Pandas 简介
Pandas 是 Python 的核心数据分析支持库,提供了快速、灵活、明确的数据结构,旨在简单、直观地处理关系型、标记型数据。Pandas 的目标是成为 Python 数据分析实践与实战的必备高级工具,其长远目标是成为最强大、最灵活、可以支持任何语言的开源数据分析工具。经过多年不懈的努力,Pandas 离这个目标已经越来越近了。
Pandas 适用于处理以下类型的数据:
- 与 SQL 或 Excel 表类似的,含异构列的表格数据;
- 有序和无序(非固定频率)的时间序列数据;
- 带行列标签的矩阵数据,包括同构或异构型数据;
- 任意其它形式的观测、统计数据集, 数据转入 Pandas 数据结构时不必事先标记。
Pandas 的主要数据结构是 Series(一维数据)与 DataFrame(二维数据),这两种数据结构足以处理金融、统计、社会科学、工程等领域里的大多数典型用例。对于 R 用户,DataFrame 提供了比 R 语言 data.frame 更丰富的功能。Pandas 基于 NumPy 开发,可以与其它第三方科学计算支持库完美集成。
Pandas 就像一把万能瑞士军刀,下面仅列出了它的部分优势 :
- 处理浮点与非浮点数据里的缺失数据,表示为 NaN;
- 大小可变:插入或删除 DataFrame 等多维对象的列;
- 自动、显式数据对齐:显式地将对象与一组标签对齐,也可以忽略标签,在 Series、DataFrame 计算时自动与数据对齐;
- 强大、灵活的分组(group by)功能:拆分-应用-组合数据集,聚合、转换数据;
- 把 Python 和 NumPy 数据结构里不规则、不同索引的数据轻松地转换为 DataFrame 对象;
- 基于智能标签,对大型数据集进行切片、花式索引、子集分解等操作;
- 直观地合并(merge)、**连接(join)**数据集;
- 灵活地重塑(reshape)、**透视(pivot)**数据集;
- 轴支持结构化标签:一个刻度支持多个标签;
- 成熟的 IO 工具:读取文本文件(CSV 等支持分隔符的文件)、Excel 文件、数据库等来源的数据,利用超快的 HDF5 格式保存 / 加载数据;
- 时间序列:支持日期范围生成、频率转换、移动窗口统计、移动窗口线性回归、日期位移等时间序列功能。
这些功能主要是为了解决其它编程语言、科研环境的痛点。处理数据一般分为几个阶段:数据整理与清洗、数据分析与建模、数据可视化与制表,Pandas 是处理数据的理想工具。
其它说明:
- Pandas 速度很快。Pandas 的很多底层算法都用 Cython 优化过。然而,为了保持通用性,必然要牺牲一些性能,如果专注某一功能,完全可以开发出比 Pandas 更快的专用工具。
- Pandas 是 statsmodels 的依赖项,因此,Pandas 也是 Python 中统计计算生态系统的重要组成部分。
- Pandas 已广泛应用于金融领域。
Pandas 数据结构

为什么有多个数据结构?
Pandas 数据结构就像是低维数据的容器。比如,DataFrame 是 Series 的容器,Series 则是标量的容器。使用这种方式,可以在容器中以字典的形式插入或删除对象。
此外,通用 API 函数的默认操作要顾及时间序列与截面数据集的方向。多维数组存储二维或三维数据时,编写函数要注意数据集的方向,这对用户来说是一种负担;如果不考虑 C 或 Fortran 中连续性对性能的影响,一般情况下,不同的轴在程序里其实没有什么区别。Pandas 里,轴的概念主要是为了给数据赋予更直观的语义,即用“更恰当”的方式表示数据集的方向。这样做可以让用户编写数据转换函数时,少费点脑子。
处理 DataFrame 等表格数据时,index(行)或 columns(列)比 axis 0 和 axis 1 更直观。用这种方式迭代 DataFrame 的列,代码更易读易懂:
for col in df.columns:
series = df[col]
# do something with series大小可变与数据复制
Pandas 所有数据结构的值都是可变的,但数据结构的大小并非都是可变的,比如,Series 的长度不可改变,但 DataFrame 里就可以插入列。
Pandas 里,绝大多数方法都不改变原始的输入数据,而是复制数据,生成新的对象。 一般来说,原始输入数据不变更稳妥。
Pandas 入门
本节是帮助 Pandas 新手快速上手的简介。实例里介绍了更多实用案例。
本节以下列方式导入 Pandas 与 NumPy:
import pandas as pd
import numpy as np生成对象
详见数据结构简介文档。
用值列表生成 Series 时,Pandas 默认自动生成整数索引:
import pandas as pd
import numpy as np
s = pd.Series([1, 3, 5, np.nan, 6, 8])
print(s)用含日期时间索引与标签的 NumPy 数组生成 DataFrame:
生成日期索引
import pandas as pd
import numpy as np
dates = pd.date_range('20130101', periods=6)
print(dates)生成DateFrame(合并之前的代码):
import pandas as pd
import numpy as np
dates = pd.date_range('20130101', periods=6)
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD'))
print(df)用 Series 字典对象生成 DataFrame:
import pandas as pd
import numpy as np
df2 = pd.DataFrame({'A': 1.,
'B': pd.Timestamp('20130102'),
'C': pd.Series(1, index=list(range(4)), dtype='float32'),
'D': np.array([3] * 4, dtype='int32'),
'E': pd.Categorical(["test", "train", "test", "train"]),
'F': 'foo'})
print(df2)DataFrame 的列有不同数据类型(合并上面的代码)。
import pandas as pd
import numpy as np
df2 = pd.DataFrame({'A': 1.,
'B': pd.Timestamp('20130102'),
'C': pd.Series(1, index=list(range(4)), dtype='float32'),
'D': np.array([3] * 4, dtype='int32'),
'E': pd.Categorical(["test", "train", "test", "train"]),
'F': 'foo'})
print(df2.dtypes)Pandas 基础用法
本节介绍 Pandas 数据结构的基础用法。下列代码创建上一节(Pandas 数据结构)用过的示例数据对象:
Head 与 Tail
head() 与 tail() 用于快速预览 Series 与 DataFrame,默认显示 5 条数据,也可以指定显示数据的数量
In [4]: long_series = pd.Series(np.random.randn(1000))
In [5]: long_series.head()
Out[5]:
0 -1.157892
1 -1.344312
2 0.844885
3 1.075770
4 -0.109050
dtype: float64
In [6]: long_series.tail(3)
Out[6]:
997 -0.289388
998 -1.020544
999 0.589993
dtype: float64
属性与底层数据
Pandas 可以通过多个属性访问元数据:
- shape:输出对象的轴维度,与 ndarray 一致
- 轴标签Series: Index (仅有此轴)DataFrame: Index (行) 与列
注意: 为属性赋值是安全的!
In [7]: df[:2]
Out[7]:
A B C
2000-01-01 -0.173215 0.119209 -1.044236
2000-01-02 -0.861849 -2.104569 -0.494929
In [8]: df.columns = [x.lower() for x in df.columns]
In [9]: df
Out[9]:
a b c
2000-01-01 -0.173215 0.119209 -1.044236
2000-01-02 -0.861849 -2.104569 -0.494929
2000-01-03 1.071804 0.721555 -0.706771
2000-01-04 -1.039575 0.271860 -0.424972
2000-01-05 0.567020 0.276232 -1.087401
2000-01-06 -0.673690 0.113648 -1.478427
2000-01-07 0.524988 0.404705 0.577046
2000-01-08 -1.715002 -1.039268 -0.370647
Pandas 对象(Index, Series, DataFrame)相当于数组的容器,用于存储数据、执行计算。大部分类型的底层数组都是 numpy.ndarray。不过,Pandas 与第三方支持库一般都会扩展 NumPy 类型系统,添加自定义数组(见数据类型)。
.array 属性用于提取 Index 或 Series 里的数据。
In [10]: s.array
Out[10]:
<PandasArray>
[ 0.4691122999071863, -0.2828633443286633, -1.5090585031735124,
-1.1356323710171934, 1.2121120250208506]
Length: 5, dtype: float64
In [11]: s.index.array
Out[11]:
<PandasArray>
['a', 'b', 'c', 'd', 'e']
Length: 5, dtype: object
array 一般指 ExtensionArray。至于什么是 ExtensionArray 及 Pandas 为什么要用 ExtensionArray 不是本节要说明的内容。更多信息请参阅数据类型。
提取 NumPy 数组,用 to_numpy() 或 numpy.asarray()。
In [12]: s.to_numpy()
Out[12]: array([ 0.4691, -0.2829, -1.5091, -1.1356, 1.2121])
In [13]: np.asarray(s)
Out[13]: array([ 0.4691, -0.2829, -1.5091, -1.1356, 1.2121])
Series 与 Index 的类型是 ExtensionArray 时, to_numpy() 会复制数据,并强制转换值。详情见数据类型。
to_numpy() 可以控制 numpy.ndarray 生成的数据类型。以带时区的 datetime 为例,NumPy 未提供时区信息的 datetime 数据类型,Pandas 则提供了两种表现形式:
- 一种是带 Timestamp 的 numpy.ndarray,提供了正确的 tz 信息。
- 另一种是 datetime64[ns],这也是一种 numpy.ndarray,值被转换为 UTC,但去掉了时区信息。
时区信息可以用 dtype=object 保存。
In [14]: ser = pd.Series(pd.date_range('2000', periods=2, tz="CET"))
In [15]: ser.to_numpy(dtype=object)
Out[15]:
array([Timestamp('2000-01-01 00:00:00+0100', tz='CET', freq='D'),
Timestamp('2000-01-02 00:00:00+0100', tz='CET', freq='D')],
dtype=object)
或用 dtype='datetime64[ns]' 去除。
In [16]: ser.to_numpy(dtype="datetime64[ns]")
Out[16]:
array(['1999-12-31T23:00:00.000000000', '2000-01-01T23:00:00.000000000'],
dtype='datetime64[ns]')
提取 DataFrame 里的原数据稍微有点复杂。DataFrame 里所有列的数据类型都一样时,DataFrame.to_numpy() 返回底层数据:
In [17]: df.to_numpy()
Out[17]:
array([[-0.1732, 0.1192, -1.0442],
[-0.8618, -2.1046, -0.4949],
[ 1.0718, 0.7216, -0.7068],
[-1.0396, 0.2719, -0.425 ],
[ 0.567 , 0.2762, -1.0874],
[-0.6737, 0.1136, -1.4784],
[ 0.525 , 0.4047, 0.577 ],
[-1.715 , -1.0393, -0.3706]])
DataFrame 为同构型数据时,Pandas 直接修改原始 ndarray,所做修改会直接反应在数据结构里。对于异质型数据,即 DataFrame 列的数据类型不一样时,就不是这种操作模式了。与轴标签不同,不能为值的属性赋值。
注意
处理异质型数据时,输出结果 ndarray 的数据类型适用于涉及的各类数据。若 DataFrame 里包含字符串,输出结果的数据类型就是 object。要是只有浮点数或整数,则输出结果的数据类型是浮点数。
以前,Pandas 推荐用 Series.values 或 DataFrame.values 从 Series 或 DataFrame 里提取数据。旧有代码库或在线教程里仍在用这种操作,但 Pandas 已改进了此功能,现在,推荐用 .array 或 to_numpy 提取数据,别再用 .values 了。.values 有以下几个缺点:
- Series 含扩展类型时,Series.values 无法判断到底是该返回 NumPy array,还是返回 ExtensionArray。而 Series.array 则只返回 ExtensionArray,且不会复制数据。Series.to_numpy() 则返回 NumPy 数组,其代价是需要复制、并强制转换数据的值。
- DataFrame 含多种数据类型时,DataFrame.values 会复制数据,并将数据的值强制转换同一种数据类型,这是一种代价较高的操作。DataFrame.to_numpy() 则返回 NumPy 数组,这种方式更清晰,也不会把 DataFrame 里的数据都当作一种类型。
加速操作
借助 numexpr 与 bottleneck 支持库,Pandas 可以加速特定类型的二进制数值与布尔操作。
处理大型数据集时,这两个支持库特别有用,加速效果也非常明显。 numexpr 使用智能分块、缓存与多核技术。bottleneck 是一组专属 cython 例程,处理含 nans 值的数组时,特别快。
请看下面这个例子(DataFrame 包含 100 列 X 10 万行数据):

强烈建议安装这两个支持库,更多信息,请参阅推荐支持库。
这两个支持库默认为启用状态,可用以下选项设置:
0.20.0 版新增。
pd.set_option('compute.use_bottleneck', False)
pd.set_option('compute.use_numexpr', False)
Pandas 数据结构简介
本节介绍 Pandas 基础数据结构,包括各类对象的数据类型、索引、轴标记、对齐等基础操作。首先,导入 NumPy 和 Pandas:
In [1]: import numpy as np
In [2]: import pandas as pd
“数据对齐是内在的”,这一原则是根本。除非显式指定,Pandas 不会断开标签和数据之间的连接。
下文先简单介绍数据结构,然后再分门别类介绍每种功能与方法。
#Series
Series 是带标签的一维数组,可存储整数、浮点数、字符串、Python 对象等类型的数据。轴标签统称为索引。调用 pd.Series 函数即可创建 Series:
>>> s = pd.Series(data, index=index)
上述代码中,data 支持以下数据类型:
- Python 字典
- 多维数组
- 标量值(如,5)
index 是轴标签列表。不同数据可分为以下几种情况:
多维数组
data 是多维数组时,index 长度必须与 data 长度一致。没有指定 index 参数时,创建数值型索引,即 [0, ..., len(data) - 1]。
In [3]: s = pd.Series(np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])
In [4]: s
Out[4]:
a 0.469112
b -0.282863
c -1.509059
d -1.135632
e 1.212112
dtype: float64
In [5]: s.index
Out[5]: Index(['a', 'b', 'c', 'd', 'e'], dtype='object')
In [6]: pd.Series(np.random.randn(5))
Out[6]:
0 -0.173215
1 0.119209
2 -1.044236
3 -0.861849
4 -2.104569
dtype: float64
注意
Pandas 的索引值可以重复。不支持重复索引值的操作会触发异常。其原因主要与性能有关,有很多计算实例,比如 GroupBy 操作就不用索引。
字典
Series 可以用字典实例化:
In [7]: d = {'b': 1, 'a': 0, 'c': 2}
In [8]: pd.Series(d)
Out[8]:
b 1
a 0
c 2
dtype: int64
注意
data 为字典,且未设置 index 参数时,如果 Python 版本 >= 3.6 且 Pandas 版本 >= 0.23,Series 按字典的插入顺序排序索引。
Python < 3.6 或 Pandas < 0.23,且未设置 index 参数时,Series 按字母顺序排序字典的键(key)列表。
上例中,如果 Python < 3.6 或 Pandas < 0.23,Series 按字母排序字典的键。输出结果不是 ['b', 'a', 'c'],而是 ['a', 'b', 'c']。
如果设置了 index 参数,则按索引标签提取 data 里对应的值。
In [9]: d = {'a': 0., 'b': 1., 'c': 2.}
In [10]: pd.Series(d)
Out[10]:
a 0.0
b 1.0
c 2.0
dtype: float64
In [11]: pd.Series(d, index=['b', 'c', 'd', 'a'])
Out[11]:
b 1.0
c 2.0
d NaN
a 0.0
dtype: float64
注意
Pandas 用 NaN(Not a Number)表示缺失数据。
标量值
data 是标量值时,必须提供索引。Series 按索引长度重复该标量值。
In [12]: pd.Series(5., index=['a', 'b', 'c', 'd', 'e'])
Out[12]:
a 5.0
b 5.0
c 5.0
d 5.0
e 5.0
dtype: float64
#Series 类似多维数组
Series 操作与 ndarray 类似,支持大多数 NumPy 函数,还支持索引切片。
In [13]: s[0]
Out[13]: 0.4691122999071863
In [14]: s[:3]
Out[14]:
a 0.469112
b -0.282863
c -1.509059
dtype: float64
In [15]: s[s > s.median()]
Out[15]:
a 0.469112
e 1.212112
dtype: float64
In [16]: s[[4, 3, 1]]
Out[16]:
e 1.212112
d -1.135632
b -0.282863
dtype: float64
In [17]: np.exp(s)
Out[17]:
a 1.598575
b 0.753623
c 0.221118
d 0.321219
e 3.360575
dtype: float64
注意
索引与选择数据一节介绍了 s[[4, 3, 1]] 等数组索引操作。
和 NumPy 数组一样,Series 也支持 dtype。
Pandas 索引和数据选择器
索引和数据选择器
Pandas对象中的轴标记信息有多种用途:
- 使用已知指标识别数据(即提供元数据),这对于分析,可视化和交互式控制台显示非常重要。
- 启用自动和显式数据对齐。
- 允许直观地获取和设置数据集的子集。
在本节中,我们将重点关注最后一点:即如何切片,切块,以及通常获取和设置pandas对象的子集。主要关注的是Series和DataFrame,因为他们在这个领域受到了更多的开发关注。
注意
Python和NumPy索引运算符[]和属性运算符. 可以在各种用例中快速轻松地访问pandas数据结构。这使得交互式工作变得直观,因为如果您已经知道如何处理Python字典和NumPy数组,那么几乎没有新的东西需要学习。但是,由于预先不知道要访问的数据类型,因此直接使用标准运算符会有一些优化限制。对于生产代码,我们建议您利用本章中介绍的优化的pandas数据访问方法。
警告
是否为设置操作返回副本或引用可能取决于上下文。这有时被称为应该避免。请参阅返回视图与复制。chained assignment
警使用浮点数对基于整数的索引进行索引已在0.18.0中进行了说明,有关更改的摘要,请参见此处
见多指标/高级索引的MultiIndex和更先进的索引文件。
有关一些高级策略,请参阅食谱。
#索引的不同选择
对象选择已经有许多用户请求的添加,以支持更明确的基于位置的索引。Pandas现在支持三种类型的多轴索引。
-
.loc主要是基于标签的,但也可以与布尔数组一起使用。当找不到物品时.loc会提高KeyError。允许的输入是:- 单个标签,例如
5或'a'(注意,它5被解释为索引的 标签。此用法不是索引的整数位置。)。 - 列表或标签数组。
['a', 'b', 'c'] - 带标签的切片对象
'a':'f'(注意,相反普通的Python片,都开始和停止都包括在内,当存在于索引中!见有标签切片 和端点都包括在内。) - 布尔数组
- 一个
callable带有一个参数的函数(调用Series或DataFrame)并返回有效的索引输出(上面的一个)。
版本0.18.1中的新功能。
在标签选择中查看更多信息。
- 单个标签,例如
-
.iloc是基于主要的整数位置(从0到length-1所述轴的),但也可以用布尔阵列使用。 如果请求的索引器超出范围,.iloc则会引发IndexError,但允许越界索引的切片索引器除外。(这符合Python / NumPy 切片 语义)。允许的输入是:- 一个整数,例如
5。 - 整数列表或数组。
[4, 3, 0] - 带有整数的切片对象
1:7。 - 布尔数组。
- 一个
callable带有一个参数的函数(调用Series或DataFrame)并返回有效的索引输出(上面的一个)。
版本0.18.1中的新功能。
有关详细信息,请参阅按位置选择,高级索引和高级层次结构。
- 一个整数,例如
-
.loc,.iloc以及[]索引也可以接受一个callable索引器。在Select By Callable中查看更多信息。
从具有多轴选择的对象获取值使用以下表示法(使用.loc作为示例,但以下也适用.iloc)。任何轴访问器可以是空切片:。假设超出规范的轴是:,例如p.loc['a']相当于 。p.loc['a', :, :]

#基础知识
正如在上一节中介绍数据结构时所提到的,索引的主要功能[](也就是__getitem__ 那些熟悉在Python中实现类行为的人)是选择低维切片。下表显示了使用以下方法索引pandas对象时的返回类型值[]:

在这里,我们构建一个简单的时间序列数据集,用于说明索引功能:
In [1]: dates = pd.date_range('1/1/2000', periods=8)
In [2]: df = pd.DataFrame(np.random.randn(8, 4),
...: index=dates, columns=['A', 'B', 'C', 'D'])
...:
In [3]: df
Out[3]:
A B C D
2000-01-01 0.469112 -0.282863 -1.509059 -1.135632
2000-01-02 1.212112 -0.173215 0.119209 -1.044236
2000-01-03 -0.861849 -2.104569 -0.494929 1.071804
2000-01-04 0.721555 -0.706771 -1.039575 0.271860
2000-01-05 -0.424972 0.567020 0.276232 -1.087401
2000-01-06 -0.673690 0.113648 -1.478427 0.524988
2000-01-07 0.404705 0.577046 -1.715002 -1.039268
2000-01-08 -0.370647 -1.157892 -1.344312 0.844885
Pandas 处理文本字符串
Pandas 处理文本字符串
序列和索引包含一些列的字符操作方法,这可以使我们轻易操作数组中的各个元素。最重要的是,这些方法可以自动跳过 缺失/NA 值。这些方法可以在str属性中访问到,并且基本上和python内建的(标量)字符串方法同名:
In [1]: s = pd.Series(['A', 'B', 'C', 'Aaba', 'Baca', np.nan, 'CABA', 'dog', 'cat'])
In [2]: s.str.lower()
Out[2]:
0 a
1 b
2 c
3 aaba
4 baca
5 NaN
6 caba
7 dog
8 cat
dtype: object
In [3]: s.str.upper()
Out[3]:
0 A
1 B
2 C
3 AABA
4 BACA
5 NaN
6 CABA
7 DOG
8 CAT
dtype: object
In [4]: s.str.len()
Out[4]:
0 1.0
1 1.0
2 1.0
3 4.0
4 4.0
5 NaN
6 4.0
7 3.0
8 3.0
dtype: float64
In [5]: idx = pd.Index([' jack', 'jill ', ' jesse ', 'frank'])
In [6]: idx.str.strip()
Out[6]: Index(['jack', 'jill', 'jesse', 'frank'], dtype='object')
In [7]: idx.str.lstrip()
Out[7]: Index(['jack', 'jill ', 'jesse ', 'frank'], dtype='object')
In [8]: idx.str.rstrip()
Out[8]: Index([' jack', 'jill', ' jesse', 'frank'], dtype='object')
索引的字符串方法在清理或者转换数据表列的时候非常有用。例如,你的列中或许会包含首位的白空格:
In [9]: df = pd.DataFrame(np.random.randn(3, 2),
...: columns=[' Column A ', ' Column B '], index=range(3))
...:
In [10]: df
Out[10]:
Column A Column B
0 0.469112 -0.282863
1 -1.509059 -1.135632
2 1.212112 -0.173215
这些字符串方法可以被用来清理需要的列。这里,我们想清理开头和结尾的白空格,将所有的名称都换为小写,并且将其余的空格都替换为下划线:
In [13]: df.columns = df.columns.str.strip().str.lower().str.replace(' ', '_')
In [14]: df
Out[14]:
column_a column_b
0 0.469112 -0.282863
1 -1.509059 -1.135632
2 1.212112 -0.173215
如果你有一个序列,里面有很多重复的值 (即,序列中唯一元素的数量远小于序列的长度),将原有序列转换为一种分类类型,然后使用.str. 或者 .dt.方法,则会获得更快的速度。 速度的差异来源于,在分类类型的序列中,字符操作只是在categories中完成的,而不是针对序列中的每一个元素。
请注意,相比于字符串类型的序列,带.categories类型的 分类 类别的 序列有一些限制(例如,你不能像其中的元素追加其他的字串:s + " " + s 将不能正确工作,如果s是一个分类类型的序列。并且,.str 中,那些可以对 列表(list) 类型的元素进行操作的方法,在分类序列中也无法使用。
警告
v.0.25.0版以前, .str访问器只会进行最基本的类型检查。 从v.0.25.0起,序列的类型会被自动推断出来,并且会更为激进地使用恰当的类型。
一般来说 .str 访问器只倾向于针对字符串类型工作。只有在个别的情况下,才能对非字符串类型工作,但是这也将会在未来的版本中被逐步修正
#拆分和替换字符串
类似split的方法返回一个列表类型的序列:
In [15]: s2 = pd.Series(['a_b_c', 'c_d_e', np.nan, 'f_g_h'])
In [16]: s2.str.split('_')
Out[16]:
0 [a, b, c]
1 [c, d, e]
2 NaN
3 [f, g, h]
dtype: object
切分后的列表中的元素可以通过 get 方法或者 [] 方法进行读取:
In [17]: s2.str.split('_').str.get(1)
Out[17]:
0 b
1 d
2 NaN
3 g
dtype: object
In [18]: s2.str.split('_').str[1]
Out[18]:
0 b
1 d
2 NaN
3 g
dtype: object
使用expand方法可以轻易地将这种返回展开为一个数据表.
In [19]: s2.str.split('_', expand=True)
Out[19]:
0 1 2
0 a b c
1 c d e
2 NaN NaN NaN
3 f g h
Pandas 可视化
import matplotlib.pyplot as pltimport matplotlib.pyplot as plt
# 创建一个画布
fig, ax = plt.subplots(figsize=(10, 5))
# 绘制广州各类天气条形图
ax.bar(df3['新天气'], df3['天数'], width=0.4, label='广州')
# 绘制湛江各类天气条形图
ax.bar(df4['新天气'], df4['天数'], width=0.4, label='湛江', alpha=0.7)
# 设置图例
ax.legend()
# 设置 x 轴标签和标题
ax.set_xlabel('天气类型')
ax.set_ylabel('天数')
ax.set_title('广州和湛江各类天气天数对比')
# 显示图表
plt.show()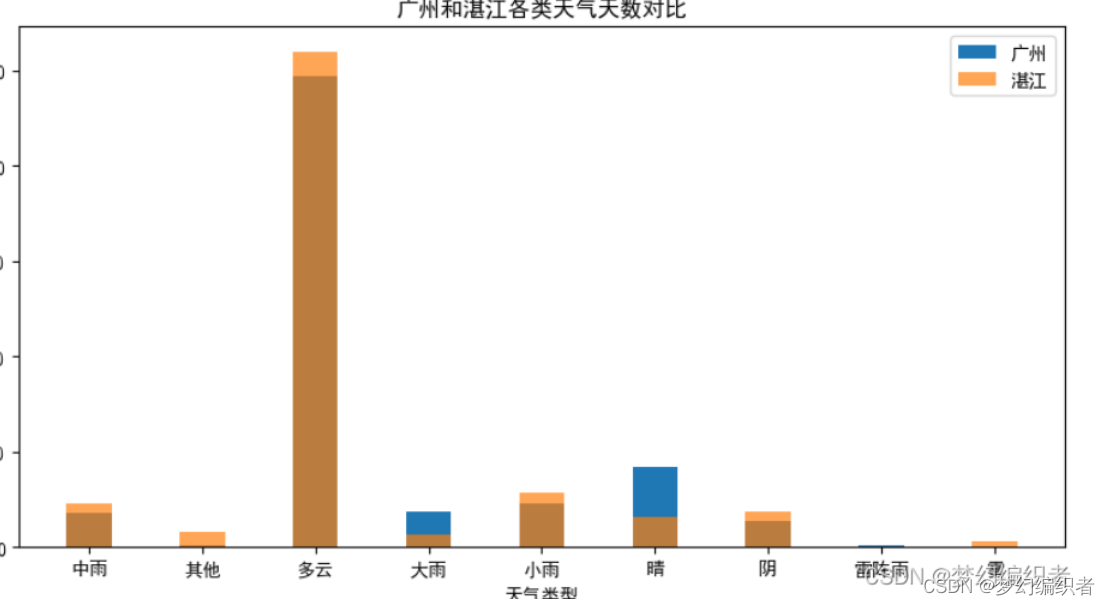
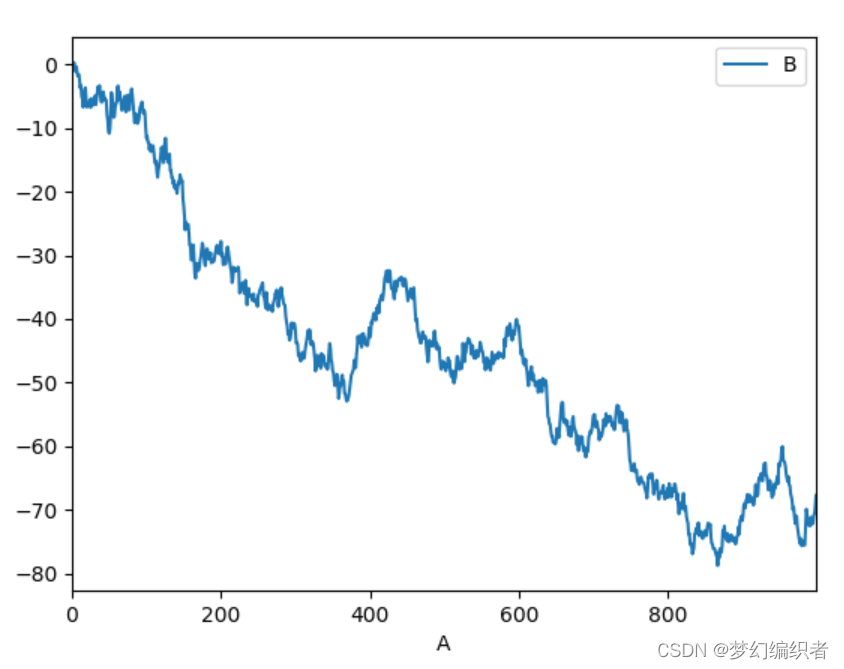
In [6]: df = pd.DataFrame(np.random.randn(1000, 4),
...: index=ts.index, columns=list('ABCD'))
...:
In [7]: df = df.cumsum()
In [8]: plt.figure();
In [9]: df.plot();

In [10]: df3 = pd.DataFrame(np.random.randn(1000, 2), columns=['B', 'C']).cumsum()
In [11]: df3['A'] = pd.Series(list(range(len(df))))
In [12]: df3.plot(x='A', y='B')
Out[12]: <matplotlib.axes._subplots.AxesSubplot at 0x7f65d97c1668>
In [20]: df2 = pd.DataFrame(np.random.rand(10, 4), columns=['a', 'b', 'c', 'd'])
In [21]: df2.plot.bar();

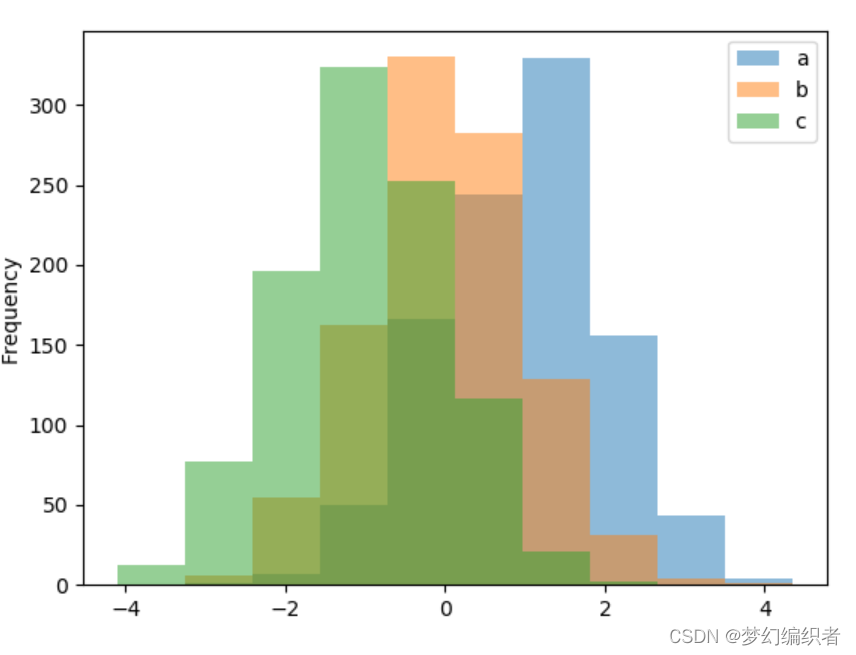
In [24]: df4 = pd.DataFrame({'a': np.random.randn(1000) + 1, 'b': np.random.randn(1000),
....: 'c': np.random.randn(1000) - 1}, columns=['a', 'b', 'c'])
....:
In [25]: plt.figure();
In [26]: df4.plot.hist(alpha=0.5)
Out[26]: <matplotlib.axes._subplots.AxesSubplot at 0x7f65da345e48>
以上就是pandas的功能,期待博主下一篇文章吧