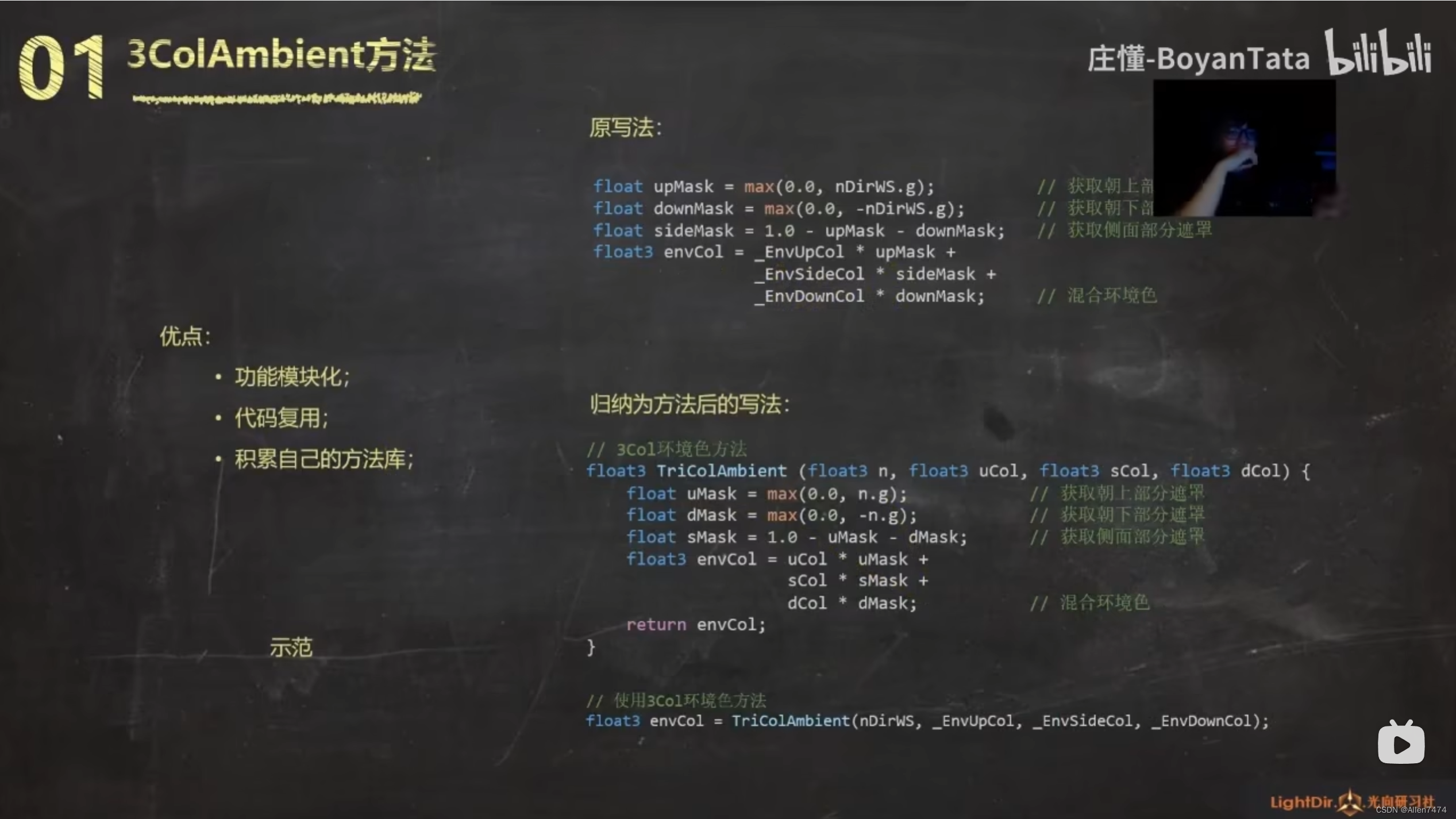
基础IO
- 🏞️1. 系统文件I/O
- 📖1.1 接口介绍
- 📖1.2 creat系统调用
- 📖1.3 理解fd文件描述符
- 📖1.4 不按顺序的读取和写入
- 📖1.5 文件重命名
- 🌁2. 理解Linux下一切皆文件
- 🌠3. 理解重定向
- 📖3.1 重定向原理
- 📖3.2 dup2系统调用
- 🌿4. 理解缓冲区
- 📖4.1 什么是缓冲区
- 📖4.2 为什么要有缓冲区?
- 📖4.3 缓冲区存在哪里?
- 🍁5. 硬链接和软链接
🏞️1. 系统文件I/O
📖1.1 接口介绍
操作文件,除了语言级别的接口,我们还可以采用系统接口来进行文件访问.
open()接口介绍:
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
pathname:要打开或者创建的目标文件
flags:打开文件时,可以传入多个参数选项,用下面的一个或者多个常量进行"或"运算,构成flags.
选项:
O_RDONLY:只读打开
O_WRONLY:只写打开
O_RDWR:读、写打开,这三个常量,必须指定一个且只能指定一个
O_CREAT:若文件不存在,则创建它,需要指明mode选项,来指明新文件的访问权限
O_APPEND:追加写

返回值:
成功:新打开的文件描述符
失败:-1
介绍了这个接口之后,让我们先来简单使用一下它:
int fd = open("test.txt", O_CREAT | O_WRONLY | O_TRUNC);
函数open()接受一些不同的标志. 在本例中,程序创建文件(O_CREAT),只能写入该文件,因为以(O_WRONLY)这种方式打开,并且如果该文件已经存在,则首先将其截断为0字节大小,删除所有现有内容(O_TRUNC).
write()系统调用:
ssize_t write(int fd, const void *buf, size_t count);
int main()
{
int fd = open("test.txt", O_WRONLY | O_CREAT | O_TRUNC);
ssize_t s = write(fd, "aaa", 3);
close(fd);
return 0;
}
read()的第一个参数是文件描述符,从而告诉文件系统读取哪个文件,一个进程当然可以同时打开多个文件,因此文件描述符fd使操作系统能够知道某个特定的读取引用了哪个文件.
第二个参数指向一个用于放置read()结果的缓冲区.
第三个参数是缓冲区的大小.
📖1.2 creat系统调用
补充:creat()系统调用
创建文件的旧方法是调用creat(),如下所示:
int fd = creat("foo");
你可以认为creat()是open()加上以下标志:O_CREAT | O_WRONLY | O_TRUNC,因为open()可以创建一个文件,所以creat()的用法有些失宠(实际上,它可能就是实现对open()的一个库调用),然而,它确实在UNIX知识中占有一席之地.
📖1.3 理解fd文件描述符
open()的一个重要方面是它的返回值:文件描述符.
文件描述符只是一个整数,是每个进程私有的,在Linux系统中用于访问文件,因此,一旦文件被打开,你就可以使用文件描述符来读取或写入文件,假如你有权这样做.
那么,我们所,open()系统调用的返回值是文件描述符,不妨我们将它打印出来看看:

观察结果为:3
接下来,不妨我们多创建几个文件看看:
int main()
{
int fd1 = open("test1.txt", O_WRONLY | O_CREAT | O_TRUNC);
int fd2 = open("test2.txt", O_WRONLY | O_CREAT | O_TRUNC);
int fd3 = open("test3.txt", O_WRONLY | O_CREAT | O_TRUNC);
int fd4 = open("test4.txt", O_WRONLY | O_CREAT | O_TRUNC);
int fd5 = open("test5.txt", O_WRONLY | O_CREAT | O_TRUNC);
printf("fa1: %d\n", fd1);
printf("fa2: %d\n", fd1);
printf("fa3: %d\n", fd1);
printf("fa4: %d\n", fd1);
printf("fa5: %d\n", fd1);
close(fd1);
close(fd2);
close(fd3);
close(fd4);
close(fd5);
return 0;
}




文件描述符的分配规则:在files_struct数组中,找到当前没有被使用的一个最小的下标,作为新的文件描述符.
📖1.4 不按顺序的读取和写入
到目前为止,我们已经讨论过了如何读取和写入文件,但所有访问都是顺序的,也就是说,我们从头到尾读取一个文件,或者从头到尾写一个文件,但是,有时能够读取或写入文件中的特定偏移量是有用的,例如:如果在文本文件上构建了索引并利用它来查找单词,最终可能会从文件中的某些随机偏移量中读取数据,为此,我们将使用lseek()系统调用,下面是函数原型:
off_t lseek(int fd, off_t offset, int whence);
If whence is SEEK_SET, the offset is set to offset bytes.
If whence is SEEK_CUR, the offset is set to its current location plus offset bytes.
If whence is SEEK_END, the offset is set to the size of the file plus offset bytes.
📖1.5 文件重命名
有了一个文件后,有时需要给一个文件一个不同的名字,在命令行键入时,这是通过mv命令完成的,在下面的例子中,文件foo被重命名为bar.
prompt> mv foo bar
利用strace,我们可以看到mv使用了系统调用rename(char* old, char* new),它只需要两个参数:文件的原来名称和新名称.
rename()调用提供了一个有用的保证:它通常是一个原子调用,无论系统是否崩溃,如果系统在重命名期间崩溃,文件将被命名为旧名称或新名称,不会出现奇怪的中间状态.
int fd = open("foo.txt.tmp", O_WRONLY|O_CREAT|O_TRUNC);
write(fd, buffer, size); // write out new version of file
fsync(fd);
close(fd);
rename("foo.txt.tmp", "foo.txt");
这个例子中,编辑器做的事很简单:将文件的新版本写入临时名称(foot.txt.tmp),使用 fsync()将其强制写入磁盘. 然后,当应用程序确定新文件的元数据和内容在磁盘上,就将临时文件重命名为原有文件的名称. 最后一步自动将新文件交换到位,同时删除旧版本的文件,从而实现原子文件更新.
🌁2. 理解Linux下一切皆文件
在文件描述符中,0、1、2分别对应stdin, stdout, stderr,可是stdin是键盘,stdout是显示器,这也用文件来标识吗?
所以,我们应该如何用文件来标识硬件呢?又如何理解Linux下一切皆文件?

所以,当我们要向硬盘中写入数据时,操作系统的内存文件系统为硬盘创建一个struct file结构,并将struct file结构体中的读写方法函数指针指向对应硬盘的驱动读写方法,当我们想要写入数据时,用struct file中的读写方法便可以完成我们的操作,也实现了以统一的方式看待所有的设备,即Linux下一切皆文件.
🌠3. 理解重定向
📖3.1 重定向原理
#include<stdio.h>
#include<string.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<unistd.h>
int main()
{
//关闭了stdout
close(1);
int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
if(fd < 0)
{
perror("open");
return 0;
}
fprintf(stdout, "打开文件成功, fd: %d\n", fd);
fflush(stdout);
close(fd);
return 0;
}
在这段代码中,进程将自己的stdout关闭,然后打开一个文件,文件描述符的分配规则:遍历文件描述符表,将第一个未分配的下标分配给当前打开的文件,也就是说,fd为1,当我们向stdout中写入数据时,即对应fd为1的文件,本应该写到显示器上的内容就写入到了log.txt中,这不就是重定向吗?
重定向原理:

📖3.2 dup2系统调用
#include <unistd.h>
int dup2(int oldfd, int newfd);
dup2系统调用的作用是将本应该写入newfd中的内容写到oldfd中.
#include<stdio.h>
#include<string.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<unistd.h>
int main()
{
int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
if(fd < 0)
{
perror("open");
return 0;
}
//将本该写入到文件描述符1中的内容写入到fd中
dup2(fd, 1);
fprintf(stdout, "打开文件成功, fd: %d\n", fd);
fflush(stdout);
close(fd);
return 0;
}
🌿4. 理解缓冲区
📖4.1 什么是缓冲区
缓冲区的本质就是一段内存.
📖4.2 为什么要有缓冲区?
- 解放使用缓冲区的进程时间,可以只将写入放在缓冲区中,就可以做其他任务
- 缓冲区的存在可以集中处理数据刷新,减少IO次数,从而达到提高整机效率的目的.
📖4.3 缓冲区存在哪里?
对于我们在进行文件操作时,缓冲区其实是封装在文件FILE结构体中的,可以通过设置刷新策略,来决定什么时候将缓冲区的数据刷新,即什么时候调用write()系统调用.
刷新的本质:把缓冲区的数据write到OS内部,清空缓冲区.
缓冲区存在FILE内部,在C语言中,我们每次打开一个文件,都有一个对应的FILE* 返回,那么也就意味着,每一个文件都有一个fd和属于它自己的语言级别缓冲区.
接下来,我们可以自己试着封装一个FILE来模拟一下这个缓冲区的实现:
#include<stdio.h>
#include<string.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<unistd.h>
#include<assert.h>
#define NUM 1024
#define NONE_FLUSH 0x0
#define LINE_FLUSH 0x1
#define FULL_FLUSH 0x2
typedef struct _MyFILE
{
int _fileno;
char _buffer[NUM];
int _end;
int _flags; //fflush method
}MyFILE;
MyFILE* my_fopen(const char* filename, const char* method)
{
assert(filename);
assert(method);
int flags = O_RDONLY;
if(strcmp(method, "r") == 0)
{}
else if(strcmp(method, "r+"))
{}
else if(strcmp(method, "w") == 0)
{
flags = O_WRONLY | O_CREAT | O_TRUNC;
}
else if(strcmp(method, "w+") == 0)
{}
else if(strcmp(method, "a") == 0)
{
flags = O_WRONLY | O_CREAT | O_APPEND;
}
else if(strcmp(method, "a+") == 0)
{}
int fileno = open(filename, flags, 0666);
if(fileno < 0)
{
return NULL;
}
MyFILE* fp = (MyFILE*)malloc(sizeof(MyFILE));
if(fp == NULL)
return fp;
memset(fp, 0, sizeof(MyFILE));
fp->_fileno = fileno;
fp->_flags |= LINE_FLUSH;
fp->_end = 0;
return fp;
}
void my_fflush(MyFILE* fp)
{
assert(fp);
if(fp->_end > 0)
{
write(fp->_fileno, fp->_buffer, fp->_end);
fp->_end > 0;
syncfs(fp->_fileno);
}
}
void my_fwrite(MyFILE* fp, const char* start, int len)
{
assert(fp);
assert(start);
assert(len > 0);
//将数据写入缓冲区
strncpy(fp->_buffer + fp->_end, start, len);
fp->_end += len;
if(fp->_flags & NONE_FLUSH)
{}
else if(fp->_flags & LINE_FLUSH)
{
if(fp->_end > 0 && fp->_buffer[fp->_end - 1] == '\n')
{
//写到内核中
write(fp->_fileno, fp->_buffer, fp->_end);
fp->_end = 0;
syncfs(fp->_fileno);
}
}
else if(fp->_flags & FULL_FLUSH)
{}
}
void my_fclose(MyFILE* fp)
{
my_fflush(fp);
close(fp->_fileno);
free(fp);
}
🍁5. 硬链接和软链接
在谈论软硬链接之前,我们先使用一下它:
建立软链接:

建立硬链接:


那么,我们明显观察到了软链接和硬链接的一个不同:
软链接的inode编号与它所链接的文件不同,而硬链接的inode编号与它所链接的文件是相同的.
其实,软链接是一个独立的文件,而硬链接就是单纯在Linux指定的目录下,给指定的文件新增文件名和inode编号的映射关系.
怎么使用软硬链接呢?
首先我们来看软链接的使用:
现在,我们在距离当前目录较远的目录下建立一个可执行程序:

如果不使用软链接,我们在执行可执行程序的时候就需要带上指定路径,但有了软链接,我们就可以在当前目录下为它建立一个软链接,从而直接执行它:

硬链接的使用:
在使用硬链接之前,首先我们来认识一个叫硬链接数的概念:

硬链接数本质就是该文件inode属性中的一个计数器,标识有几个文件名和我的inode建立了映射关系.
一个普通文件的默认硬链接数就是1,因为它自己的文件名就和它的inode建立了映射.
创建一个空的目录,它的默认链接数是2:

因为除了它自己的文件名和自己的inode建立了链接,在它的目录下,还有一个.与它的inode也建立了映射.



![[附源码]Python计算机毕业设计Django在线项目管理](https://img-blog.csdnimg.cn/b82537c7679b4fcf8f5eca441af35ade.png)