目录
一、优先级队列介绍
1. 什么是大根堆(大堆)和小根堆(小堆)
2. 堆的性质
二、堆的创建
1. 向下调整建堆
向下调整算法代码实现:
2. 创建大根堆
三、堆的插入和删除(向上调整算法)
1. 堆的插入
2. 堆中插入元素代码实现
3. 堆的删除
堆的删除的步骤
3. 堆的删除代码实现
四、堆的模拟实现优先级队列
五、常用接口:PriorityQueue 的介绍
1. 介绍PriorityQueue类
2. PriorityQueue的构造方法
构造方法使用的演示
3. PriorityQueue底层源码详解
4. 如何将标准库中的PriorityQueue(小根堆)变成大根堆
代码实现
解释
六、优先级队列涉及到的TopK问题
1. 找前K个最大的元素 :oj题链接: 寻找第K大_牛客题霸_牛客网
思路
代码实现
2. 找前K个最小的元素
思路
代码实现
前言
上一篇文章已经介绍过队列和Java集合框架中的Queue,队列是一种先进先出的数据结构,但有些情况下操作的数据带有优先级,一般出队列时,可能需要优先级高的元素先出队列,此时,就又引出了另一种关于队列的数据结构,优先级队列。
在上述场景下,数据结构 应该提供两个基本操作,一个时返回最高优先级对象,一个是添加新的对象,此时这种数据结构就是优先级队列。
一、优先级队列介绍
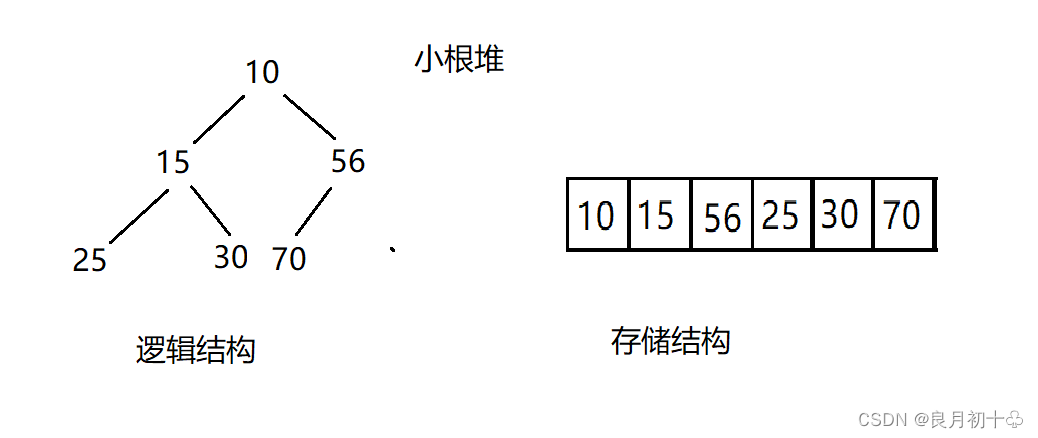
1. 什么是大根堆(大堆)和小根堆(小堆)
堆的本质就是一颗完全二叉树,如上图所示;用顺序存储的方式来进行存储(如果是非完全二叉树,不宜采用顺序方式来存储数据,此时会有数组空间的浪费)。
| 大根堆 | 如果一组数据集合中的所有的元素按照完全二叉树的顺序存储方式来进行存储,并且根节点都大于左右孩子节点,此时这个就称作大根堆。 |
| 小根堆 | 和大根堆类似,本质也是用顺序存储的方式存储的一颗二叉树,并且根节点小于左右孩子节点,此时称作这个堆为小根堆。 |
而优先级队列的本质就是一个大根堆或者小根堆。
2. 堆的性质
| 堆中的某个节点的值总是不大于或者不小于其父亲节点的值。 |
| 堆总是一颗完全二叉树。 |
二、堆的创建
1. 向下调整建堆
以小根堆为例,首先向下调整是从最后一颗子树的根节点开始进行调整,如下图:

向下调整算法代码实现:
注:此时如果是一个需要向下调整很多步才能建好的堆,如何才能保证这个堆调整结束了呢?
就需要每颗子树的位置不能大于顺序存储(数组)的长度。
时间复杂度:logN --> 最坏的情况就是一直从最后一颗子树的根节点一直调整到二叉树的根节点,此时调整的就是树的高度
思路:首先要知道最后一颗子树亲节点和孩子节点,才能向下调整,最后一颗子树的叶子节点就是数组长度-1,其父亲节点就是 (孩子节点-1)/ 2。找到之后进行比较,以小根堆为例:先比较左右孩子谁最小(因为父亲节点要比他俩都小),然后再和父亲节点进行比较,看需否需要交换位置进行向下调整。
/*parent:每棵树的根节点
* len:每颗子树调整的结束位置 不能大于len(这里的参数传过来的是usedSize)*/
private void shiftDown(int parent, int len) {
int child = 2*parent + 1;
//1.必须保证有左孩子
while (child < len) {
//child+1 < len是为了必须保证有右孩子
if (child+1 < len && elem[child] < elem[child + 1]) {
child++;
}
if (elem[parent] < elem[child]) {
int tmp = elem[parent];
elem[parent] = elem[child];
elem[child] = tmp;
//此时只能保证局部是大根堆,但是整体还没有调整结束
parent = child;
child = parent*2 + 1;//child继续是parent的左孩子
}else {
break;//说明此时已经是大根堆
}
}
}2. 创建大根堆
时间复杂度:O(N)(此时计算时间复杂度是用到了错位相减法和求节点个数的公式来推导的,此处就不进行介绍了)
思路:遍历数组中的元素,每次进行比较的时候都要进行向下调整,看是否当前的堆满足大根堆或者小根堆的要求,最后数组中的元素遍历完了之后,也就是一颗大根堆了。
/*建堆的时间复杂度:O(n)(用到错位相减法和求节点个数的公式来推导的)*/
public void createHeap() {
//从最后一个子树的根节点开始进行调整
/*(useSized-2)/2一直孩子节点,推导父亲节点,0下标这棵树也需要进行调整
* parent--是因为从最后一个子树的根节点的下标开始往前走*/
for (int parent = (useSized-2)/2; parent >= 0; parent--) {
/*这里第二个参数是usedSize是因为每次调整之后程序如何才能知道此时调整
* 应该结束了,当定义的孩子下标往下走的时候,发现下标值超过了usedSize
* 此时就说明没有这个孩子节点,此时调整结束*/
shiftDown(parent,useSized);//从每颗子树向下调整
}
}
/*parent:每棵树的根节点
* len:每颗子树调整的结束位置 不能大于len(这里的参数传过来的是usedSize)*/
private void shiftDown(int parent, int len) {
int child = 2*parent + 1;
//1.必须保证有左孩子
while (child < len) {
//child+1 < len是为了必须保证有右孩子
if (child+1 < len && elem[child] < elem[child + 1]) {
child++;
}
if (elem[parent] < elem[child]) {
int tmp = elem[parent];
elem[parent] = elem[child];
elem[child] = tmp;
//此时只能保证局部是大根堆,但是整体还没有调整结束
parent = child;
child = parent*2 + 1;//child继续是parent的左孩子
}else {
break;//说明此时已经是大根堆
}
}
}三、堆的插入和删除(向上调整算法)
1. 堆的插入
| (1)先将元素放入到堆的最后一个节点的位置(也就是数组的有效元素的最后的一个位置)注:此时空间不够时需要进行扩容。 |
| (2)将最后新插入的节点向上调整,直到满足堆的性质 |

如上图所示:此时的调整算法称为向上调整算法,是从最后一个叶子节点开始向上调整,上图是建立一个小根堆,此时最后一个节点 10 不满足小根堆的性质,此时直接和父亲节点进行比较,然后交换,之后一路向上,和父亲节点一直进行比较,最后一直调整到根节点。
2. 堆中插入元素代码实现
注:
| (1)此时数组放满之后要进行扩容。 |
| (2)在判断何时才能向上调整结束的条件时,此时要考虑到根节点可能也是需要进行调整的,所以结束条件就是孩子节点 > 0 时(此时父亲节点下标已经是负数了),向上调整结束。 |
//插入元素 时间复杂度:O(logN) 最大调整树的高度
public void offer(int val) {
if (isFull()) {
//2倍扩容
elem = Arrays.copyOf(this.elem,2*this.elem.length);
}
this.elem[useSized] = val;
useSized++;
//然后想办法重新调整为大根堆
shiftUp(useSized - 1);//这里参数传的是下标
}
//向上调整算法:
private void shiftUp(int child) {
int parent = (child - 1) / 2;
while (child > 0) {//此时0下标的位置也是需要调整的
//但是此时不能是parent > 0,parent为0的时候还没有调整0下标位置的节点
if (elem[child] > elem[parent]) {
int tmp = elem[child];
elem[child] = elem[parent];
elem[parent] = tmp;
//此时还是只是局部是大根堆
child = parent;
parent = (child-1) / 2;
}else {
break;
}
}
}
private boolean isFull() {
return useSized == elem.length;
}3. 堆的删除
堆的删除的步骤:
| 1. 将堆顶元素和堆中的最后一个元素进行交换。 |
| 2. 将堆中有效数据减少一个。 |
| 3. 对堆顶元素进行向下调整。 |
思路:删除的元素一定在大根堆的最后一个位置,也就是数组的最后一个位置;而且删除的元素只能是堆顶元素,所以首先堆顶元素和最后一个叶子节点交换位置,然后删除最后一个位置的元素,有效元素个数 - 1。

3. 堆的删除代码实现
public int pop () {
if (isEmpty()) return -1;
//交换堆顶和最后一个位置的元素
int tmp = elem[0];
elem[0] = elem[useSized - 1];
elem[useSized - 1] = tmp;
useSized--;
//保证它仍然是一个大根堆
shiftDown(0,useSized);
return tmp;//tmp就是删除的元素
}
/*parent:每棵树的根节点
* len:每颗子树调整的结束位置 不能大于len(这里的参数传过来的是usedSize)*/
private void shiftDown(int parent, int len) {
int child = 2*parent + 1;
//1.必须保证有左孩子
while (child < len) {
//child+1 < len是为了必须保证有右孩子
if (child+1 < len && elem[child] < elem[child + 1]) {
child++;
}
if (elem[parent] < elem[child]) {
int tmp = elem[parent];
elem[parent] = elem[child];
elem[child] = tmp;
//此时只能保证局部是大根堆,但是整体还没有调整结束
parent = child;
child = parent*2 + 1;//child继续是parent的左孩子
}else {
break;//说明此时已经是大根堆
}
}
}四、堆的模拟实现优先级队列
Java 集合框架中 PriorityQueue 的底层就是一个小根堆,所以这部分代码和底层的源码大概意思是差不多的。
public class TextHeap {
public int[] elem;
public int useSized;
public static final int DEFAULT_SIZE = 10;
public TextHeap() {
elem = new int[DEFAULT_SIZE];
}
public void initElem(int[] array) {
for (int i = 0; i < array.length; i++) {
elem[i] = array[i];
useSized++;
}
}
/*建堆的时间复杂度:O(n)(用到错位相减法和求节点个数的公式来推导的)*/
public void createHeap() {
//从最后一个子树的根节点开始进行调整
/*(useSized-2)/2一直孩子节点,推导父亲节点,0下标这棵树也需要进行调整
* parent--是因为从最后一个子树的根节点的下标开始往前走*/
for (int parent = (useSized-2)/2; parent >= 0; parent--) {
/*这里第二个参数是usedSize是因为每次调整之后程序如何才能知道此时调整
* 应该结束了,当定义的孩子下标往下走的时候,发现下标值超过了usedSize
* 此时就说明没有这个孩子节点,此时调整结束*/
shiftDown(parent,useSized);//从每颗子树向下调整
}
}
/*parent:每棵树的根节点
* len:每颗子树调整的结束位置 不能大于len(这里的参数传过来的是usedSize)*/
private void shiftDown(int parent, int len) {
int child = 2*parent + 1;
//1.必须保证有左孩子
while (child < len) {
//child+1 < len是为了必须保证有右孩子
if (child+1 < len && elem[child] < elem[child + 1]) {
child++;
}
if (elem[parent] < elem[child]) {
int tmp = elem[parent];
elem[parent] = elem[child];
elem[child] = tmp;
//此时只能保证局部是大根堆,但是整体还没有调整结束
parent = child;
child = parent*2 + 1;//child继续是parent的左孩子
}else {
break;//说明此时已经是大根堆
}
}
}
//插入元素 时间复杂度:O(logN) 最大调整树的高度
public void offer(int val) {
if (isFull()) {
//2倍扩容
elem = Arrays.copyOf(this.elem,2*this.elem.length);
}
this.elem[useSized] = val;
useSized++;
//然后想办法重新调整为大根堆
shiftUp(useSized - 1);//这里参数传的是下标
}
//向上调整算法:
private void shiftUp(int child) {
int parent = (child - 1) / 2;
while (child > 0) {//此时0下标的位置也是需要调整的
//但是此时不能是parent > 0,parent为0的时候还没有调整0下标位置的节点
if (elem[child] > elem[parent]) {
int tmp = elem[child];
elem[child] = elem[parent];
elem[parent] = tmp;
//此时还是只是局部是大根堆
child = parent;
parent = (child-1) / 2;
}else {
break;
}
}
}
private boolean isFull() {
return useSized == elem.length;
}
//删除堆中的元素(一定只能删除堆顶元素)
public int pop () {
if (isEmpty()) return -1;
//交换堆顶和最后一个位置的元素
int tmp = elem[0];
elem[0] = elem[useSized - 1];
elem[useSized - 1] = tmp;
useSized--;
//保证它仍然是一个大根堆
shiftDown(0,useSized);
return tmp;//tmp就是删除的元素
}
public boolean isEmpty() {
return useSized == 0;
}
//查看堆顶元素
public int peek() {
if (isFull()) return -1;
return elem[0];
}
}五、常用接口:PriorityQueue 的介绍(主要介绍源码中是如何实现小根堆以及如何将底层的小根堆建立成一个大根堆)
1. 介绍PriorityQueue类
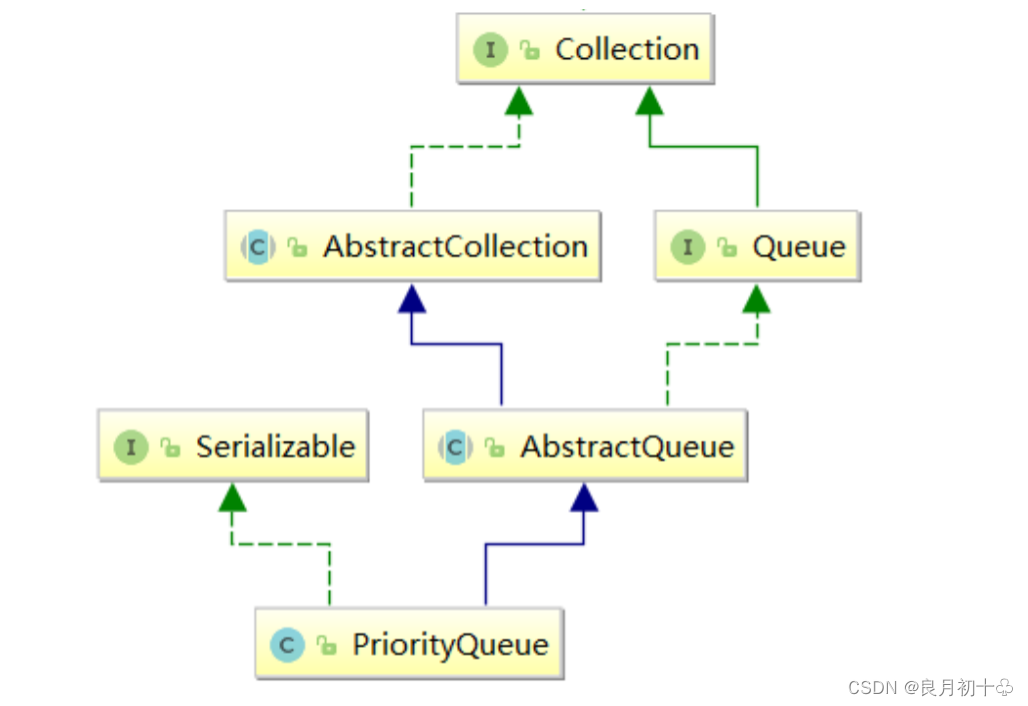
PriorityQueue类继承了Queue接口,所以此时的PriorityQueue接口一定是重写了Queue接口的方法,这里的方法应该比Queue接口中的方法多。
2. PriorityQueue的构造方法

构造方法使用的演示:
class IntCmp implements Comparator<Integer> {
//此时底层的优先级队列就从一个小根堆变成了一个大根堆
@Override
public int compare(Integer o1, Integer o2) {
// return o2 - o1;
return o2.compareTo(o1);
}
}
public static void main2(String[] args) {
//堆(优先级队列) 标准库中的PriorityQueue底层是一个小堆
//如果自己实现了比较器,传一个比较器的参数,此时就是变成了大根堆
PriorityQueue<Integer> queue = new PriorityQueue<>(new IntCmp());//传入一个比较器
queue.offer(30);
queue.offer(20);
queue.offer(3);
System.out.println(queue.poll());
System.out.println(queue.poll());
System.out.println(queue.poll());
}
public static void main(String[] args) {
//传入一个实现了Collection接口的list集合
ArrayList<Integer> list = new ArrayList<>();
PriorityQueue<Integer> queue = new PriorityQueue<>(list);
//参数也可以指定一个默认容量
PriorityQueue<Integer> queue1 = new PriorityQueue<>(222);
}3. PriorityQueue底层源码详解
PriorityQueue minHeap = new PriorityQueue<>();
minHeap.offer(10);
minHeap.offer(10);
minHeap.offer(20);
System.out.println(minHeap.poll());
System.out.println(minHeap.poll());
System.out.println(minHeap.peek());当我们什么参数都没给时,我们可以看下PriorityQueue的源码做了啥:this关键字就是谁调用这个minHeap这个引用谁就是this;可以看到给了一个初始容量11,然后传入了一个空的比较器,


综上图所述 源码的详解,也就是说,当第二次offer元素的时候,如果比第一个offer的元素大,就直接把第二个元素放到数组1下标的位置,第一个元素还是在数组0下标的位置,不用进行交换。
如下图所示:
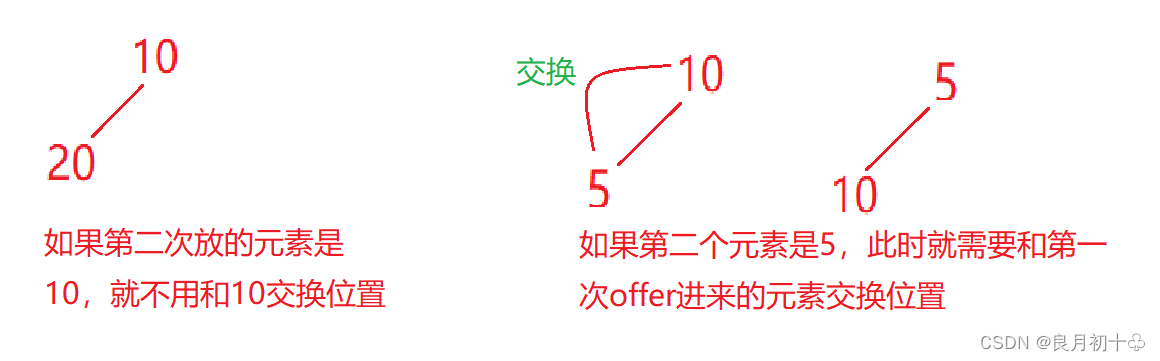
综上所述,PriorityQueue的底层是一个小根堆,
注:不是建堆的时候就一定要用向下调整,在插入和删除元素的时候就一定用向上调整算法,用哪种算法都是可以的。
4. 如何将标准库中的PriorityQueue(小根堆)变成大根堆
代码实现:
PriorityQueue<Integer> maxHeap = new PriorityQueue<>(k, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2.compareTo(o1);
}
});解释:
可以看到刚才源码中默认的比较器比较的方式是: return o1.compareTo(o2); 也就是第一个元素和第二个元素进行比较,如果反过来比较,用第二个元素和第一个元素进行比较,此时的比较器就会正好相反,如果第二个元素大于第一个元素返回一个正数,我们可以看下刚才向上调整的源码: 也就是key 和 e 正好反过来,如果第一次offer一个10,第二次offer一个20,现在key就是20了,e就是10了,if 条件是成立的,也就是10和20 不用交换位置,此时就是一个大根堆了。
private void siftUpComparable(int k, E x) {
Comparable<? super E> key = (Comparable<? super E>) x;
while (k > 0) {
int parent = (k - 1) >>> 1;
Object e = queue[parent];
if (key.compareTo((E) e) >= 0)
break;
queue[k] = e;
k = parent;
}
queue[k] = key;
}六、优先级队列涉及到的TopK问题
1. 找前K个最大的元素 :oj题链接: 寻找第K大_牛客题霸_牛客网
思路:
如果是整体建立一个大根堆(此时堆顶元素最大,就弹出,但是这种方法时间复杂度很高)。
所以另一种思路就是:如果找前K大的元素 -->将数组中前K个元素建立一个小根堆,然后用数组中剩下的元素和堆定元素进行比较,然后重新调整为大根堆。此时如果比堆顶元素大(说明当前堆中的K个元素一定不是最大的),就更新堆顶元素的值,最后比较完数组中剩下的元素,此时堆中就是前K个最大的元素。
代码实现:
public int findKth (int[] arr, int n, int K) {
PriorityQueue<Integer> minHeap = new PriorityQueue<>(K);
for (int i = 0; i < arr.length; i++) {
if (i < K) {
minHeap.offer(arr[i]);//入堆
} else {
int val = arr[i];
if (val > minHeap.peek()) {
minHeap.poll();
minHeap.offer(arr[i]);
}
}
}
return minHeap.peek();
}2. 找前K个最小的元素
思路:
和寻找前K个最大的数据是一样的;如果是找前K个最小的元素 ---> 将数组的前K个元素建立一个大根堆,然后用堆顶元素和数组中剩下的元素进行比较,如果堆顶元素比数组中某一个元素小 此时就更新堆顶元素的值,然后重新调整为小根堆。最后堆中的元素就是前K个最小的元素。
代码实现:
/*时间复杂度:O(N + O(K * logN)),建堆的时间复杂度是O(N),弹出k个元素每次弹出
* 都需要向上调整,时间复杂度:O(K * logN)*/
public int[] smallestK(int[] arr, int k) {
//1.建立一个小根堆
PriorityQueue<Integer> minHeap = new PriorityQueue<>();
//2.取出数组中的每一个元素放到堆中
for (int i = 0; i < arr.length; i++) {
minHeap.offer(arr[i]);
}
int[] tmp = new int[k];
//3.弹出k个元素放进数组中
for (int i = 0; i < k; i++) {
tmp[i] = minHeap.poll();
}
return tmp;
}