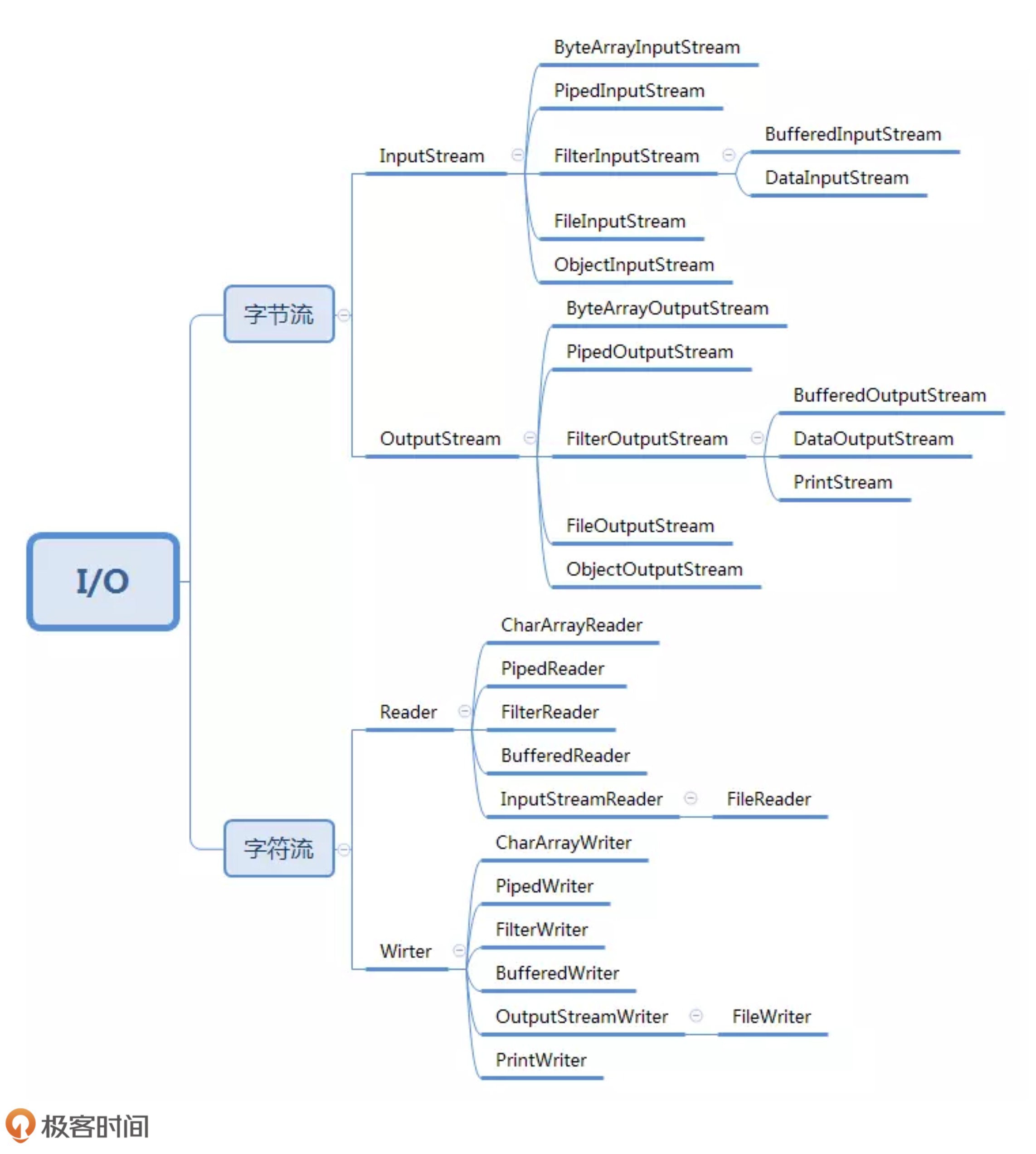
二叉树系列4
- 617 合并二叉树
- 重点
- 代码随想录的代码
- 我的代码(晚上理解后自己编写)
- 700 二叉搜索树中的搜索
- 未看解答自己编写
- 看了解答后,精简了两个判断的写法
- 重点
- 代码随想录的代码
- 我的代码(晚上理解后自己编写)
- 98 验证二叉搜索树
- 重点
- 看到二叉搜索树,就要想到中序遍历。
- 代码随想录的代码
- 我的代码(晚上理解后自己编写)
- 这道题是有点难度的!二刷要注意!
- 530 二叉搜索树的最小绝对差
- 未看解答之前,第一遍自己编写
- 重点
- 代码随想录的代码
- 我的代码(晚上理解后自己编写)
- 501 二叉搜索树中的众数
- 看了一眼思路自己独立编写的青春垃圾版
- 重点
- 代码随想录的代码
- 我的代码(晚上理解后自己编写)
- 236 二叉树的最近公共祖先
- 重点
- 代码随想录的代码
- 我的代码(晚上理解后自己编写)
- 二叉树系列4总结
617 合并二叉树
本题本质上是,同时遍历两颗二叉树,遍历操作可以选择递归。对于本题来说,遍历的顺序,前中后序均可。
本题递归代码在编写的时候,要注意返回条件的编写。
如果采用迭代法的话,在前面写过一道,判断二叉树是否对称的题目,也是同时遍历两个子树,使用的是基于队列的层序遍历。
重点
代码随想录的代码
(版本一) 递归 - 前序 - 修改root1
class Solution:
def mergeTrees(self, root1: TreeNode, root2: TreeNode) -> TreeNode:
# 递归终止条件:
# 但凡有一个节点为空, 就立刻返回另外一个. 如果另外一个也为None就直接返回None.
if not root1:
return root2
if not root2:
return root1
# 上面的递归终止条件保证了代码执行到这里root1, root2都非空.
root1.val += root2.val # 中
root1.left = self.mergeTrees(root1.left, root2.left) #左
root1.right = self.mergeTrees(root1.right, root2.right) # 右
return root1 # ⚠️ 注意: 本题我们重复使用了题目给出的节点而不是创建新节点. 节省时间, 空间.
(版本二) 递归 - 前序 - 新建root
class Solution:
def mergeTrees(self, root1: TreeNode, root2: TreeNode) -> TreeNode:
# 递归终止条件:
# 但凡有一个节点为空, 就立刻返回另外一个. 如果另外一个也为None就直接返回None.
if not root1:
return root2
if not root2:
return root1
# 上面的递归终止条件保证了代码执行到这里root1, root2都非空.
root = TreeNode() # 创建新节点
root.val += root1.val + root2.val# 中
root.left = self.mergeTrees(root1.left, root2.left) #左
root.right = self.mergeTrees(root1.right, root2.right) # 右
return root # ⚠️ 注意: 本题我们创建了新节点.
(版本三) 迭代
class Solution:
def mergeTrees(self, root1: TreeNode, root2: TreeNode) -> TreeNode:
if not root1:
return root2
if not root2:
return root1
queue = deque()
queue.append(root1)
queue.append(root2)
while queue:
node1 = queue.popleft()
node2 = queue.popleft()
# 更新queue
# 只有两个节点都有左节点时, 再往queue里面放.
if node1.left and node2.left:
queue.append(node1.left)
queue.append(node2.left)
# 只有两个节点都有右节点时, 再往queue里面放.
if node1.right and node2.right:
queue.append(node1.right)
queue.append(node2.right)
# 更新当前节点. 同时改变当前节点的左右孩子.
node1.val += node2.val
if not node1.left and node2.left:
node1.left = node2.left
if not node1.right and node2.right:
node1.right = node2.right
return root1
(版本四) 迭代 + 代码优化
from collections import deque
class Solution:
def mergeTrees(self, root1: TreeNode, root2: TreeNode) -> TreeNode:
if not root1:
return root2
if not root2:
return root1
queue = deque()
queue.append((root1, root2))
while queue:
node1, node2 = queue.popleft()
node1.val += node2.val
if node1.left and node2.left:
queue.append((node1.left, node2.left))
elif not node1.left:
node1.left = node2.left
if node1.right and node2.right:
queue.append((node1.right, node2.right))
elif not node1.right:
node1.right = node2.right
return root1
我的代码(晚上理解后自己编写)
class Solution:
def mergeTrees(self, root1: Optional[TreeNode], root2: Optional[TreeNode]) -> Optional[TreeNode]:
if root1 == None :
return root2
if root2 == None :
return root1
root1.val += root2.val
root1.left = self.mergeTrees(root1.left,root2.left)
root1.right = self.mergeTrees(root1.right,root2.right)
return root1
其他版本的代码,后续二刷再学习。
700 二叉搜索树中的搜索
本题的迭代法,很简单!
二叉搜索树是一个有序树:
1、若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
2、若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
3、它的左、右子树也分别为二叉搜索树
未看解答自己编写
class Solution:
def searchBST(self, root: Optional[TreeNode], val: int) -> Optional[TreeNode]:
if root == None :
return None
if root.val == val :
return root
elif root.val > val and root.left == None :
return None
elif root.val < val and root.right == None :
return None
elif root.val > val :
return self.searchBST(root.left,val)
elif root.val < val :
return self.searchBST(root.right,val)
看了解答后,精简了两个判断的写法
class Solution:
def searchBST(self, root: Optional[TreeNode], val: int) -> Optional[TreeNode]:
if root == None :
return None
if root.val == val :
return root
elif root.val > val :
return self.searchBST(root.left,val)
elif root.val < val :
return self.searchBST(root.right,val)
重点
代码随想录的代码
递归:
class Solution:
def searchBST(self, root: TreeNode, val: int) -> TreeNode:
# 为什么要有返回值:
# 因为搜索到目标节点就要立即return,
# 这样才是找到节点就返回(搜索某一条边),如果不加return,就是遍历整棵树了。
if not root or root.val == val:
return root
if root.val > val:
return self.searchBST(root.left, val)
if root.val < val:
return self.searchBST(root.right, val)
迭代法:
class Solution:
def searchBST(self, root: TreeNode, val: int) -> TreeNode:
while root:
if val < root.val: root = root.left
elif val > root.val: root = root.right
else: return root
return None
我的代码(晚上理解后自己编写)
递归在第一次做题时已经写出来,迭代法也非常简短精巧。
class Solution:
def searchBST(self, root: TreeNode, val: int) -> TreeNode:
while root:
if val < root.val: root = root.left
elif val > root.val: root = root.right
else: return root
return None
98 验证二叉搜索树
第一次看题无思路。原因是没有了解二叉搜索树的特性。
假设一个二叉搜索树具有如下特征:
1:节点的左子树只包含小于当前节点的数。
2:节点的右子树只包含大于当前节点的数。
3:所有左子树和右子树自身必须也是二叉搜索树。
以上特性意味着:如果对二叉搜索树进行中序遍历(左中右),得到的数组一定是有序的。
所以思路就是,对树进行中序遍历,如果序列是有序的,就是二叉搜索树。
重点
通过此题要学会,二叉搜索树,的特性,中序遍历,有序!
如果一棵树是一个空树(根节点为None),那么它什么二叉树都是,是完全二叉树,二叉搜索树,平衡二叉树,满二叉树等。
中序遍历,判断数组是否有序的方法不是一个好的方法,没有必要用数组去判断是否为单调递增的。本题直接基于二叉树,去判断单调递增。
如何不使用数组?
代码误区:


一定要避免陷阱一,在不用数组的情况下,其思路还是中序遍历,只不过用一个数值去记录遍历的上一个值罢了,因为中序遍历得到为单调递增,这个性质很关键。
上述额外定义一个数值也是不太好的,因为如果二叉树中的最小值为编程语言的最小值怎么办?那样直接就返回 False 了,所以最好的办法是,让前一个节点和后一个节点进行比较。Pre 记录当前节点的前一个节点。
看到二叉搜索树,就要想到中序遍历。
代码随想录的代码
递归法(版本一)利用中序递增性质,转换成数组
class Solution:
def __init__(self):
self.vec = []
def traversal(self, root):
if root is None:
return
self.traversal(root.left)
self.vec.append(root.val) # 将二叉搜索树转换为有序数组
self.traversal(root.right)
def isValidBST(self, root):
self.vec = [] # 清空数组
self.traversal(root)
for i in range(1, len(self.vec)):
# 注意要小于等于,搜索树里不能有相同元素
if self.vec[i] <= self.vec[i - 1]:
return False
return True
递归法(版本二)设定极小值,进行比较
class Solution:
def __init__(self):
self.maxVal = float('-inf') # 因为后台测试数据中有int最小值
def isValidBST(self, root):
if root is None:
return True
left = self.isValidBST(root.left)
# 中序遍历,验证遍历的元素是不是从小到大
if self.maxVal < root.val:
self.maxVal = root.val
else:
return False
right = self.isValidBST(root.right)
return left and right
递归法(版本三)直接取该树的最小值
class Solution:
def __init__(self):
self.pre = None # 用来记录前一个节点
def isValidBST(self, root):
if root is None:
return True
left = self.isValidBST(root.left)
if self.pre is not None and self.pre.val >= root.val:
return False
self.pre = root # 记录前一个节点
right = self.isValidBST(root.right)
return left and right
迭代法
class Solution:
def isValidBST(self, root):
stack = []
cur = root
pre = None # 记录前一个节点
while cur is not None or len(stack) > 0:
if cur is not None:
stack.append(cur)
cur = cur.left # 左
else:
cur = stack.pop() # 中
if pre is not None and cur.val <= pre.val:
return False
pre = cur # 保存前一个访问的结点
cur = cur.right # 右
return True
我的代码(晚上理解后自己编写)
二刷时没写出来,是想写用搜索树本身节点来写递归的,但是错把pre节点放在了递归参数里,逻辑一下子理不清了,不知道如何给pre赋初值。
思考递归的返回条件和处理逻辑都没问题,就没想到可能是参数构造出了问题!递归三部曲真的很重要啊!
pre节点应该设置为全局变量。
class Solution:
def __init__(self):
self.pre = None
def isValidBST(self, root: Optional[TreeNode]) -> bool:
if root == None :
return True
left = self.isValidBST(root.left)
if self.pre != None and self.pre.val >= root.val :
return False
self.pre = root
right = self.isValidBST(root.right)
return left and right
这道题是有点难度的!二刷要注意!
此题难点在于return逻辑的判断,当pre不为空 and 不满足单调递增的情况下,return False。这里不要想着去return True , 因为True的情况是必须整棵树为二叉搜索树时才满足,而False的情况很好判断,只要有一个小条件不满足即可。
另一个难点,在于 self.pre = root ,如何想到递归的处理逻辑,先处理左子树,满足单增,因为是中序遍历,pre转为中间节点,进入右子树的遍历,同样也要满足单增,如果一直满足,就是True。
在中间 return False 的逻辑中,可以看做是及时返回,有矛盾出现时,就返回,不需要再进行后面的右子树搜索了。
530 二叉搜索树的最小绝对差
未看解答之前,第一遍自己编写
class Solution:
def __init__(self):
self.pre = None
self.min = inf
def getMinimumDifference(self, root: Optional[TreeNode]) -> int:
self.digui(root)
return self.min
def digui(self,root):
if root == None :
return
self.digui(root.left)
if self.pre != None :
if abs(self.pre.val-root.val) < self.min :
self.min = abs(self.pre.val-root.val)
self.pre = root
self.digui(root.right)
return
重点
代码随想录的代码
递归法(版本一)利用中序递增,结合数组
class Solution:
def __init__(self):
self.vec = []
def traversal(self, root):
if root is None:
return
self.traversal(root.left)
self.vec.append(root.val) # 将二叉搜索树转换为有序数组
self.traversal(root.right)
def getMinimumDifference(self, root):
self.vec = []
self.traversal(root)
if len(self.vec) < 2:
return 0
result = float('inf')
for i in range(1, len(self.vec)):
# 统计有序数组的最小差值
result = min(result, self.vec[i] - self.vec[i - 1])
return result
递归法(版本二)利用中序递增,找到该树最小值:
class Solution:
def __init__(self):
self.result = float('inf')
self.pre = None
def traversal(self, cur):
if cur is None:
return
self.traversal(cur.left) # 左
if self.pre is not None: # 中
self.result = min(self.result, cur.val - self.pre.val)
self.pre = cur # 记录前一个
self.traversal(cur.right) # 右
def getMinimumDifference(self, root):
self.traversal(root)
return self.result
迭代法
class Solution:
def getMinimumDifference(self, root):
stack = []
cur = root
pre = None
result = float('inf')
while cur is not None or len(stack) > 0:
if cur is not None:
stack.append(cur) # 将访问的节点放进栈
cur = cur.left # 左
else:
cur = stack.pop()
if pre is not None: # 中
result = min(result, cur.val - pre.val)
pre = cur
cur = cur.right # 右
return result
我的代码(晚上理解后自己编写)
501 二叉搜索树中的众数
第一次写题,不会做,失败点在于,如果众数是唯一的,利用双指针法就可以得到,也不需要额外的存储空间,但是如果,众数不唯一呢?怎么不利用额外的空间去存储?
代码随想录的解答:
比较好想的方法是,遍历两次二叉树,第一次统计Maxcount,第二次将所有count等于Maxcount的数值输出。
但是能不能只遍历一遍呢?
就是,只要count==Maxcount,就添加,当Maxcount变化时,就清空res数组。其实有想到这一点,但是看题目进阶要求,说不能申请额外的空间,以为这样一个list也是不行的,虽然它的长度比遍历二叉树的长度要小得多。
现在回过头去想想,这样一个常数大小的res(因为众数的个数总是有限的),比起整棵二叉树(N)来说,就可以看做,不申请额外空间。
看了一眼思路自己独立编写的青春垃圾版
不写不知道,虽然逻辑很简单,但是落实到代码上,还有很多问题啊,总归是加了一堆判断写出来了,但是很垃圾的代码。
class Solution:
def __init__(self):
self.pre = None
self.res = []
self.maxcount = 1
self.count = 1
def findMode(self, root: Optional[TreeNode]) -> List[int]:
if root == None :
return []
if root.left == None and root.right == None :
return [root.val]
self.digui(root)
return self.res
def digui(self,root):
if root == None :
return
self.digui(root.left)
if self.pre != None :
if self.pre.val == root.val :
self.count += 1
else :
self.count = 1
if self.count > self.maxcount :
self.maxcount = self.count
self.res.clear()
self.res.append(root.val)
elif self.count == self.maxcount :
self.res.append(root.val)
else :
self.res.append(root.val)
self.pre = root
self.digui(root.right)
return
重点
代码随想录的代码
代码随想录的代码中的条件判断逻辑要比我自己写的清楚一些。
递归法(版本一)利用字典
from collections import defaultdict
class Solution:
def searchBST(self, cur, freq_map):
if cur is None:
return
freq_map[cur.val] += 1 # 统计元素频率
self.searchBST(cur.left, freq_map)
self.searchBST(cur.right, freq_map)
def findMode(self, root):
freq_map = defaultdict(int) # key:元素,value:出现频率
result = []
if root is None:
return result
self.searchBST(root, freq_map)
max_freq = max(freq_map.values())
for key, freq in freq_map.items():
if freq == max_freq:
result.append(key)
return result
递归法(版本二)利用二叉搜索树性质
class Solution:
def __init__(self):
self.maxCount = 0 # 最大频率
self.count = 0 # 统计频率
self.pre = None
self.result = []
def searchBST(self, cur):
if cur is None:
return
self.searchBST(cur.left) # 左
# 中
if self.pre is None: # 第一个节点
self.count = 1
elif self.pre.val == cur.val: # 与前一个节点数值相同
self.count += 1
else: # 与前一个节点数值不同
self.count = 1
self.pre = cur # 更新上一个节点
if self.count == self.maxCount: # 如果与最大值频率相同,放进result中
self.result.append(cur.val)
if self.count > self.maxCount: # 如果计数大于最大值频率
self.maxCount = self.count # 更新最大频率
self.result = [cur.val] # 很关键的一步,不要忘记清空result,之前result里的元素都失效了
self.searchBST(cur.right) # 右
return
def findMode(self, root):
self.count = 0
self.maxCount = 0
self.pre = None # 记录前一个节点
self.result = []
self.searchBST(root)
return self.result
迭代法
class Solution:
def findMode(self, root):
st = []
cur = root
pre = None
maxCount = 0 # 最大频率
count = 0 # 统计频率
result = []
while cur is not None or st:
if cur is not None: # 指针来访问节点,访问到最底层
st.append(cur) # 将访问的节点放进栈
cur = cur.left # 左
else:
cur = st.pop()
if pre is None: # 第一个节点
count = 1
elif pre.val == cur.val: # 与前一个节点数值相同
count += 1
else: # 与前一个节点数值不同
count = 1
if count == maxCount: # 如果和最大值相同,放进result中
result.append(cur.val)
if count > maxCount: # 如果计数大于最大值频率
maxCount = count # 更新最大频率
result = [cur.val] # 很关键的一步,不要忘记清空result,之前result里的元素都失效了
pre = cur
cur = cur.right # 右
return result
我的代码(晚上理解后自己编写)
236 二叉树的最近公共祖先
难,第一次看题一点思路都没有,只能想到用后序遍历,但是再多一点的也想不到了。
重点
太牛了这道题,多看文章讲解和视频。
代码随想录的代码
递归法(版本一)
class Solution:
def lowestCommonAncestor(self, root, p, q):
if root == q or root == p or root is None:
return root
left = self.lowestCommonAncestor(root.left, p, q)
right = self.lowestCommonAncestor(root.right, p, q)
if left is not None and right is not None:
return root
if left is None and right is not None:
return right
elif left is not None and right is None:
return left
else:
return None
递归法(版本二)精简
class Solution:
def lowestCommonAncestor(self, root, p, q):
if root == q or root == p or root is None:
return root
left = self.lowestCommonAncestor(root.left, p, q)
right = self.lowestCommonAncestor(root.right, p, q)
if left is not None and right is not None:
return root
if left is None:
return right
return left
我的代码(晚上理解后自己编写)
二叉树系列4总结
代码随想录的总结很不错,直接上链接。
二叉树系列4总结