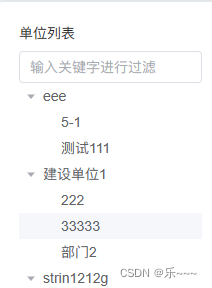
泛化误差(generalization error)是指,模型应⽤在同样从原始样本的分布中 抽取的⽆限多数据样本时,模型误差的期望。考虑对掷硬币的结果(类别0:正⾯,类别1:反⾯)进⾏分类的问题。假设硬币是公平的,无论我们想出什么算法,泛化误差始终是![]() 。
。
决策树和神经网络是两种不同的机器学习模型,它们在结构和工作原理上存在着差异。
结构:决策树是一种树状结构,由一系列的决策节点和叶子节点组成。每个决策节点代表一个特征或属性的判断条件,而叶子节点表示最终的分类结果或回归值。神经网络则是由多个神经元(或称为节点)组成的层次结构。神经元之间通过连接权重相互连接,并通过激活函数进行信息传递和处理。
工作原理:决策树通过将数据集分割成多个子集来进行决策,每个子集对应一个特征或属性的取值范围。从根节点开始,根据样本数据的特征值逐步向下遍历,直到达到叶子节点并得出预测结果。神经网络则通过前向传播和反向传播两个阶段进行训练。在前向传播中,输入数据经过各层的运算和激活函数处理,最后输出预测结果;而在反向传播中,根据预测结果与真实标签的误差,通过调整连接权重来优化网络模型。
表达能力:决策树在处理离散型和连续型数据上具有较好的表达能力,能够处理非线性关系和高维特征。它可以生成可解释性较强的规则,便于理解和解释模型的推理过程。神经网络适用于处理大规模的数据集和复杂的非线性问题,具有较强的拟合能力和泛化能力。但神经网络的模型结构相对于决策树来说更加复杂,对于模型的可解释性较弱。
因此,决策树和神经网络在结构、工作原理和表达能力等方面存在差异,选择使用哪种模型取决于具体的问题背景和数据特征。
几个倾向于影响模型泛化的因素。
1. 可调整参数的数量。当可调整参数的数量(有时称为自由度)很大时,模型往往更容易过拟合。
2. 参数采用的值。当权重的取值范围较大时,模型可能更容易过拟合。
3. 训练样本的数量。即使模型很简单,也很容易过拟合只包含一两个样本的数据集。而过拟合一个有着数百万个样本的数据集则需要一个极其灵活的模型。
常⻅做法是将我们的数据分成三份,除了训练和测试数据集之外,还增加⼀个验证数据集
(validation dataset),也叫验证集(validation set)。但现实是验证数据和测试数据之间的边界模糊得令⼈担忧,意思应该是常常把验证集合测试集的概念混为一谈。这可能是因为验证数据集和测试数据集都用于模型评估,但它们的使用方式有所不同。
通常情况下,验证数据集被用来评估不同模型的性能,并根据验证集的结果进行模型调优,例如选择不同的超参数或尝试不同的模型结构。因此,验证数据集的目的是帮助我们确定最佳模型,并对模型进行改进。
测试数据集则是在模型调优完成后,用于最终评估模型的泛化能力和性能。测试数据集应该是模型之前未见过的数据,用于检验模型的真实性能。测试数据集的结果可以作为模型的最终性能指标。
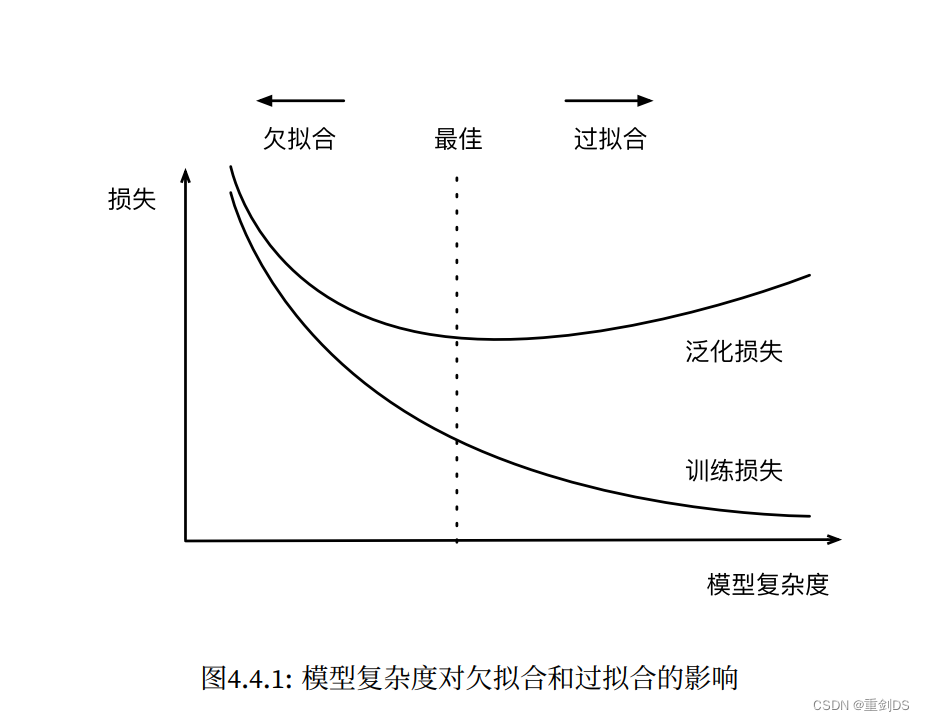
如下图4.4.1所示,拿d阶的多项式拟合来说明(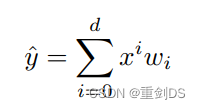 )。横轴表示模型复杂度越高,说明d越大,多项式的阶数也就越大,这时候通过观察泛化损失可以很好的看多项式拟合是欠拟合、最佳还是过拟合了。
)。横轴表示模型复杂度越高,说明d越大,多项式的阶数也就越大,这时候通过观察泛化损失可以很好的看多项式拟合是欠拟合、最佳还是过拟合了。
features.shape为torch.Size([200, 1]),features[:2]其实是等价于features[0:2],并且也等价于features[0:2, :]。
因为在PyTorch中,使用切片操作时,如果不指定维度,则默认会选择所有元素。所以 features[:2] 实际上等价于 features[0:2, :],它们都选择了前两行的所有列。
具体来说:
- features[:2] 表示选择索引从 0 到 1(不包括 2)的行,即前两行。
- features[0:2, :] 表示选择索引从 0 到 1(不包括 2)的行,并且 : 表示选择所有列,即前两行的所有列。
两种写法是等价的,它们都选择了相同的行,没有指定列的范围,因此默认选择所有列。