模型介绍:
该系列模型在通用中文基座模型(如 Chinese-LLaMA、ChatGLM 等)的基础上扩充法律领域专有词表、大规模中文法律语料预训练,增强了大模型在法律领域的基础语义理解能力。在此基础上,构造法律领域对话问答数据集、中国司法考试数据集进行指令精调,提升了模型对法律内容的理解和执行能力。
开源仓库:https://github.com/pengxiao-song/LaWGPT
我的运行环境:Pytorch 1.9.1 Ubuntu
1 * NVIDIA T4 32G
1、安装conda环境
wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-2023.03-Linux-x86_64.sh
bash Anaconda3-2023.03-Linux-x86_64.sh
设置环境变量
export PATH="/home/ubuntu/anaconda3/bin:$PATH"
source ~/.bashrc
2、clone模型安装依赖
# 下载代码
git clone git@github.com:pengxiao-song/LaWGPT.git
cd LaWGPT
# 创建环境
conda create -n lawgpt python=3.10 -y
conda activate lawgpt
pip install -r requirements.txt
3、安装模型推理所需包
conda install cudatoolkit
conda install scipy
conda insatll chardet
4、运行webui界面
bash scripts/webui.sh
注意,这一步需要使用huggingface上已经训练好的模型,我的服务器是新加坡地区访问可以正常下载,国内的服务器可能会出现下载卡顿,总共14G左右的模型
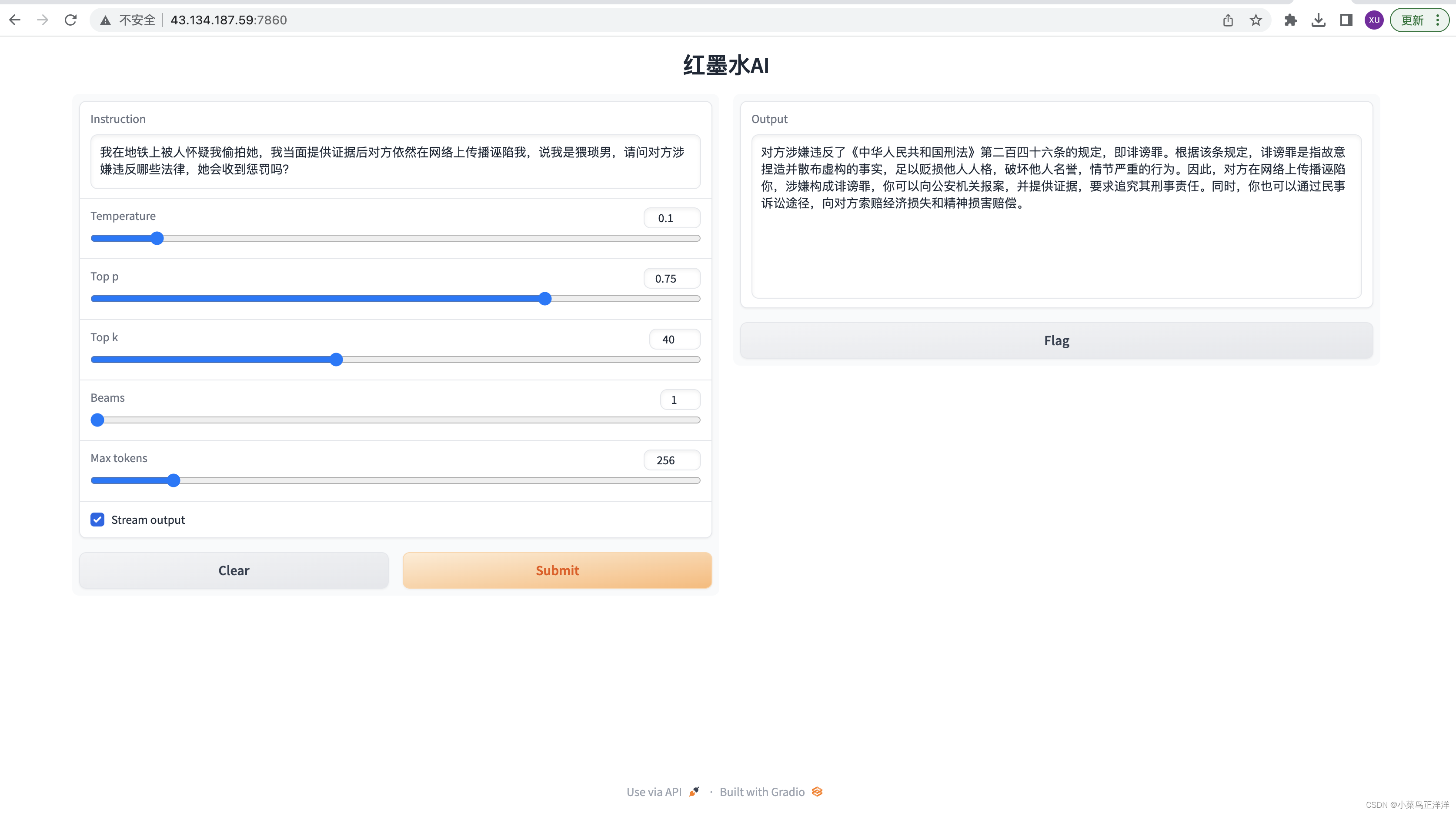
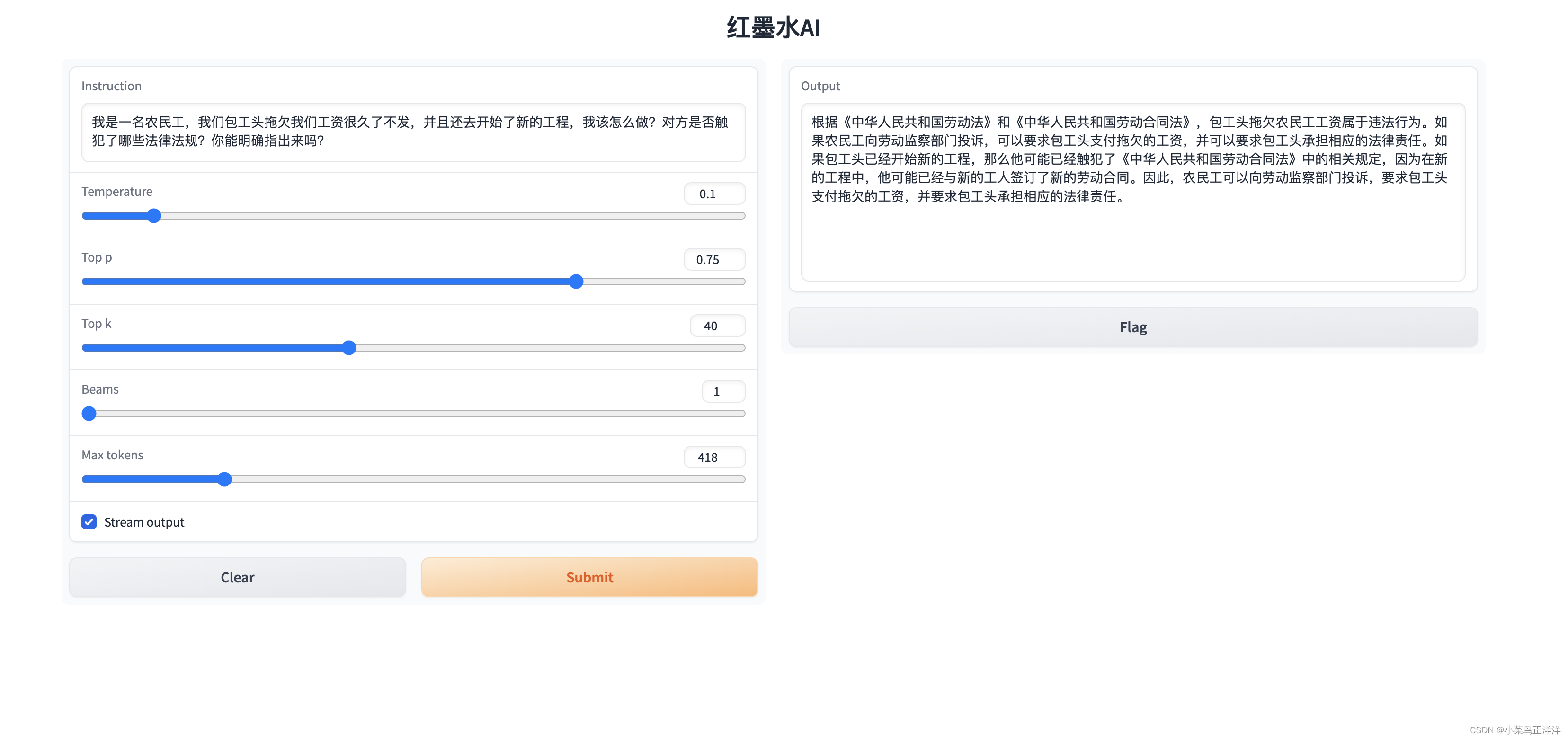
5、访问weui就可以体验这个法律模型了