文章目录
- 1.Kafka集群模式下Broker|主题|分区|副本的概念
- 1.1.Broker|主题|分区|副本的概念
- 1.2.创建一个Topic指定3个副本数
- 1.3.多副本的Topic详细信息描述
- 2.集群模式下以消费者组消费Topic中各分区消息的概念
- 2.1.分消费者组消费各分区的概念
- 2.2.集群模式下消息的发送和消费
- 3.Kafka集群中各组件的概念
- 3.1.Controller组件
- 3.2.Reblance机制
- 3.3.HW和LEO的概念
1.Kafka集群模式下Broker|主题|分区|副本的概念
1.1.Broker|主题|分区|副本的概念
Broker、主题、分区在的概念我们已经全部都了解了,下面来详细描述一下副本的概念。
所谓的副本类似于备份,在创建Topic主题时,需要指定该Topic主题的副本数量,这个副本数量一般是按照集群中Broker的节点数量为依据的,如果集群中有三台节点,那么就存在3个Broker,创建Topic主题时,就指定副本数为3。
Topic副本数可以理解为是分区的备份,如下图所示,主题名称叫做my-rc-topic,指定的副本数为3个、分区数为3个,Topic创建成功后,Topic的三个分区会分别在集群中每个Broker中创建一份,并且会从所有副本分区中选举出一个Leader节点作为主分区,其余各副本分区为Follower节点,拥有Leader角色的副本分区会承担生产者和消费者的读写操作,Leader会定期将数据向各个Follower副本分区进行同步,一旦Leader副本分区挂掉后,Kafka会从剩余的Follower副本分区中进行选举,选举出新的Leader节点,承担发送者和消费者的读写操作。
副本其实就用于将Topic主题中的每个分区在不同的Broker中创建多个备份节点,选举一个副本为Leader节点,其余都是Follower节点,即使集群中某个Broker坏掉,也不会影响数据的读取。
下图可以非常清楚的说明在Kafka集群模式下,Broker、主题、分区和副本是怎样的一个概念。
在集群模式下,每一个Kafka节点充当一个Broker,Broker之间通过ID号进行区分,一个主题中的多个分区会在每一个Broker中创建出副本分区,保障数据的高可靠性。

副本分区中各个角色的作用:
在副本分区中有三个重要角色。
- Leader:承担发送者和消费者的读写操作,负责将消息数据定期同步到Follower副本分区中,当Leader挂掉,经过主从选举,从多个Follower节点中选举出新的Leader。
- Follower:接收Leader节点同步的数据,当Leader挂掉后,进行投票选举,成为新的Leader节点。
- Isr:将正在同步数据的副本和数据同步完成的副本节点都存放在Isr结合中,当某一个节点的性能较差时,会被踢出Isr集合,充分保障集群中的性能。
Broker、Topic、分区、副本连贯起来的概念:
集群模式下会有很多个Broker,创建Topic主题时可以指定主题的分区有多少个,将消息数据拆分到不同的分区中进行存储,增加读写的吞吐量,然后还可以将分区创建出多个副本节点,不同的副本节点存放在不同的Broker里,副本之间进行数据上的同步,保证消息数据的高可靠性。
1.2.创建一个Topic指定3个副本数
1.创建一个多副本的Topic
[root@kafka-1 ~]# /data/kafka/bin/kafka-topics.sh --create --zookeeper 192.168.20.10:2181 --replication-factor 3 --partitions 3 --topic my-rc-topic
Created topic my-rc-topic.
`--replication-factor 3`:指定副本数为3
2.查看Topic的详细信息
[root@kafka-1 ~]# /data/kafka/bin/kafka-topics.sh --describe --zookeeper 192.168.20.10:2181 --topic my-rc-topic
Topic: my-rc-topic PartitionCount: 3 ReplicationFactor: 3 Configs:
Topic: my-rc-topic Partition: 0 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
Topic: my-rc-topic Partition: 1 Leader: 2 Replicas: 2,0,1 Isr: 2,0,1
Topic: my-rc-topic Partition: 2 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2

1.3.多副本的Topic详细信息描述
Topic: my-rc-topic PartitionCount: 3 ReplicationFactor: 3 Configs: Topic: my-rc-topic Partition: 0 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0 Topic: my-rc-topic Partition: 1 Leader: 2 Replicas: 2,0,1 Isr: 2,0,1 Topic: my-rc-topic Partition: 2 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2PartitionCount: 3 分区的数量
ReplicationFactor: 3 副本的数量
Topic: my-rc-topic 主题的名称
指定多少个分区就会打印出多少行,每一行都是一个分区的信息。
Partition: 0 分区的名称,第一个分区为0。
Partition: 1 分区的名称,第二个分区为1。
Partition: 2 分区的名称,第三个分区为2。
Partition: 0 Leader: 1 Leader副本节点位于集群中的哪一个Broker上,这里的1表示第0分区的Leader节点在Broker-1上。
Partition: 1 Leader: 2 Leader副本节点位于集群中的哪一个Broker上,这里的2表示第1分区的Leader节点在Broker-2上。
Partition: 2 Leader: 0 Leader副本节点位于集群中的哪一个Broker上,这里的0表示第2分区的Leader节点在Broker-0上。
Replicas: 1,2,0 副本所在的Broker节点是谁,1表示Broker-1,2表示Broker-2,0表示Broker-0。
Isr: 1,2,0 Isr集合,包含同步的Broker节点和已经同步完成的Broker节点,1表示Broker-1,2表示Broker-2,0表示Broker-0,第一位是该副本分区中的Leader,第二位是Controller,第三位是同步没问题的Broker。
。
创建完多副本后,分区的副本会在每一个Kafka节点上都进行持久化存储。
2.集群模式下以消费者组消费Topic中各分区消息的概念
2.1.分消费者组消费各分区的概念
单分区的Topic消费概念分为单播模式和多播模式,适合单节点模式,在集群模式下会有多副本和多分区的概念,接下来我们来看看多分区下消费者消费数据的概念。
如下图所示:
Topic划分了4个Partition分区,分别是Partition0、Partition1、Partition2、Partition3,消费方有两个消费者组,消费组A中有2个消费者,消费组B中有4个消费者,同一组下的每个消费者会对不同的分区进行消费,同一组下只能有一个消费者去消费Topic中的某一个分区,这点与单播的概念一致。
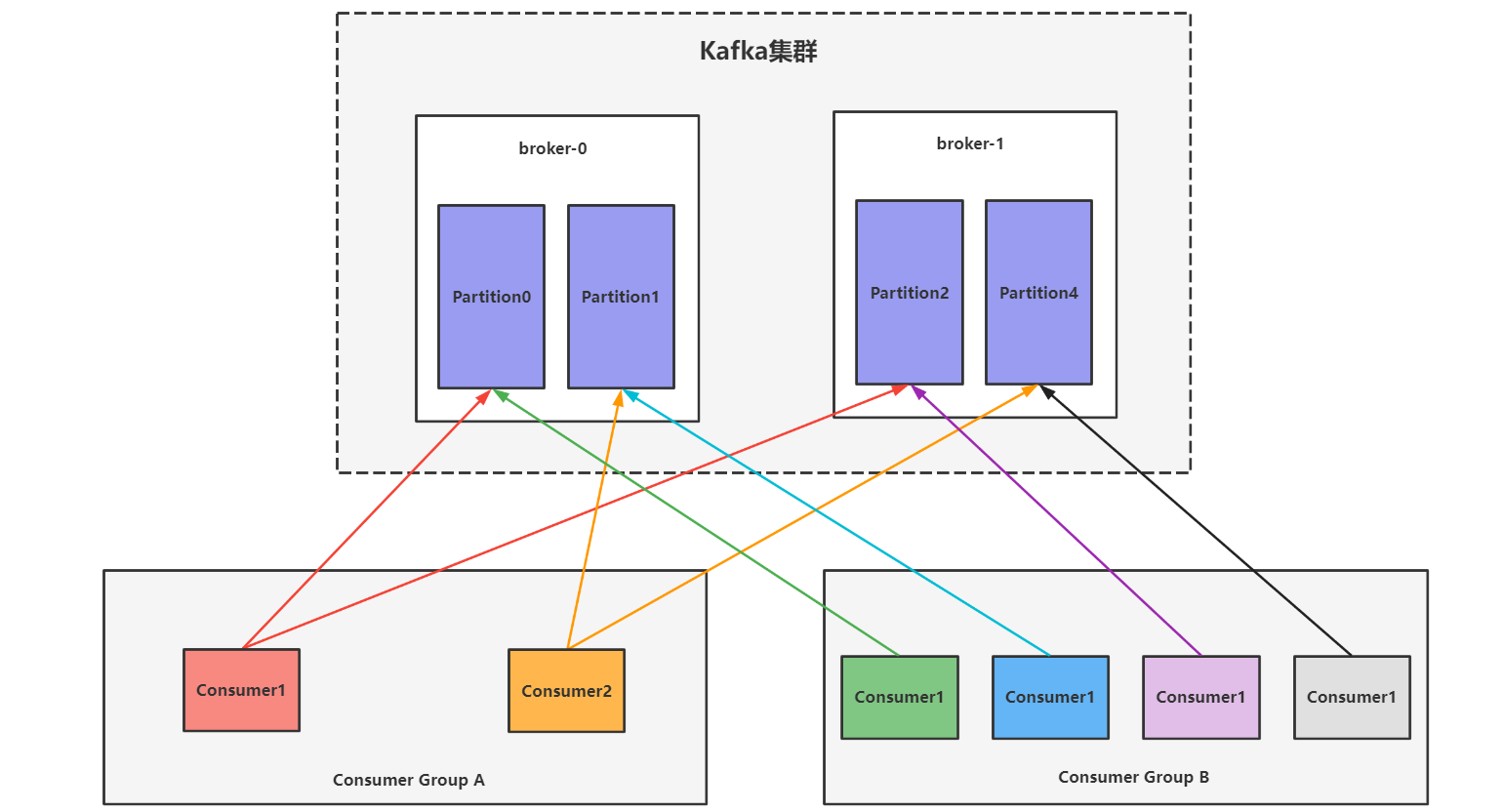
多分区消费的概念:
- Topic中一个Partition分区只能被一个消费者组中的某一个消费者进行消费,和单播概念一致。
- 同一组中的每个消费者都可以同时消费不同的Topic分区,但是一个Topic只能被一个组中的某一个消费者进行消费。
- 消费者一对多,分区一对一。
- Partition分区的数量是可以决定消费组中消费者的数量,建议统一组中消费者的数量不要超过分区的数量,最好可以和分区数量保持一致,这样一来一个消费者就可以对一个分区进行消费,当然少几个也是没有问题的,一个消费者可以对多个分区进行消费,但是消费者不要超过分区的数量,多出来的消费者不会去消费数据,反而会影响性能。
- 如果组中某一个消费者挂了,那么二舅会触发rebalance机制,让其他消费者来消费该分区。
为什么不让消费者组中多个消费者同时消费一个分区呢?
这样做的目的是为了保证消息消费的顺序性,如果多个一组中多个消费者同时消费该分区的数据,那么就会因为网络波动的原因,从而导致消息的错误消费,影响业务逻辑。
2.2.集群模式下消息的发送和消费
1)发生消息数据
[root@kafka-1 bin]# ./kafka-console-producer.sh --broker-list 192.168.20.10:9092,192.168.20.11:9092,192.168.20.12:9092 --topic my-rc-topic
>jiangxl nihao
>
>hahaha
>
>hello
2)消费消息数据
[root@kafka-1 bin]# ./kafka-console-consumer.sh --bootstrap-server 192.168.20.10:9092,192.168.20.11:9092,192.168.20.12:9092 --from-beginning --topic my-rc-topic

3.Kafka集群中各组件的概念
在Kafka集群模式下有三个重要组件:Controller、Rabalance、HW。
3.1.Controller组件
每个Broker启动后会向Zookeeper集群中创建一个临时序号节点,获得序号最小的那个Broker将会成为集群中的Controller节点。
Controller节点的作用如下:
-
当集群中Topic分区中Leader副本挂掉后,Controller节点会在集群中选举出一个新的Leader,选举规则是将Isr集合中最左边的Broker选举为Leader节点。
-
如下图所示:Isr集合中最左侧的是Leader所在的Broker号,当Leader挂掉后,Controller会在Isr集合中将挂掉的Broker删除,此时就会剩下2个Broker,最左侧的那个Broker就会成为新的Leader,如篮框所示。
-

-
-
当集群中有Broker新增或者减少,Controller会同步信息到其他的Broker。
-
当集群中有分区新增或者减少时,Controller会同步信息给其他Broker。
3.2.Reblance机制
当消费组中的消费者没有明确指明要消费的Topic分区,或者消费者正在消费某个分区时该消费者突然挂掉,这两种情况都会触发Reblance机制。
Reblance机制会在消费者和分区的关系发生变化后,重新调整消费者消费哪个分区。
在触发Rebalance机制之前,消费者消费哪个分区有三种策略:
- range:根据公式计算得到每个消费者消费的分区列表。
- 触发前的公式:分区总数量/消费者数量+1。
- 触发后的公式:分区总数量/消费者数量。
- 轮询:所有消费者轮流消费分区中的数据
- sticky:粘合策略,触发了Rebalance机制后,会在之前分配的基础上在做调整,不会改变之前的分配情况,只会故障的消费者关联的分区,进行分配。
- 粘合策略必须开启,如果不开始,触发Rebalance机制后,会将正常的分区与消费者都进行重新分配,损耗集群的性能。
3.3.HW和LEO的概念
HW俗称高水位,LEO是某个副本中最后一条消息的消息位置。
HW高水位线会位于所有副本分区中数据已经同步完成的位置,如下图所示,HW高水位线就会位于消息数据4下面,消息数据5已经写入到Leader副本分区中了,但是还没有同步到其他副本中,HW高水位线此时不会往下移动产生变化,只有当消息数据全部同步完成后,HW高水位线才会更新往下移动,这时消费者才可以去消费消息5,这样做的目的是防止消息数据会丢失。
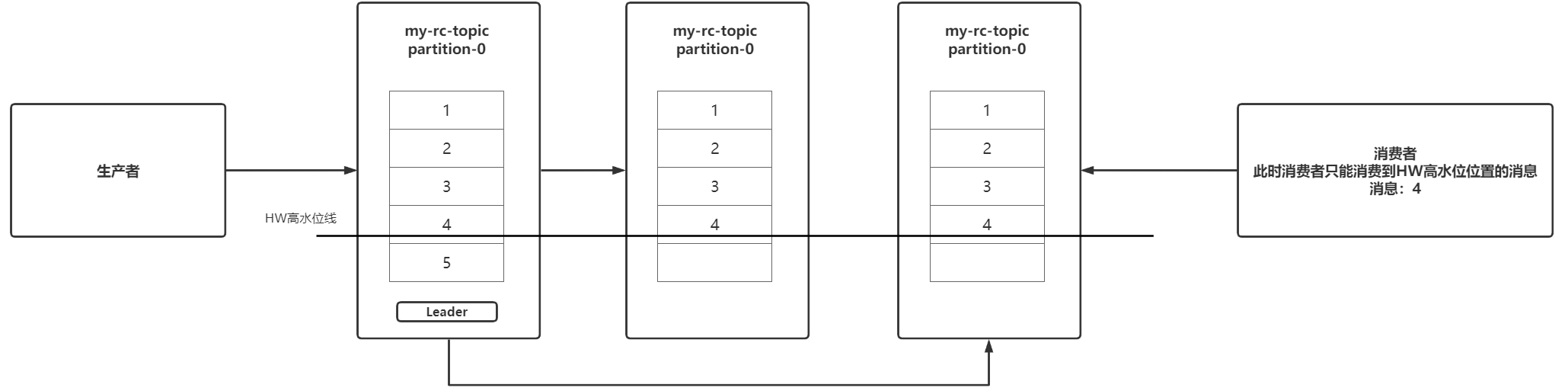
消费者最多只能消费到HW所在的位置。另外每个副本都有HW,leader和follower各自负责更新自己的HW的状态。对于leader新写入的消息,消费者不能立刻消费,leader会等待该消息被所有ISR中的副本同步后才会更新HW,此时消息才能被消费者消费。这样就保证了如果leader所在的broker失效,该消息仍然可以从新选举的leader中获取。