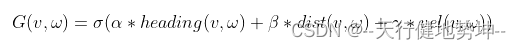YOLOv5-Face
文章目录
- YOLOv5-Face
- 1. 为什么人脸检测 = 一般检测?
- 1.1 YOLOv5Face人脸检测
- 1.2 YOLOv5Face Landmark
- 2.YOLOv5Face的设计目标和主要贡献
- 2.1 设计目标
- 2.2 主要贡献
- 3. YOLOv5Face架构
- 3.1 模型架构
- 3.1.1 模型示意图
- 3.1.2 CBS模块
- 3.1.3 Head输出
- 3.1.4 stem结构
- 3.1.5 CSP结构
- 3.1.9 SPP结构
- 3.2 输入端的改进
- 3.3 Landmark回归
- 3.3.1 输出 Landmark
- 3.3.2 Landmark损失函数Wing
- 3.3.3 Wing Loss
- 3.4 后处理NMS
- 3.4.1 yolov5
- 3.4.2 yolov5s-face
- 4.模型训练
- 4.1 下载源码
- 4.2 下载widerface数据集
- 4.3 运行train2yolo.py和val2yolo.py
- 4.4 train
- 4.4.1 更改训练配置文件
- 4.4.2 训练可视化
- 4.4.3 相关报错
- 4.5 detect
- 4.6 ONNX导出及TensorRT环境配置
- 4.7 OnnXruntime推理

近年来,CNN在人脸检测方面已经得到广泛的应用。但是许多人脸检测器都是需要使用特别设计的人脸检测器来进行人脸的检测,而YOLOv5的作者则是把人脸检测作为一个一般的目标检测任务来看待的。
YOLOv5Face在YOLOv5的基础上添加了一个 5-Point Landmark Regression Head(关键点回归),并对Landmark Regression Head使用了Wing loss进行约束。YOLOv5Face设计了不同模型尺寸的检测器,从大模型到超小模型,以实现在嵌入式或移动设备上的实时检测。
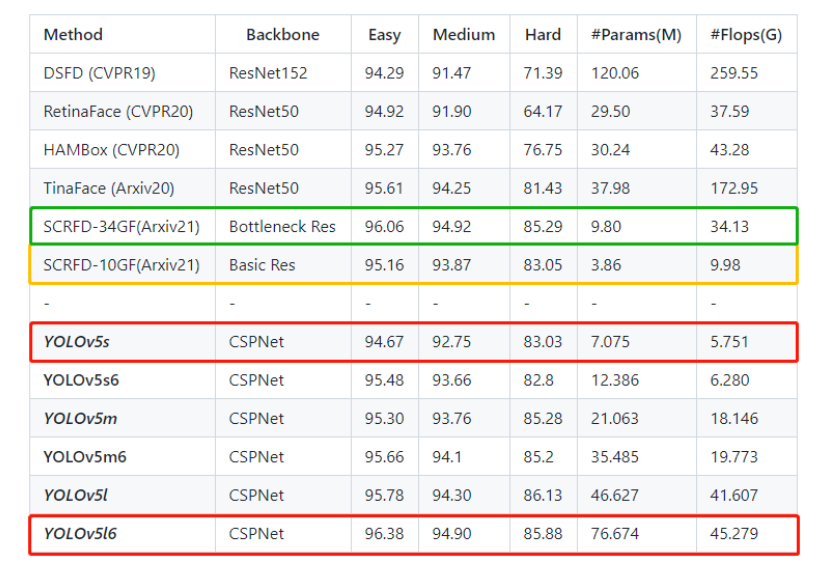
在WiderFace数据集上的实验结果表明,YOLOv5Face在几乎所有的Easy、Medium和Hard子集上都能达到最先进的性能,超过了特定设计的人脸检测器。
Github地址:https://www.github.com/deepcam-cn/yolov5-face
1. 为什么人脸检测 = 一般检测?
1.1 YOLOv5Face人脸检测
在YOLOv5Face的方法中是把人脸检测作为一个一般的目标检测任务。与TinaFace想法类似把人脸作为一个目标。正如在TinaFace中所讨论的:
- 从数据的角度来看,人脸所具有的诸如姿态、尺度、遮挡、光照以及模糊等也会出现在其他的一般检测任务之中;
- 从面部的独特属来看性,如表情和化妆,也可以对应一般检测问题中的形状变化和颜色变化。
1.2 YOLOv5Face Landmark
Landmark相对来说是一个特殊的存在,但他们也并不是唯一的。它们只是一个物体的关键点。例如,在车牌检测中,也使用了Landmark。在目标预测模型的Head中添加Landmark回归相对来说是一键简单的事情。那么从人脸检测所面临的挑战来看,多尺度、小人脸、密集场景等在一般的目标检测中都存在。因此,人脸检测完全可以看作一个一般目标检测子任务。
2.YOLOv5Face的设计目标和主要贡献
2.1 设计目标
YOLOv5Face针对人脸检测的对YOLOv5进行了再设计和修改,考虑到大人脸、小人脸、Landmark监督等不同的复杂性和应用。YOLOv5Face的目标是为不同的应用程序提供一个模型组合,从非常复杂的应用程序到非常简单的应用程序,以在嵌入式或移动设备上获得性能和速度的最佳权衡。
2.2 主要贡献
- 重新设计了YOLOV5来作为一个人脸检测器,并称之为YOLOv5Face。对网络进行了关键的修改,以提高平均平均精度(mAP)和速度方面的性能;
- 设计了一系列不同规模的模型,从大型模型到中型模型,再到超小模型,以满足不同应用中的需要。除了在YOLOv5中使用的Backbone外,还实现了一个基于ShuffleNetV2的Backbone,它为移动设备提供了最先进的性能和快速的速度;
- 在WiderFace数据集上评估了YOLOv5Face模型。在VGA分辨率的图像上,几乎所有的模型都达到了SOTA性能和速度。这也证明了前面的结论,不需要重新设计一个人脸检测器,因为YOLO5就可以完成它。
3. YOLOv5Face架构
3.1 模型架构
3.1.1 模型示意图
YOLOv5Face是以YOLOv5作为Baseline来进行改进和再设计以适应人脸检测。这里主要是检测小脸和大脸的修改。
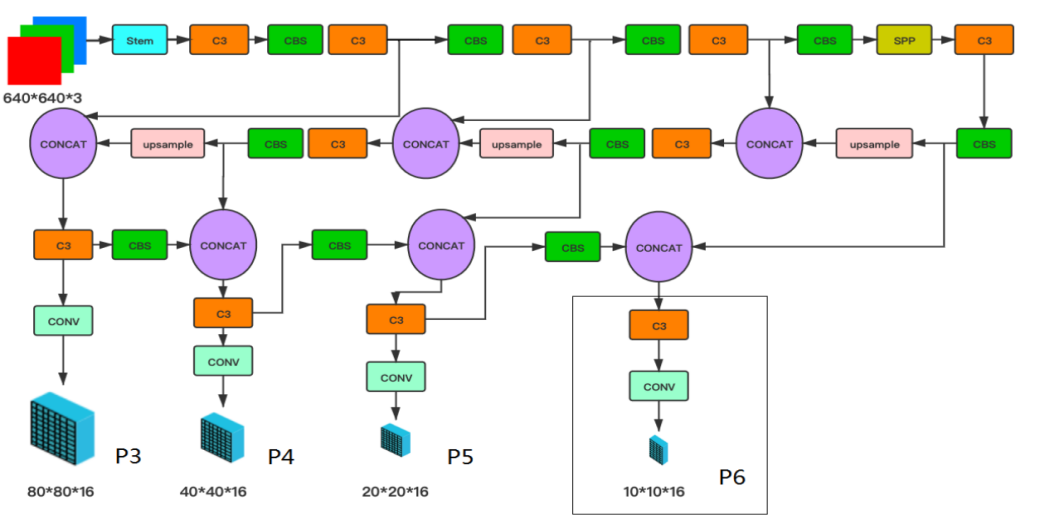
YOLO5人脸检测器的网络架构如图1所示。它由Backbone、Neck和Head组成,描述了整体的网络体系结构。在YOLOv5中,使用了CSPNet Backbone。在Neck中使用了SPP和PAN来融合这些特征。在Head中也都使用了回归和分类。
3.1.2 CBS模块
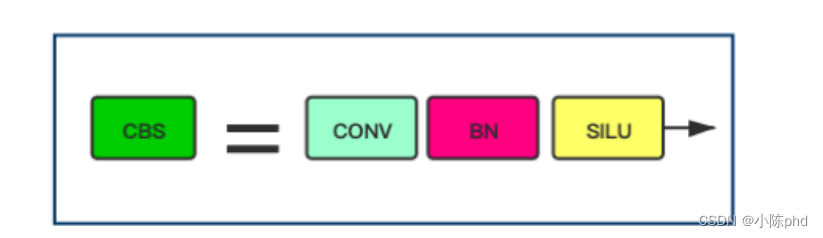
在图中,定义了一个CBS Block,它由Conv、BN和SiLU激活函数组成。CBS Block也被用于许多其他Block之中。
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Conv, self).__init__()
# 卷积层
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
# BN层
self.bn = nn.BatchNorm2d(c2)
# SiLU激活层
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
3.1.3 Head输出

显示Head的输出标签,其中包括边界框(bbox)、置信度(conf)、分类(cls)和5-Point Landmarks。这些Landmarks是对YOLOv5的改进点,使其成为一个具有Landmarks输出的人脸检测器。如果没有Landmarks,最后一个向量的长度应该是6而不是16。框(4)+置信度(1)+关键点(5*2)+cls(类别)
P3中的输出尺寸80×80×16,P4中的40×40×16,P5中的20×20×16,可选P6中的10×10×16为每个Anchor。实际的尺寸应该乘以Anchor的数量。
3.1.4 stem结构
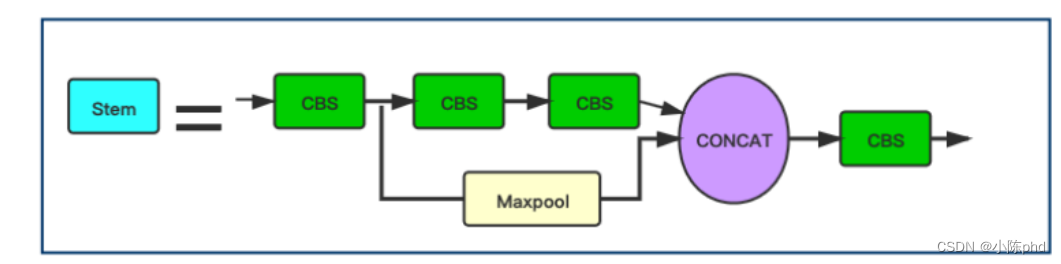
图为stem结构,它用于取代YOLOv5中原来的Focus层。在YOLOv5中引入Stem块用于人脸检测是YOLOv5Face的创新之一。
class StemBlock(nn.Module):
def __init__(self, c1, c2, k=3, s=2, p=None, g=1, act=True):
super(StemBlock, self).__init__()
# 3×3卷积
self.stem_1 = Conv(c1, c2, k, s, p, g, act)
# 1×1卷积
self.stem_2a = Conv(c2, c2 // 2, 1, 1, 0)
# 3×3卷积
self.stem_2b = Conv(c2 // 2, c2, 3, 2, 1)
# 最大池化层
self.stem_2p = nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)
# 1×1卷积
self.stem_3 = Conv(c2 * 2, c2, 1, 1, 0)
def forward(self, x):
stem_1_out = self.stem_1(x)
stem_2a_out = self.stem_2a(stem_1_out)
stem_2b_out = self.stem_2b(stem_2a_out)
stem_2p_out = self.stem_2p(stem_1_out)
out = self.stem_3(torch.cat((stem_2b_out, stem_2p_out), 1))
return out
用Stem模块替代网络中原有的Focus模块,提高了网络的泛化能力,降低了计算复杂度,同时性能也没有下降。Stem模块的图示中虽然都是用的CBS,但是看代码可以看出来第2个和第4个CBS是1×1卷积,第1个和第3个CBS是3×3,stride=2的卷积。配合yaml文件可以看到stem以后图像大小由640×640变成了160×160。
3.1.5 CSP结构
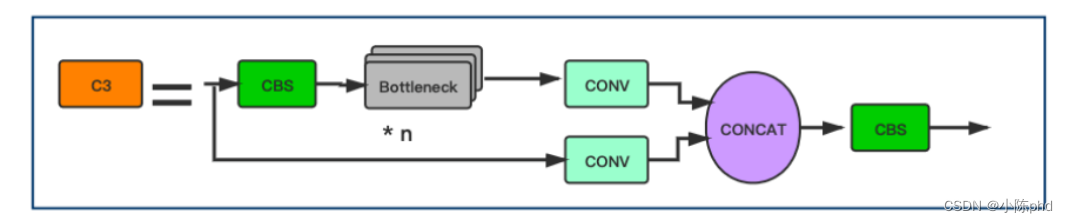
CSP Block的设计灵感来自于DenseNet。但是,不是在一些CNN层之后添加完整的输入和输出,输入被分成 2 部分。其中一半通过一个CBS Block,即一些Bottleneck Blocks,另一半是经过Conv层进行计算:
class C3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(C3, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
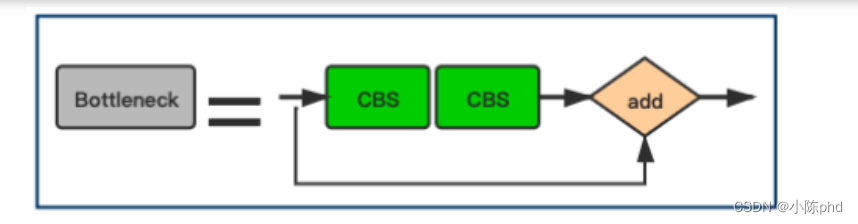
其中Bottleneck层表示为:
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super(Bottleneck, self).__init__()
c_ = int(c2 * e) # hidden channels
#第1个CBS模块
self.cv1 = Conv(c1, c_, 1, 1)
#第2个CBS模块
self.cv2 = Conv(c_, c2, 3, 1, g=g)
#元素add操作
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
3.1.9 SPP结构
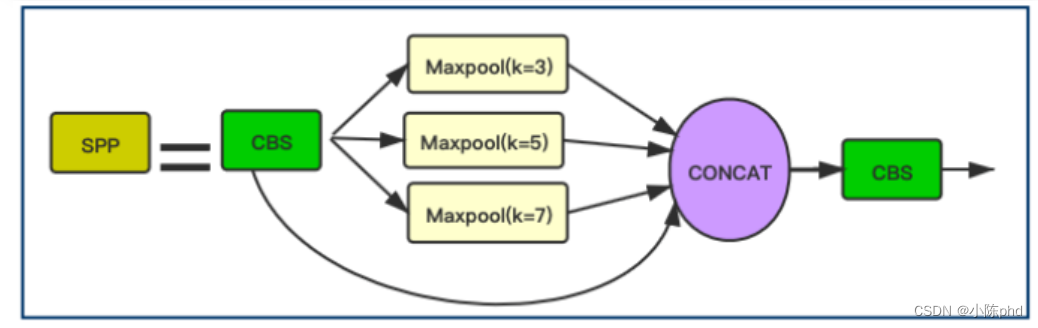
YOLOv5Face在这个Block中把YOLOv5中的13×13,9×9,5×5的kernel size被修改为7×7,5×5,3×3,这个改进更适用于人脸检测并提高了人脸检测的精度。
class SPP(nn.Module):
# 这里主要是讲YOLOv5中的kernel=(5,7,13)修改为(3, 5, 7)
def __init__(self, c1, c2, k=(3, 5, 7)):
super(SPP, self).__init__()
c_ = c1 // 2 # hidden channels
# 对应第1个CBS Block
self.conv1 = Conv(c1, c_, 1, 1)
# 对应第2个 cat后的 CBS Block
self.conv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
# ModuleList=[3×3 MaxPool2d,5×5 MaxPool2d,7×7 MaxPool2d]
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
x = self.conv1(x)
return self.conv2(torch.cat([x] + [m(x) for m in self.m], 1))
同时,YOLOv5Face添加一个stride=64的P6输出块,P6可以提高对大人脸的检测性能。(之前的人脸检测模型大多关注提高小人脸的检测性能,这里作者关注了大人脸的检测效果,提高大人脸的检测性能来提升模型整体的检测性能)。P6的特征图大小为10x10。
注意,这里只考虑VGA分辨率的输入图像。为了更精确地说,输入图像的较长的边缘被缩放到640,并且较短的边缘被相应地缩放。较短的边缘也被调整为SPP块最大步幅的倍数。例如,当不使用P6时,较短的边需要是32的倍数;当使用P6时,较短的边需要是64的倍数。
3.2 输入端的改进
一些目标检测的数据增广方法并不适合用在人脸检测中,包括上下翻转和Mosaic数据增广。
- 删除上下翻转可以提高模型性能。
- 对小人脸进行Mosaic数据增广反而会降低模型性能,但是对中尺度和大尺度人脸进行Mosaic可以提高性能。
- 随机裁剪有助于提高性能。
备注:COCO数据集和WiderFace数据集尺度有差异,WiderFace数据集小尺度数据相对较多。
3.3 Landmark回归
3.3.1 输出 Landmark
Landmark是人脸的重要特征。它们可以用于人脸比对、人脸识别、面部表情分析、年龄分析等任务。传统Landmark由68个点组成。它们被简化为5点时,这5点Landmark就被广泛应用于面部识别。人脸标识的质量直接影响人脸对齐和人脸识别的质量。
- 一般的物体检测器不包括Landmark。可以直接将其添加为回归Head。因此,作者将它添加到YOLO5Face中。Landmark输出将用于对齐人脸图像,然后将其发送到人脸识别网络。
3.3.2 Landmark损失函数Wing
用于Landmark回归的一般损失函数为L2、L1或smooth-L1。MTCNN使用的就是L2损失函数。然而,作者发现这些损失函数对小的误差并不敏感。为了克服这个问题,提出了Wing loss:
wing
(
x
)
=
{
w
ln
(
1
+
∣
x
∣
/
ϵ
)
if
∣
x
∣
<
w
∣
x
∣
−
C
otherwise
\operatorname{wing}(x)= \begin{cases}w \ln (1+|x| / \epsilon) & \text { if }|x|<w \\ |x|-C & \text { otherwise }\end{cases}
wing(x)={wln(1+∣x∣/ϵ)∣x∣−C if ∣x∣<w otherwise
w
:
w:
w: 正数
w
w
w 将非线性部分的范围限制在
[
−
w
,
w
]
[-w, w]
[−w,w] 区间内;
ϵ
\epsilon
ϵ :约束非线性区域的曲率,并且
C
=
w
−
w
ln
(
1
+
x
ϵ
)
C=w-w \ln \left(1+\frac{x}{\epsilon}\right)
C=w−wln(1+ϵx) 是一个常数,可与平滑的来连接分段 的线性和非线性部分。
ϵ
\epsilon
ϵ 的取值是一个很小的数值,因为它会使网络训练变得不稳定,并且会 因为很小的误差导致梯度爆炸问题。
实际上,的Wing loss函数的非线性部分只是简单地采用
ln
(
x
)
\ln (x)
ln(x) 在
[
ϵ
/
w
,
1
+
ϵ
/
w
]
[\epsilon / w, 1+\epsilon / w]
[ϵ/w,1+ϵ/w] 之间的曲 线,并沿X轴和
Y
Y
Y 轴将其缩放比例为W。另外,沿
Y
Y
Y 轴应用平移以使wing
(
0
)
=
0
(0)=0
(0)=0, 并在损失函 数上施加连续性。
Landmark点向量
s
=
{
s
i
}
s=\left\{s_i\right\}
s={si} 与其ground truth
s
′
=
{
s
i
}
s^{\prime}=\left\{s_i\right\}
s′={si} 的损失函数为:
loss
L
(
s
)
=
∑
i
wing
(
s
i
−
s
i
′
)
\operatorname{loss}_L(s)=\sum_i \operatorname{wing}\left(s_i-s_i^{\prime}\right)
lossL(s)=i∑wing(si−si′)
其中
i
=
1
,
2
,
…
,
10
i=1,2, \ldots, 10
i=1,2,…,10 。
设YOLOv5中通用的目标检测损失函数为
l
o
s
s
O
l o s s_O
lossO ,则新的总损失函数为:
loss
(
s
)
=
loss
O
+
λ
L
⋅
loss
L
\operatorname{loss}(s)=\operatorname{loss}_O+\lambda_L \cdot \operatorname{loss}_L
loss(s)=lossO+λL⋅lossL
其中
λ
L
\lambda_L
λL 为Landmark回归损失函数的权重因子。
landmark的获取:其中
i
=
1
,
2
,
…
,
10
i=1,2, \ldots, 10
i=1,2,…,10 。
设YOLOv5 中通用的目标检测损失函数为
l
o
s
s
O
l o s s_O
lossO ,则新的总损失函数为:
loss
(
s
)
=
loss
O
+
λ
L
⋅
loss
L
\operatorname{loss}(s)=\operatorname{loss}_O+\lambda_L \cdot \operatorname{loss}_L
loss(s)=lossO+λL⋅lossL
其中
λ
L
\lambda_L
λL 为Landmark回归损失函数的权重因子。
landmark的获取:
#landmarks
lks = t[:,6:14]
lks_mask = torch.where(lks < 0, torch.full_like(lks, 0.), torch.full_like(lks, 1.0))
#应该是关键点的坐标除以anch的宽高才对,便于模型学习。使用gwh会导致不同关键点的编码不同,没有统一的参考标准
lks[:, [0, 1]] = (lks[:, [0, 1]] - gij)
lks[:, [2, 3]] = (lks[:, [2, 3]] - gij)
lks[:, [4, 5]] = (lks[:, [4, 5]] - gij)
lks[:, [6, 7]] = (lks[:, [6, 7]] - gij)
Wing Loss的计算如下:
class WingLoss(nn.Module):
def __init__(self, w=10, e=2):
super(WingLoss, self).__init__()
# https://arxiv.org/pdf/1711.06753v4.pdf Figure 5
self.w = w
self.e = e
self.C = self.w - self.w * np.log(1 + self.w / self.e)
def forward(self, x, t, sigma=1): #这里的x,t分别对应之后的pret,truel
weight = torch.ones_like(t) #返回一个大小为1的张量,大小与t相同
weight[torch.where(t==-1)] = 0
diff = weight * (x - t)
abs_diff = diff.abs()
flag = (abs_diff.data < self.w).float()
y = flag * self.w * torch.log(1 + abs_diff / self.e) + (1 - flag) * (abs_diff - self.C) #全是0,1
return y.sum()
class LandmarksLoss(nn.Module):
# BCEwithLogitLoss() with reduced missing label effects.
def __init__(self, alpha=1.0):
super(LandmarksLoss, self).__init__()
self.loss_fcn = WingLoss()#nn.SmoothL1Loss(reduction='sum')
self.alpha = alpha
def forward(self, pred, truel, mask): #预测的,真实的 600(原来为62*10)(推测是去掉了那些没有标注的值)
loss = self.loss_fcn(pred*mask, truel*mask) #一个值(tensor)
return loss / (torch.sum(mask) + 10e-14)
分析比较L1,L2和Smooth L1损失函数
loss
(
s
,
s
′
)
=
∑
i
=
1
2
L
f
(
s
i
−
s
i
′
)
\operatorname{loss}\left(\mathbf{s}, \mathbf{s}^{\prime}\right)=\sum_{i=1}^{2 L} f\left(s_i-s_i^{\prime}\right)
loss(s,s′)=i=1∑2Lf(si−si′)
其中
s
s
s 是人脸关键点的ground-truth,函数
f
(
x
)
f(x)
f(x) 就等价于:
L1 loss
L
1
(
x
)
=
∣
x
∣
L 1(x)=|x|
L1(x)=∣x∣
L2 loss
L
2
(
x
)
=
1
2
x
2
L 2(x)=\frac{1}{2} x^2
L2(x)=21x2
Smooth L 1 ( x ) : smooth L 1 ( x ) = { 1 2 x 2 if ∣ x ∣ < 1 ∣ x ∣ − 1 2 otherwise \operatorname{Smooth}_{L 1}(x): \operatorname{smooth}_{L 1}(x)= \begin{cases}\frac{1}{2} x^2 & \text { if }|x|<1 \\ |x|-\frac{1}{2} & \text { otherwise }\end{cases} SmoothL1(x):smoothL1(x)={21x2∣x∣−21 if ∣x∣<1 otherwise
损失函数对
x
x
x 的导数分别为:
d
L
2
(
x
)
d
x
=
x
\frac{d L_2(x)}{d x}=x
dxdL2(x)=x
d L 1 ( x ) d x = { 1 if x ≥ 0 − 1 otherwise \frac{d L_1(x)}{d x}= \begin{cases}1 & \text { if } x \geq 0 \\ -1 & \text { otherwise }\end{cases} dxdL1(x)={1−1 if x≥0 otherwise
d smooth L 1 ( x ) d x = { x if ∣ x ∣ < 1 ± 1 otherwise \frac{d \operatorname{smooth}_{L 1}(x)}{d x}= \begin{cases}x & \text { if }|x|<1 \\ \pm 1 & \text { otherwise }\end{cases} dxdsmoothL1(x)={x±1 if ∣x∣<1 otherwise
-
L2损失函数,当 x x x 增大时L2 loss对 x x x 的导数也增大,这就导致训练初期,预测值与groundtruth差异过大时,损失函数对预测值的梯度十分大,导致训练不稳定。
-
L1 loss的导数为常数,在训练后期,预测值与ground-truth差异很小时,损失对预测值的导 数的绝对值仍然为 1 ,此时学习率(learning rate)如果不变,损失函数将在稳定值附近波动, 难以继续收敛达到更高精度。
-
smooth L1损失函数,在x较小时,对 x x x 的梯度也会变小,而在 x x x 很大时,对 x x x 的梯度的绝对值 达到上限 1,也不会太大以至于破坏网络参数。smooth L1完美地避开了L1和L2损失的缺 陷。
此外,根据fast rcnn的说法, “… L1 loss that is less sensitive to outliers than the L2 loss used in R-CNN and SPPnet.” 也就是smooth L1让loss对于离群点更加鲁棒,即相比于L2 损失函数,其对离群点、异常值 (outlier) 不敏感,梯度变化相对更小,训练时不容易跑飞。
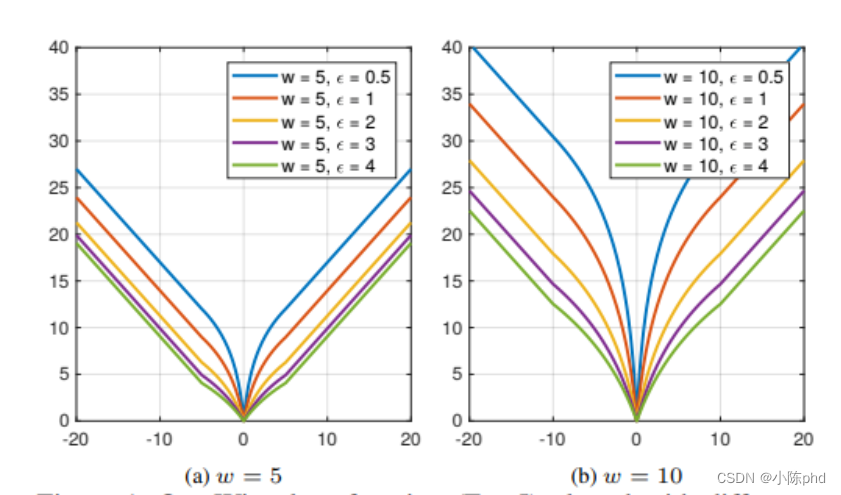
上图描绘了这些损失函数的曲线图。需要注意的是,Smoolth L1损失是Huber损失的一种特殊情况,L2损失函数在人脸关键点检测中被广泛应用,然而,L2损失对异常值很敏感。
3.3.3 Wing Loss
所有损失函数在出现较大误差时表现良好。这说明神经网络的训练应更多地关注具有小或中误差的样本。为了实现此目标,提出了一种新的损失函数,即基于CNN的面部Landmark定位的Wing Loss。

当NME在0.04的时候,测试数据比例已经接近1了,所以在0.04到0.05这一段,也就是所谓的large errros段,并没有分布更多的数据,说明各损失函数在large errors段都表现很好。
模型表现不一致的地方就在于small errors和medium errors段,例如,在NME为0.02的地方画一根竖线,相差甚远的。因此作者提出训练过程中应该更多关注samll or medium range errros样本。
可以使用
ln
x
\ln x
lnx 来增强小误差的影响,它的梯度是
1
x
\frac{1}{x}
x1, 对于接近0的值就会越大,optimal step size 为
x
2
x^2
x2 ,这样gradient就由small errors “主导", step size由large errors “主导"。这样可 以恢复不同大小误差之间的平衡。但是,为了防止在可能的错误方向上进行较大的更新步骤,重要的是不要过度补偿较小的定位 错误的影响。这可以通过选择具有正偏移量的对数函数来实现。
但是这种类型的损失函数适用于处理相对较小的定位误差。在wild人脸关键点检测中,可能会 处理极端姿势,这些姿势最初的定位误差可能非常大,在这种情况下,损失函数应促进从这些 大错误中快速恢复。这表明损失函数的行为应更像
L
1
L 1
L1 或
L
2
L 2
L2 。由于
L
2
L 2
L2 对异常值敏感,因此选择 了L1。
所以,Wing Loss对于小误差,它应该表现为具有偏移量的对数函数,而对于大误差,则应表现为
L
1
L 1
L1 。
3.4 后处理NMS
3.4.1 yolov5
def non_max_suppression(prediction, conf_thres=0.25, iou_thres=0.45, classes=None, agnostic=False, labels=()):
"""Performs Non-Maximum Suppression (NMS) on inference results
Returns:
detections with shape: nx6 (x1, y1, x2, y2, conf, cls)
"""
nc = prediction.shape[2] -5 # number of classes
3.4.2 yolov5s-face
def non_max_suppression_face(prediction, conf_thres=0.25, iou_thres=0.45, classes=None, agnostic=False, labels=()):
"""Performs Non-Maximum Suppression (NMS) on inference results
Returns:
detections with shape: nx6 (x1, y1, x2, y2, conf, cls)
"""
# 不同之处
nc = prediction.shape[2] - 15 # number of classes
4.模型训练
4.1 下载源码
git clone https://github.com/deepcam-cn/yolov5-face
4.2 下载widerface数据集
下载后,解压缩位置放到yolov5-face-master项目里data文件夹下的widerface文件夹下。
https://drive.google.com/file/d/1tU_IjyOwGQfGNUvZGwWWM4SwxKp2PUQ8/view?usp=sharing
4.3 运行train2yolo.py和val2yolo.py
data文件夹下新建widerfaceyolo文件夹,子目录设立为train、test、val
python train2yolo.py ./widerface/train ../data/widerfaceyolo/train
python val2yolo.py ./widerface ../data/widerfaceyolo/val
把数据集转成yolo训练用的格式。完成后文件夹显示如下:

4.4 train
4.4.1 更改训练配置文件
widerface.yaml 更改目录为数据集目录
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: ./data/widerfaceyolo/train # 16551 images
val: ./data/widerfaceyolo/val # 16551 images
#val: /ssd_1t/derron/yolov5-face/data/widerface/train/ # 4952 images
# number of classes
nc: 1
# class names
names: [ 'face']
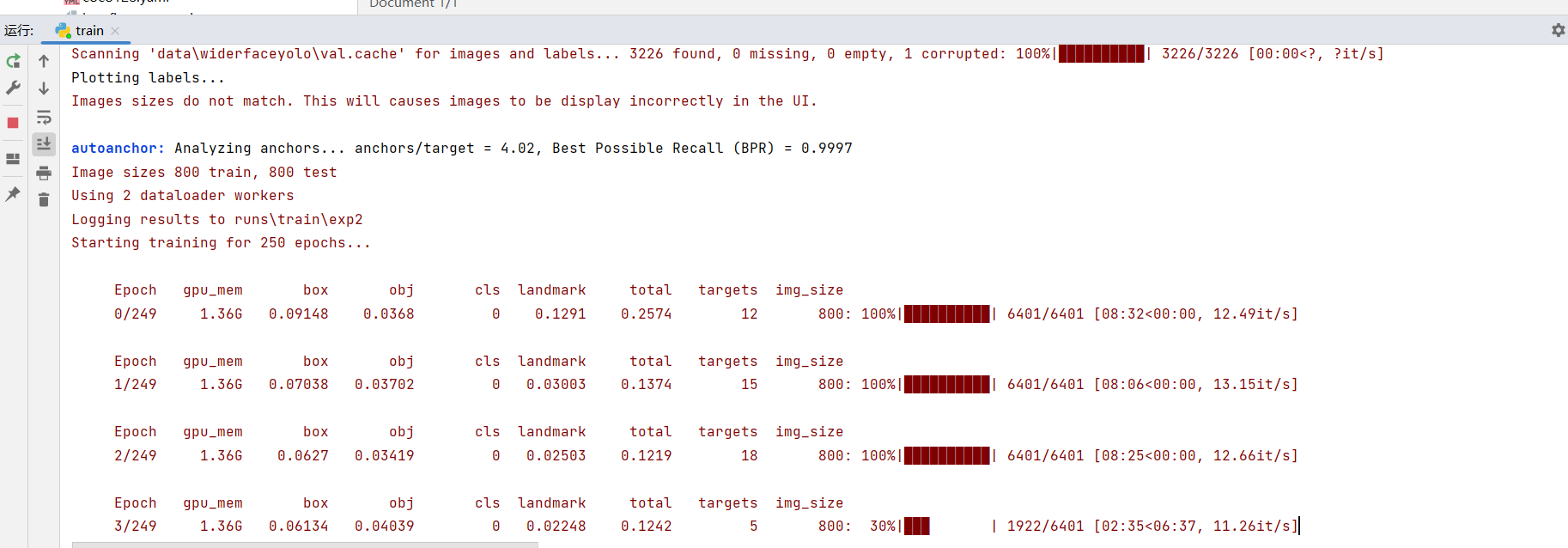
4.4.2 训练可视化
tensorboard --logdir runs/train
4.4.3 相关报错
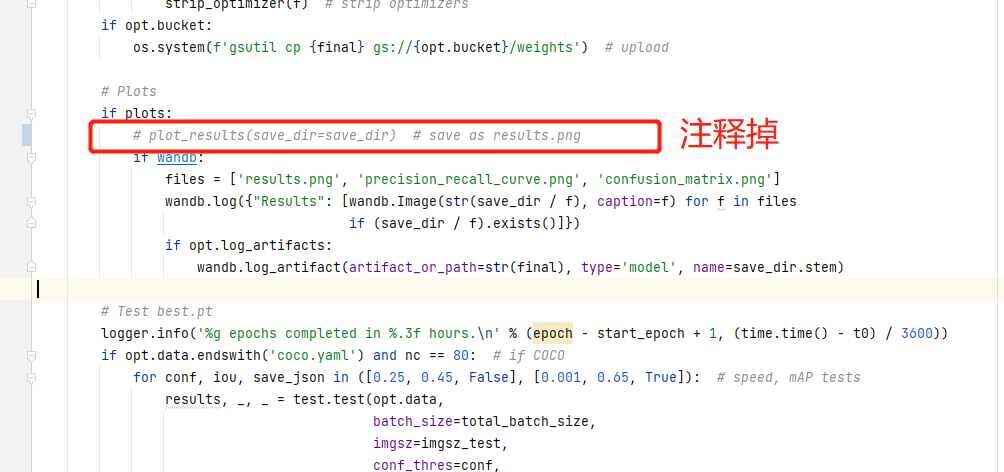
- 无法绘制图像
Traceback (most recent call last):
File "D:\yolov5-face\train.py", line 523, in <module>
train(hyp, opt, device, tb_writer, wandb)
File "D:\yolov5-face\train.py", line 410, in train
plot_results(save_dir=save_dir) # save as results.png
File "D:\yolov5-face\utils\plots.py", line 393, in plot_results
assert len(files), 'No results.txt files found in %s, nothing to plot.' % os.path.abspath(save_dir)
解决方案注释掉这行代码:
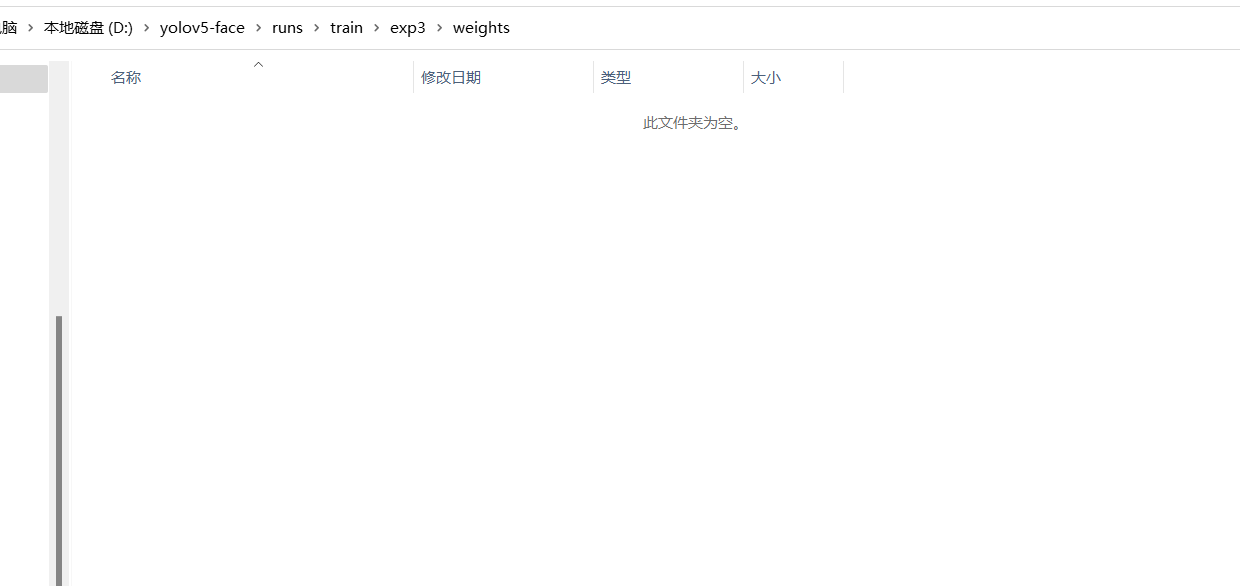
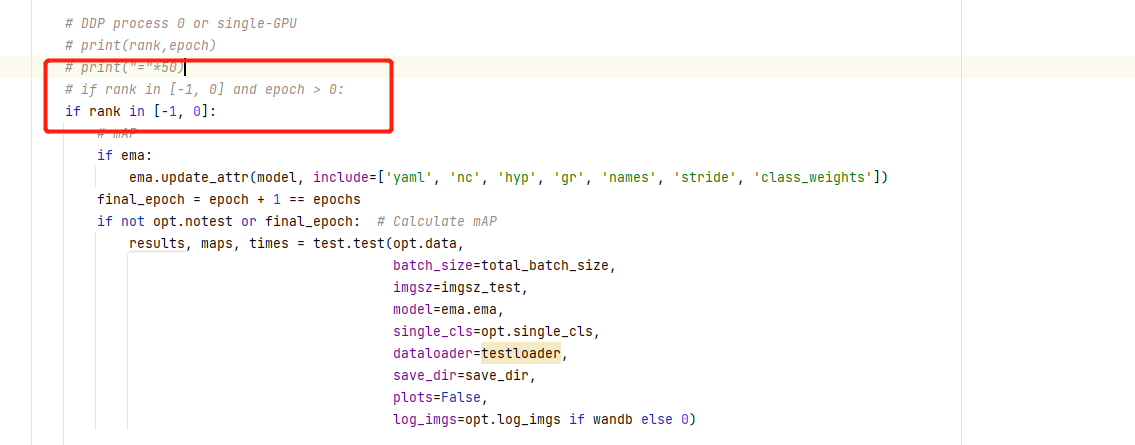
- 不保存权重
训练半天最后竟然发现保存权重为空,注释相关epoch大于20才保存权重代码
4.5 detect
更改代码
if __name__ == '__main__':
parser = argparse.ArgumentParser()
# 更改权重,指定权重类型
parser.add_argument('--weights', nargs='+', type=str, default='yolov5s-face.pt', help='model.pt path(s)')
parser.add_argument('--source', type=str, default='0', help='source') # file/folder, 0 for webcam
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--project', default=ROOT / 'runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--save-img', action='store_true', help='save results')
parser.add_argument('--view-img', default=True,action='store_true', help='show results')
opt = parser.parse_args()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = load_model(opt.weights, device)
detect(model, opt.source, device, opt.project, opt.name, opt.exist_ok, opt.save_img, opt.view_img)
4.6 ONNX导出及TensorRT环境配置
"""Exports a YOLOv5 *.pt model to ONNX and TorchScript formats
Usage:
$ export PYTHONPATH="$PWD" && python models/export.py --weights ./weights/yolov5s.pt --img 640 --batch 1
"""
import argparse
import sys
import time
sys.path.append('./') # to run '$ python *.py' files in subdirectories
import torch
import torch.nn as nn
import models
from models.experimental import attempt_load
from utils.activations import Hardswish, SiLU
from utils.general import set_logging, check_img_size
import onnx
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='./yolov5s-face.pt', help='weights path') # from yolov5/models/
parser.add_argument('--img_size', nargs='+', type=int, default=[640, 640], help='image size') # height, width
parser.add_argument('--batch_size', type=int, default=1, help='batch size')
parser.add_argument('--dynamic', action='store_true', default=False, help='enable dynamic axis in onnx model')
parser.add_argument('--onnx2pb', action='store_true', default=False, help='export onnx to pb')
parser.add_argument('--onnx_infer', action='store_true', default=True, help='onnx infer test')
#=======================TensorRT=================================
parser.add_argument('--onnx2trt', action='store_true', default=True, help='export onnx to tensorrt')
parser.add_argument('--fp16_trt', action='store_true', default=True, help='fp16 infer')
#================================================================
opt = parser.parse_args()
opt.img_size *= 2 if len(opt.img_size) == 1 else 1 # expand
print(opt)
set_logging()
t = time.time()
# Load PyTorch model
model = attempt_load(opt.weights, map_location=torch.device('cpu')) # load FP32 model
delattr(model.model[-1], 'anchor_grid')
model.model[-1].anchor_grid=[torch.zeros(1)] * 3 # nl=3 number of detection layers
model.model[-1].export_cat = True
model.eval()
labels = model.names
print(labels)
# exit()
# Checks
gs = int(max(model.stride)) # grid size (max stride)
opt.img_size = [check_img_size(x, gs) for x in opt.img_size] # verify img_size are gs-multiples
# Input 给定一个输入
img = torch.zeros(opt.batch_size, 3, *opt.img_size) # image size(1,3,320,192) iDetection
# Update model
for k, m in model.named_modules():
m._non_persistent_buffers_set = set() # pytorch 1.6.0 compatibility
if isinstance(m, models.common.Conv): # assign export-friendly activations
if isinstance(m.act, nn.Hardswish):
m.act = Hardswish()
elif isinstance(m.act, nn.SiLU):
m.act = SiLU()
# elif isinstance(m, models.yolo.Detect):
# m.forward = m.forward_export # assign forward (optional)
if isinstance(m, models.common.ShuffleV2Block):#shufflenet block nn.SiLU
for i in range(len(m.branch1)):
if isinstance(m.branch1[i], nn.SiLU):
m.branch1[i] = SiLU()
for i in range(len(m.branch2)):
if isinstance(m.branch2[i], nn.SiLU):
m.branch2[i] = SiLU()
y = model(img) # dry run
# ONNX export
print('\nStarting ONNX export with onnx %s...' % onnx.__version__)
f = opt.weights.replace('.pt', '.onnx') # filename
model.fuse() # only for ONNX
input_names=['input']
output_names=['output']
torch.onnx.export(model, img, f, verbose=False, opset_version=12,
input_names=input_names,
output_names=output_names,
dynamic_axes = {'input': {0: 'batch'},
'output': {0: 'batch'}
} if opt.dynamic else None)
# Checks
onnx_model = onnx.load(f) # load onnx model
onnx.checker.check_model(onnx_model) # check onnx model
print('ONNX export success, saved as %s' % f)
# Finish
print('\nExport complete (%.2fs). Visualize with https://github.com/lutzroeder/netron.' % (time.time() - t))
# exit()
# onnx infer
if opt.onnx_infer:
import onnxruntime
import numpy as np
providers = ['CPUExecutionProvider']
session = onnxruntime.InferenceSession(f, providers=providers)
im = img.cpu().numpy().astype(np.float32) # torch to numpy
y_onnx = session.run([session.get_outputs()[0].name], {session.get_inputs()[0].name: im})[0]
print("pred's shape is ",y_onnx.shape)
print("max(|torch_pred - onnx_pred|) =",abs(y.cpu().numpy()-y_onnx).max())

4.7 OnnXruntime推理
代码如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2023/5/30 23:24
# @Author : 陈伟峰
# @Site :
# @File : onnxruntime_infer.py
# @Software: PyCharm
import time
import numpy as np
import argparse
import onnxruntime
import os, torch
import cv2, copy
from detect_face import scale_coords_landmarks, show_results
from utils.general import non_max_suppression_face, scale_coords
def allFilePath(rootPath, allFIleList): # 遍历文件
fileList = os.listdir(rootPath)
for temp in fileList:
if os.path.isfile(os.path.join(rootPath, temp)):
allFIleList.append(os.path.join(rootPath, temp))
else:
allFilePath(os.path.join(rootPath, temp), allFIleList)
def my_letter_box(img, size=(640, 640)): #
'''
将输入的图像img按照指定的大小size进行缩放和填充,
使其适应指定的大小。
具体来说,
它首先获取输入图像的高度h、宽度w和通道数c,然后计算出缩放比例r,并根据缩放比例计算出新的高度new_h和宽度new_w。
接着,它计算出在新图像中上、下、左、右需要填充的像素数,并使用cv2.resize函数将输入图像缩放到新的大小。最后,
它使用cv2.copyMakeBorder函数在新图像的上、下、左、右四个方向进行填充,
并返回填充后的图像img、缩放比例r、左侧填充像素数left和上方填充像素数top
Args:
img:
size:
Returns:
'''
h, w, c = img.shape
# cv2.imshow("res",img)
# cv2.waitKey(0)
r = min(size[0] / h, size[1] / w)
new_h, new_w = int(h * r), int(w * r)
top = int((size[0] - new_h) / 2)
left = int((size[1] - new_w) / 2)
bottom = size[0] - new_h - top
right = size[1] - new_w - left
img_resize = cv2.resize(img, (new_w, new_h))
# print(top,bottom,left,right)
# exit()
img = cv2.copyMakeBorder(img_resize, top, bottom, left, right, borderType=cv2.BORDER_CONSTANT,
value=(114, 114, 114))
# cv2.imshow("res",img)
# cv2.waitKey(0)
return img, r, left, top
def xywh2xyxy(boxes): # xywh坐标变为 左上 ,右下坐标 x1,y1 x2,y2
xywh = copy.deepcopy(boxes)
xywh[:, 0] = boxes[:, 0] - boxes[:, 2] / 2
xywh[:, 1] = boxes[:, 1] - boxes[:, 3] / 2
xywh[:, 2] = boxes[:, 0] + boxes[:, 2] / 2
xywh[:, 3] = boxes[:, 1] + boxes[:, 3] / 2
return xywh
def detect_pre_precessing(img, img_size): # 检测前处理
img, r, left, top = my_letter_box(img, img_size)
# cv2.imwrite("1.jpg",img)
img = img[:, :, ::-1].transpose(2, 0, 1).copy().astype(np.float32)
img = img / 255
img = img.reshape(1, *img.shape)
return img, r, left, top
def restore_box(boxes, r, left, top): # 返回原图上面的坐标
boxes[:, [0, 2, 5, 7, 9, 11]] -= left
boxes[:, [1, 3, 6, 8, 10, 12]] -= top
boxes[:, [0, 2, 5, 7, 9, 11]] /= r
boxes[:, [1, 3, 6, 8, 10, 12]] /= r
return boxes
def post_precessing(dets, r, left, top, conf_thresh=0.3, iou_thresh=0.5): # 检测后处理
"""
这段代码是一个用于检测后处理的函数。它的输入包括检测结果(dets)、
图像的缩放比例(r)、左上角坐标(left和top)、置
信度阈值(conf_thresh)和IoU阈值(iou_thresh)。
函数的主要功能是对检测结果进行筛选和处理,包括去除置信度低于阈值的检测框、将检测框的坐标从中心点和宽高格式转换为左上角和右下角格式、
计算每个检测框的得分并选取最高得分的类别作为输出、对输出进行非极大值抑制(NMS)处理、最后将输出的检测框坐标还原到原始图像中
Args:
dets:
r:
left:
top:
conf_thresh:
iou_thresh:
Returns:
"""
# 置信度
choice = dets[:, :, 4] > conf_thresh
dets = dets[choice]
dets[:, 13:15] *= dets[:, 4:5]
# 前四个值为框
box = dets[:, :4]
boxes = xywh2xyxy(box)
score = np.max(dets[:, 13:15], axis=-1, keepdims=True)
index = np.argmax(dets[:, 13:15], axis=-1).reshape(-1, 1)
output = np.concatenate((boxes, score, dets[:, 5:13], index), axis=1)
reserve_ = nms(output, iou_thresh)
output = output[reserve_]
output = restore_box(output, r, left, top)
return output
def nms(boxes, iou_thresh): # nms
index = np.argsort(boxes[:, 4])[::-1]
keep = []
while index.size > 0:
i = index[0]
keep.append(i)
x1 = np.maximum(boxes[i, 0], boxes[index[1:], 0])
y1 = np.maximum(boxes[i, 1], boxes[index[1:], 1])
x2 = np.minimum(boxes[i, 2], boxes[index[1:], 2])
y2 = np.minimum(boxes[i, 3], boxes[index[1:], 3])
w = np.maximum(0, x2 - x1)
h = np.maximum(0, y2 - y1)
inter_area = w * h
union_area = (boxes[i, 2] - boxes[i, 0]) * (boxes[i, 3] - boxes[i, 1]) + (
boxes[index[1:], 2] - boxes[index[1:], 0]) * (boxes[index[1:], 3] - boxes[index[1:], 1])
iou = inter_area / (union_area - inter_area)
idx = np.where(iou <= iou_thresh)[0]
index = index[idx + 1]
return keep
if __name__ == "__main__":
begin = time.time()
parser = argparse.ArgumentParser()
parser.add_argument('--detect_model', type=str, default=r'yolov5s-face.onnx', help='model.pt path(s)') # 检测模型
# parser.add_argument('--rec_model', type=str, default='weights/plate_rec.onnx', help='model.pt path(s)')#识别模型
parser.add_argument('--image_path', type=str, default='imgs', help='source')
parser.add_argument('--img_size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--output', type=str, default='result1', help='source')
parser.add_argument('--device', type=str, default='cpu', help='device ')
# parser.add_argument('--device', type=str, default='cpu', help='device ')
# parser.add_argument('--device', type=str, default='cpu', help='device ')
opt = parser.parse_args()
device = opt.device
file_list = []
allFilePath(opt.image_path, file_list)
providers = ['CPUExecutionProvider']
clors = [(255, 0, 0), (0, 255, 0), (0, 0, 255), (255, 255, 0), (0, 255, 255)]
img_size = (opt.img_size, opt.img_size)
sess_options = onnxruntime.SessionOptions()
# sess_options.optimized_model_filepath = os.path.join(output_dir, "optimized_model_{}.onnx".format(device_name))
session_detect = onnxruntime.InferenceSession(opt.detect_model, providers=providers)
# session_rec = onnxruntime.InferenceSession(opt.rec_model, providers=providers )
if not os.path.exists(opt.output):
os.mkdir(opt.output)
save_path = opt.output
count = 0
for pic_ in file_list:
count += 1
print(count, pic_, end=" ")
img = cv2.imread(pic_)
img0 = copy.deepcopy(img)
img, r, left, top = my_letter_box(img0, size=img_size)
img = img.transpose(2, 0, 1).copy()
img = torch.from_numpy(img).to(device)
img = img.float() # uint8 to fp16/32
img /= 255.0 # 0 - 255 to 0.0 - 1.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
im = img.cpu().numpy().astype(np.float32) # torch to numpy
pred = session_detect.run([session_detect.get_outputs()[0].name], {session_detect.get_inputs()[0].name: im})[0]
pred = non_max_suppression_face(torch.tensor(pred, dtype=torch.float), 0.3, 0.5)
for i, det in enumerate(pred): # detections per image
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], img0.shape).round()
# Print results
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum() # detections per class
det[:, 5:15] = scale_coords_landmarks(img.shape[2:], det[:, 5:15], img0.shape).round()
for j in range(det.size()[0]):
xyxy = det[j, :4].view(-1).tolist()
conf = det[j, 4].cpu().numpy()
landmarks = det[j, 5:15].view(-1).tolist()
class_num = det[j, 15].cpu().numpy()
img0 = show_results(img0, xyxy, conf, landmarks, class_num)
cv2.imshow('result', img0)
k = cv2.waitKey(0)
# print(len(pred[0]), 'face' if len(pred[0]) == 1 else 'faces')
# outputs = post_precessing(y_onnx,r,left,top) #检测后处理
# print(f"总共耗时{time.time() - begin} s")

- 相关部署链接 yolov5face-toolkit
- yolov5-face-landmarks-opencv-v2