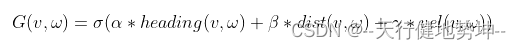1. SAM介绍
由Meta AI Research开发的Segment anything model(简称SAM)最近引起了广泛的关注。SAM在超过10亿个mask的大型分割数据集上进行了训练,能够在特定的图像上分割任何对象。在最初的SAM工作中,作者们使用了零样本迁移任务(如边缘检测)来评估SAM的性能。最近,许多工作试图在各种场景中研究SAM识别和分割对象的性能。此外,也有许多项目通过将SAM与其他模型(如Grounding DINO、Stable Diffusion、ChatGPT等)结合,展示了SAM作为基础模型的多功能性。随着相关的论文和项目数量呈指数级增长,读者们很难跟上SAM的发展进程。为此,我们进行了第一个也是最全面的关于SAM的调研。这是一个正在进行的项目,我们打算定期更新稿件。因此,如果读者完成了与SAM相关的新工作,欢迎他们联系我们,以便我们可以在下一版中包含他们的作品。

ChatGPT颠覆了我们对AI的认知,引起了全球范围内的重大关注和兴趣。它标志着生成AI(AIGC,又名人工智能生成内容)的重大突破,其中基础模型发挥了重要的作用。这种大型语言模型在语言任务中取得了显著的性能,引领了各种NLP领域的新范式。
在视觉领域,多项研究(Radford等人[2021],Jia等人[2021],Yuan等人[2021])尝试通过对比学习(He等人[2020],Qiao等人[2023],Zhang等人[2022a])将图像编码器与文本编码器一起学习。因此得到的图像编码器可以被视为视觉基础模型。另一种训练视觉基础模型的形式是通过自监督学习,例如masked autoencoder。然而,这种视觉基础模型在用于下游任务之前通常需要进行微调。
最近,Meta研究团队发布了一个名为"Segment Anything"的项目,其中提出了一个名为Segment Anything Model (SAM)的模型。"Segment Anything"项目的总体视图如图1所示。值得一提的是,SAM执行的是可提示的分割,这与语义分割有两点不同:(1) SAM生成的mask没有标签;(2) SAM依赖于提示。换言之,SAM只是在图像中剪切出物体,而不分配标签(见图1),哪个物体被剪切取决于给定的提示。考虑到所谓的提示工程,SAM在无需微调的情况下展现出了显著的零样本转移性能,使许多人相信,SAM对计算机视觉的影响就如同GPT-3 Brown等人[2020]对自然语言处理的影响一样。SAM在SA-1B上进行训练,该数据集包含来自1100万张图片的超过10亿个mask,是迄今为止发布的最大的分割数据集。
标签预测与mask预测。从概念上讲,语义分割可以被认为是mask预测和标签预测的结合。"Segment Anything"项目的成功表明,这两个子任务可以被解耦,而SAM专门解决第一个任务。没有像现有的图像分割任务(如实例分割和全景分割)那样的标签预测,SAM解决的任务乍看之下可能似乎是一个微不足道的任务。然而,实际上,它解决了计算机视觉中的一个基本任务,这对于视觉基础模型的发展有所贡献。为了最大化对未见分布的泛化,视觉基础模型需要使用足够大且多样化的数据集进行训练。当数据集的大小和多样性增加时,物体类别和标签具有开放词汇性,这使得无法预先确定一份固定的标签列表。
视觉基础模型遇见可提示的分割。为了克服上述问题,SAM Kirillov等人[2023]选择了基于提示的mask预测任务(也称为可提示的分割),在其中,提示的角色类似于注意力。当人眼理解世界时,它通常会集中在某个特定的对象上,同时将其周围的区域视为背景。如果在同一场景中存在众多对象,没有注意力机制,人眼就无法理解它。此外,即使观察者过去从未见过类似的对象,人眼也能识别和分割出感兴趣的对象。例如,一个初次看到萨摩耶犬的婴儿会跟踪狗的运动,尽管它从未理解过什么是狗。换句话说,视觉理解主要依赖于物体mask,而不是其对应的标签。总的来说,可提示的分割任务很好地模仿了人眼如何理解世界。在可提示分割上训练的SAM构成了一种视觉基础模型,这种模型不仅可以推广到未见的分布,而且与其他模型兼容,用于实现更多需求的任务。在不到一个月的时间里,社区已经进行了许多项目和文章,从各种角度研究SAM。它们大致可以分为两类:(1)第一类在现实世界的物体检测任务中评估和改进SAM;(2)第二类通过将SAM与其他模型结合,利用SAM的多功能性。鉴于工作量的增加,读者可能很难跟上SAM的发展。为此,本文对SAM在视觉进入NLP路径拥抱基础模型时代的情况进行了一次调研。

2 . SAM真的可以在所有情况下分割任何东西吗?
正如标题所示,SAM声称可以分割图像中的任何内容。然而,目前还不清楚SAM模型是否能在现实世界中很好地工作。因此,最近开展了大量工作来评估其在各种场景中的性能,包括医学图像等。
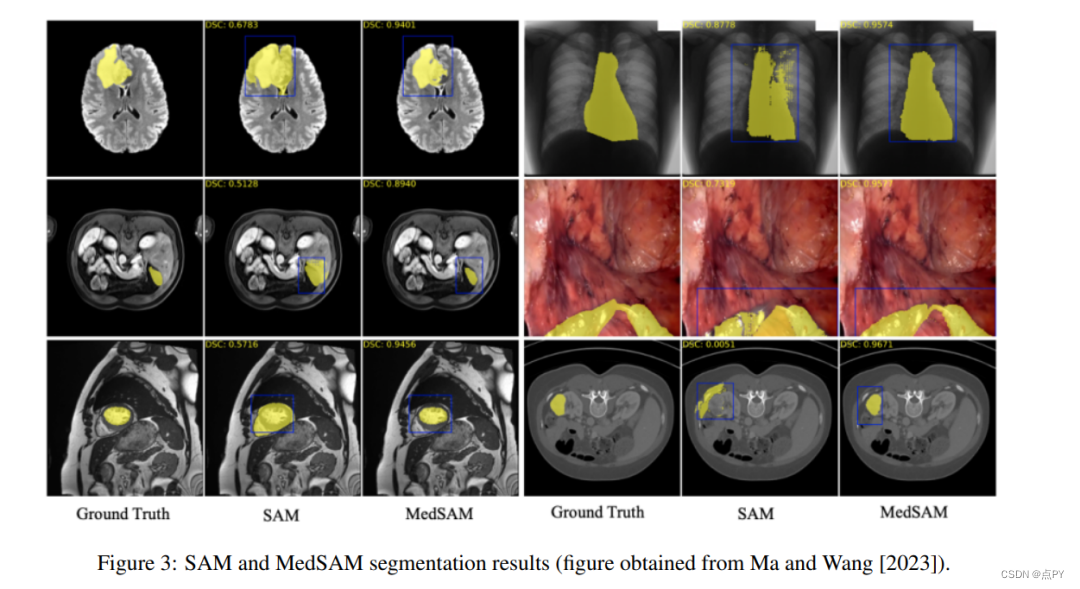
3. From segment anything to X anyting
SAM (自监督联想记忆)在“分割任何事物”方面的成功激励了社区去研究"X 任何事物"。具体来说,SAM已经在许多项目中表现出了其多功能性,当与其他模型结合使用时,可以实现令人印象深刻的性能。
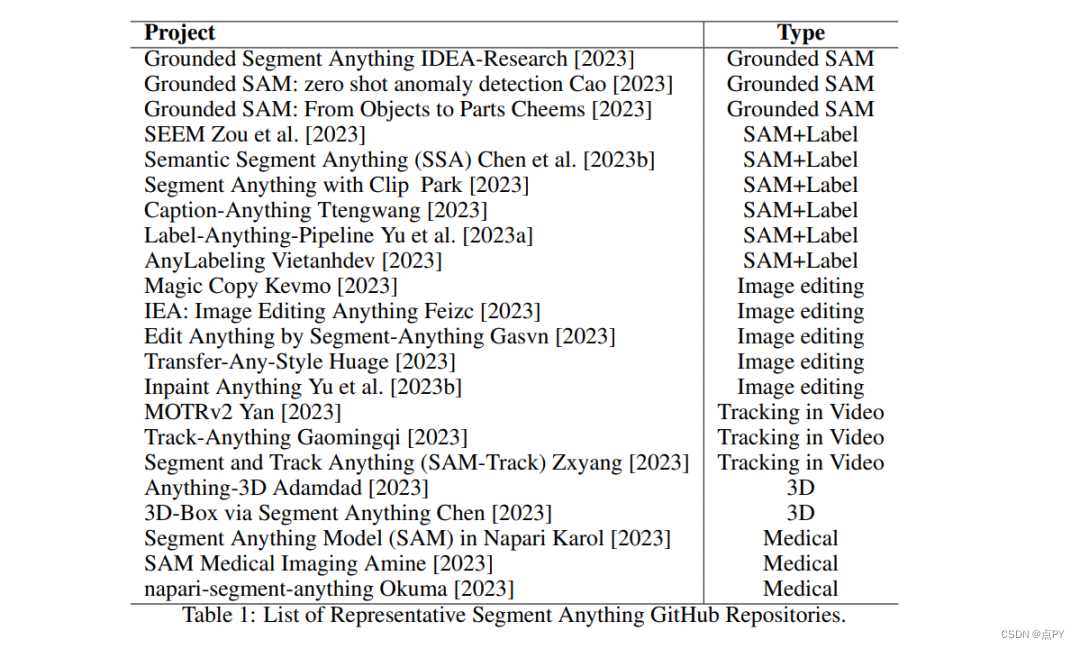
4. 评估SAM全能模式的度量标准
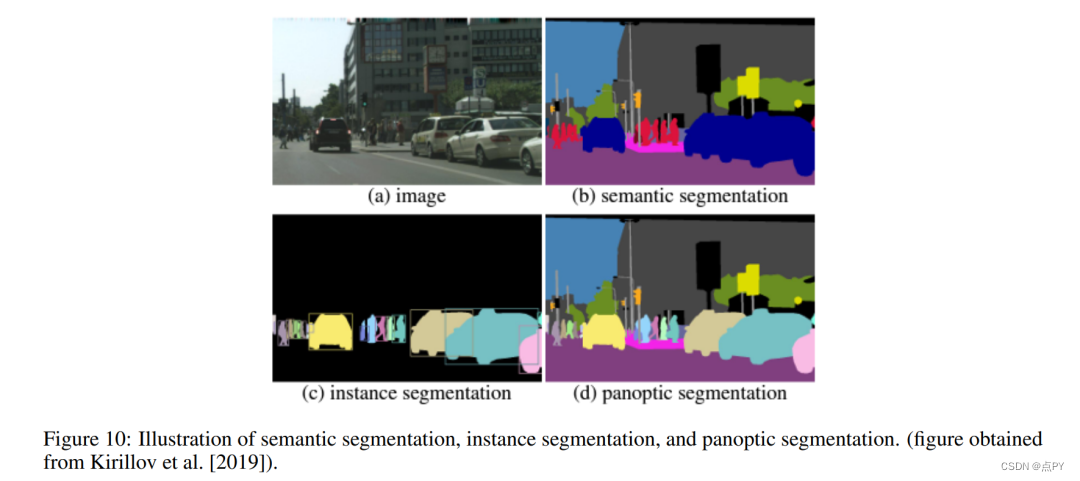
SAM的一个重要特征是它可以在“分割所有事物”的模式下工作。这种模式提供了一个直接的方式来可视化SAM的质量。然而,我们并没有度量标准来评估SAM在这种模式下的性能。评估SAM全能模式的一个主要挑战在于,预测的遮罩没有标签。换句话说,模型只是切割出对象,而没有赋予标签,因此我们将全能模式称为切割分割。在我们介绍我们提出的切割分割度量标准之前,我们首先总结了现有的图像分割任务的度量标准,如图10所示。
5 . 结论
基于可提示的分割任务,"分割任何事物"模型(SAM)是首个模仿人眼理解世界的视觉基础模型,其出现彻底改变了计算机视觉社区。我们的工作进行了对SAM的首次而全面的调研。我们希望我们的调研能帮助对SAM感兴趣并希望进行相关研究的读者。
参考
https://mp.weixin.qq.com/s/Qqhox8Ua2M4Bc8Z4twUdTg