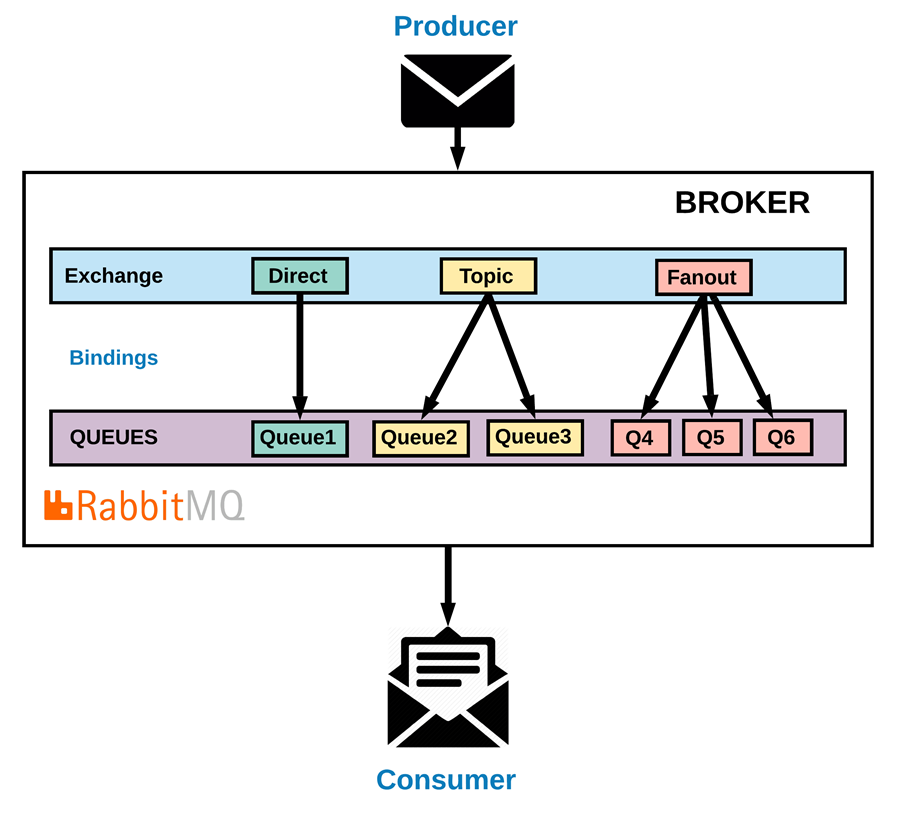
一、决策树的构造
决策树的构造是一个递归的过程,有三种情形会导致递归返回:(1)当前结点包含的样本全属于同一类别,这时直接将该结点标记为叶结点,并设为相应的类别;(2)当前属性集为空,或是所有样本在所有属性上取值相同,无法划分,这时将该结点标记为叶结点,并将其类别设为该结点所含样本最多的类别;(3)当前结点包含的样本集合为空,不能划分,这时也将该结点标记为叶结点,并将其类别设为父结点中所含样本最多的类别。算法的基本流程如下图所示:

可以看出:决策树学习的关键在于如何选择划分属性,不同的划分属性得出不同的分支结构,从而影响整颗决策树的性能。属性划分的目标是让各个划分出来的子结点尽可能地"纯",即属于同一类别。因此下面便介绍量化纯度的具体方法,决策树最常用的算法是三种:ID3,C4.5和CART。
二、ID3算法
ID3算法使用信息增益为准则来选择划分属性,"信息熵(information entropy)"是度量样本结合纯度的常用指标,假定当前样本集合D中第k类样本所占比例为pk,则样本集合D的信息熵定义为:

假定通过属性划分样本集D,产生了V个分支结点,v表示其中第v个分支结点,易知:分支结点包含的样本数越多,表示该分支结点的影响力越大。故可以计算出划分后相比原始数据集D获得的"信息增益(information gain)"。

信息增益越大,表示使用该属性划分样本集D的效果越好,因此ID3算法在递归过程中,每次选择最大信息增益的属性作为当前的划分属性。
缺点:
- 无剪枝策略,容易过拟合;
- 信息熵的设定使得更多取值种类数的特征的信息增益会很大。因为更多取值情况代表了树要分裂非常多的叶子结点,并且每个叶子结点上的样本数很少,越小的数据自己其"纯度"显然越容易高,导致了信息增益会很大。
- 只能用于处理离散分布的特征并且只能处理分类问题
- 没有考虑缺失值
三、C4.5算法
上面我们已经提到了,ID3算法存在一个问题,就是偏向于取值数目较多的属性,例如:如果存在一个唯一标识,这样样本集D将会被划分为|D|个分支,每个分支只有一个样本,这样划分后的信息熵为零,十分纯净,但是对分类毫无用处。因此C4.5算法使用了"增益率"(gain ratio)来选择划分属性,来避免这个问题带来的困扰。增益率定义为:

但是使用增益率可能产生另外一个问题,就是如果属性取值数目较少,我们来想一个比较极端的例子,假如属性只取一个值,属性熵就是0.我们知道一个数除以一个接近0的数,会变成无穷大。所以增益率可能会偏好取值比较少的属性。因此C4.5采用了一个启发式的算法,先从候选属性中找出高于平均水平的属性,再从高于平均水平的属性中选择增益率最高的属性。
3.1 连续值处理
C4.5算法讲连续的属性进行离散化,离散化策略就是二分法。

对于离散变量,在前一轮被当作划分属性之后,下一轮就不能当作候选属性来被选作划分属性了,但是连续变量在这一轮当作划分属性之后,下一轮仍然可以当作候选属性来被选作划分属性。
3.2 缺失值处理
对于缺失值,我们需要解决两个问题:(1)如何在属性值缺失的情况下进行划分属性选择?(2)给定划分属性,若样本在该属性上的值缺失,如何对样本进行划分?


3.3 剪枝处理
从决策树的构造流程中我们可以直观地看出:不管怎么样地训练集,决策树总是能很好地讲各个类别分离开来,这时就会遇到之前提到过地问题:过拟合(overfitting),即太依赖训练样本。剪枝(pruning)则是决策树算法对付过拟合地主要手段,剪枝的策略有两种如下:
- 预剪枝(prepruning):在构造的过程中先评估,再考虑是否分支。
- 后剪枝(post-pruning):在构造好一颗完整的决策树后,自底向上,评估分支的必要性。
评估指的是性能度量,即决策树的泛化性能。之前提到:可以使用测试集作为学习器泛化性能的近似,因此可以讲数据集划分为训练集和测试集。预剪枝表示在构造数的过程中,对一个节点考虑是否分支时,首先计算决策树不分枝时在测试集上的性能,再计算分支之后的性能,若分支对性能没有提升,则选择不分支(即剪枝)。后剪枝则表示再构造好一颗完整的决策树后,从最下面的节点开始,考虑该节点分支对模型的性能是否有提升,若无则剪枝,即将该节点标记为叶子节点,类别标记为其包含样本最多的类别。



上图分别表示不剪枝处理的决策树,预剪枝决策树和后剪枝决策树。预剪枝处理使得决策树的很多分支被剪掉,因此大大降低了训练时间开销,同时降低了过拟合的风险,但另一方面由于剪枝同时剪掉了当前节点后续子节点的分支,因此预剪枝”贪心“的本质阻止了分支的展开,在一定程度上带来了欠拟合的风险。而后剪枝则通常保留了更多的分支,因此采用后剪枝策略的决策树性能往往优于预剪枝,但其自底向上遍历了所有节点,并计算性能,训练时间开销相比预剪枝大大提升。
C4.5算法采用的后剪枝。
C4.5算法虽然解决了ID3的一些缺陷,但是其本身也有一些不足:
(1)C4.5生成的是多叉树,一个父节点可以有多个子节点。计算的时候,运算效率没有二叉树高;
(2)C4.5使用熵模型,里面有大量的对数运算。如果是连续值的属性,还涉及到排序运算,运算量很大。
四、CART(classification and rregression tree)
CART既可以处理分类问题,有可能处理回归问题。对回归树用平方误差最小化准则,对分类树用基尼指数最小化准则,进行特征选择,生成二叉树。
4.1 回归树的生成




每个叶子节点都对应一个样本的小区域,对应的y值就是这些样本的目标值的均值。在预测阶段,一个样本落到一个叶子节点之后,该区域的目标值的均值就是该样本的预测值。
4.2 分类树的生成
分类树用基尼指数选择最优特征,同时决定该特征的最优二值切分点。

因此我们每次都选GINi(D,A)最小的特征A作为划分属性。

4.3 CART剪枝
CART剪枝算法从"完全生长"的决策树的底端剪去一些子树,使决策树变小(模型变简单),从而能够对未知数据有更准确的预测。CART剪枝算法由两步组成:首先从生成算法产生的决策树 �0 底端开始不断剪枝,直到�0的根节点,形成一个子树序列 {�0,�1,...,��} ;然后通过交叉验证法在独立的验证数据集上对子树序列进行测试,从中选择最优子树。

缺失值的处理参考下面的文章:
马东什么:决策树 ID3 C4.5 cart 总结45 赞同 · 16 评论文章正在上传…重新上传取消
马东什么:ID3、c4.5、cart、rf到底是如何处理缺失值的?32 赞同 · 7 评论文章
最后说明下基尼指数、熵、分类误差率三者之间的关系