前言
MQ消息是目前分布式系统必不可少的组件,但是面对市面上众多的MQ组件,我们该用什么呢?我以实际项目的需求触发,介绍今天的主角——rabbitMQ。同时也会告知又有哪些优势和不足。事不宜迟,就开始今天的学习吧
目录
一、MQ及MQ组件
1. MQ的解释与用处
2. 几款常用的MQ框架简介
二、RabbitMQ的特点
1. RabbitMQ的模型与优势
2. 与kafka的对比
3. 为什么选择RabbitMQ?
4. 不可避免的弊端
一、MQ及MQ组件
1. MQ的解释与用处
如果你已经对MQ有所了解,想必对其用途已经了然于胸了。如果你仅仅是听说过,或许可以直白的描述它,它就相当于日常生活中的社交软件的消息,可以通过它把信息发给对方。特点是不如电话那么及时,但可以群发,即使对方不在线,等其上线照样可以获得该信息。当然,从架构角度消息归纳起来有以下几种好处
-
解耦应用程序: 使用MQ,应用程序之间可以通过中间件进行通信,这样应用程序之间的连接就成为松散的,即使一方出现问题也不会影响其他应用程序的正常运行。
-
提高系统可靠性:MQ允许将消息存储在队列中,这样如果一个应用程序出现故障,消息也不会丢失。在应用程序恢复正常运行后,它可以从队列中读取并处理这些消息。
-
增加系统伸缩性:MQ允许多个应用程序同时访问同一个队列,这样就可以轻松地添加更多消费者来处理消息,从而实现水平扩展。
-
支持异步处理:使用MQ,发送者可以异步发送消息到队列中,接收者可以在自己的时间内获取并处理这些消息,从而提高系统的性能和响应速度。
-
支持多种协议和消息格式:MQ支持多种协议和消息格式,如AMQP、JMS、Kafka等,可根据需要选择合适的协议和格式。
2. 几款常用的MQ框架简介
除了我们今天的主角rabbitMQ,目前市面上还有几款消息中间件是比较流行的,如ActiveMQ、Apache Kafka、以及阿里的RocketMQ,我们以一张简表速览一下
| 特性 | ActiveMQ | RabbitMQ | RocketMQ | kafka |
| 开发语言 | java | erlang | java | scala |
| 单机吞吐量 | 万级 | 万级 | 10万级 | 10万级 |
| 时效性 | ms级 | us级 | ms级 | ms级以内 |
| 可用性 | 高(主从架构) | 高(主从架构) | 非常高(分布式架构) | 非常高(分布式架构) |
| 功能特性 | 成熟的产品,在很多公司得到应用;有较多的文档;各种协议支持较好 | 基于erlang开发,所以并发能力很强,性能极其好,延时很低;管理界面较丰富 | MQ功能比较完备,扩展性佳 | 只支持主要的MQ功能,像一些消息查询,消息回溯等功能没有提供,毕竟是为大数据准备的,在大数据领域应用广。 |
上述四种是最常用的MQ组件了,当然一个工程,根据要求可以同时运用多种框架,毕竟框架之间使用场景有所差异。
二、RabbitMQ的特点
1. RabbitMQ的模型与优势
我们先来看看RabbitMQ的模型图,其主要有交换机(Exchange)、队列(Queue)两个组件构成。然后通过绑定和路由配置来实现多种传递方式,可以说功能十分强大
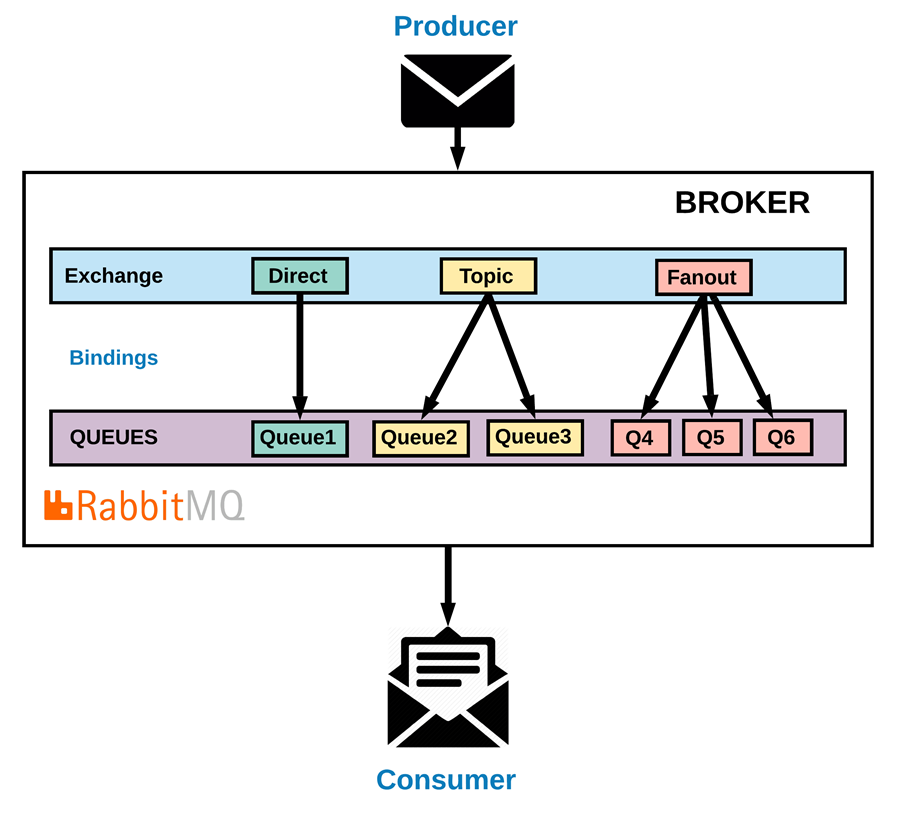
更具体的说,其具备以下特点:
- AMQP支持:RabbitMQ 实现了 AMQP,这是一个强大的开放标准消息协议,支持多语言和平台。
- 可靠性:RabbitMQ 提供了丰富的特性来保证消息的可靠性,包括消息确认、持久化、镜像队列、备份队列等。
- 灵活性:RabbitMQ 支持多种消息模式,如点对点、发布/订阅、任务队列、RPC等,满足各种应用场景的需求
- 扩展性:RabbitMQ 拥有分布式架构,支持高可用和集群部署,可以实现水平和垂直扩展
- 监控和管理:RabbitMQ 提供了 web 控制台和命令行工具,方便用户对队列状态进行监控和管理。
- 社区支持:RabbitMQ 的用户社区非常活跃,提供了大量的文档和教程,有问题可以很快得到解决
2. 与kafka的对比
kafka严格的讲,并不是一款MQ框架,也没有实现 AMQP 协议。更确切的说,kafka是一款分布式流处理平台,以高吞吐量、低延迟和可靠性为特点,适用于大规模数据处理和实时数据集成,但我们仍然可以把它作为一种消息中间件来使用,我们来看下它与rabbitMQ的详细对比:
| 对比项 | kafka | rabbitmq |
| 单机吞吐量 | 10万级 | 万级 |
| 时效性 | ms级以内 | us级(微秒级) |
| 是否支持消息回溯 | 支持消息回溯,因为消息持久化,消息被消费后会记录offset和timstamp | 不支持,消息确认被消费后,会被删除 |
| 是否支持消息数据持久化 | 支持消息数据持久 | 支持消息数据持久 |
| 优先级队列 | 不支持 | 支持。建议优先级大小设置在0-10之间。 |
| 延迟队列 | 不支持 | 支持 |
| 重试队列 | 不支持。 | 不支持RabbitMQ中可以参考延迟队列实现一个重试队列,二次封装比较简单。如果要在Kafka中实现重试队列,首先得实现延迟队列的功能,相对比较复杂。 |
| 是否支持消息堆积 | 支持消息堆积,并批量持久化到磁盘 | 支持阈值内的消息对接,无法支持较大的消息堆积 |
| 是否支持流量控制 | 支持控制用户和客户端流量 | 支持生产者的流量控制 |
| 开发语言 | scala,Java | erlang |
| 是否支持多租户 | 2.x.x支持多租户 | 支持多租户 |
| 是否支持topic优先级 | 不支持 | 支持 |
| 是否支持消息全局有序 | 不支持 | 支持 |
| 是否支持消息分区有序 | 支持 | 支持 |
| 是否内置监控 | 无内置监控 | 内置监控 |
| 是否支持多个生产者 | 一个topic支持多个生产者 | |
| 是否支持多个消费者 | 一个topic支持多个消费者 | |
| 是否支持一个分区多个消费者 | 不支持 | 不支持 |
| 是否支持JMX | 支持 | 不支持(非java语言编写) |
| 是否支持加密 | 支持 | 支持 |
| 消息队列协议支持 | 仅支持自定义协议 | 支持AMQP、MQTT、STOMP协议 |
| 客户端语言支持 | 支持多语言客户端 | 支持多语言客户端 |
| 是否支持消息追踪 | 不支持消息追踪 | 支持消息追踪 |
| 是否支持消费者推/拉模式 | 拉模式 | 推模式+拉模式 |
| 是否支持广播消息 | 支持广播消息 | 支持广播消息 |
| 元数据管理 | 通过zookeeper进行管理 | 支持消息数据持久 |
| 默认服务端口 | 9200 | 5672 |
| 默认监控端口 | kafka web console 9000;kafka manager 9000; | 15672 |
| 网络开销 | 相对较小 | 相对较大 |
| 内存消耗 | 相对较小 | 相对较大 |
| cpu消耗 | 相对较大 | 相对较小 |
3. 为什么选择RabbitMQ?
什么时候才能选rabbitMQ作为自己系统的中间件呢?我可以举一个实例
我们系统在过去有大量的同步调用,而且因为下游的实现语言有很多种,有java、C# 、PHP等。所以同步调用其实采用的自研协议,但是同步调用加自研协议的性能,带来的一个问题就是链路很耗时,硬件利用率低,给用户的印象就是卡和延迟,因此急需缩短链路上的耗时,但因为承担的核心系统间的调用功能,所以业务的可靠性需要极高的保障,而且下游真的出现问题要能及时发现和通知。
针对这种场景,那么我们就需要一款消息组件来作为异步调用中转,而且该组件需要有可靠性。那么它应当有以下几种功能:
- 消息可靠,要求消息全程都能有保障,消息能落在硬盘上
- 下游多语言的支持
- 对下游有容错,消息有自动重发能力。
- 支持一条消息被多个下游消费,且下游数量可随意增减
- 消息支持轮流消费和广播两种能力
- 有方便的管理界面,进行总体情况的查看
- 灵活的消息传递路径
- 社区活跃,有问题方便解决
其中有几种是MQ组件独有的能力,比如有消息重发的能力,这一点Kafka就得开发者自己去搞定了,所以kafka首先排除。
然后是RocketMQ,RocketMQ其实顺序消息和实时性方面更加优秀,但一个是下游多语言,一个是社区活跃度就稍有不足了,尤其是rocketMQ目前仅支持java及c++,这一点是致命伤,所以用不了RocketMQ
同样的,ActiveMQ也是个成熟的项目,支持多语言而且功能完善,但也有问题,就是其界面支持比较弱。另外现在Apache的工作中心在其下一代Apollo,社区活跃度也下降了,所以ActiveMQ后续的长期维护肯定不方便的,被排除
如此一来,只剩一个水桶选择了,那就是rabbitMQ,它满足了我们需要种种功能,社区活跃度还高,支持多种模型和管理都是加分项,而且延迟很低
4. 不可避免的弊端
尽管我们最后选了RabbitMQ,但也不能忽视其存在的问题:
使用的学习成本:其基于AMQP的协议,有着交换机和队列及绑定操作,以及多种路由规则,并不是傻瓜式的上手就能掌握。
排查的成本,RabbitMQ的性能和可靠性是使用Erlang语言的结果,但这也使得它的维护成本较高,因为Erlang相对于其他编程语言使用较少,而且维护排查问题的成本较高
限制较多:RabbitMQ限制了消息的大小、队列数量、连接数量等,这可能在一些特定场景下对业务造成限制。