卡塔尔世界杯,究竟谁能捧起大力神杯,就让我们用机器学习预测一下吧!

文章目录
- 数据源
- 技术提升
- 数据集构建
- 功能开发
- 数据分析
- 模型
- 世界杯模拟
- 结论
数据源
为了构建机器学习模型,我们需要来自团队的数据。首先需要一些能够说明球队表现的信息,这些信息可以从之前的比赛中提取出来。此外,在构建功能时使用 FIFA 排名。它们将有助于量化球队在比赛中面对对手的素质。这两个数据都可以在 Kaggle 上找到。
技术提升
本文由技术群粉丝分享,项目源码、数据、技术交流提升,均可加交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友
方式①、添加微信号:dkl88191,备注:来自CSDN +研究方向
方式②、微信搜索公众号:Python学习与数据挖掘,后台回复:加群
数据集构建
哪些特征可以影响足球比赛的胜负?这个问题有一个非常开放的答案。从选定的球员到当天球场的温度,一切都会对结果产生影响。然后,这里选择仅使用参与比赛的每个团队的过去统计数据构建一个数据集,优先考虑可以通过简单方式收集的可量化统计数据,例如进球数、平均排名、赢得的分数以及其他将详细点。
此外,将仅分析 2022 年世界杯周期的表现。这个想法是只考虑世界杯备战中表现的变化。
import pandas as pd
import re
df = pd.read_csv("games/results.csv") #games between national teams
df["date"] = pd.to_datetime(df["date"])
df = df[(df["date"] >= "2018-8-1")].reset_index(drop=True) #games at the 2022 wc cycle
df_wc = df #pre-wc outcomes
rank = pd.read_csv("fifa_ranking-2022-10-06.csv") #rankings
rank["rank_date"] = pd.to_datetime(rank["rank_date"])
rank = rank[(rank["rank_date"] >= "2018-8-1")].reset_index(drop=True) #selecting games from the 2022 wc cycle
rank["country_full"] = rank["country_full"].str.replace("IR Iran", "Iran").str.replace("Korea Republic", "South Korea").str.replace("USA", "United States") #ajustando nomes de algumas seleções
rank = rank.set_index(['rank_date']).groupby(['country_full'], group_keys=False).resample('D').first().fillna(method='ffill').reset_index()
rank_wc = rank #dataframe with rankings
#Making the merge
df_wc_ranked = df_wc.merge(rank[["country_full", "total_points", "previous_points", "rank", "rank_change", "rank_date"]], left_on=["date", "home_team"], right_on=["rank_date", "country_full"]).drop(["rank_date", "country_full"], axis=1)
df_wc_ranked = df_wc_ranked.merge(rank[["country_full", "total_points", "previous_points", "rank", "rank_change", "rank_date"]], left_on=["date", "away_team"], right_on=["rank_date", "country_full"], suffixes=("_home", "_away")).drop(["rank_date", "country_full"], axis=1)
以上是创建所需数据集的代码。

数据集
如上所示,数据集已准备就绪,还有更多关于客队的信息。重要的是要记住国家队之间的大部分比赛都是在中立场地进行的,但这里将使用“主队”和“客队”的名称来简化谈论所涉及球队的方式。
功能开发
现在,我们需要一组候选特征。有了它们,我们可以进行分析,表明该特征是否具有预测能力,以了解我们是否需要保留、删除或修改该特征。作为候选计算的特征是:
-
世界杯周期和最近 5 场比赛的平均进球数。
-
世界杯周期和最近 5 场比赛的平均进球数。
-
每支球队之间的 FIFA 排名位置差异。
-
国际足联排名每支球队在世界杯周期比赛和最近 5 场比赛中平均面对。
-
从周期的第一场比赛到现在,FIFA 排名的积分增加。
-
FIFA 排名 5 场比赛前和现在的积分增加。
-
世界杯周期和最近 5 场比赛的平均局分。
-
根据世界杯周期和最近 5 场比赛中的排名位置加权平均赢得的比赛积分。
-
分类变量告诉游戏是否是友好的。
前两个特征用于量化一支球队的进攻力和防守力。国际足联在比赛中排名位置的差异是用来量化国际足联计算的两队实力的差异。面对平均排名用于分析球队面对的对手的实力。
国际足联排名积分的增加是为了分析世界杯周期和最近5场比赛中球队质量的增加。
球队的场均胜率是纯粹量化球队的表现,而球队的场均胜负加权平均是根据球队所面对的对手的排名位次进行加权,以分析球队的表现是否高对低水平的对手。
要基于 FIFA 排名构建特征,有两种选择:使用 FIFA 排名积分,或使用 FIFA 排名位置。除了排名的增加,我们选择在所有功能中使用排名位置。我们没有创建相同的功能,仅通过 FIFA 排名点改变 FIFA 排名位置,因为这些列是非常负相关的,如下所示。

那么,通过使用排名的分数和排名的位置来创建加权平均游戏积分等特征的两个版本是没有意义的,因为它们会产生相同的结果。
数据分析
在建模之前,需要分析将要预测的内容。然而,理想的预测是赢、平、输,一个 3 类分类问题很难分析和评估。然后,我们决定在两个类别之间进行预测:主队赢和主队平/输。
为了分析与目标相关的特征,我们将使用小提琴图和箱线图。这个想法是分析它们的分布如何与每个类的值相关,以及它们是否可以很好地分离数据。


第一组数据的小提琴图
对于第一组数据,已经创建的,只有rank_dif,两队排名的差值,对target classes有影响。因此将根据差异创建更多特征,因为它们似乎是很好的预测指标:
-目标差异。
-
遭遇净胜球。
-
球队进球与对手进球之间的差异。
我们再次分析了小提琴图。

小提琴图的新特点
目标的差异和目标的差异所遭受的特征有很好的影响。然而,映射球队进球与对手进球之间差异的特征没有影响。因此,我们现在:
-
排名差异。
-
世界杯周期和最近 5 场比赛的进球差异。
-
在世界杯周期和最近 5 场比赛中出现净胜球。
此外,我们还可以计算积分的差异、排名位置的差异以及排名所获得的积分差异。而且,为了衡量对手的水平,还考虑了以下特征:排名所造成的进球与所遭受的进球之间的差异。
由于规模小,用小提琴查看这些数据不是很有效。然后,再分析这些数据的箱线图。


Violin 和 Boxplot 的差异特征
积分差异、排名的进球差异、排名的积分差异和面临的排名差异是很好的特征。但是,他们最近 5 场比赛的版本和他们整个周期的版本似乎是相关的。我们会在下面检查这个。




特征的相关性 分析相关性可以看出,在排名做出的目标差异中,理想的是只选择其中一个版本,而这里选择了考虑全周期的版本。对于其他人,可以同时使用这两个版本。
然后,作为特征,我们有:
-
排名差异(rank_dif)
-
世界杯周期和过去 5 场比赛的平均进球数之间的差异 (goals_dif/goals_dif_l5)
-
世界杯周期和过去 5 场比赛平均进球数之间的差异 (goals_suf_dif/goals_suf_dif_l5)
-
世界杯周期和最近 5 场比赛的平均排名差异 (dif_rank_agst/dif_rank_agst_l5)
-
世界杯周期平均排名加权进球数之间的差异 (goals_per_ranking_dif)
-
世界杯周期和过去 5 场比赛中排名平均得分之间的差异 (dif_points_rank/dif_points_rank_l5)
-
表示是否友好的分类变量 (is_friendly) 这样,我们就有了一个数据库,其中包含应用机器学习模型所需的功能。
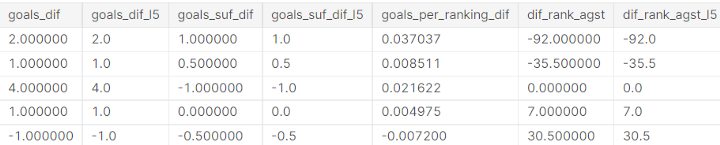
数据库的一些特性
模型
这里的想法是建立两个模型,一个是Random Forest,另一个是Gradient Boosting,比较一下哪个更好,以便在仿真中使用。这里决定使用基于决策树的模型,因为它们在足球问题上做得更好。此外,由于数据集的大小,不需要使用更复杂的模型。
我们将使用 SkLearn 的GridSearchCV进行参数变化,并将在模拟中使用最佳模型。
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.model_selection import train_test_split, GridSearchCV
#separating the target from the features
X = model_db.iloc[:, 3:]
y = model_db[["target"]]
#dividing the database
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size= 0.2, random_state=1)
gb = GradientBoostingClassifier(random_state=5)
params = {"learning_rate": [0.01, 0.1, 0.5],
"min_samples_split": [5, 10],
"min_samples_leaf": [3, 5],
"max_depth":[3,5,10],
"max_features":["sqrt"],
"n_estimators":[100, 200]
}
gb_cv = GridSearchCV(gb, params, cv = 3, n_jobs = -1, verbose = False)
gb_cv.fit(X_train.values, np.ravel(y_train))
#getting the best model
gb = gb_cv.best_estimator_
由于执行延迟,为了避免测试很多参数,优先测试具有减少过度拟合的值,例如 learning_rate 不太低和 n_estimators 不太高。
对随机森林做了同样的事情:
params_rf = {"max_depth": [20],
"min_samples_split": [5, 10],
"max_leaf_nodes": [175, 200],
"min_samples_leaf": [5, 10],
"n_estimators": [250],
"max_features": ["sqrt"],
}
rf = RandomForestClassifier(random_state=1)
rf_cv = GridSearchCV(rf, params_rf, cv = 3, n_jobs = -1, verbose = False)
rf_cv.fit(X_train.values, np.ravel(y_train))
我们用混淆矩阵和ROC曲线分析了模型,结果是:
analyze(gb)


梯度提升结果
analyze(rf)


随机森林结果
随机森林模型的性能稍好,但似乎过拟合。分析 Gradient Boosting 的 AUC-ROC,我们看到一个模型具有几乎相同的性能,但过度拟合的风险较低,这就是选择它的原因。
世界杯模拟
现在,我们到了最有趣的部分:看看模型将预测哪支球队赢得世界杯!

首先要做的是获取参加世界杯的球队名单,我们使用Pandas 的read_html方法。该方法从网页中获取数据框,将其放入维基百科世界杯页面。这样,我们将重新创建世界杯表。
该表包含比赛、小组中每支球队的得分以及存储球队赢得每场比赛的概率的列表。如果两支球队在小组中积分相同,这将用作决胜局。

创表前四组及世界杯前十场比赛正如已经解释过的,该模型对主队获胜和客队获胜/平局进行了分类。那么,我们如何预测平局呢?我们为此创建了一个客观规则:知道世界杯的所有比赛都是在中立场地进行的,预测将以两种形式进行:
-
A 队 x B 队(模拟 1)
-
B 队 x A 队(模拟 2)
如果两个预测都是 A 队或 B 队获胜,则将获胜分配给该队。如果一队在第一次预测中获胜,而另一队在第二次预测中获胜,则将被分配平局。季后赛阶段,将计算两次预测的概率,平均概率最高的球队晋级。由于模型将“胜利”分配给客队,即使平局也是如此,因此平局概率在客队的概率范围内。因此,通过这种类型的模拟,两支球队都获得了以平局为优势的模拟。
模拟使用的数据直到球队的最后一场比赛。换句话说,对于巴西来说,特征将计算到对阵突尼斯的比赛,这是巴西最后一场比赛。
现在,我们可以运行一个代码来逐场模拟比赛,计算分数并查看第一阶段发生的情况。
advanced_group = []
last_group = ""
for k in table.keys():
for t in table[k]:
t[1] = 0
t[2] = []
for teams in matches:
draw = False
team_1 = find_stats(teams[1])
team_2 = find_stats(teams[2])
features_g1 = find_features(team_1, team_2)
features_g2 = find_features(team_2, team_1)
probs_g1 = gb.predict_proba([features_g1])
probs_g2 = gb.predict_proba([features_g2])
team_1_prob_g1 = probs_g1[0][0]
team_1_prob_g2 = probs_g2[0][1]
team_2_prob_g1 = probs_g1[0][1]
team_2_prob_g2 = probs_g2[0][0]
team_1_prob = (probs_g1[0][0] + probs_g2[0][1])/2
team_2_prob = (probs_g2[0][0] + probs_g1[0][1])/2
if ((team_1_prob_g1 > team_2_prob_g1) & (team_2_prob_g2 > team_1_prob_g2)) | ((team_1_prob_g1 < team_2_prob_g1) & (team_2_prob_g2 < team_1_prob_g2)):
draw=True
for i in table[teams[0]]:
if i[0] == teams[1] or i[0] == teams[2]:
i[1] += 1
elif team_1_prob > team_2_prob:
winner = teams[1]
winner_proba = team_1_prob
for i in table[teams[0]]:
if i[0] == teams[1]:
i[1] += 3
elif team_2_prob > team_1_prob:
winner = teams[2]
winner_proba = team_2_prob
for i in table[teams[0]]:
if i[0] == teams[2]:
i[1] += 3
for i in table[teams[0]]: #adding criterio de desempate (probs por jogo)
if i[0] == teams[1]:
i[2].append(team_1_prob)
if i[0] == teams[2]:
i[2].append(team_2_prob)
if last_group != teams[0]:
if last_group != "":
print("\n")
print("Group %s advanced: "%(last_group))
for i in table[last_group]: #adding crieterio de desempate
i[2] = np.mean(i[2])
final_points = table[last_group]
final_table = sorted(final_points, key=itemgetter(1, 2), reverse = True)
advanced_group.append([final_table[0][0], final_table[1][0]])
for i in final_table:
print("%s -------- %d"%(i[0], i[1]))
print("\n")
print("-"*10+" Starting Analysis for Group %s "%(teams[0])+"-"*10)
if draw == False:
print("Group %s - %s vs. %s: Winner %s with %.2f probability"%(teams[0], teams[1], teams[2], winner, winner_proba))
else:
print("Group %s - %s vs. %s: Draw"%(teams[0], teams[1], teams[2]))
last_group = teams[0]
print("\n")
print("Group %s advanced: "%(last_group))
for i in table[last_group]: #adding crieterio de desempate
i[2] = np.mean(i[2])
final_points = table[last_group]
final_table = sorted(final_points, key=itemgetter(1, 2), reverse = True)
advanced_group.append([final_table[0][0], final_table[1][0]])
for i in final_table:
print("%s -------- %d"%(i[0], i[1]))
结果是:
---------- Starting Analysis for Group A ----------
Group A - Qatar vs. Ecuador: Winner Ecuador with 0.62 probability
Group A - Senegal vs. Netherlands: Winner Netherlands with 0.62 probability
Group A - Qatar vs. Senegal: Winner Senegal with 0.60 probability
Group A - Netherlands vs. Ecuador: Winner Netherlands with 0.73 probability
Group A - Ecuador vs. Senegal: Draw
Group A - Netherlands vs. Qatar: Winner Netherlands with 0.78 probability
Group A advanced:
Netherlands -------- 9
Senegal -------- 4
Ecuador -------- 4
Qatar -------- 0
---------- Starting Analysis for Group B ----------
Group B - England vs. Iran: Winner England with 0.62 probability
Group B - United States vs. Wales: Draw
Group B - Wales vs. Iran: Draw
Group B - England vs. United States: Winner England with 0.61 probability
Group B - Wales vs. England: Winner England with 0.64 probability
Group B - Iran vs. United States: Winner United States with 0.58 probability
Group B advanced:
England -------- 9
United States -------- 4
Wales -------- 2
Iran -------- 1
---------- Starting Analysis for Group C ----------
Group C - Argentina vs. Saudi Arabia: Winner Argentina with 0.79 probability
Group C - Mexico vs. Poland: Draw
Group C - Poland vs. Saudi Arabia: Winner Poland with 0.70 probability
Group C - Argentina vs. Mexico: Winner Argentina with 0.67 probability
Group C - Poland vs. Argentina: Winner Argentina with 0.71 probability
Group C - Saudi Arabia vs. Mexico: Winner Mexico with 0.71 probability
Group C advanced:
Argentina -------- 9
Poland -------- 4
Mexico -------- 4
Saudi Arabia -------- 0
---------- Starting Analysis for Group D ----------
Group D - Denmark vs. Tunisia: Winner Denmark with 0.68 probability
Group D - France vs. Australia: Winner France with 0.71 probability
Group D - Tunisia vs. Australia: Draw
Group D - France vs. Denmark: Draw
Group D - Australia vs. Denmark: Winner Denmark with 0.71 probability
Group D - Tunisia vs. France: Winner France with 0.69 probability
Group D advanced:
France -------- 7
Denmark -------- 7
Tunisia -------- 1
Australia -------- 1
---------- Starting Analysis for Group E ----------
Group E - Germany vs. Japan: Winner Germany with 0.62 probability
Group E - Spain vs. Costa Rica: Winner Spain with 0.76 probability
Group E - Japan vs. Costa Rica: Winner Japan with 0.63 probability
Group E - Spain vs. Germany: Draw
Group E - Japan vs. Spain: Winner Spain with 0.67 probability
Group E - Costa Rica vs. Germany: Winner Germany with 0.65 probability
Group E advanced:
Spain -------- 7
Germany -------- 7
Japan -------- 3
Costa Rica -------- 0
---------- Starting Analysis for Group F ----------
Group F - Morocco vs. Croatia: Winner Croatia with 0.58 probability
Group F - Belgium vs. Canada: Winner Belgium with 0.75 probability
Group F - Belgium vs. Morocco: Winner Belgium with 0.67 probability
Group F - Croatia vs. Canada: Winner Croatia with 0.64 probability
Group F - Croatia vs. Belgium: Winner Belgium with 0.64 probability
Group F - Canada vs. Morocco: Draw
Group F advanced:
Belgium -------- 9
Croatia -------- 6
Morocco -------- 1
Canada -------- 1
---------- Starting Analysis for Group G ----------
Group G - Switzerland vs. Cameroon: Winner Switzerland with 0.69 probability
Group G - Brazil vs. Serbia: Winner Brazil with 0.72 probability
Group G - Cameroon vs. Serbia: Winner Serbia with 0.66 probability
Group G - Brazil vs. Switzerland: Draw
Group G - Serbia vs. Switzerland: Winner Switzerland with 0.57 probability
Group G - Cameroon vs. Brazil: Winner Brazil with 0.81 probability
Group G advanced:
Brazil -------- 7
Switzerland -------- 7
Serbia -------- 3
Cameroon -------- 0
---------- Starting Analysis for Group H ----------
Group H - Uruguay vs. South Korea: Winner Uruguay with 0.62 probability
Group H - Portugal vs. Ghana: Winner Portugal with 0.81 probability
Group H - South Korea vs. Ghana: Winner South Korea with 0.76 probability
Group H - Portugal vs. Uruguay: Winner Portugal with 0.60 probability
Group H - Ghana vs. Uruguay: Winner Uruguay with 0.77 probability
Group H - South Korea vs. Portugal: Winner Portugal with 0.67 probability
Group H advanced:
Portugal -------- 9
Uruguay -------- 6
South Korea -------- 3
Ghana -------- 0
看到一些结果很有趣,比如巴西和瑞士以及丹麦和法国之间的平局。总的来说,夺冠热门在小组赛阶段就过关了。
在季后赛中,思路是一样的:
advanced = advanced_group
playoffs = {"Round of 16": [], "Quarter-Final": [], "Semi-Final": [], "Final": []}
for p in playoffs.keys():
playoffs[p] = []
actual_round = ""
next_rounds = []
for p in playoffs.keys():
if p == "Round of 16":
control = []
for a in range(0, len(advanced*2), 1):
if a < len(advanced):
if a % 2 == 0:
control.append((advanced*2)[a][0])
else:
control.append((advanced*2)[a][1])
else:
if a % 2 == 0:
control.append((advanced*2)[a][1])
else:
control.append((advanced*2)[a][0])
playoffs[p] = [[control[c], control[c+1]] for c in range(0, len(control)-1, 1) if c%2 == 0]
for i in range(0, len(playoffs[p]), 1):
game = playoffs[p][i]
home = game[0]
away = game[1]
team_1 = find_stats(home)
team_2 = find_stats(away)
features_g1 = find_features(team_1, team_2)
features_g2 = find_features(team_2, team_1)
probs_g1 = gb.predict_proba([features_g1])
probs_g2 = gb.predict_proba([features_g2])
team_1_prob = (probs_g1[0][0] + probs_g2[0][1])/2
team_2_prob = (probs_g2[0][0] + probs_g1[0][1])/2
if actual_round != p:
print("-"*10)
print("Starting simulation of %s"%(p))
print("-"*10)
print("\n")
if team_1_prob < team_2_prob:
print("%s vs. %s: %s advances with prob %.2f"%(home, away, away, team_2_prob))
next_rounds.append(away)
else:
print("%s vs. %s: %s advances with prob %.2f"%(home, away, home, team_1_prob))
next_rounds.append(home)
game.append([team_1_prob, team_2_prob])
playoffs[p][i] = game
actual_round = p
else:
playoffs[p] = [[next_rounds[c], next_rounds[c+1]] for c in range(0, len(next_rounds)-1, 1) if c%2 == 0]
next_rounds = []
for i in range(0, len(playoffs[p])):
game = playoffs[p][i]
home = game[0]
away = game[1]
team_1 = find_stats(home)
team_2 = find_stats(away)
features_g1 = find_features(team_1, team_2)
features_g2 = find_features(team_2, team_1)
probs_g1 = gb.predict_proba([features_g1])
probs_g2 = gb.predict_proba([features_g2])
team_1_prob = (probs_g1[0][0] + probs_g2[0][1])/2
team_2_prob = (probs_g2[0][0] + probs_g1[0][1])/2
if actual_round != p:
print("-"*10)
print("Starting simulation of %s"%(p))
print("-"*10)
print("\n")
if team_1_prob < team_2_prob:
print("%s vs. %s: %s advances with prob %.2f"%(home, away, away, team_2_prob))
next_rounds.append(away)
else:
print("%s vs. %s: %s advances with prob %.2f"%(home, away, home, team_1_prob))
next_rounds.append(home)
game.append([team_1_prob, team_2_prob])
playoffs[p][i] = game
actual_round = p
为了在此处查看结果,除了文本输出之外,我们决定像在这个 Kaggle 笔记本中那样用淘汰赛图片绘制图表。这是查看这些问题结果的一种非常有趣的方式。
----------
Starting simulation of Round of 16
----------
Netherlands vs. United States: Netherlands advances with prob 0.54
Argentina vs. Denmark: Argentina advances with prob 0.59
Spain vs. Croatia: Spain advances with prob 0.61
Brazil vs. Uruguay: Brazil advances with prob 0.64
Senegal vs. England: England advances with prob 0.64
Poland vs. France: France advances with prob 0.67
Germany vs. Belgium: Belgium advances with prob 0.53
Switzerland vs. Portugal: Portugal advances with prob 0.57
----------
Starting simulation of Quarter-Final
----------
Netherlands vs. Argentina: Netherlands advances with prob 0.51
Spain vs. Brazil: Brazil advances with prob 0.54
England vs. France: England advances with prob 0.51
Belgium vs. Portugal: Portugal advances with prob 0.52
----------
Starting simulation of Semi-Final
----------
Netherlands vs. Brazil: Brazil advances with prob 0.55
England vs. Portugal: England advances with prob 0.51
----------
Starting simulation of Final
----------
Brazil vs. England: Brazil advances with prob 0.56
模拟世界杯!模型预测巴西队获胜,决赛中对阵英格兰队的概率为 56%!最大的冷门可能是比利时击败德国和英格兰进入决赛,在四分之一决赛中淘汰法国。看到一些概率非常小的比赛很有趣,比如荷兰对阿根廷。从四分之一决赛到决赛,没有一支球队晋级的概率超过60%,这说明晋级季后赛的球队大多水平相近。

淘汰赛阶段
结论
根据我们的预测,巴西会夺得冠军。但究竟花落谁家呢?就让我们拭目以待吧!