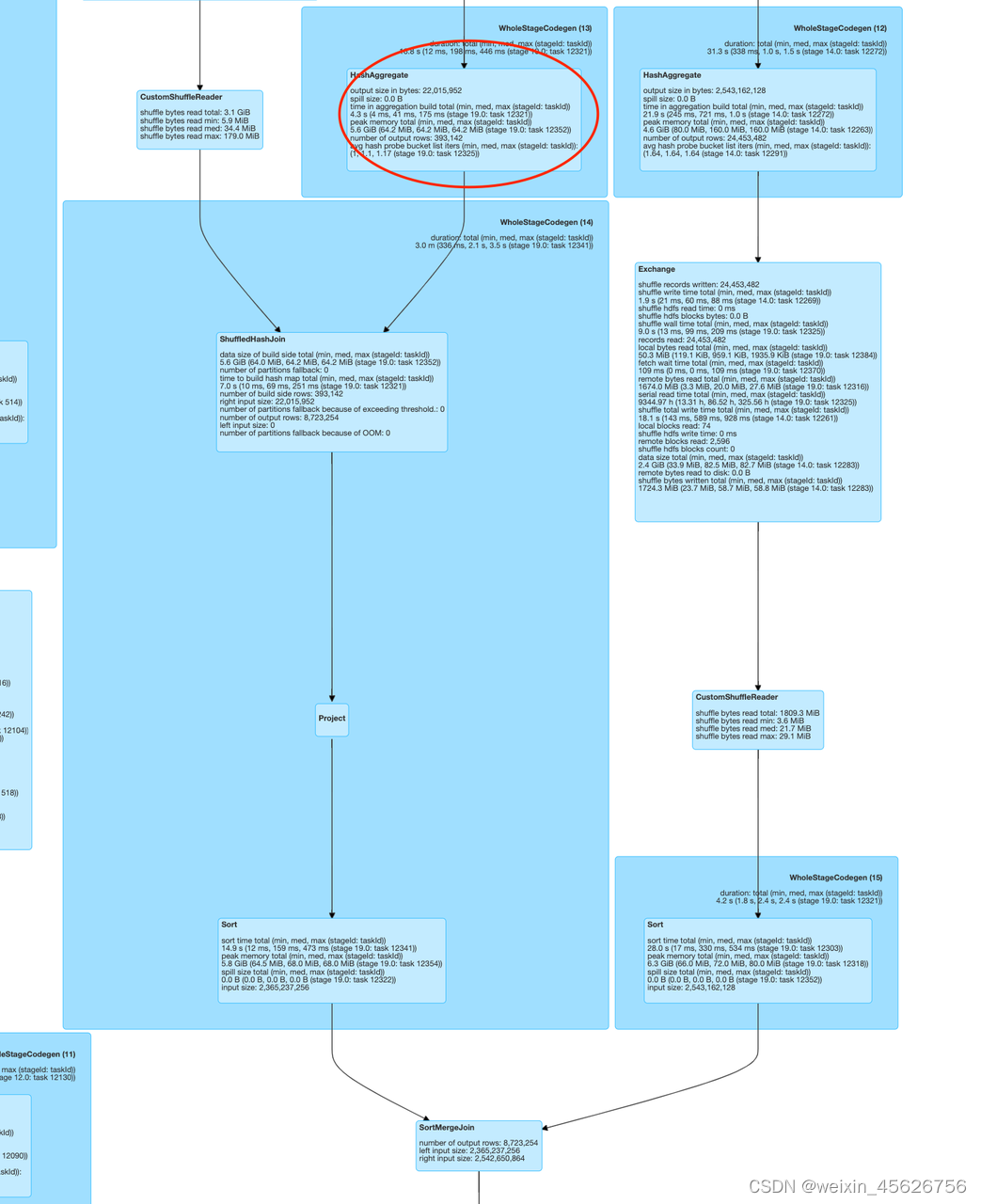
Apache Doris介绍

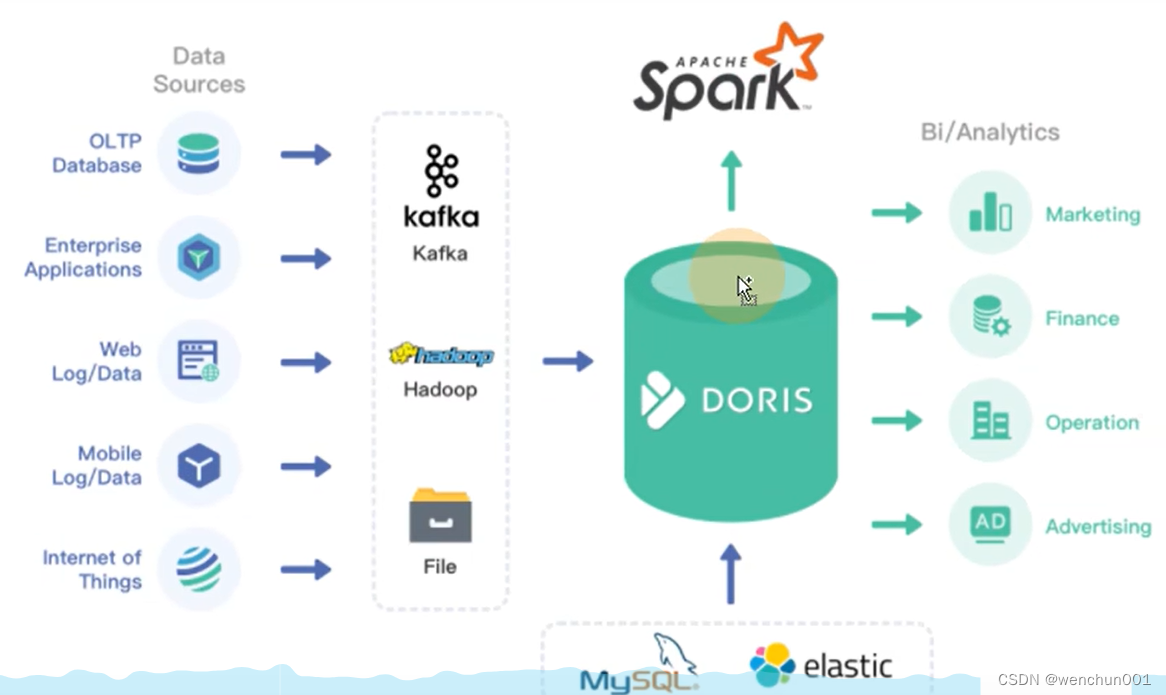
Apache Doris应用场景
Apache Doris核心特性

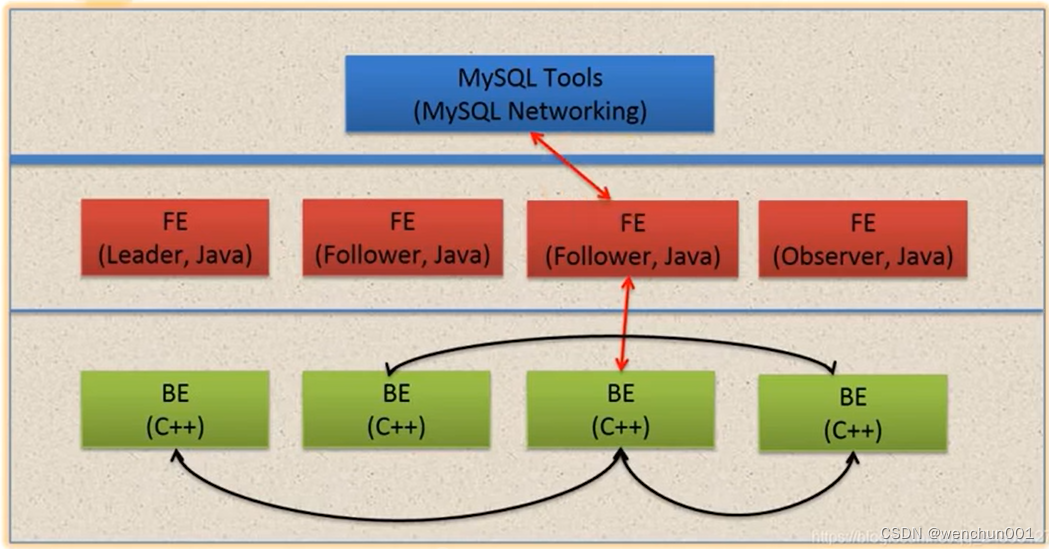
Apache Doris架构
Doris数据模型三种
Aggregate模型介绍


Uniq模型介绍
在某些多维分析场景下,用户更关注的是如何保证Key的唯一性Key 唯一性约束。因此,我们引入了 Unig 的数据模型。该模型本质上是聚合模型的一个特例,也是一种简化的表结构表示方式。
CREATETABLE IF NOT EXISTS
test db.user'
user id' LARGEINT NOT NULL COMMENT“用户id",username VARCHAR(50) NOT NULL COMMENT“用户昵称city’VARCHAR(20) COMMENT“用户所在城市”SMALLINT COMMENT“用户年龄”ageTINYINT COMMENT“用户性别”sex~phone’ LARGEINT COMMENT“用户电话”,VARCHAR(500) COMMENT“用户地址”addressDATETIMECOMMENT“用户注册时间“register time'
UNIQUE KEY(user id'username)DISTRIBUTED IBY HASH(user id )BUCKETS 10;Duplicate 模型介绍
在某些多维分析场景下,数据既没有主键,也没有聚合需求。Duplicate 数据模型可以满足这类需求。数据完全按照导入文件中的数据进行存储,不会有任何聚合。即使两行数据完全相同,也都会保留。 而在建表语句中指定的 DUPLICATEKEY,只是用来指明底层数据按照那些列进行排序。
数据模型-选择建议
因为数据模型在建表时就已经确定,且无法修改。所以,选择一个合适的数据模型非常
重要。
(1)Aggregate 模型可以通过预聚合,极大地降低聚合查询时所需扫描的数据量和查询的计算量,非常适合有固定模式的报表类查询场景。但是该模型对 count(*)查询很不友好同时因为固定了 Value 列上的聚合方式,在进行其他类型的聚合查询时,需要考虑语意正确性。
(2)Uniq 模型针对需要唯一主键约束的场景,可以保证主键唯一性约束。但是无法利用 ROLLUP 等预聚合带来的查询优势(因为本质是REPLACE,没有 SUM这种聚合方式)。
(3)Duplicate 适合任意维度的 Ad-hoc 查询。虽然同样无法利用预聚合的特性,但是不受聚合模型的约束,可以发挥列存模型的优势(只读取相关列,而不需要读取所有 Key 列)
聚合模型局限性
这里我们针对 Aggregate 模型(包括 Uniq 模型),来介绍下聚合模型的局限性。“在聚合模型中,模型对外展现的,是最终聚合后的数据。也就是说,任何还未聚合的数据(比如说两个不同导入批次的数据),必须通过某种方式,以保证对外展示的一致性。








![【线段树】P6492 [COCI2010-2011#6] STEP](https://img-blog.csdnimg.cn/91489698409c4a719676d670f53a8d05.png)