList(struct Node* head)
{
struct Node* cur = head;
//将每个copy结点链接在原结点cur的后面
while (cur)
{
//创建新结点
struct Node* copy = (struct Node*)malloc(sizeof(struct Node));
copy->val = cur->val;
//将copy插入到cur的后面
copy->next = cur->next;
cur->next = copy;
//将cur移动到原链表的下一个结点
cur = copy->next;
}
//如果原结点的random是空,则copy结点的random就是空
//如果原结点的random不为空,则copy结点的random等于原结点cur的random的next:copy->random=cur->random->next
cur = head;
while (cur)
{
struct Node* copy = cur->next;
if (cur->random == NULL)
{
copy->random = NULL;
}
else
{
copy->random = cur->random->next;//指向原结点cur后的copy结点
}
cur = copy->next;
}
//把拷贝结点copy解下来,链接到一起,恢复原链表
cur = head;
struct Node* copyHead = NULL, * copyTail = NULL;
while (cur)
{
struct Node* copy = cur->next;
struct Node* next = copy->next;
//尾插
if (copyTail == NULL)
{
//链表为空
copyHead = copyTail = copy;
}
else
{
//链表不为空
copyTail->next = copy;
copyTail = copyTail->next;
}
//恢复原结点
cur->next = next;
cur = next;
}
return copyHead;
}