如有错误,恳请指出。
文章目录
- 0. 前言
- 1. 背景
- 2. 准备工作
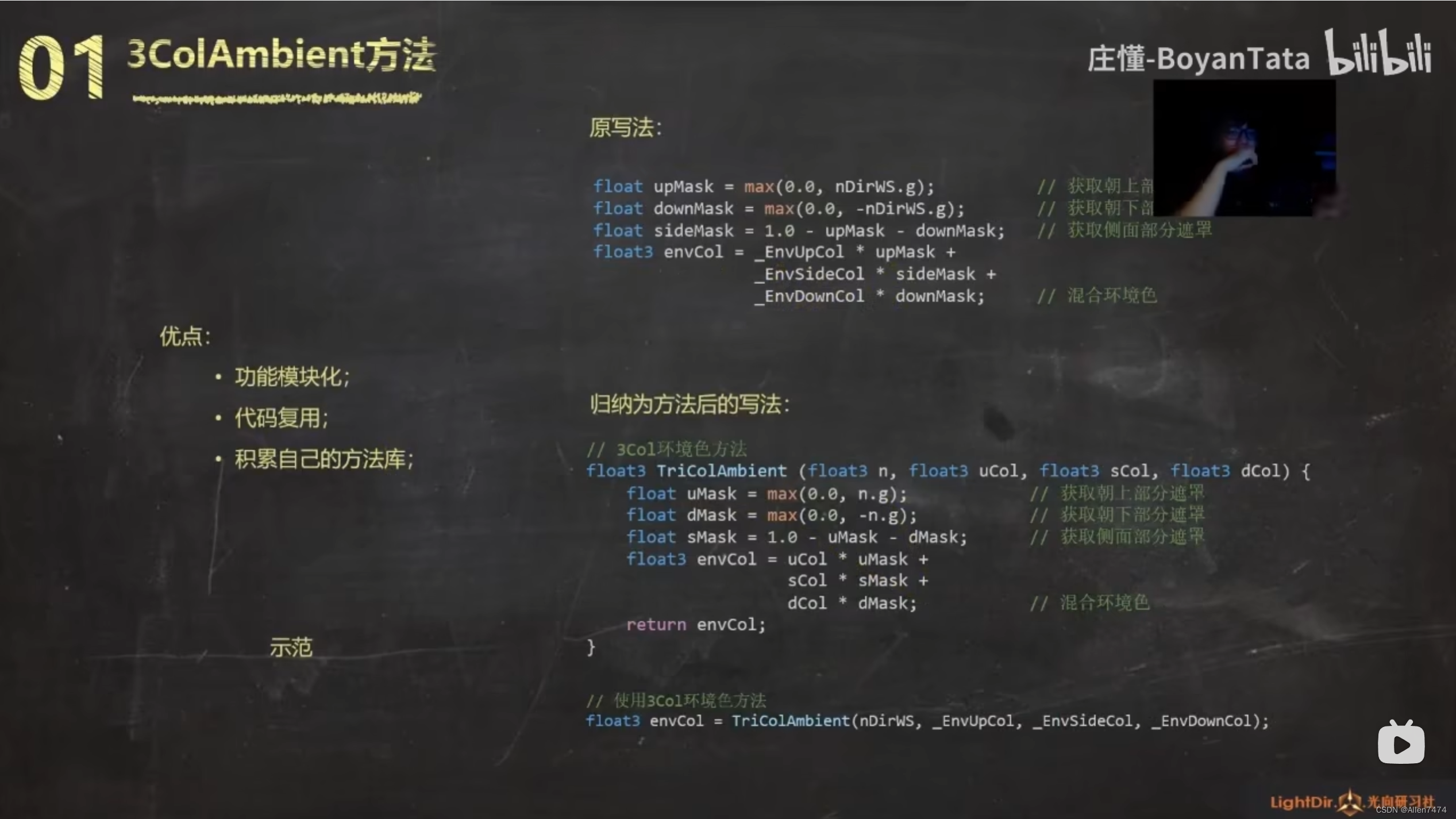
- 3. 网络结构
- 3.1 RPN
- 3.2 RCNN
- 4. 实验结果
paper:《Center-based 3D Object Detection and Tracking》(2021CVPR)
0. 前言
CenterPoint应该是与CenterNet是同一个团队的成果,部分作者是一样的。对于2d检测算法CenterNet,详细可以查看之前的笔记:论文阅读笔记 | 目标检测算法——CenterNet算法,CenterPoint的思想就是将CenterNet用到基于点云的3d目标检测上。
1. 背景
与2d检测相比,3d检测面临一些特别的挑战:1)点云的稀疏性导致大部分空间为空;2)输出需要产生带方向的3d框,这不能与坐标系进行很好的对齐;3)3d目标的尺寸范围变化比较大。也很好理解,在一个3d框的自由度比较高,具有方向的属性,在空间上难以和坐标轴对齐,2d的axis-aligned的方法对3d检测也就不太适用。
为此,CenterPoint的核心思想就是将框预测改为中心点预测来避免这个问题的出现。预测目标框的中心点避免了方向属性,减少了搜索空间;其次对于中心点的方法可以简化一些例如目标跟踪的下游任务。所以CenterPoint本质上是一个two-stage、anchor-free的算法(利用中心点预测代替anchor)
2. 准备工作
为了容易理解Centerpoint算法,这里首先再简要介绍一下CenterNet算法,详细见:论文阅读笔记 | 目标检测算法——CenterNet算法
在CenterNet中,利用2d卷积生成的特征图,后面分别接一个heatmap、sizemap、offsetmap。对于数据集中有k个类别,heatmap的维度构成即为hxwxk,也就是说对每个类别够构建一个热力图,每个热力图的局部最大值对应就是相关类别的对象中心,2channels的sizemap用来预测对象的宽高尺寸。而由于下采样得到的特征图会存在一些偏差,所以会再接一个offsetmap来预测这部分的偏差。CenterNet就是利用这三个map来准确的预测物体的位置。
这里paper还额外提到,基于bev视图的3d检测算法(类似yolo3d,pixor、hdnet)是依赖于2d的bev iou进行目标分配,这对于为不同类别或不同数据集选择正/负阈值产生了不必要的负担。原文:“Moreover, during the training, previous anchor-based 3D detectors rely on 2D Box IoU for target assignment [42, 54], which creates unnecessary burdens for choosing positive/negative thresholds for different classes or different dataset.”
对于这一点我的理解是,对于anchor-based的检测算法,需要计算每个anchor与target的iou,从而需要设置阈值来区分需要训练的正负样本,这个计算iou的过程中存在一些计算负担。在CenterNet中,推测采取的heatmap中的峰值来作为置信度,来分配正负样本。
3. 网络结构
CenterPoint本质上是一个two-stage、anchor-free(center-based)的算法,其算法思路继承自CenterNet,结构图如下所示。

3.1 RPN
CenterPoint的思路是在bev视图上做3d检测,不过回归的是一个真正的3d框(包含离地面高度预测以及框高度信息预测)。利用SECOND、PointPillars的backbone,进行稀疏3d卷积提取特征图,在bev视图上进行投影,最后的维度大小为WxHxC。
得到了backbone输出的特征,首先在其后接一个heatmap head用于预测目标中心点。假设数据集中存在k类对象,那么这里就会输出一个大小为k的channels,每一个channel表示其中的一类。有监督信息通过3d场景在2d的bev视图中投影获得。考虑到点云信息的稀疏性,这里会扩大每个对象中心的高斯峰值来增加heatmap的正样本监督,“increase the positive supervision for the target heatmap Y by enlarging the Gaussian peak rendered at each ground truth object center”。
CenterPoint在对方向预测上也使用了类似Complex的隐信息编码,也就是用(sin(α), cos(α))两个值来预测方向信息。对于位置信息xyz,以及尺寸信息hwl,还有方向全部都采用L1 loss来进行回归处理(使用对数回归可以更好的处理各种形状)。这个回归过程是通过另外一个分支regression head来实现的,在推理时直接取heatmap中峰值索引,在regression head获取到3d框的属性信息。
CenterPoint的一阶段简单来说,就是利用heatmap预测出相应的类别以及对象的中心点,然后在regression map中的对应位置获取其他的3d框属性,构建成最后的3d候选框。
3.2 RCNN
得到了3d候选框就需要利用候选框中的特征进行特征聚合,这里选择的是3d候选框每个面的特征。具体来说,在bev视图上,顶部中心点与底部中心点在backbone输出的特征图中索引的位置特征是一样的,而前后左右4个方向的面特征其实也就是bev图上每条边的中心点特征,如结构图所示。一般来说,带有方向的候选框一般都和坐标轴不是对齐的,所以在对齐的backbone输出特征中不能正常索引,为此这里采用的双线性插值来获取这些点的特征。所以如结构图所示,对于每一个候选框可以从backboen输出的特征图中获得5个点的channels特征。
随后对这些point-features进行concat,再送入MLP处理。这里只预测置信度以及回归信息,不再预测类别信息(一阶段的heatmap中以及分类预测好)。在训练时,这里的置信度回归的是3d iou值;在推理时,最后输出的置信度是一阶段的类别分数预测以及这里的置信度预测的相乘再开方,Qt = sqrt(Yt ∗ It)。
在二阶段中,同样采用的是l1 loss对一阶段的候选框进行修正。CenterPoint简化了之前Two-stage的特征提取与RoIAlign操作。
4. 实验结果
可以发现,CenterPoint使用的backbone是与SECOND、PointPillars方法是一样的,不同的是前者是center-based的方法,后者是anchor-based的方法,可以从消融实验中看到使用center-based所带来的提升,证明了center-based方法的优越性。

ps:其中anchor-based方法的损失构造可以参考SECOND、PointPillars;而这里的Grid Point-based方法就是常见的anchor-free方法,代表性的有PointRCNN中的bin-based损失构造(联合分类+残差回归),以及PIXOR的直接回归(对方向信息利用sin+cos隐形回归)
CneterPoint这里在Waymo和nuScenes这两个比较大型的数据集上对网络进行了测试(kitti相比之下比较小,然后难度也没有那么大,逐渐退出历史舞台),CenterPoint的效果是杠杠的,甚至比很多现在的新方法性能还要好,在paper with code中排前列。

![[附源码]Python计算机毕业设计Django在线项目管理](https://img-blog.csdnimg.cn/b82537c7679b4fcf8f5eca441af35ade.png)