目录
1.GAN
2.AutoEncoder及其变种:AE/DAE/VAE/VQVAE
2.1 AE:
2.2 DAE:Denoising AutoEncoder
2.3 VAE:Variational AutoEncoder
2.4 VQVAE:Vector-quantised Variational AutoEncoder
3. 扩散模型
3.1 扩散模型的基本原理
3.2 扩散模型的发展历程
3.2.1 DDPM
3.2.2 improved DDPM
3.3.3 Diffusion Model Beats GAN
3.2.4 Glide
3.2.5 DALLE 2
4.AE家族 vs 扩散模型
本文简单介绍了下图像生成相关的一些模型。
本来想从吴恩达的deepai课程开始写的,但是感觉还是不够简单,推荐跟着李沐学AI里的DALL·E 2,我个人觉得讲的蛮清楚的。
传送门:DALL·E 2(内含扩散模型介绍)【论文精读】_哔哩哔哩_bilibili,从28分开始讲解。
1.GAN
GAN就是左右手互搏,生成器(G)和判别器(D)。

生成器:给定随机噪声,生成图像X’,希望X’尽可能的接近真实图像。
判别器:给定X’和真实图像X,判别图片真假。
目标函数:
通过训练,生成器和判别器不断迭代,最终生成器可以生成比较逼真的图像。
优点:生成的图像比较逼真,需要的数据量不那么多,可以在各个场景下使用
缺点:训练不稳定,容易模型坍塌。
图片真实但是多样性不足。
非概率模型,隐式生成图像,在数学上的可解释性不如VAE
2.AutoEncoder及其变种:AE/DAE/VAE/VQVAE
2.1 AE:
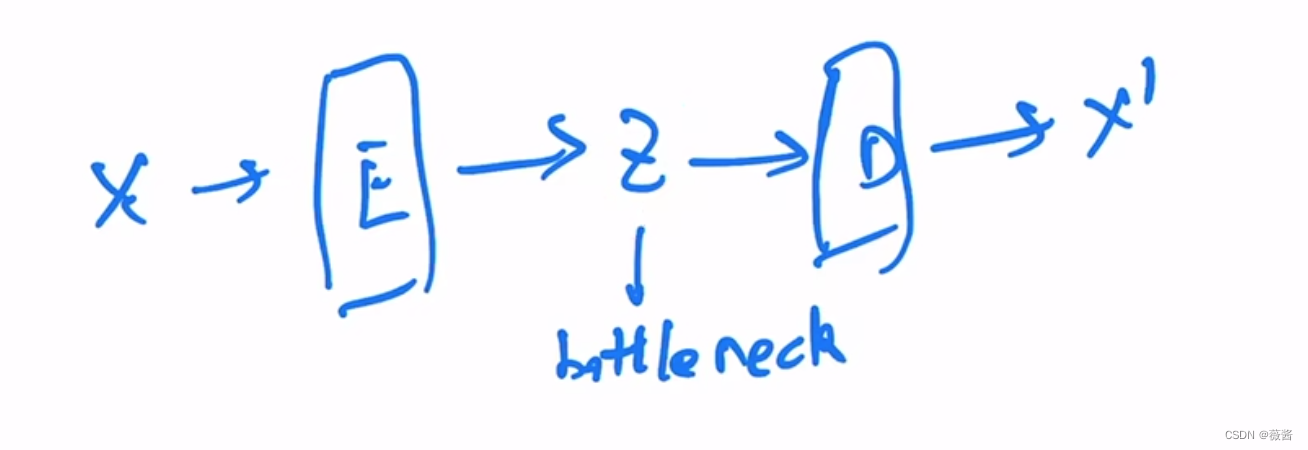
原始图像X通过encoder后,得到一个较小维度的特征(bottleneck),再从bottleneck开始,经过decoder后得到新的X',希望X‘尽可能重建原始X。
2.2 DAE:Denoising AutoEncoder
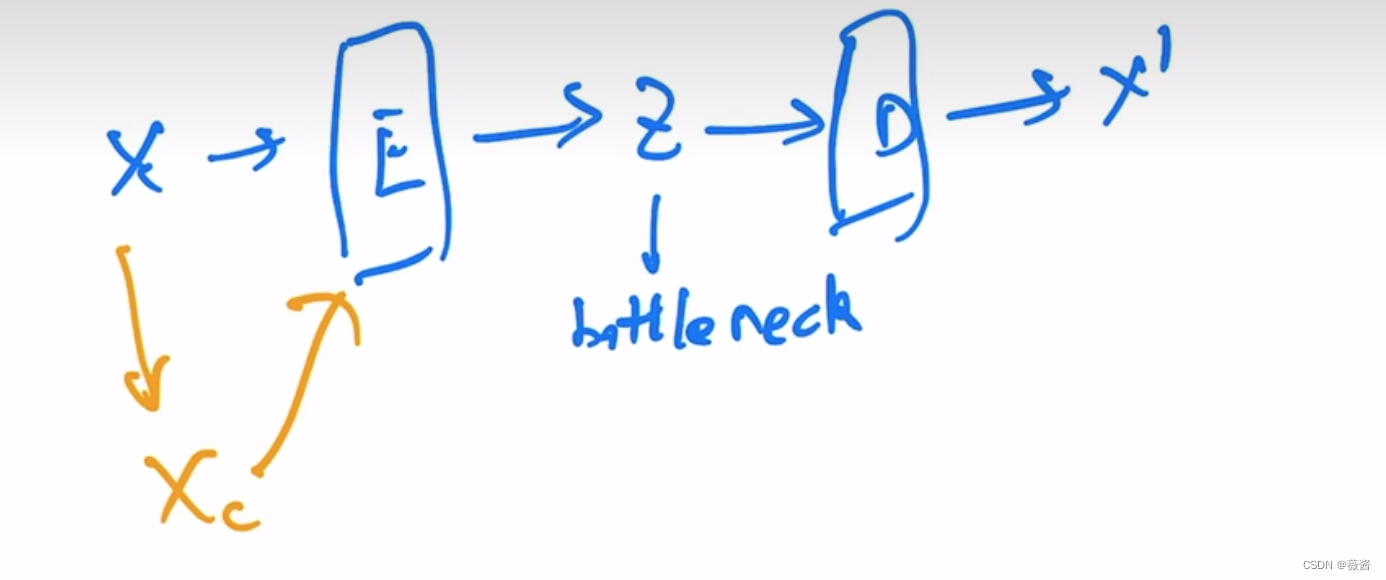
原始图像经过扰乱后得到Xc(X corrupt),再将Xc传给encoder,后续和AE的步骤一致,目标也是希望X’能够尽可能地重建X(而不是扰乱之后的Xc)
优点:训练出来的结果非常的稳健,也不容易过拟合(原因:图像这边的冗余太高了,参考MAE,masked AutoEncoder,masked 75%)
AE/DAE/MAE的目标都是生成中间的bottleneck,可以用这个embedding做下游的分类任务,但是这里的bottleneck不是一个概率分布,没法对其进行采样,所以无法做生成任务。
2.3 VAE:Variational AutoEncoder
 和上面的图很像,只不过不再学习一个固定的bottleneck特征,而是去学习了一个分布,且这个分布满足高斯分布。
和上面的图很像,只不过不再学习一个固定的bottleneck特征,而是去学习了一个分布,且这个分布满足高斯分布。
编码器的特征通过FC层,预测分布的均值和方差,
利用均值和方差,采样一个Z出来,后续的步骤和AE类似。
当模型训练好之后,可以直接由分布生成Z,再通过decoder生成对应的图片X‘,这样就可以做生成任务了。
数学解释:
q(Z|X)后验概率
分布:先验分布
p(X|Z):likelihood
优点:学习的是分布,图像多样性优秀。数学解释性好。
2.4 VQVAE:Vector-quantised Variational AutoEncoder
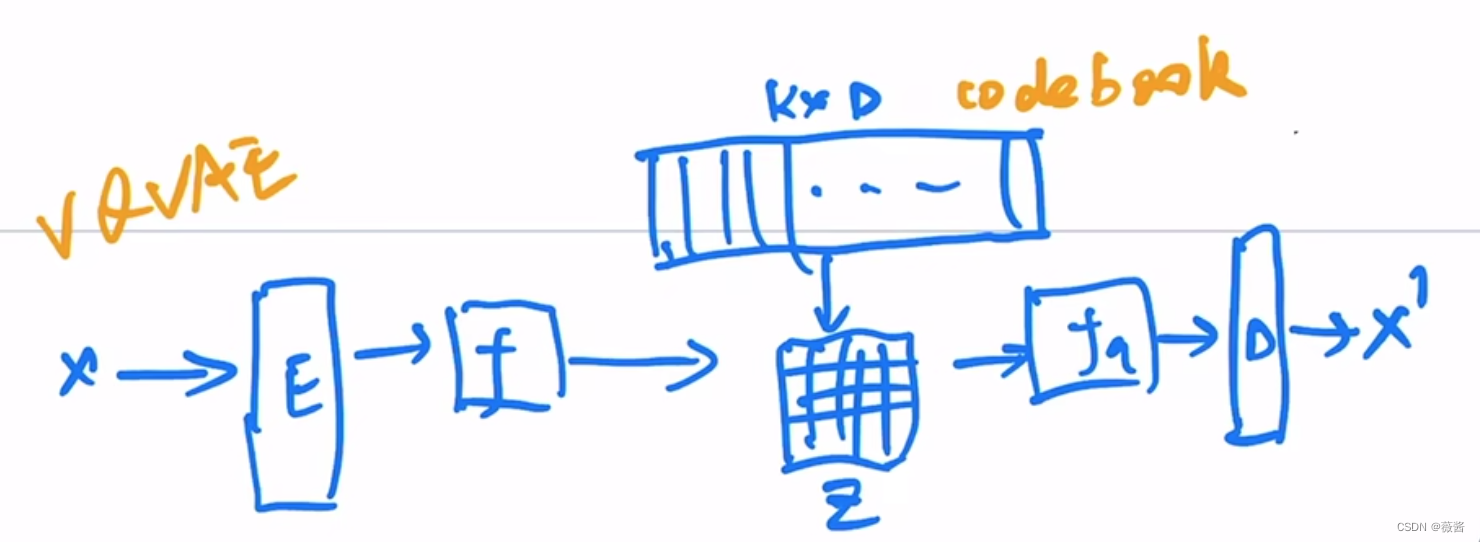
codebook:可以理解为聚类中心 ,用离散化的codebook替代distribution,效果更好(类比分类比回归效果好)
K:一般是8192,向量的个数
D:512或768,向量的维度
图片通过编码器得到特征图f后,在codebook中找到和特征图最接近的聚类中心,将聚类中心的编码记录到Z中,将index对应的特征取出,作为fa,完成后续的流程。
额外训练了一个pixel-CNN,当做prior网络,从而利用已经训练好的codebook去做图像的生成。
3. 扩散模型
3.1 扩散模型的基本原理
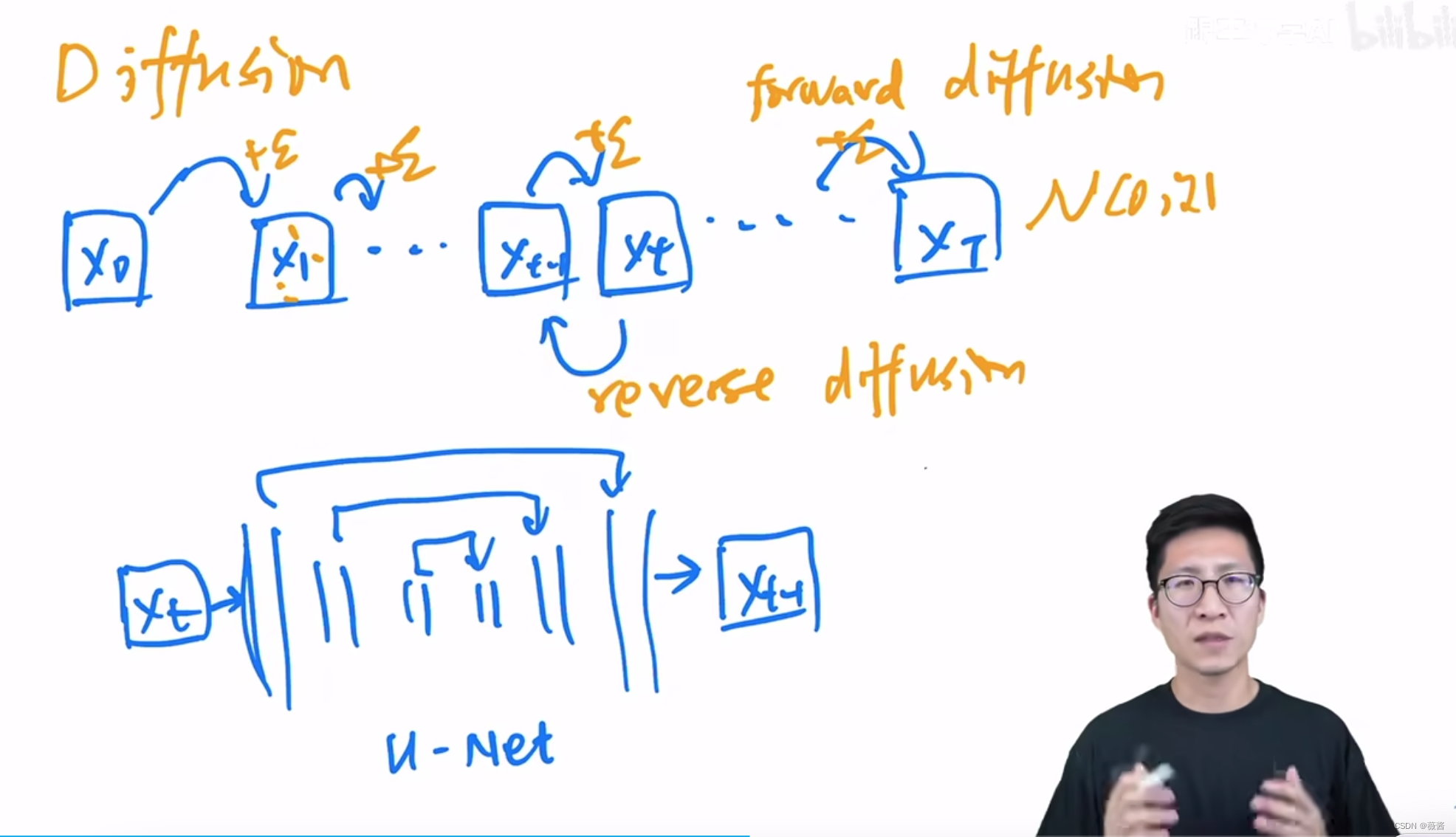 一张图片X0,每一步都给它加一个极小的噪声,T步之后得到XT,当T特别大时,这时的XT就趋近于一个真正的噪声,满足各向同性的正态分布,整个过程就是forward disfussion,前向扩散过程。
一张图片X0,每一步都给它加一个极小的噪声,T步之后得到XT,当T特别大时,这时的XT就趋近于一个真正的噪声,满足各向同性的正态分布,整个过程就是forward disfussion,前向扩散过程。
reverse diffusion整个过程反过来,抽样一个噪声XT,通过不断地消除一点点噪声,T步之后,就可以得到一个真正的图片X0,所有的Xt->Xt-1都是用的同一个模型,共享参数,只不过需要抽样很多次。
U-Net:扩散模型一般使用的是U-Net模型,也就是CNN模型。
先用编码器不断压缩图像,再用解码器不断恢复图像,输入图像和输出图像大小一致,中间还有skip-connection,帮助更好地恢复图像。后续也有加入attention的操作,帮助更好地生成图像。
缺点:非常贵,推理也需要T次(T一般是1000)
3.2 扩散模型的发展历程
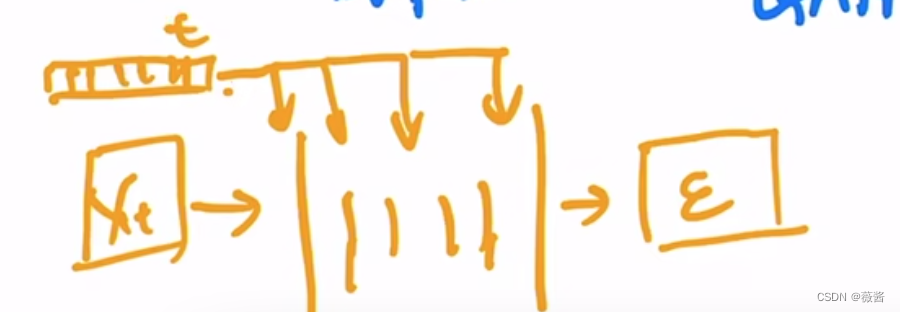
3.2.1 DDPM
- 优化了SD的预测目标,将其从图像->图像,变为了去预测对应的噪声是如何加上的,有点像resnet,去预测对应的 residual。
- 加入了temporal embedding,时序相关的embedding,因为所有步骤的unet结构都一致,我们希望模型在不同步能够生成不同的东西就通过这个embedding来(PS:使用Stable Diffusion的时候会发现,先有轮廓再有细节就是因为这个)
- 提出只需要预测均值(方差只需要是常数就可以工作的很好),进一步降低模型优化的难度。
3.2.2 improved DDPM
1.在DDPM的基础上,还是去学习了对应的方差,生成图片的效果进一步提升。
2.添加噪声的schedule 由线性改为余弦添加(类似学习率的余弦schedule)
3.尝试使用扩散模型的大模型,发现模型越大,效果也越好。
3.3.3 Diffusion Model Beats GAN
1.将模型加大加宽
增加自注意力头的数量,single-scale attention->multi-scale attention(多尺度注意力是指在神经网络中引入多个不同尺度的特征图,然后通过注意力机制对这些特征图进行加权融合,从而提高模型对不同尺度信息的感知能力和表达能力。)
2.新的归一化方式(Adaptive Group Normalization)
根据步数做自适应的归一化
3.classifier guidance
引导模型做采样和生成,让生成的图片效果更逼真,也加速了反向采样的速度(只需要25次反向采样,相比于之前的1000次,速度提升非常大)
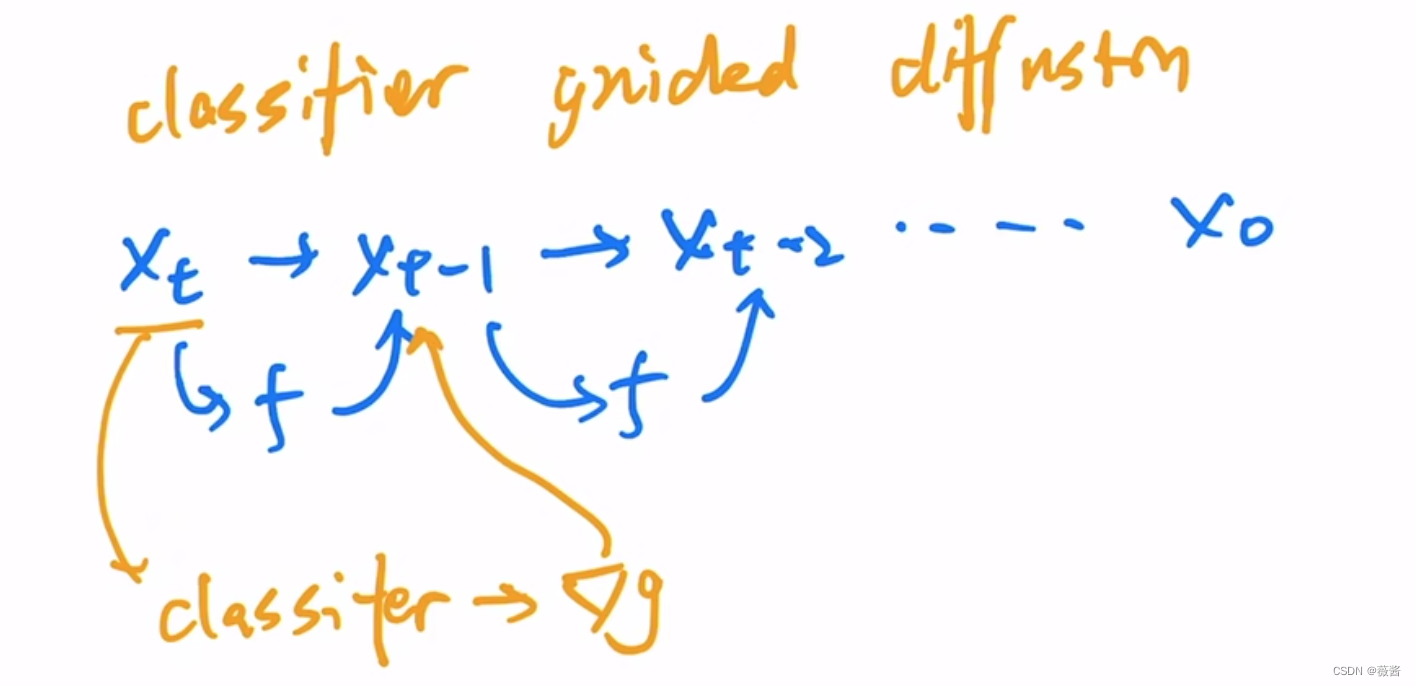
图中的classifer 是在有噪声的ImageNet上训练的图片分类器,加入噪声是因为扩散模型本身就是在有噪声的图片上训练的。
每次训练时,将Xt传给classifer,预测它对应所属的类别,并且计算交叉熵,得到梯度g,用梯度g来指导后续噪声的采样。通过梯度的引导,让Unet采样的结果尽可能接近真实的物体,也就是能被classifer正确分类。
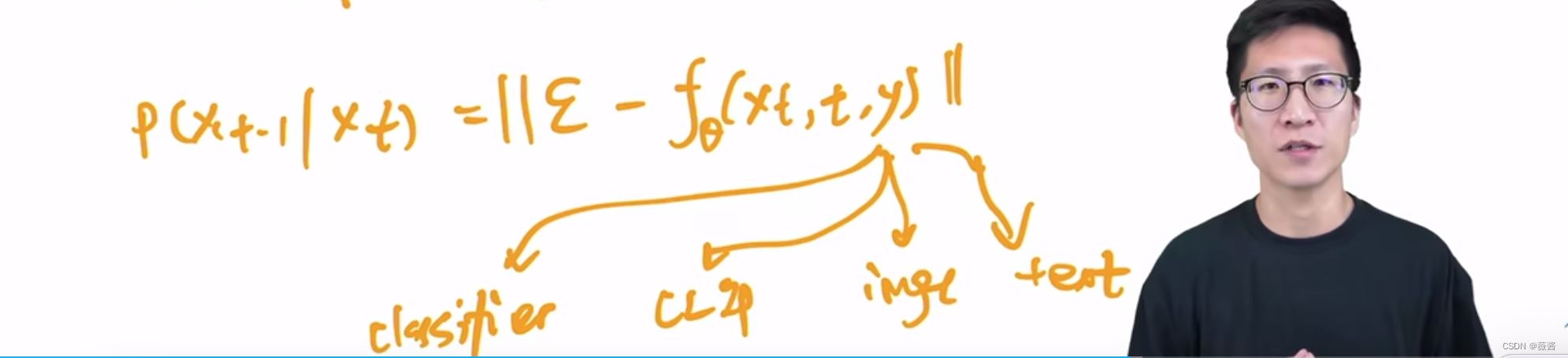
除了classifer之外,还有clip、image、text等其他的引导方式。它们都相当于是公式中条件y。
clip:后续除了使用classifer来引导图片的采样和生成,也可以将其:替换成clip,将文本和图像联系起来,从而用文本来引导图片的采样和生成,
image :图片的重建--像素级别的引导,特征层面的引导,图像风格的引导
text:大语言模型做引导
3.2.4 Glide
classifer-free guidance

之前的classfier guidance都是在扩散模型之外,再额外训练一个模型,训练过程不太可控。classifer-free guidance则是同一个模型同时生成2张图片,一张是有条件的(图片左边),一张是无条件的(图片右边),图片右边的条件是一个空集,在训练过程中,让模型学会两张图片的差距。在反向扩散的过程中,通过没有条件生成的图片去推测生成有条件y生成的图片。
3.2.5 DALLE 2
有空补DALLE和DALLE2的坑,哈哈哈。
4.AE家族 vs 扩散模型
都可以视作是编码器解码器结构
区别:1.AE的编码器是学习到的,Diffusion的编码器是固定的过程(这种固定更像是说,每一步都走同一道门,走1000次,最终变成了不同的样子,意会一下)
2.扩散模型每一步的中间过程,尺寸和原始图片大小都是相同的,而AE的bottleneck则是远小于输入图片的。
3.扩散模型有很多步,所以有time step,time embedding的概念,而在AE中则没有。
后续应该还会开坑:
1.写dalle和dalle2,这2个是使用文本生成图像的,效果也很惊艳。网上也有一些API可以玩
2.吴恩达的扩散模型系列,好像视频只有半小时,看看有没有新东西,如果有的话,也蹭个热度。
3.unclip,比如blip
感兴趣的可以点个关注,ღ( ´・ᴗ・` )比心