文章目录
- 1.一些杂七杂八的引入
- 2.实现
- 2.1 安装所需python包
- 2.1.1 requests包
- 2.1.1 BeautifulSoup包
- 3.源码分享
- 4.效果展示
1.一些杂七杂八的引入
最近是端午节,本人碰巧又刚考完试(数学砸了,估分115,别的还行)
于是……
于是……
我又开始整活啦~
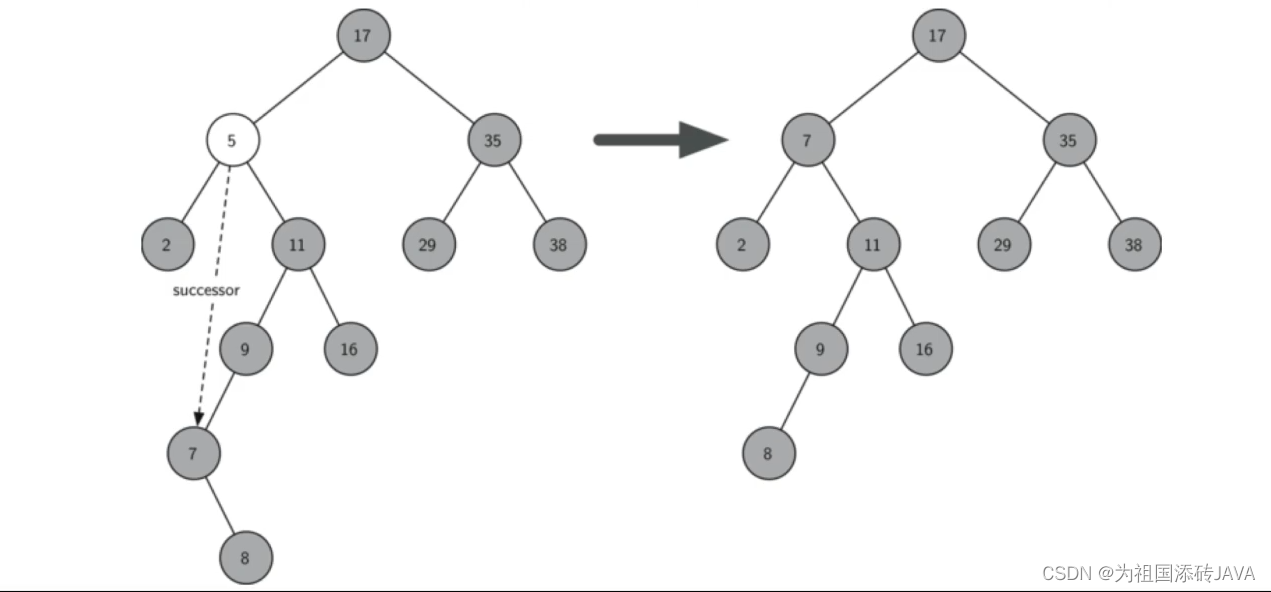
as we all know,一个网页,它是由html写成的,其中必然有许多图片,比如……
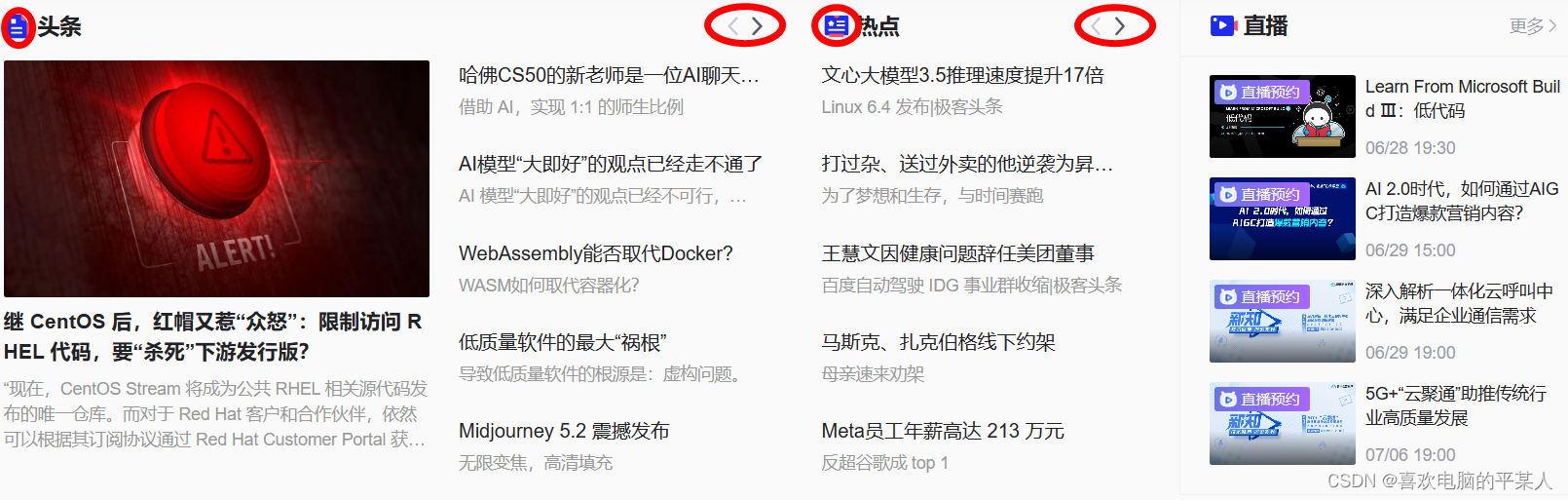
没错,这些都是图片,不信你看……





当然还有很多,比如……

什么,你问我这些图片是哪里来的?
好吧,其实是……

你不会连这个图标都不认识吧?

2.实现
好吧,其实这个类似爬虫的东西用python其实很简单(bushi)
2.1 安装所需python包
2.1.1 requests包
requests用于发送HTTP请求,所以本程序用到了这个库,必须要装,因为……
import requests
我相信稍微了解python的同志们都懂了罒ω罒
安装步骤:
1.按下Win+R,打开“运行”对话框
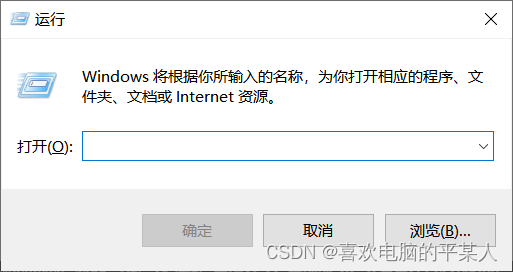
2.输入“cmd”
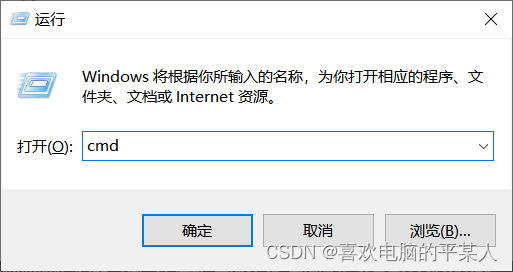
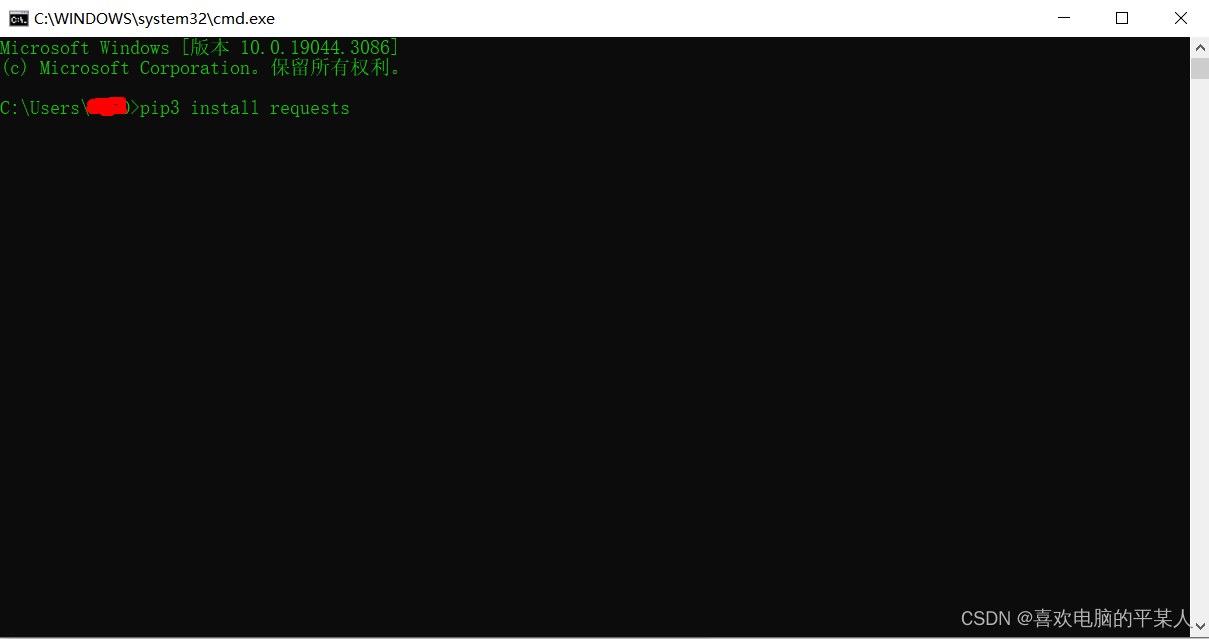
3.单击“确定”,进入cmd命令提示符,输入以下内容:
pip3 install requests#这个是python版本是3点几的同学
pip install requests#这个是python版本是其他的同学
2.1.1 BeautifulSoup包
requests用于解析HTML,所以本程序用到了这个库,必须要装,因为……
from bs4 import BeautifulSoup
我相信稍微了解python的同志们又懂了罒ω罒
安装步骤:
1.按下Win+R,打开“运行”对话框
2.输入“cmd”
3.单击“确定”,进入cmd命令提示符,输入以下内容:
pip3 install beautifulsoup4#这个是python版本是3点几的同学
pip install beautifulsoup4#这个是python版本是其他的同学

3.源码分享
直接上源码:
import requests
from bs4 import BeautifulSoup
import os
def download_images(url):
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
image_tags = soup.find_all('img')
if not os.path.exists('downloaded_images'):
os.makedirs('downloaded_images')
for tag in image_tags:
try:
image_url = tag['src']
if image_url.startswith('http'):
response = requests.get(image_url)
else:
response = requests.get(url + image_url, stream=True)
file_name = os.path.join('downloaded_images', image_url.split('/')[-1])
with open(file_name, 'wb') as f:
f.write(response.content)
print("下载完成:", file_name)
except Exception as e:
print("下载失败:", str(e))
url = input("请输入网址:(By CSDN@喜欢电脑的平某人)")
download_images(url)
4.效果展示
一个自动下载网页图片的python小程序的演示