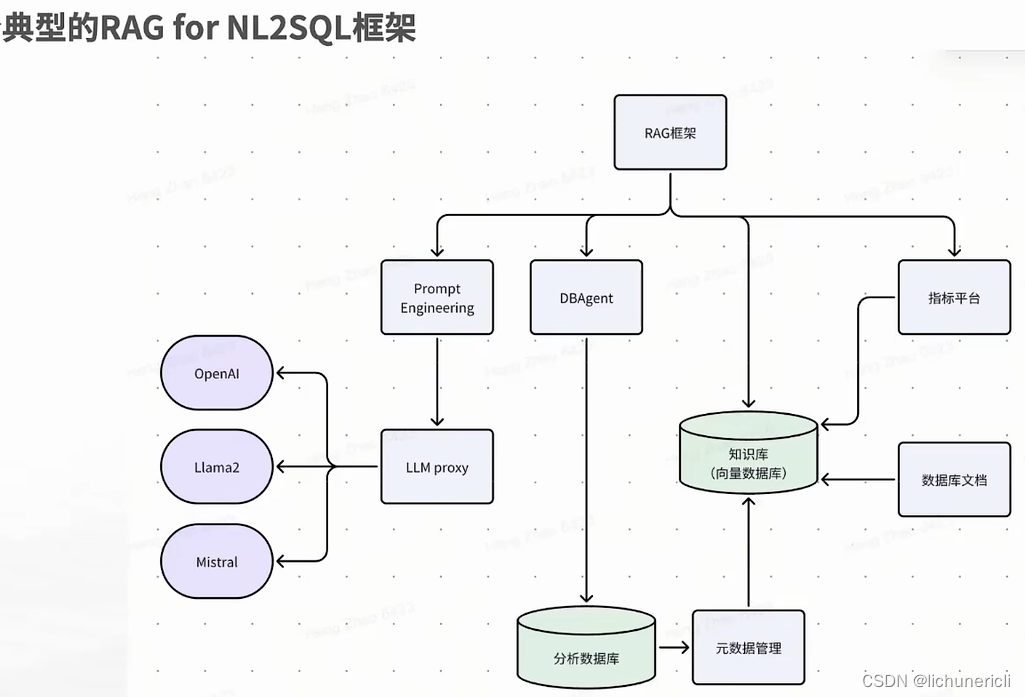
前言
本文主要介绍通过python实现数据聚类、脚本开发、办公自动化。读取voc数据,聚类voc数据。
一、业务逻辑
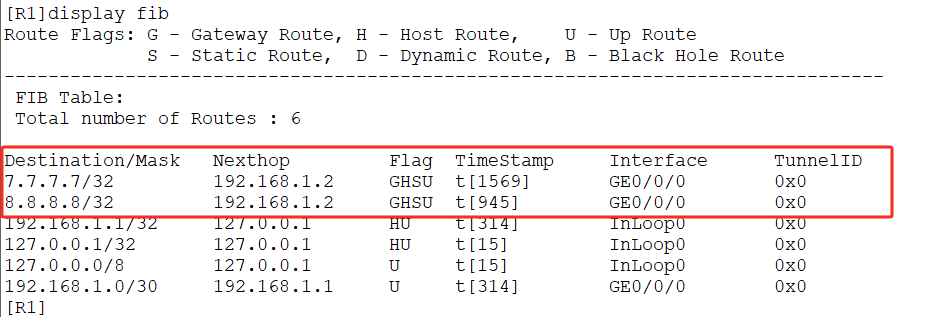
- 读取voc数据采集的数据
- 批处理,使用jieba进行分词,去除停用词
- LDA模型计算词汇和每个词的频率
- 将可视化结果保存到HTML文件中
二、具体产出
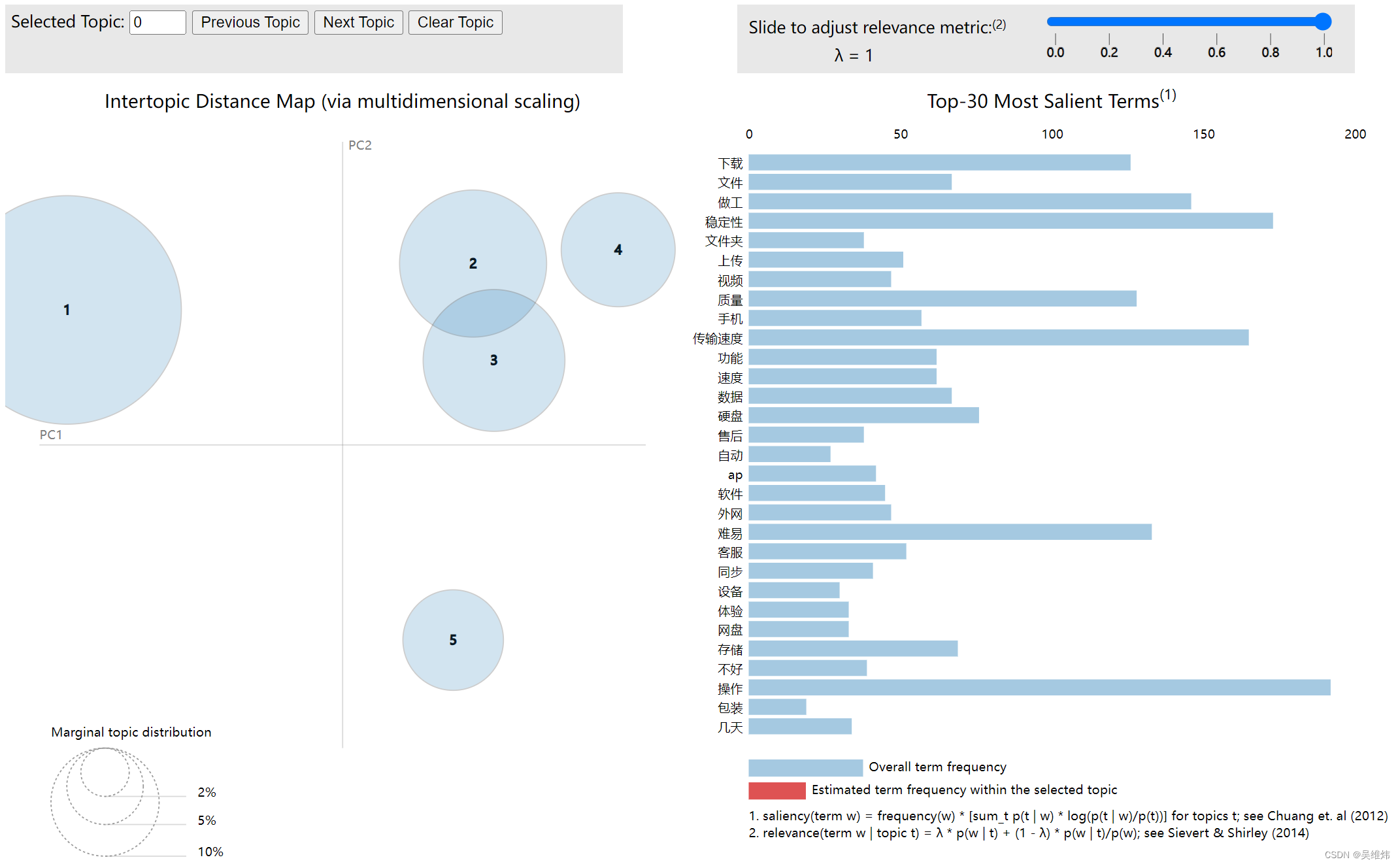
三、执行脚本
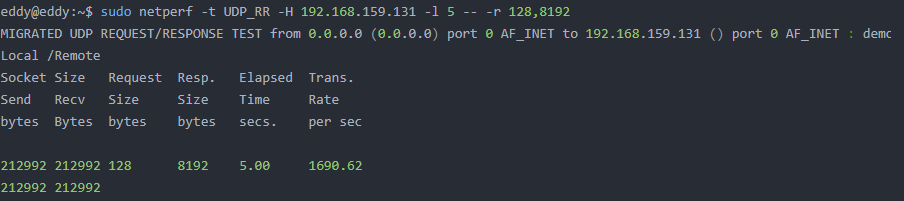
python lda.py
四、关键代码
# LDA主题分析模型
import pandas as pd
import jieba
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation
import pyLDAvis
fileName = "100005785591" # 文件名
# 加载停用词
with open('stopwordsfull', 'r', encoding='utf-8') as f:
stopwords = set([line.strip() for line in f])
# 加载业务域名词
with open('luyouqi.txt', 'r', encoding='utf-8') as f:
business_terms =