《诸神之眼:Nmap网络安全审计技术揭秘》读书笔记
作者:李华峰
◆ 前言
NSE是Nmap中革命性的创新。通过Nmap强大的脚本引擎(NSE),每一个用户都可以向Nmap中添加自己编写的代码,从而将Nmap打造成用户自由定制功能的强大工具。
◆ 2.1 活跃主机发现技术简介
如果想知道网络中的某台主机是否处于活跃状态,同样可以采用这种“敲门”的方式,只不过需要使用发送数据包的形式来代替现实生活中的“敲门”动作,也就是说活跃主机发现技术其实就是向目标计算机发送数据包,如果对方主机收到了这些数据包,并给出了回应,就可以判断这台主机是活跃主机。
◆ 2.3 基于ARP协议的活跃主机发现技术
基于ARP协议的活跃主机发现技术的原理是:如果想要知道处在同一网段的IP地址为*...*的主机是否为活跃主机,只需要构造一个ARP请求数据包,并广播出去,如果得到了回应,则说明该主机为活跃主机。
◆ 2.4 基于ICMP协议的活跃主机发现技术
查询报文是用一对请求和应答定义的。也就是说,主机A为了获得一些信息,可以向主机B发送ICMP数据包,主机B在收到这个数据包之后,会给出应答。
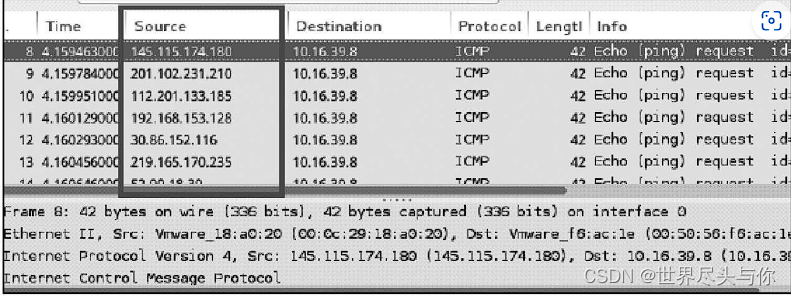
ICMP中适合使用的查询报文包括如下3类。1.响应请求和应答用来测试发送与接收两端链路及目标主机TCP/IP协议是否正常,只要收到就是正常。我们日常使用最多的是ping命令,利用响应请求和应答,主机A向一个主机B发送一个ICMP报文,如果途中没有异常(例如被路由器丢弃、目标不回应ICMP或传输失败),则主机B返回ICMP报文,说明主机B处于活跃主机。2.时间戳请求和应答ICMP时间戳请求允许系统向另一个系统查询当前的时间。返回的建议值是自午夜开始计算的毫秒数,即协调世界时(Coordinated Universal Time, UTC)(早期的参考手册认为UTC是格林尼治时间)。如果想知道B主机是否在线,还可以向B主机发送一个ICMP时间戳请求,如果得到应答的话就可以视为B主机在线。当然,其实数据包内容并不重要,重要的是是否收到了回应。3.地址掩码请求和应答ICMP地址掩码请求由源主机发送,用于无盘系统在引导过程中获取自己的子网掩码。这里很多人可能会觉得我们的系统大多数时候都不是无盘系统,是不是这个技术就没有用了呢?虽然RFC规定,除非系统是地址掩码的授权代理,否则它不能发送地址掩码应答(为了成为授权代理,它必须进行特殊配置,以发送这些应答)。但是,大多数主机在收到请求时都发送一个应答。如果想知道B主机是否在线,还可以向B主机发送一个ICMP掩码地址请求,如果得到应答的话就可以视为B主机在线。
◆ 2.5 基于TCP协议的活跃主机发现技术
在Nmap中常用的TCP协议扫描方式有两种,分别是TCP SYN扫描和TCP ACK扫描,这两种扫描方式其实都是利用TCP的三次握手实现的。
在发出SYN数据包之后,只要收到数据包,无论是SYN/ACK数据包还是RST数据包,都意味着目标主机是活跃的。如果没有收到任何数据包,就意味着目标主机不在线。
Nmap所在主机在收到这个数据包之后,并不会真的和目标主机建立连接,因为目的只是判断目标主机是否为活跃主机,因此需要结束这次连接,TCP协议中结束连接的方法就是向目标发送一个RST数据包。
Nmap直接向目标主机发送一个TCP/ACK数据包,目标主机显然无法清楚这是怎么回事,当然也不可能成功建立TCP连接,因此只能向Nmap所在主机发送一个RST标志位的数据包,表示无法建立这个TCP连接
在Nmap发出数据包之后,并没有收到任何应答,这时存在两种可能,一种是这个数据包被对方的安全机制过滤掉了,因为目标根本没有收到这个数据包,另一种就是目标主机并非活跃主机。Nmap通常会按照第二种情况进行判断,也就是给出一个错误的结论:目标并非活跃主机。
◆ 2.6 基于UDP协议的活跃主机发现技术
当一个UDP端口收到一个UDP数据包时,如果它是关闭的,就会给源端发回一个ICMP端口不可达数据包;如果它是开放的,就会忽略这个数据包,也就是将它丢弃而不返回任何信息。
缺点为扫描结果的可靠性比较低。因为当发出一个UDP数据包而没有收到任何的应答时,有可能因为这个UDP端口是开放的,也有可能是因为这个数据包在传输过程中丢失了。另外,扫描的速度很慢。原因是在RFC1812中对ICMP错误报文的生成速度做出了限制。例如Linux就将ICMP报文的生成速度限制为每4秒产生80个,当超出这个限制的时候,还要暂停1/4秒。
TCP需要扫描目标主机开放的端口,而UDP需要扫描的是目标主机关闭的端口。在扫描的过程中,需要避开那些常用的UDP协议端口,例如DNS(端口53)、SNMP(161)。因此在扫描的时候,最合适的做法就是选择一个值比较大的端口,例如35462。
◆ 2.7 基于SCTP协议的活跃主机发现技术
SCTP协议与TCP完成的任务是相同的。但两者之间却存在着很大的不同之处。首先,TCP协议一般是用于单地址连接的,而SCTP却可以用于多地址连接。其次,TCP协议是基于字节流的,SCTP是基于消息流的。TCP只能支持一个流,而SCTP连接(association)同时可以支持多个流(stream)。最后,TCP连接的建立是通过三次握手实现的,而SCTP是通过一种4次握手的机制实现的,这种机制可以有效避免攻击的产生。在SCTP中,客户端使用一个INIT报文发起一个连接,服务器端使用一个INIT-ACK报文进行应答,其中就包括了cookie(标识这个连接的唯一上下文)。然后客户端使用一个COOKIE-ECHO报文进行响应,其中包含了服务器端所发送的cookie。服务器端要为这个连接分配资源,并通过向客户端发送一个COOKIE-ACK报文对其进行响应。
◆ 2.10 主机发现技术的分析
Nmap中提供了–packet-trace选项,通过它就可以观察Nmap发出了哪些数据包,收到了哪些数据包,有了这个研究方法,可以更深入地理解Nmap的运行原理。
Nmap在进行主机发现的时候,无论你指定了何种方式,Nmap都会先判断一下目标主机与自己是否在同一子网中,如果在同一子网中,Nmap直接使用ARP协议扫描的方式,而不会使用你所指定的方式。
◆ 3.2 端口的分类
公认端口(well known port):这一类端口是最为常用的端口,因此也被称为“常用端口”。所使用的从0到1024的端口都是公认端口。通常这些端口已经明确地和某种服务的协议进行了关联,一般不应该对其进行改变。例如所熟知的80端口运行的总是http通信,而telnet也总是适用23号端口。这些端口的作用一般已经约定好,因此不会被其他程序所使用。
注册端口(registered port):这部分端口号的范围是从1025到49151。它们通常也会关联到一些服务上,但是并没有明确的规定,不同的程序可以根据实际情况进行定义。
动态和/或私有端口(dynamic and/or private port):这部分端口号的范围是从49152到65535。一般来说,常见的服务不应该使用这部分端口,但是由于这部分端口不容易引起注意,因此有些程序尤其是一些木马或者病毒程序十分钟爱这部分端口。
◆ 3.4 Nmap中的各种端口扫描技术
首先Nmap会向目标主机的一个端口发送请求连接的SYN数据包,而目标计算机在接收到这个SYN数据包之后会以SYN/ACK进行应答,Nmap在收到SYN/ACK后会发送RST包请求断开连接而不是ACK应答。这样,三次握手就没有完成,无法建立正常的TCP连接,因此,这次扫描就不会被记录到系统日志中。这种扫描技术一般不会在目标主机上留下扫描痕迹。
这种扫描方式其实和SYN扫描很像,只是这种扫描方式完成了TCP的三次握手。
UDP扫描的速度是相当慢的
在扫描过程中可能会产生一些状态为filtered的端口,这些端口的真实状态可能是open,也有可能是closed。要从这些状态为filtered的端口中找到那些其实是open的端口,需要进一步的测试
Nmap将会向每个open|filtered的端口发送UDP probe,如果目标端口对任何一个probe有了反应,状态都会被修改为open
TCP FIN扫描方法向目标端口发送一个FIN数据包
TCP NULL扫描方法是向目标端口发送一个不包含任何标志的数据包
TCP Xmas Tree扫描方法是向目标端口发送一个含有FIN、URG和PUSH标志的数据包
这种扫描方式在思路上十分巧妙,在整个扫描过程中,扫描者无须向目标主机发送任何数据包
下面介绍这种扫描的原理。步骤1:检测第三方的IP ID值并记录下来。步骤2:在本机上伪造一个源地址为第三方主机的数据包,并将数据包发送给目标主机端口,根据目标端口状态的不同,目标主机可能会导致第三方主机的IP ID值增加。步骤3:再回来检查第三方主机的IP ID值。比较这两次的值。这时,第三方主机的IP ID值应该是增加了1到2,如果只是增加了1,那么说明第三方主机在这期间并没有向外发送数据包,这种情况就认为目标主机的端口是关闭的。如果增加了2,就表明第三方主机在这期间向外部发送了数据包,这样就说明目标主机的端口是开放的。
通过idle扫描方式,目标主机日志中记录下来的是第三方的地址
通常一个SYN扫描所需要花费的时间只是几秒,而idle扫描的扫描时间要远远多于这个时间,另一点就是很多时候,宽带提供商并不会允许你向外发送伪造的数据包。还有最为重要的一点是,idle扫描要求你必须能找到一个正在工作的第三方主机
首先这台第三方主机产生IP ID的方法必须是整体增加的,而不是根据每个通信自行开始的,最好是空闲的,因为大量的无关流量将会导致结果极为混乱。当然主机与第三方主机的延迟小也是理想的情况
那么如何查看一台主机是否适合作为一台第三方主机呢?方法一是,在对一台主机进行扫描的时候,执行一个端口扫描以及操作系统检测,启动详细模式(-v),操作系统就会检测IP ID增长方法,如果返回值为“IP ID Sequence Generation:Incremental”,这是一个好消息。但还需要确定一下,因为很多系统其实为每一个通信开启了一个IP ID,另外,如果这台主机和外界进行大量的通信,这种方法也是不适用的。方法二是运行ipidseq NSE脚本。
◆ 4.2 操作系统指纹简介
远程判断目标计算机操作系统的方法一般可以分成两类。▯ 被动式方法:并不向目标系统发送任何数据包,而是通过各种抓包工具来收集流经网络的数据报文,再从这些报文中得到目标计算机的操作系统信息。▯ 主动式方法:指客户端主动向远程主机发送信息,远程主机一般要对这些信息做出反应,回复一些信息,发送者对这些返回的信息进行分析,就有可能得知远程主机的操作系统类型。这些信息可以是通过正常的网络程序如Telnet、FTP等与主机交互的信息,也可以是一些经过精心构造、正常的或残缺的数据报文。
Nmap并不使用被动式的方法。Nmap中的主动式方法采用多达15个探针的操作系统指纹扫描包。
Nmap中对数据包进行调整的部分包括窗口大小、窗口字段、分片标识、时间戳、序号以及其他一些细节,例如TTL等。
◆ 4.5 如何使用Nmap进行服务发现
Nmap提供了更精确的服务及版本检测选项,可通过添加选项-sV进行服务和版本检测。
Nmap-service-probes数据库包含查询不同服务的探测报文和解析识别响应的匹配表达式。版本检测程序会将探测结果与Nmap-service-probes数据库中的内容进行比较,如果与其中的某一项匹配成功,就可以确认目标端口运行的具体服务。
◆ 6.1 Nmap的伪装技术
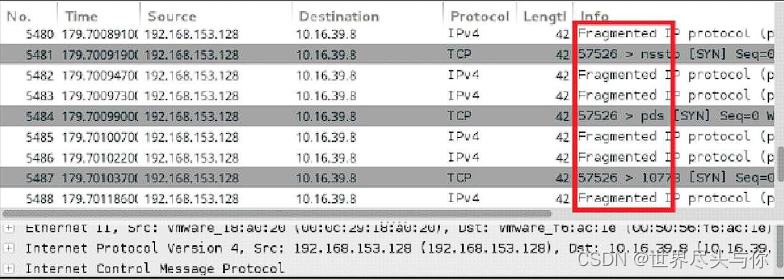
使用-f选项可以对Nmap发送的探测数据包进行分段。这样将原来的数据包分成几个部分,目标网络的防御机制例如包过滤、防火墙等在对这些数据包进行检测的时候就会变得更加困难
使用Wireshark抓包获得的数据,可以清楚地看到大量的数据包上面都含有Fragmented IP protocol的标识。这一点说明这些数据包都是分段的报文。
最大传输单元(Maximum Transmission Unit, MTU)是指一种通信协议的某一层上面所能通过的最大数据包大小(以字节为单位)。一般来说,以太网的MTU值默认是1500 bytes,这个含义就是指当发送者的协议高层向IP层发送了长度为2008 bytes的数据报文,则该报文在添加20 bytes的IP包头后IP包的总长度是2028 bytes,因为2028大于1500,因此该数据报文就会被分片
在Nmap中使用–mtu选项可以指定MTU的大小
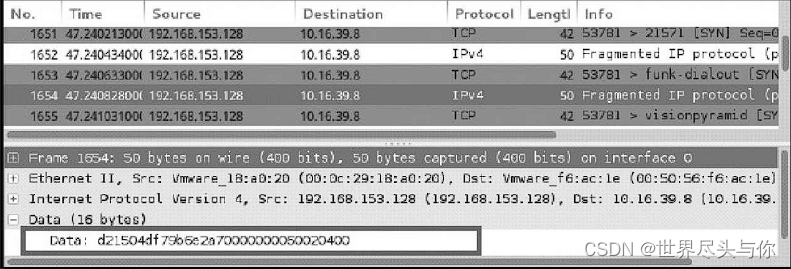
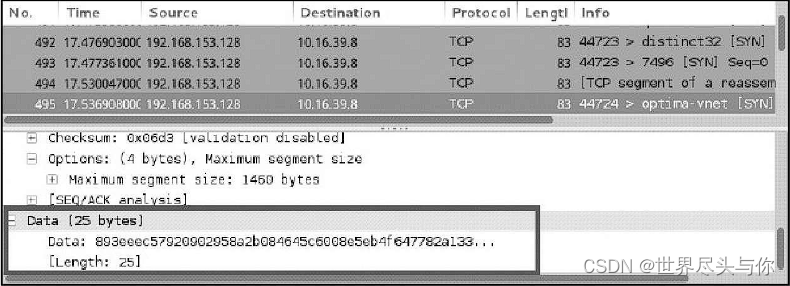
同样使用Wireshark捕获发送的数据包并查看详情,捕获的数据包中Data字段长度为16bytes,如图所示。可以看到每个发送的包的数据区域大小都被修改成了16bytes。
Nmap中支持使用诱饵主机,在扫描时,使用选项-D来指定诱饵主机,使用逗号分隔每个诱饵IP地址,也可用自己的真实IP作为诱饵,自己的IP地址可以使用ME选项。如果在第6个位置或更后的位置使用ME选项,一些常用端口扫描检测器(如Solar Designer’s excellent scanlogd)就不会报告这个真实IP。如果不使用ME选项,Nmap将真实IP放在一个随机的位置。
在初始的ping扫描(ICMP、SYN、ACK等)阶段或真正的端口扫描,以及远程操作系统检测(-O)阶段都可以使用诱饵主机选项。但是在进行版本检测或TCP连接扫描时,诱饵主机选项是无效的
使用Wireshark抓取发送出去的数据包,捕获到的数据包如图所示。使用Wireshark捕获的诱饵数据包可以看到Nmap伪造了大量的诱饵主机对目标进行扫描
网络安全控制中有一种访问控制列表技术,这种技术主要是依靠IP地址和端口来对数据包进行限制,例如有时如果需要保证DNS和FTP协议正常工作,注意到DNS响应来自于53端口,FTP连接来自于20端口,很多新手管理员会犯下一个错误,他们经常会直接允许来自于这些端口的数据进入网络。
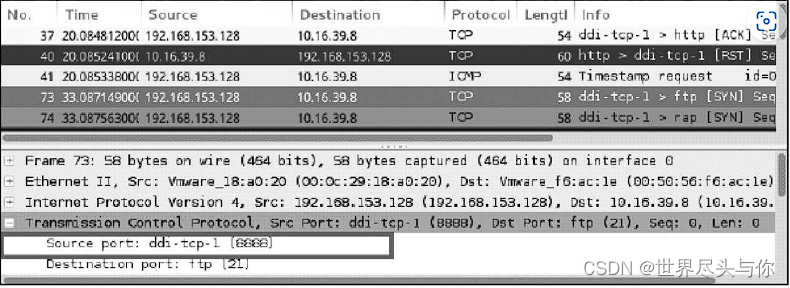
Nmap提供了-g和–source-port选项(它们是相同的),用于利用上述弱点。只需要有一个被目标检测机制遗忘的端口号,Nmap就可以从这个端口发送数据。
同样使用Wireshark抓取发送出去的数据包,抓取到的数据包如图所示,可以通过“Source port”字段来查看源端口。
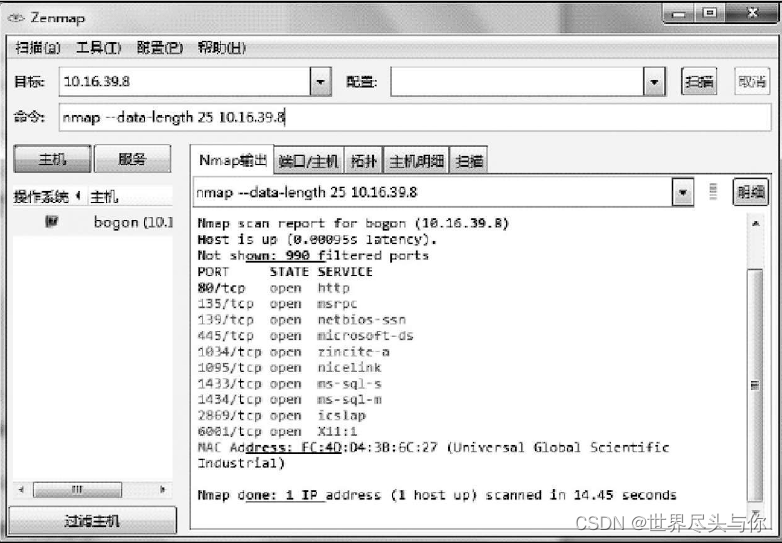
默认情况下,Nmap发送的报文中只包含头部,内容部分是空的,因此TCP数据包的大小只有40字节,而ICMP ECHO请求只有28字节。这种内容为空的报文很容易被目标网络检测机制所发现,因此在试图通过这些目标网络的检测机制时,可以在数据包上附加指定数量的随机字节
在Zenmap中指定数据包data部分长度为25
使用Wireshark查看发送数据包data部分的长度
如果简单地使用字符串“0”, Nmap选择一个完全随机的MAC地址。如果给定的字符是一个使用分号分隔的十六进制偶数,Nmap将使用这个MAC地址。如果是小于12的十六进制数字,Nmap会随机填充剩下的6个字节。如果参数不是0或十六进制字符串,Nmap将通过Nmap-mac-prefixes查找厂商的名称(区分大小写),如果找到匹配,Nmap将使用厂商的OUI(3字节前缀),然后随机填充剩余的3个节字。
◆ 9.8 Lua协同程序
线程与协同程序的主要区别在于,一个具有多个线程的程序可以同时运行几个线程,而协同程序却需要彼此协作运行。在任一指定时刻只有一个协同程序在运行,并且这个正在运行的协同程序只有在明确要求挂起的时候才会被挂起。
- coroutine.create()这个方法用来创建一个coroutine,将要进行多线程的函数作为参数,返回值是一个coroutine。
- coroutine.resume()这个方法用来完成coroutine重启操作,与create配合使用。
- coroutine.yield()这个方法用来实现coroutine的挂起操作,将coroutine设置为挂起状态。
- coroutine.status()这个方法用来查看coroutine的状态。这里coroutine的状态一共有dead、suspend、running三种。
- coroutine.wrap()这个方法创建一个coroutine,用于返回一个函数,一旦调用这个函数,就进入coroutine,与create功能相同。
- coroutine.running()这个方法返回正在运行的coroutine。一个coroutine就是一个线程,当使用running时,返回的是当前正在运行的coroutine的线程号。
◆ 9.9 Lua语言中的注释和虚变量
使用符号
--,功能等同于C语言中的//,例如:--这是一个单行的注释
使用
--[[ 注释的内容 ]],功能等同于C语言中的/**/,例如:--[[ 这是一个多行的 注释 ]]
如果只想要
string.find返回的第二个值,可以使用虚变量(即下画线)来存储丢弃不需要的数值。Local _, s = string.find("hello ", " ll ")
◆ 12.1 NSE中的服务发现模式
一个完整的服务发现过程包括如下步骤。步骤1:如果目标端口的状态是opened,就会发送一个NULL类型的探针到这个端口,这种类型的探针包括一个用于打开连接的请求,然后Nmap会等待从目标端口返回的回应。在收到回应之后,Nmap会将这个回应和数据库中的各种指纹数据进行比较,产生一个softmatch或者hardmatch,如果匹配结果是softmatch, Nmap会再发送额外的探针。步骤2:如果这个NULL探针没能成功检测出目标的服务信息,保存在Nmap-service-probes文件中的TCP和UDP类型探针就会发送到目标。这个过程与NULL指针的探测过程十分相似,稍有不同的就是这两种类型的探针都不是空的,其中包含了一段字符串作为载荷。正如之前所说的,这些探针产生的回应也要和数据库中的已知指纹数据进行比较。步骤3:如果这两个阶段都没有得到结果,Nmap就会发送特殊类型的探针,这个阶段经过优化,尽量减少发送的探针的数量,以避免对网络造成过大的负载。步骤4:发送的探针会检测目标上是否运行SSL服务。如果检测到这个服务,服务扫描将会重启,来检测这个服务。步骤5:发送一系列的探针来检测目标是否开放了基于RPC的服务。步骤6:如果探针产生的回应是无法识别的,Nmap将根据这个回应产生一个指纹文件,然后提交到Nmap的开发中心,以提高数据库识别服务的能力。
发送到每个服务的探针的数量取决于它们在Nmapservice-probes文件中的定义,也可以使用参数
--version-intensity [0-9]来改变扫描的强度,也就是改变探针的数量。Nmap -sV --version-intensity 9 <target>
Nmap在默认的情况下并不会向从9100到9107这部分TCP端口发送版本检测的探针。这是因为这些端口上通常运行的都是一些打印机的服务,当这些端口收到探针之后,就会返回大量的垃圾文件。
◆ 13.1 Nmap中数据文件所在的位置
在Windows操作系统中,这些文件都在C:\Program Files\Nmap\NSElib\data文件夹中,64位系统稍有不同。在Linux系列操作系统中,这些文件在/usr/local/share/Nmap/NSElib/data和/usr/share/Nmap/ selib/data中。
◆ 13.4 Web应用审计数据文件
http-fingerprints.lua这个文件是一个Lua table形式保存的数据文件,在这个文件中包含了一些常见Web应用的信息,这些信息包括这些应用中关键文件所在的位置。
http-sql-errors.lst这个数据文件中包含了一些标识错误的字符串,这个数据文件主要被脚本http-sql-injection所使用。用来完成对应用是否能够抵御SQL注入进行检测
同样也可以使用参数http-sql-injection.errorstrings来改变这个脚本执行时所使用的数据文件
http-web-files-extensions.lstNSE中的http-spider库文件在对页面进行扫描的过程中就会使用该文件。这个文件中包含了200多个常见的Web应用扩展名,也可以很容易地将另外一些Web应用扩展名添加到这个文件中
http-devframework-fingerprints.lua这个数据文件由Lua table所构成,被脚本http-devframework所调用,目的是检测目标Web应用的开发语言,例如ASP、PHP等
http-folders.txt这个数据文件中包含了956个HTTP中常见的目录名,被脚本http-iis-webdav-vuln所调用,用来检测IIS 5.1/6.0类型服务器上的漏洞
如果不想使用这个数据文件,也可以使用参数
--script-args folderdb来指定其他的数据文件,例如使用/pentest/fuzzers/folders.txt作为这个目录。

vhosts-default.lst脚本http-vhosts就是用这个数据文件来判断目标服务器到底是一个虚拟机还是一个真正的Web服务器
wp-plugins.lst这个文件中包含了18575个常见的WordPress插件的名称,脚本http-wordpress-plugins就是利用这个文件来对采用WordPress建站的服务器进行暴力穷举攻击
如果http-wordpress-plugins脚本中不特殊指定
--script-args http-wordpress-plugins.search,这个脚本只会读取前100个插件名
◆ 13.5 DBMS-auditing数据文件
mysql-cis.audit这个文件位于Nmap的安装目录中,主要根据CIS MySQL v1.0.2 benchmark来检测MySQL数据库的配置安全性。NSE中有一个mysql-audit脚本就是使用了这个文件
oracle-default-accounts.lst这个文件中包含了687个Oracle数据库中用来验证的用户名
oracle-sids文件oracle-sids包含了700个常见的Oracle数据库实例名
◆ 16.1 Nmap中的并发执行
Nmap将多个目标IP地址空间分成扫描组,然后在同一时间对一个扫描组进行扫描。hostgroup代表了一个扫描组,参数–min-hostgroup和–max-hostgroup决定了这个扫描组中数量的下限和上限。通常,一个扫描组中的数量越大,扫描就会越快。
◆ 16.3 Lua中的并发执行
步骤1:使用coroutine.create()创建一个coroutine。这个coroutine中有一个循环函数,同时实现了数字1~5的打印输出和暂停另一个coroutine。 co1 = coroutine.create( function() for i = 1, 5 do print(“coroutine #1:”…i) coroutine.yield(co2) end end )步骤2:同样的方式,创建另一个coroutine,使用co2作为coroutine的名字。 co2 = coroutine.create( function() for i = 1, 5 do print(“coroutine #2:”…i) coroutine.yield(co1) end end )步骤3:使用另外一个循环来运行这两个coroutine。 for i = 1, 5 do coroutine.resume(co1) coroutine.resume(co2) end