以下内容来自系统教程如何搞定单目/鱼眼/双目/阵列 相机标定?
点击领取相机标定资料和代码
为什么需要对相机标定? 我们所处的世界是三维的,而相机拍摄的照片却是二维的,丢失了其中距离/深度的信息。从数学上可以简单理解为,相机本身类似一个映射函数,其将输入的场景,通过某种关系映射为一张RGB图片,即  而相机标定,就是使用数学模型和数学方法来近似逼近这一复杂映射函数的过程。标定后的相机即具有了描述这一过程的能力,从而可以用于各种计算机视觉的任务,如深度恢复、三维重建等,本质上都是对丢失的距离信息的恢复。
而相机标定,就是使用数学模型和数学方法来近似逼近这一复杂映射函数的过程。标定后的相机即具有了描述这一过程的能力,从而可以用于各种计算机视觉的任务,如深度恢复、三维重建等,本质上都是对丢失的距离信息的恢复。 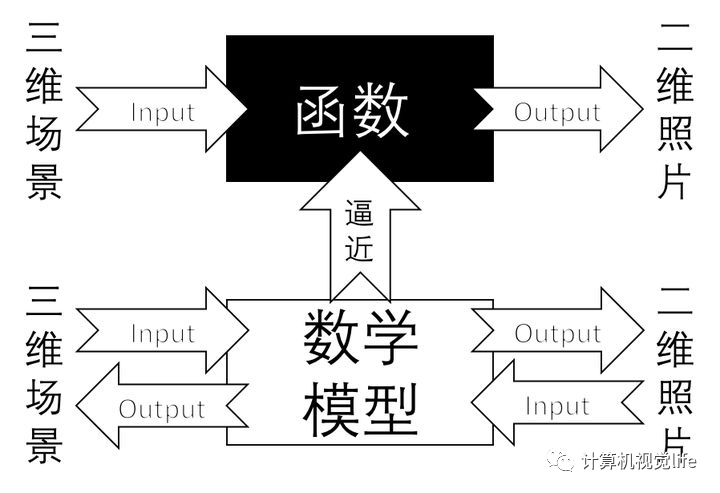 为什么说是逼近,因为我们永远也不可能百分之百得知一个真实的相机是如何投影图像的
为什么说是逼近,因为我们永远也不可能百分之百得知一个真实的相机是如何投影图像的
相机标定到底在标什么? 机器视觉中,需要标定的应用场景可以简单分为如下几类:
单目视觉应用,如单帧测距、车载 ADAS 辅助、单目SLAM等 这类应用,我们通常需要相机自身的成像模型参数以及相机相对某个坐标系下的相对位姿。
比如下图简单场景,我们知道相机的朝向以及和地面的高度,就可以大致估计出相机某个像素对应物体的距离(物体高度已知或贴近地面) 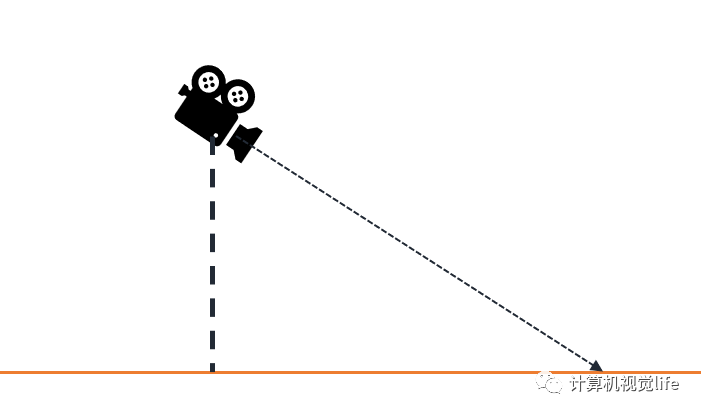 这种模型在一些简单的车载的任务上比较常见,比如推测前车距离
这种模型在一些简单的车载的任务上比较常见,比如推测前车距离
再如工业上比较常见的机器人控制,需要构建机器人坐标系和其视觉坐标系之间的相对位置关系(也就是手眼标定) 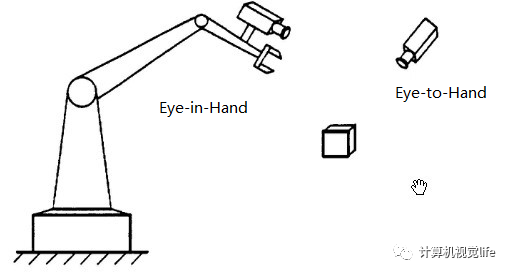 再比如单目深度恢复,一些传统的单目深度恢复通常使用固定尺寸的物体作为标志物,之后移动物体,通过相机中物体大小来判断实际的拍摄距离。
再比如单目深度恢复,一些传统的单目深度恢复通常使用固定尺寸的物体作为标志物,之后移动物体,通过相机中物体大小来判断实际的拍摄距离。 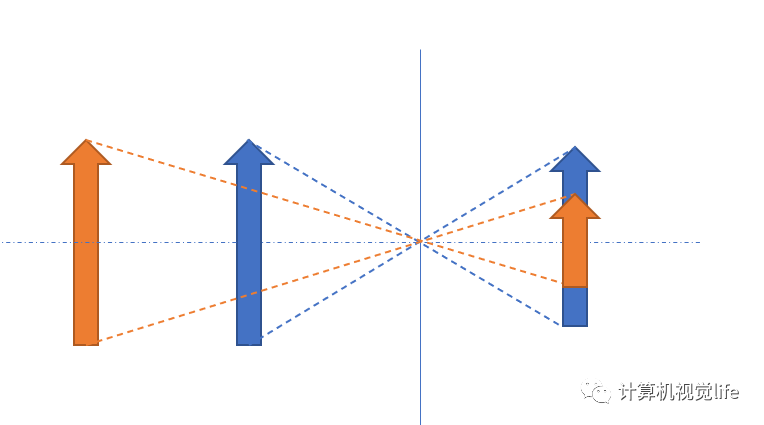 再比如大家熟知的一些SLAM方法
再比如大家熟知的一些SLAM方法 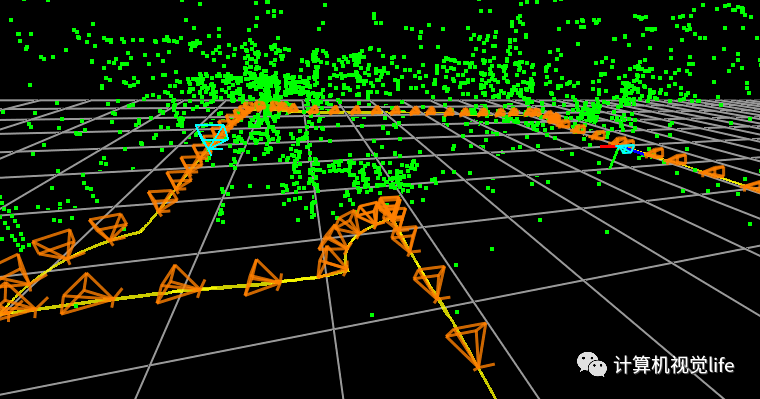 目前有一些自监督的深度学习方法也会使用相对姿态信息作为监督,比如最近的 ManyDepth:
目前有一些自监督的深度学习方法也会使用相对姿态信息作为监督,比如最近的 ManyDepth: 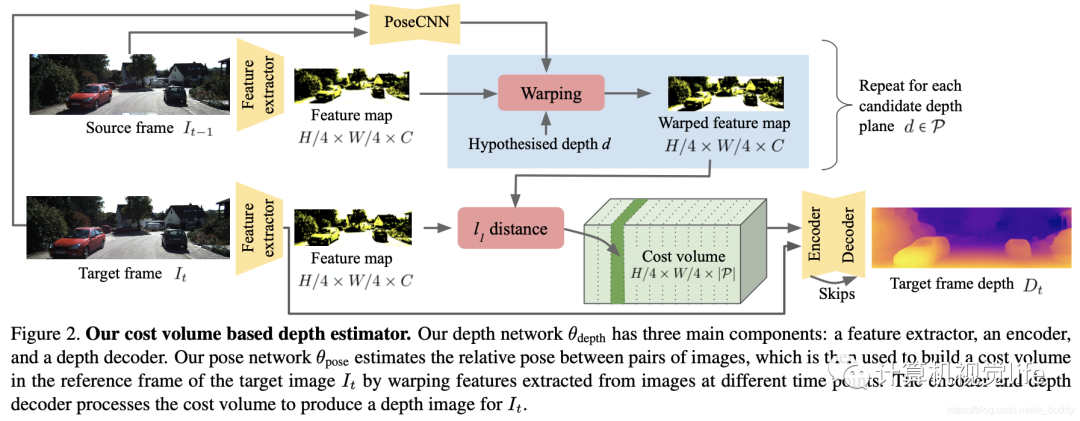 双目/多目/RGB-D组合 这类应用更加常见,我们需要获取相机自身信息,以及各个相机之间的相对位姿关系,有时也需要获取其和某固定坐标系之间的关系,举几个例子:
双目/多目/RGB-D组合 这类应用更加常见,我们需要获取相机自身信息,以及各个相机之间的相对位姿关系,有时也需要获取其和某固定坐标系之间的关系,举几个例子:
如车载全景环视(图片来自网络) 我们需要获取四个相机相对位姿以及其和地面坐标系的关系,才能得到最终的全景拼接结果(图片来自网络)。
再如AR应用  或者更复杂的相机阵列
或者更复杂的相机阵列  标定方法简述 目前相机标定方法主要分为三类:
标定方法简述 目前相机标定方法主要分为三类: 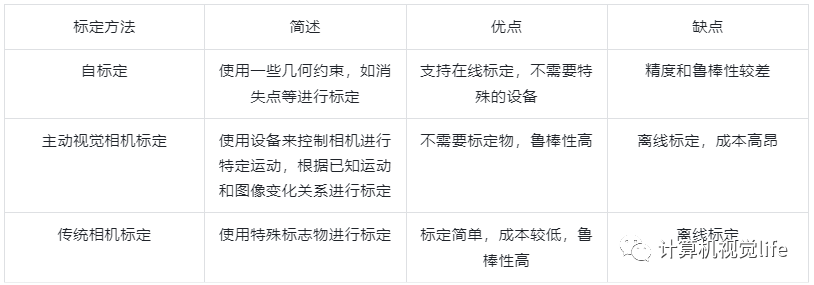 而传统相机标定中张正友标定法仅使用一个规格已知的平面标定板进行标定,制作成本较低,因此是目前主流的标定方案。
而传统相机标定中张正友标定法仅使用一个规格已知的平面标定板进行标定,制作成本较低,因此是目前主流的标定方案。
张正有标定操作步骤 张正友标定方案使用平面标志物,通常是规整的棋盘格或者点阵图,如下  当然,通常情况下为了方便区分图片中棋盘格朝向,我们一般使用宽高不同的棋盘格。
当然,通常情况下为了方便区分图片中棋盘格朝向,我们一般使用宽高不同的棋盘格。
将标志物打印后,使用待标定相机拍摄不同角度多组标定图案  ,三张图片就可以完成标定,但是为了减小标定误差,拍摄图片会稍微多一些
,三张图片就可以完成标定,但是为了减小标定误差,拍摄图片会稍微多一些
标定图案需要保证平整 每张图片中标志物尽量占据画面1/4以上,不同标定板角度尽量存在一个相对明显的旋转和平移 拍摄时应尽量保证相机参数不变 这里主要是焦距不变,焦距变化会导致部分fov变化,从而影响几乎全部的标定参数。当然,大多数场景中相机本身焦距都是固定的,而消费级,如手机镜头由于其本身畸变不大,且焦距较短,因此影响会比较小。
拍摄图案的总和需要覆盖整个画面 由于圆点在模糊情况不会改变其中心点位置,精度理论上会更好一些
拍摄图案的总和需要覆盖整个画面 我们知道标定本身可以理解为一个拟合各个像素位置成像的过程,如果覆盖不完全,就会导致某些区域像素处于无约束状态,从而出现标定错误。我们常见的图片去畸变后边缘扭曲大多是该原因导致的。
使用标定工具进行标定计算 不同标定板的优缺点 以下部分图片来自数据来自文章 Accurate camera calibration using iterative refinement of control points
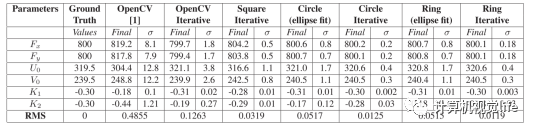 棋盘格本身存在角点检测不精确的问题
棋盘格本身存在角点检测不精确的问题  如角点边缘并不一定满足正交的要求,而这是亚像素角点提取的一种要求。
如角点边缘并不一定满足正交的要求,而这是亚像素角点提取的一种要求。
圆点检测更精确,但是会存在偏心误差  AprilTag 如果部分被遮挡也是可用的
AprilTag 如果部分被遮挡也是可用的  以上内容来自系统教程如何搞定单目/鱼眼/双目/阵列 相机标定?
以上内容来自系统教程如何搞定单目/鱼眼/双目/阵列 相机标定?
本文由博客一文多发平台 OpenWrite 发布!