目录
Mycat分片规则_取模
Mycat分片规则_分片枚举
Mycat分片规则_范围约定
Mycat分片规则_取模
实现方式
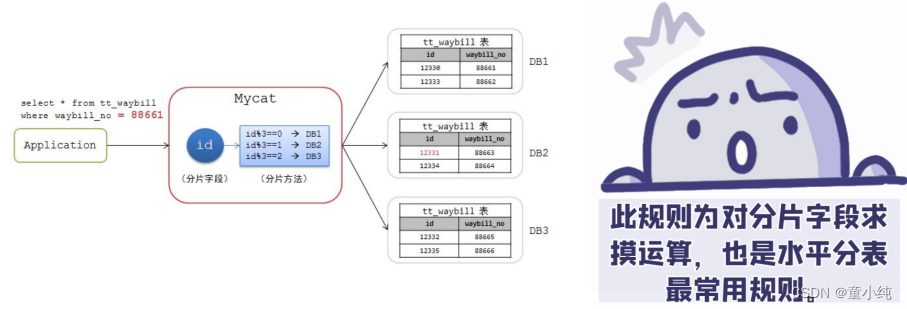
取模分片就是根据数据表的某一个字段,通常是某一个整数型的字 段,对其进行十进制的求模运算,将运算结果作为Mycat的路由结果。
注意:
优点:这种策略可以很好的分散数据库写的压力。
缺点:出现了范围查询,就需要MyCAT去合并结果,当数据量偏高的时候,这种跨库查询 +合并结果消耗的时间有可能会增加很多,尤其是还出现了order by的时候。
tableRule 标签
这个标签定义表规则。
<tableRule name="mod-long">
<rule>
<columns>user_id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>参数:
name :属性指定唯一的名字,用于标识不同的表规则。 内嵌的 rule 标签则指定对物理表中 的哪一列进行拆分和使用什么路由算法。
columns :内指定要拆分的列名字。
algorithm:使用 function 标签中的 name 属性。连接表规则和具体路由算法。当然,多个 表规则可以连接到 同一个路由算法上。
function标签
定义具体路由算法
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">2</property>
</function>注意:
name 指定算法的名字。 class 制定路由算法具体的类名字。
property 为具体算法需要用到的一些属性。
count:表示需要取模的最大值,将数据分成该配置的切片。
实时学习反馈
1.Mycat技术中取模的分片规则缺点是___。
A 分散数据库写的压力
B 分但数据库的读压力
C 范围查询
Mycat分片规则_分片枚举

实现原理
有些业务需要按照省份或区县来做保存,这类业务使用本条规则。
实现过程
在这里,需定义三个值,规则均是在rule.xml中定义。
tableRule
function
mapFile
创建示例表
#订单归属区域信息表
CREATE TABLE orders_ware_info(
`id` INT AUTO_INCREMENT comment '编号',
`order_id` INT comment '订单编号',
`address` VARCHAR(200) comment '地址',
`areacode` VARCHAR(20) comment '区域编号',
PRIMARY KEY(id)
);修改schema.xml配置文件
<table name="orders_ware_info" dataNode="dn1,dn2" rule="sharding-by-intfile"></table>定义tableRule
<tableRule name="sharding-by-intfile">
<rule>
<columns>areacode</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>注意: 其中,sharding-by-intfile-test是规则名,会在schema.xml中用到。columns指的是对省份进行分片。algorithm是算法名, 该算法必须在function中定义。
定义funtion
<function name="hash-int" class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
<property name="type">1</property>
<property name="defaultNode">0</property>
</function>注意:
mapFile:指的是配置文件名
type:默认值为0,0表示Integer,非零表示String。因为我接下来的测试是基于省份分片, 所以需type指定为1。
defaultNode 默认节点:小于0表示不设置默认节点,大于等于0表示设置默认节点 默认节点的作用:枚举分片时,如果碰到不识别的枚举值,就让它路由到默认节点。
修改partition-hash-int.txt配置文件
110=0
120=1
注意: 其中,110会被分发到第一个节点中,120分发被第二个节点中。
重启Mycat
mycat restart插入数据
INSERT INTO orders_ware_info(id,order_id,address,areacode) VALUES (1,1,'北京','110');
INSERT INTO orders_ware_info(id,order_id,address,areacode) VALUES (2,2,'天津','120');
实时学习反馈
1.Mycat技术中分片枚举指的是___。
A 需要按照省份或区县来做保存
B 范围保存
C 时间保存
D 排序
Mycat分片规则_范围约定
实现原理
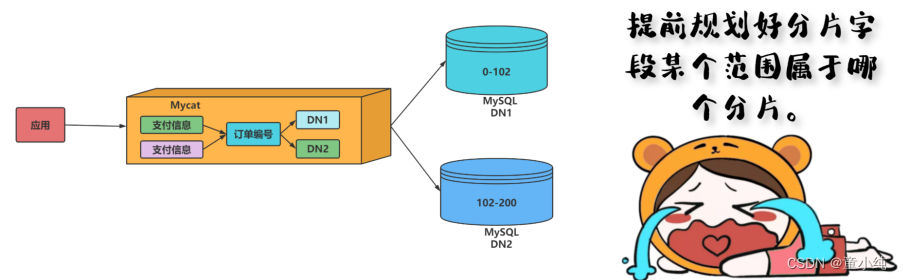
此分片适用于,提前规划好分片字段某个范围属于哪个分片。
举个例子
比如将id在0-500W的数据分片在第一个节点上面,将id在500W-1000W的数据分片在第二个节点上,依次类推下去。
优缺点:
优点:适用于想明确知道某个分片字段的某个范围具体在哪一个节点;
缺点:如果短时间内有大量的批量插入操作,那么某个分片节点可能一下子会承受比较大的 数据库压力,而别的分片节点此时可能处于闲置状态,无法利用其它节点进行分担压力(热 点数据问题);
实现过程
创建示例表
#支付信息表
CREATE TABLE payment_info
(`id` INT AUTO_INCREMENT comment '编号',
`order_id` INT comment '订单编号',
`payment_status` INT comment '支付状态',
PRIMARY KEY(id)
);
修改schema.xml配置文件
<table name="payment_info" dataNode="dn1,dn2" rule="auto_sharding_long" ></table>
定义tableRule
<tableRule name="auto_sharding_long">
<rule>
<columns>order_id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>注意: 其中,auto_sharding_long是规则名,会在schema.xml中用 到。columns指的是对订单id进行分片。algorithm是算法名, 该算法必须在function中定义。
定义function
<function name="rang-long"
class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
<property name="defaultNode">0</property>
</function>
注意:
mapFile:指的是配置文件名
type:默认值为0,0表示Integer,非零表示String。因为我接下来的测试是基于省份分片, 所以需type指定为1。
defaultNode 默认节点:小于0表示不设置默认节点,大于等于0表示设置默认节点 默认节点的作用:枚举分片时,如果碰到不识别的枚举值,就让它路由到默认节点。
修改autopartition-long.txt配置文件
0-102=0
103-200=1重启Mycat
mycat restart
插入数据
INSERT INTO payment_info(id,order_id,payment_status) VALUES(1,101,0);
INSERT INTO payment_info(id,order_id,payment_status) VALUES(2,102,1);
INSERT INTO payment_info (id,order_id,payment_status) VALUES (3,103,0);
INSERT INTO payment_info(id,order_id,payment_status) VALUES(4,104,1);
实时学习反馈
1.Mycat技术中范围分片规则缺点是___。
A 范围查询
B 分散数据库写的压力
C 需要按照省份或区县来做保存
D 热点数据问题