MMU的产生背景
在计算机出现的早期,其内存资源十分有限,一般只有几十几百KB,当时的程序规模也小,对于当时的程序而言,KB级的内存资源尚足够使用。但随着计算机技术的发展,应用程序的规模不断膨胀,一个难题终于出现在程序员的面前,即应用程序太大,内存已经容纳不下。
最初解决该问题的办法是把程序分割成许多分称为覆盖块(overlay)的片段。覆盖块0首先运行,结束时调用另一个覆盖块继续运行。
虽然覆盖块的交换是由OS 完成的,但是必须先由程序员先进行分割,这是一个费时费力的工作,而且相当枯燥。
人们必须找到更好的办法从根本上解决这个问题。
不久人们找到了一个办法,这就是虚拟存储器(virtual memory)。
虚拟内存器(Virtual Memory)
虚拟内存器的基本思想是:
程序、数据、堆栈的总大小可以超过物理存储器的大小,操作系统把当前使用的部分保留在内存中,而把其他未被使用的部分保存在磁盘上。
比如,对一个16MB 的程序和一个内存只有4MB的机器,OS通过选择,可以决定各个时刻将哪4MB的内容保留在内存中,并在需要时在内存和磁盘间交换程序片段,这样就可以把这个16MB的程序运行在一个具有4MB内存机器上了。而这个16M的程序在运行前不必由程序员进行分割。
任何时候,计算机上都存在一个程序能够产生的地址集合,我们称之为地址范围。
这个范围的大小由CPU 的位数决定,例如:
一个32位的CPU ,它的地址范围是0x0 ~ 0xFFFF FFFF (4G),
而对于一个64位的CPU ,它的地址范围为0x0 ~ 0xFFFF FFFF FFFF FFFF (64T)。
这个范围就是我们程序能够产生的地址范围,我们把这个地址范围称为虚拟地址空间,该空间中的某一个地址我们称之为虚拟地址。
与虚拟地址空间和虚拟地址相对应的则是物理地址空间和物理地址,大多数时候,我们的系统所具备的物理地址空间只是虚拟地址空间的一个子集,举一个最简单的例子直观的说明这两者的区别,对于一台内存为256MB的32Bit x86主机来说,它的虚拟地址空间范围是0x0 ~ 0xFFFF FFFF (4G),而物理地址空间范围是0x0000 0000 ~ 0x0FFF FFFF ( 256MB )。
在没有使用虚拟地址的机器上,虚拟地址被直接送到内存总线上,使具有相同地址的物理存储被读写。而使用了虚拟存储的情况下,虚拟地址不是被直接送到内存地址总线上,而是送到内存管理单元— MMU。
MMU由一个或一组芯片组成,一般存在于协处理器中,其功能是把虚拟地址映射为物理地址。

- CPU 看到的是 Virtual Adress (程序中的逻辑地址)
- Caches 和 MMU 使用的是 MVA (实际的虚拟地址 MVA = (pid << 25) | VA)
- 实际物理设备使用的是 Physical Address (物理地址)
MMU的工作过程
大多数使用虚拟存储器的系统都使用一种称为分页(paging)。
虚拟地址空间划分为页(page)的单位,而相应的物理地址空间也被进行划分,单位是页框(frame)。
页和页框的大小必须相同。
接下来配合图片,以一个例子说明页与页框之间在MMU 的调度下是如何进行映射的:

在这个例子中,我们有一个可以生成16位地址的机器,它的虚拟地址范围从0x0000 ~ 0xFFFF(64k),而这台机器只有32K的物理地址,因此它可以运行64K的程序,但该程序不能一次性调入内存运行。
这台机器必须有一个达到可以存放64K程序的外部存储器(例如磁盘或Flash)以保证程序片段在需要时可以被调用。
这个例子中,页的大小为64K,页框大小与页相同(这点必须保证的,内存和外围存储器之间传输总是以页为单位),对 应64K的虚拟地址和32K的物理存储器,它们分别包含了16个页 和 8个页框。
执行下面这些指令:
MOVE REG,0// 将 0 号地址的值传递进寄存器 REG虚拟地址 0 将被送往MMU,MMU看到该虚拟地址落在页 0 范围内(页0范围是0到4095),从上图我们可以看出页0所对应的(映射)的页框为2(页框2的地址范围是8192 到 12287)。
因此,MMU将该虚拟地址转化为物理地址8192, 并把地址8192送到地址总结上。
内存对MMU的映射一无所知,它只看到一个对地址8192的读请求并执行它,MMU从而将8192到 12287换虚拟地址解析为对应的物理地址0到4096 。
MOVE REG , 20500
被转换为----> MOVE REG, 12308因为虚拟地址20500 在虚页5(虚拟地址范围是20480到24575)距开头20个字节处,虚页5映射到页框3(页框3的地址范围是12288 到 16383),于是被映射到物理地址12288 + 20 = 12308。
MOV REG , 32780虚拟地址32780 落在页 8 的范围内,从上图我们看出,页8并没有被有效的进行映射(该页被打上X),这时又会发生什么呢?
MMU注意到这个页没有被映射,于是通知CPU发生了一个缺页故障(page fault),这种情况下,操作系统必须处理这个页故障,它必须从8个物理页框中找到一个很少被使用的页框,并把该页框的内容写入外围存储器(这个动作被称为page copy),随后把需要引用的页(本例是页8)映射到刚才被释放的页框中(这个动作被称为修改映射关系),然后重新执行产生故障的指令(MOV REG, 32780)。
假定操作系统,决定释放页框1,以使以后任何对虚拟地址4K到8K的访问都引起故障而使操作系统做出适当的动作。
其次它把虚页8对应的页框号由X变为1,因此得新执行MOV REG, 32780,MMU将32780 映射为 4180。
我们已经知道,大多数使用虚拟存储器的系统都使用一种称为分页(paging)的技术,就像我们刚才所举的例子,虚拟地址空间被分为大小相同的一组页,每个页有一个用来标示它的页号(这个页号一般是它在该组中的索引,这点和C/C++中的数组相似)。
在上面的例子中0~4K的页号为0,4~8K的页号为1,8~12K的页号为2,以此类推。
而虚拟地址(注意:是一个确定的地址,不是一个空间)被MMU分为2个部分,第一部分是页号索引(page Index),第二部分则是相对该页首地址的偏移量(offset)。
我们还是以刚才那个16位机器结合下图进行一个实例说明,该实例中,虚拟地址8196被送进MMU,MMU把它映射成物理地址。16位的CPU总共能产生的地址范围是0~64K,按每页4K的大小计算,该空间必须被分成16个页。而我们的虚拟地址第一部分所能够表达的范围也必须等于16(这样才能索引到该页组中的每一个页),也就是说这个部分至少需要4个bit。
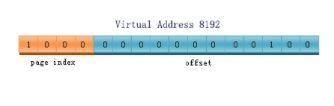
该地址的页号索引为0010(二进制码),即索引的页为页2,第二部分为000000000100(二进制),偏移量为4。
页2中的页框号为6(页2映射在页框6,见上图),我们看到页框6的物理地址是24~28K。于是MMU计算出虚拟地址8196应该被映射成物理地址24580(页框首地址+偏移量=24576+4=24580)。
同样的,若我们对虚拟地址1026进行读取,1026的二进制码为0000010000000010,page index="0000"=0,offset=010000000010=1026。
页号为0,该页映射的页框号为2,页框2的物理地址范围是8192~12287,故MMU将虚拟地址1026映射为物理地址9218(页框首地址+偏移量=8192+1026=9218)。
以上就是MMU的工作过程。
虚拟内存管理
现代操作系统普遍采用虚拟内存管理(Virtual Memory Management)机制,这需要处理器中的MMU(Memory Mangement Unit,内存管理单元)提供支持。
首先引入两个概念,虚拟地址和物理地址。
- 如果处理器没有MMU,或者有MMU但没有启用,CPU执行单元发出的内存地址将直接传到芯片引脚上,被物理内存芯片接收,这称为物理地址。
- 如果处理器启用了MMU,CPU执行单元发出的内存地址将被 MMU 截获,从CPU到MMU的地址称为虚拟地址,而MMU 将这个地址翻译成另一个地址,发到CPU芯片的外部地址引脚上,也就是将VA映射成了PA 了。
如果是32位处理器, 则内存地址总线是32位的,与CPU 执行单元相连,而经过MMU转换后的外地址总线则不一定是32位。
也就是说,虚拟地址空间与物理地址空间是独立的,32位处理器的虚拟地址空间是4GB,而物理地址空间既可以大于也可以小于4G。
MMU将VA映射到PA是以页(page)为单位的,32位处理器的页尺寸通常是4KB。
例如:
MMU可以通过一个映射项将VA的一页0xB7001000 - 0xB7001FFFF映射到PA的一页0x2000 ~ 0x2FFF。
如果CPU执行单元要访问虚拟地址0xB7001008,则实际访问到的物理地址是0x2008。
物理内存中的页称为物理页帧(page frame),虚拟内存的哪个页面映射到物理内存的哪个页帧是通过页表(Page Table)来描述的,页表保存在物理内存中,MMU会查找页表来确定一个VA应该映射到什么PA。
操作系统和 MMU 是这样配合的:操作系统在初始化或分配、释放内存时会执行一些指令在物理内存中填写页表,然后用指令设置MMU,告诉MMU页表在物理内存中的什么位置。
设置好之后,CPU 每次执行访问内存的指令都会自动引发MMU做查表和地址转换操作,地址转换操作由硬件自动完成,不需要用指令控制MMU去做。
我们在程序中使用的变量和函数都有各自的地址,程序被编译后,这些地址就成了指令中的地址,指令中的地址被CPU解释执行,就成了CPU的执行单元发出的内存地址,所以在启用MMU的情况下,程序中使用的地址都是虚拟地址,都会引发MMU做查表和地址转主换操作。
那为什么要设计这么复杂的内存管理机制呢? 多了一层 VA 到 PA 的转换到底换来什么好处?
MMU除了做地址转换之外,还提供内存保护机制,各种体系结构都有用户模式(User Mode)和特权模式(Privileged Mode)之分,操作系统可以在页表中设置每个内存页面的访问权限,有些页面不允许访问,有些页面只有在CPU 处于特权模式时才允许访问,有些页面在用户模工和特权模式都可以访问,访问权限又分为可读、可写 和可执行三种。
这样设定好之后,当CPU要访问一个 VA 时,MMU都会检查CPU当前处于用户模式还是特权模式,访问内存的目的是读数据、写数据、还是取指令,如果和操作系统设定的页面权限相符,就允许访问,把它转换成PA ;如果不允许访问,就产生一个异常(Exception)。
异常处理过程和中断类似,不同的是中断由外部设备产生而异常由CPU内部产生,中断产生的原因和CPU当前执行的指令无关,而异常的产生就是由于CPU当前执行的指令出了问题,例如,访问内存的指令被 MMU 检查出权限错误,除法指令的除数为0都会产生异常。
用户空间和内核空间
通常操作系统把虚拟地址划分为用户空间和内核空间,例如X86平台的Linux 系统虚拟地址空间是0x00000000 - 0xFFFFFFFF,前3GB(0x00000000 - 0xBFFFFFFF)是用户空间,后1GB(0xC0000000 - 0xFFFFFFFF)是内核空间。
用户程序加载到用户空间,在用户模式下执行,不能访问内核中的数据,也不能跳转到内核代码中执行。
这样可以保护内核,如果一个进程访问了非法地址,顶多这一个进程崩溃,而不会影响到内核和整个系统的稳定性。
CPU在产生中断和异常时不仅会跳转到中断或异常服务程序,还会自动切换模式,从用户模式切换到特权模式,因此从中断或异常服务程序可以跳转到内核代码中执行。
事实上,整 个内核就是由各种中断和异常处理程序组成的。
总结下:
在正常情况下 ,处理器在用户模式执行用户程序,在中断或异常情况下处理器切换到特权模式执行内核程序,处理完中断或异常之后再返回用户模式继续执行用户程序。
段错误
段错误是这样产生的:用户程序要访问一个VA, 经MMU检查无权访问,MMU产生一个异常,CPU从用户模式切换到特权模式,跳转到内核代码中执行异常服务程序。内核把这个异常解释为段错误,把相发异常的进程终止掉。







![[数学建模] [2019年A 模拟练习][层次分析法、熵值法、多目标优化、主成分分析法] 4. 深圳居民健康水平评估与测控模型研究](https://img-blog.csdnimg.cn/45b69d3ab4964bafa99bbb8122c93785.png#pic_center)