1 . 等待结果
2. 渲染类
渲染 JavaScript。
5.1 动态网 页 示例
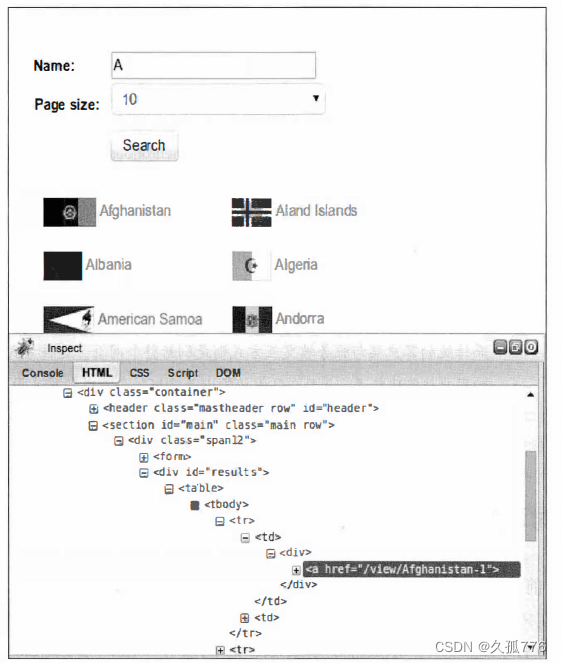
让我们来看一个动态 网页的例 子 。 示例 网 站有一个搜索表单 , 可 以通过 http : / / ex ample . webs craping . com/ s earch 进行访问, 该页面用于查 询国家。 比如说, 我们想要查找所有起始字母为 A 的国家, 其搜索结果页面如下图所示
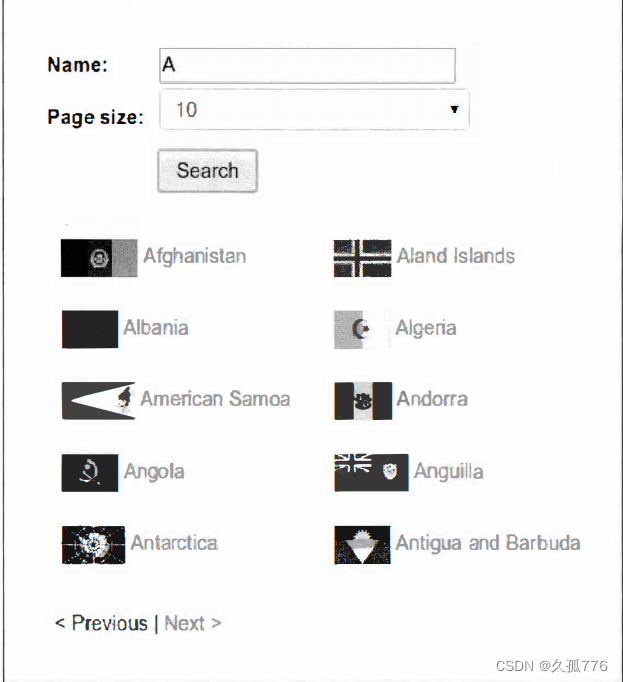
如果我们右键单击结果部分,使用Firebug查看元素可以发现结果被存储在ID为“result”的div元素中,如图下图所示 。
让我们尝试使用 l xml 模块抽取这些结果

这个示例爬虫在抽取结果时失败 了 。 检查网页源代码可 以帮助我们 了 解抽
取操作 为什么会失败 。 在源代码 中 , 可 以 发现我们准备抓取的 div 元素实际
上 是空的, 如下所示 。
而 Firebug 显示给我们的却是网页的当前状态,也就是使用JavaScript动态加载完搜索结果之后的网页。下一节中,我们将使用 Firebug 的另一个功能来了解这些结果是如何加载的。
5.2 对动态网页进行逆向工程
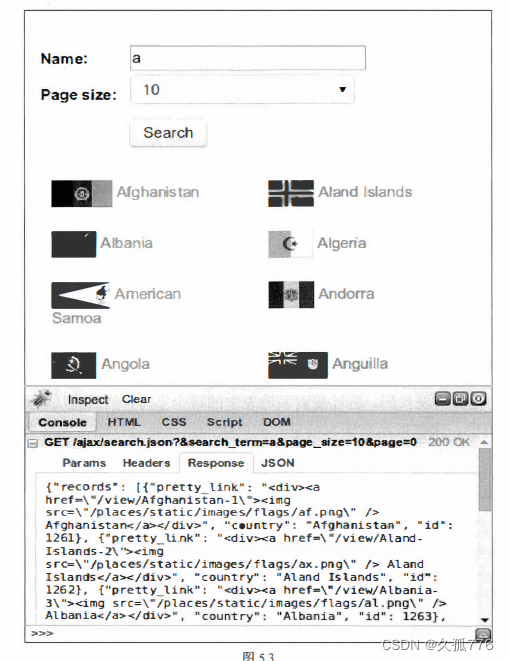
到目前为止,我们抓取网页数据使用的都是第2章中介绍的方法。但是,该方法在本章的示例网 页中无法正常运行,因为该网页中的数据是使用JavaScript动态加载的。要想抓取该数据,我们需要了解网页是如何加载该数据的,该过程也被称为逆向工程。继续上一节 的例子,在Firebug中单击Console选项卡,然后执行一次搜索,我们将会看到产生了一个 AJAX请求,如下图所示
这个AJAX数据不仅可以在搜索网页时访问到,也可以直接下载,如下面的代码所示。

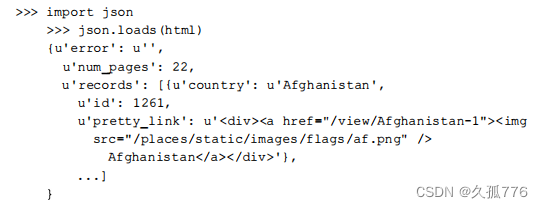
AJAX 响应返回的数据是JSON格式的,因此我们可以使用 Python 的j
son模块将其解析成一个字典,其代码如下所示 。
现在,我们得到了一个简单的方法来抓取包含字母A的国家。要想获取所有国家的信息,我们需要对字母表中的每个字母调用一次AJAX搜索。而且对于每个字母,搜索结果还会被分割成多个页 面,实际页数和请求时的pagesize相关。保存结果时还会遇到一个问题,那就是同一个国家可能会在多次搜索时返回,比如Fiji会匹配f, i, j三次搜索结果。这些重复的搜索结果需要过滤处理,这里采用的方法是在写入表格之前先将结果存储到集合中,因为集合这种数据类型不会存储重复的元素。
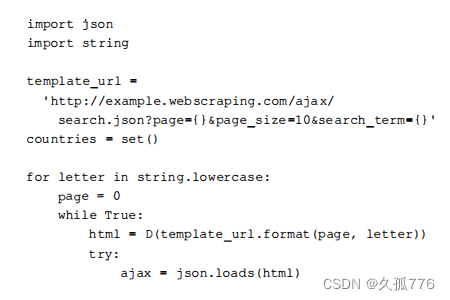
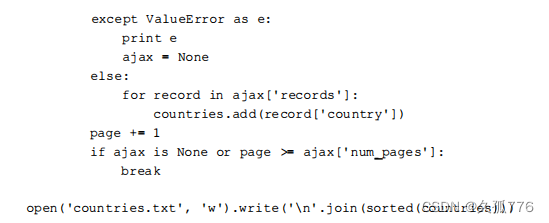
下面是其实现代码,通过搜索字母表中的每个字母,然后遍历JSON响应的结果页面,来抓取所有国家信息。其产生的结果将会存储在表格当中。
这个AJAX接口提供的抽取国家信息的方法,比第2章中介绍的抓取方法更简单。这其实是一个日常经验:依赖于AJAX的网站虽然乍看起来更加复杂,但是其结构促使数据和表现层分离,因此我们在抽取数据时会更加容易。
5.2.1 边界情况
前面的 AJAX 搜索脚本非常简单,不过我们还可以利用一些边界情况使其进一步简化。目前, 我们是针对每个字母执行查询操作的,也就是说我们需要26次单独的查询,并且这些查询结果又 有很多重复。理想情况下,我们可以使用一次搜索查询就能匹配所有结果。接下来,我们将尝试使用不同字符来测试这种想法是否可行。如果将搜索条件置为空,其结果如下。
这种方法并没有奏效我们没有得到返回结果。下面我们再来尝试’ 申 ’ 是否能够匹配所有结果。
>>> j s on . loads ( D ( url + ’ * ’)) [ ’ num_pages ’ ]
。
依然没有奏效 。现在我们再来尝试下’·’,这是正则表达式里用于匹配所有字符的元字符 。
>>> j s on . loads ( D (url + ’ · ’)) [ ’ num_page s’]
26
这次尝试成功了,看来服务端是通过正则表达式进行匹配的。因此,现在可以把依次搜索每个字符替换成只对点号搜索一次了。
此外,你可能已经注意到在 AJAX 的URL中有一个用于设定每个页面显示国家数量的参数。搜索界面中包含4、10、2。这几种选工页,其中默认值为10。因此提高每个页面的显示数量到最大值,可以使下载次数减半。
那么,要是使用比网页界面选择框支持的每页国家数更高的数值又会怎样呢?
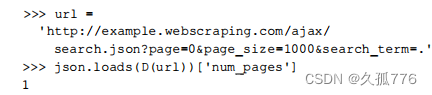
显然,服务端并没有检查该参数是否与界面允许的选项值相匹配而是直接在一个页面中返回了 所有结果。许多Web应用 不会在 AJAX 后端检查这一 参数, 因 为它们认为请求只会来 自 Web 界面 。
现在,我们手工修改了这个URL,使其能够在一次请求中下载得到所有国家的数据。进一步简化之后,抓取所有国家信息的实现代码如下。


5.3 渲染动态网页
对于搜索网页这个例子,我们可以很容易地对其运行过程实施逆向工程。但是,一些网站非常复杂,即使使用类似Firebug这样的工具也很难理解。比如,一个网站使用GoogleWebToolkit(GWT)开发,那么它产生的 JavaScript 代码是机器生成的压缩版。生成的 JavaScript 代码虽然可以使用类似 JSbeaut ifier 的工具进行还原,但是其产生的结果过于元长, 而且原始的变量名也已经丢失,这就会造成其结果难以处理。尽管经过足够的努力,任何网站都可 以被逆向工程,但我们可以使用浏览器渲染引擎避免这些工作,这种渲染引擎是浏览器在显示网页时解析HTML、应用 css 样式并执行JavaScri严语句的部分。在本节中,我们将使用 WebKit 渲染引擎,通过Qt框架可以获得该引擎的一个便捷Python接口。
5.3.1 PyQt还是PySide
Qt框架有两种可以使用的 Python 库,分别是PyQt和PySide。PyQt 最初于1998 年发布,但在用于商业项目时需要购买许可。由于该原因,开发 Qt 的公司( 原先是诺基亚,现在是Digia)后来在 2009 年开发了另一个 Python 库 PySide,并且使用了更加宽松的LGPL许可。
虽然这两个库有少许区别,但是本章中的例子在两个库中都能够正常工作。下面的代码片段用 于导入已安装的任何一种Qt库。
在这段代码中,如果PySide不可用,则会抛出ImportError异常,然后导入PyQt模块。如果PyQt 模块也不可用,则会抛出另一个工mportError异常,然后退出脚本 。
5.3.2 执行 JavaScript
为了确认WebKit能够执行JavaScript,我们可以使用位于http://example.webscraping.com/ dynamic上的这个简单示例 。
该网页只是使用 JavaScript 在div元素中写入了HelloWorld。下面是其源代码 。
使用传统方法下载原始 HTML 并解析结果时,得到的div元素为空值,如下所示 。
下面是使用WebKit的初始版本代码,当然还需事先导入上一节提到的PyQt或PySide模块 。

因为这里有很多新知识,所以下面我们会逐行分析这段代码。
1.第一行初始化了QApplication对象,在其他Qt对象完成初始化之前,Qt框架需要先创建该对象。
2.接下来,创建QWebView对象,该对象是Web文档的容器。
3.创建QEventLoop对象,该对象用于创建本地事件循环。
4.QWebView对象的loadFinished回调连接了QEventLoop的quit方法,从而可以在网页加载完成之后停止事件循环。然后,将要加载的URL传给QWebViewoPyQt需要将该U肚字符串封装在QUrl对象当中,而对于PySide来说则是可选工页。
5.由于QWebView的加载方法是异步的,因此执行过程会在网页加载时立即传入下一行。但我们又希望等待网页加载完成,因此需要在事件循环启动时调用loop.exec( )
6.网页加载完成后,事件循环退出,执行过程移到下一行,对加载得到的网页所产生的HTML进行数据抽取。
7.从最后一行可以看出,我们成功执行了JavaScript,div元素果然抽取出了HelloWorldo
这里使用的类和方法在C++的Qt框架网站中都有详细的文档,其网址为http://qt-project. org/doc/qt-4.8/。虽然 PyQt 和 PySide 都有其自身的文档,但是原始 C++版本的描述和格式更加详尽,一般的 Python 开发者可以用它替代。
5.3.3 使用WebKit与网站交互
我们用于测试的搜索网页需要用户修改后提交搜索表单,然后单击页面链接。而前面介绍的浏览器渲染引擎只能执行JavaScript,然后访问生成的HTML。要想抓取搜索页面,我们还需要对浏览器渲染引擎进行扩展,使其支持交互功能。幸运的是,Qt包含了一个非常棒的API,可以选择和操纵
对于之前的 AJAX 搜索示例,下面给出另一个实现版本。该版本己经将搜索条件设为’·’,每页显示数量设为’1000’,这样只需一次请求就能获取到全部结果。
最开始几行和之前的HelloWorld示例一样,初始化了一些用于渲染网页的Qt对象。之后,调用 QWebViewGUI的show( )方法来显示渲染窗口,这可以方便调试。然后,创建了一个指代框架的变量,可以让后面几行代码更短。QWebFrame类有很多与网页交互的有用方法。接下来的两行使用css模式在框架中定位元素,然后设置搜索参数而后表单使用evaluateJavaScript()方法进行提交,模拟点击事件。该方法非常实用,因为它允许我们插入任何想要的JavaScript 代码 ,包括直接调用网页中定义的JavaScript方法。最后一行进入应用的事件循环,此时我们可以对表单操作进行复查。如果没有使用该方法,脚本将会直接结束。
下图所示为脚本运行时的显示界面。
1 . 等待结果
实现WebKit爬虫的最后一部分是抓取搜索结果,而这又是最难的一部分,因为我们难以预估完成AJAX事件以及准备好国家数据的时间。有三种方法可以处理这一问题,分别是
1.等待一定时间,期望AJAX事件能够在此时刻之前完成:
2.重写Qt的网络管理器,跟踪URL请求的完成时间 ;
3.轮询网页,等待特定内容出现。
第
一
种方
案
最容易
实
现,不过效率也最低,因为
一
旦
设
置
了安全的超时时间,就会使大多数请求浪费大量不必要的时间。而且,当网络速度比平常慢时,固定的超时时间会出现请求失败的情况。 第二种方案虽然更加高效,但是如果延时出现在客户端而不是服务端时,则无法使用。比如,已 经完成下载,但是需要再单击一个按钮才会显示内容这种情况,延时就出现在客户端。
第
三
种方案尽
管存在
一
个小
缺
点,即会在检
查
内
容
是否
加
载
完
成时浪费CPU周期,但是该方案更加可靠且易于实现。 下面是使用第三种方案的实现代码 。

如上实现中,代码不断循环,直到国家链接出现在results这个div元素中。每次循环,都会调用 app.processEvents(),用于给Qt事件循环执行任务的时间,比如响应点击事件和更新GUI。
2. 渲染类
为了提升这些功能后续的易用性,下面会把使用到的方法封装到一个类中,其源代码可以从http s://hitbucket.org/wswp/code/src/tip/chapter05/browserrender.py获取。



你可能已经注意到,在download()和waitload( )方法中我们增加了一些代码用于处理定时器。定时器用于跟踪等待时间,并在截止时间到达时取消事件循环。否则,当出现网络问题时, 事件循环就会无休止地运行下去。
下面是使用这个新实现的类抓取搜索页面的代码 。
 5.3.4 Selenium
5.3.4 Selenium
5.3.4 Selenium
使用前面例子中的WebKit库,我们可以自定义浏览器渲染引擎,这样就能完全控制想要执行的行为。如果不需要这么高的灵活性,那么还有一个不错的替代品Selenium可以选择,它提供了使浏览器自动化的API接口。Selenium可以通过如下命令使用pip安装。
pip install selenium
为了演示Selenium是如何运行的,我们会把之前的搜索示例重写成Selenium的版本。首先,创建一个到浏览器的连接 。

当运行该命令时,会弹出一个空的浏览器窗口,如下图。该功能非常方便,因为在执行每条命令时,都可以通过浏览器窗口来检查Selenium是否依照预期运行。尽管这里我们使用的浏览器是 Firefox,不过Selenium也提供了连接其他常见浏览器的接口,比如Chrome和IE。需要注意的是, 我们只能使用系统中己安装浏览器的Selenium接口。

如果想在选定的浏览器中加载网页,可以调用get()方法:
>>> drive r . get ( ’ http : / /exarnple . webscraping . com/ s earch ’ )
然后,设置需要选取的元素,这里使用的是搜索文本框的ID。此外,Selenium也支持使用css选择器或XPath来选取元素。当找到搜索文本框之后,我们可以通过sendkeys( )方法输入内容, 模拟键盘输入。

为了让所有结果可以在一次搜索后全部返回,我们希望把每页显示的数量设置为1000。但是, 由于Selenium的设计初衷是与浏览器交互,而不是修改网页内容,因此这种想法并不容易实现。 要想绕过这一限制,我们可以使用JavaScript语句直接设置选项框的内容。

此时表单内容已经输入完毕,下面就可以单击搜索按钮执行搜索了。
>>> drive r . f ind element by i d ( ' s earch ’) • click ()
现在,我们需要等待 AJAX 请求完成之后才能加载结果,在之前讲解的 WebKit 实现中这里是最难的一部分脚本。幸运的是,Selenium 为该问题提供了一个简单的解决方法,那就是可以通过 implicitlywait( )方法设置超时
>>> drive r . implicitly_wait (30)
此处,我们设置了30秒的延时。如果我们要查找的元素没有出现,Selenium 至多等待30秒 , 然后就会抛出异常。要想选取国家链接,我们依然可以使用 WebKit 示例中用过的那个css选择器 。
>>> l inks = drive r . find elements by css sel ect。r ( ’ # results a ’ )
然后,抽取每个链接的文本,并创建一个国家列表。

最后,调用close( )方法关闭浏览器 。
>>> drive r . close ()
本示例的源代码可以从 https://bitbucket.org/wswp/code/src/tip/chapter05/selenium_search.py 获取。如果想进一步了解 Seleniurm这个python库,可以通过 https://selenium-python.readthedocs. org/获取其文档 。
5.4 本章小结
本章介绍了两种抓取动态网页数据的方法。第一种方法是借助 FirebugLite 对动态网页进行逆向工程,第二种方法是使用浏览器渲染引 擎为我们触发 JavaScript 事件。我们首先使用 WebKit 创建自定义浏览器,然后使用更高级的Selenium框架重新实现该爬虫 。
浏览器渲染引擎能够为我们节省 了解网站后端工作原理的时间,但是该方 法也有其劣势。渲染网页增加了开销,使其比单纯下载HTML更慢。另外, 使用浏览器渲染引擎的方法通常需要轮询网页来检查是否已经得到事件生成 的HTML,这种方式非常脆弱,在网络较慢时会经常会失败。我一般将浏览 器渲染引擎作为短期解决方案,此时长期的性能和可靠性并不算重要:而作 为长期解决方案,我会尽最大努力对网站进行逆向工程。