IR2Vec: LLVM IR Based Scalable Program Embeddings [TACO 2020]
S. VENKATAKEERTHY, ROHIT AGGARWAL, Indian Institute of Technology Hyderabad
我们提出了IR2Vec,一种简洁且可扩展的编码框架,将程序表示为连续空间中的分布式嵌入。这种分布式嵌入是通过结合表示学习方法和流信息来获取输入程序的语法和语义来实现的。由于我们的框架是基于源代码的中间表示(Intermediate Representation, IR),因此所获得的嵌入是独立于语言和机器的。IR的实体被建模为关系,它们的表示被学习来形成种子嵌入词汇表。使用这个框架,我们提出了两种增量编码:符号编码(Symbolic encodings)和流感知编码(Flow-Aware encodings)。从种子嵌入词汇表中获得符号编码,通过使用流信息对符号编码进行扩充获得流感知编码。
我们展示了我们的方法在两个优化任务(异构设备映射和线程粗化)上的有效性。我们表示程序的方法使我们能够使用非顺序模型,从而使训练时间更快。即使使用简单的机器学习模型,IR2Vec生成的编码在这两个任务中都优于现有的方法。特别是,我们的结果改进或匹配了跨越两个平台的设备映射任务中的11/14基准测试套件的最新加速,以及跨越四个不同平台的线程粗化任务中的53/68基准测试。与其他方法相比,我们的嵌入具有更强的可伸缩性,不需要数据(non-data-hungry),并且具有更好的词汇表外(Out-Of-Vocabulary, OOV)特征。
一句话 - IR2Vec: 将程序的中间表示编码为分布式嵌入
导论
在快速发展的不同体系结构上运行这些程序对开发最佳性能的编译器(和优化)提出了挑战。因为大多数编译器优化都是NP-Complete或不可确定的[44,48],所以大多数现代编译器都使用精心编写的启发式方法来提取这些程序在各种体系结构上的优越性能。
现有工作通过使用机器学习算法而不是依赖次优启发式来改进优化决策已经做了几次尝试。其中一些工作包括预测展开因子[53]、内联决策[54]、确定线程粗化因子[41]、设备映射[26]、向量化[27,45]等。对于这样的优化应用程序,从程序中提取信息是至关重要的,这样它就可以用来为机器学习模型提供信息,以驱动优化决策。
有两种方法将程序表示为机器学习算法的输入——基于特征的表示和分布式表示。
基于特征的表示涉及使用领域专家[23,26,41]专门为特定下游应用程序设计的精心挑选的特征来表示程序。比如基本块的数量,分支的数量,循环的数量,甚至派生/高级特征,如算术强度。
另一方面,表示学习涉及使用机器学习模型来自动学习将输入表示为分布式向量[10]。这种习得的表示——程序的编码——通常称为程序嵌入。与基于特征的表示相反,这种分布式表示是一个实值向量,其维度不能明确标记。大多数现有的使用分布式学习方法表示程序的工作使用某种形式的自然语言处理进行建模,都利用了代码的统计特性,并坚持自然性假设[3]。这些工作主要使用Word2Vec方法,如skip-gram和CBOW,或编码器-解码器模型,如Seq2Seq,将程序编码为分布式向量。
当前的程序表示工作都是为了软件工程应用设计的, 包括算法分类[42,52]、代码搜索和推荐[14,19,34,38]、代码综合[50]、Bug检测[59]、代码摘要[31]和软件维护[1,2,6,25]。然而除了应用于软件工程之外,精心设计的嵌入可以对程序的语义特征进行编码,在做出优化决策方面也非常有用。
在这篇文章中,我们提出了IR2Vec,一种用于构建连续的分布式向量的聚合方法(agglomerative approach),以表示IR层次结构(指令、函数和程序)中不同(且不断增加的)级别的源代码。使用LLVM基础编译器来处理和分析源码, 输入的程序会被转换为LLVM-IR形式. IR的初始向量表示称为种子嵌入(seed embeddings),通过在表示学习框架中考虑其统计属性来学习。利用这些习得的种子嵌入,形成新程序的层次向量。为了表示指令向量,我们提出了两种编码:符号编码(Symbolic)和流感知编码(Flow-Aware)。符号编码直接从学习到的表示中生成。当增加流分析信息时,符号编码就变成了流感知的.
Contributions
(1) 提出了一种将LLVM-IR实例映射到实值分布式嵌入的独特方法,称为种子嵌入词汇表。
(2) 使用上面的种子嵌入词汇表,提出了一个简洁且可伸缩的编码框架来将程序表示为向量。
(3) 提出了两种嵌入式方法:符号嵌入式和流感知嵌入式,它们都是基于经典程序流分析理论的,并在两个编译器优化任务上对它们进行了评估:异构设备映射(Heterogeneous device mapping)和线程粗化(Thread coarsening, 一种编译器技术,它将多个线程的工作合并为一个线程)
(4) 所提编码方法具有高度可扩展性,并且比最先进的技术性能更好。我们实现了改进的训练时间(高达8000×reduction),而且该方法不需要数据,不会遇到Out-Of-Vocabulary (OOV)单词.
设计
Overview
首先给出方法的概述,然后描述指令和基本块(BB)的嵌入过程, 接着将通过组合各个BB向量来形成最终的代码向量来解释表示函数和模块的过程。
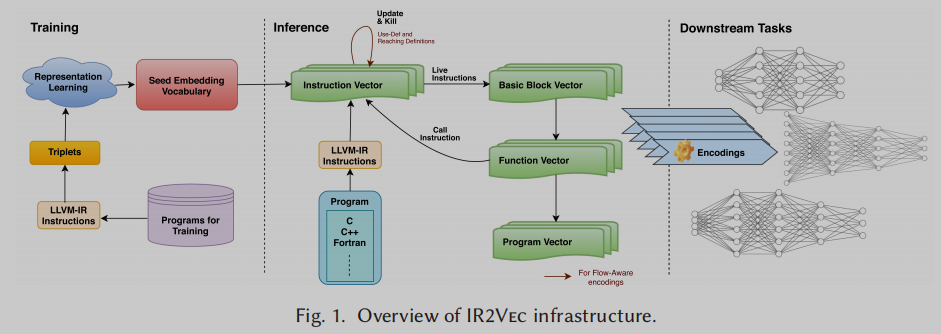
IR中的指令可以表示为实体-关系图,指令实体作为节点,实体之间的关系作为边。翻译学习模型被用来学习这些关系。这种学习的输出是一个包含实体嵌入的字典,称为种子嵌入词汇表(Seed embedding vocabulary)。
在输入程序的各个级别查找上述字典以形成嵌入。在最粗糙的层次上,指令嵌入仅通过使用Seed嵌入词汇表获得。我们称这种编码为符号编码。我们使用use - def和reach定义[29,44]信息来形成流感知编码的指令向量。活动指令向量被用来生成基本块向量, 一个函数的基本块向量用来构建函数向量, 结合调用图信息来传播函数向量则生成程序向量.
Seed Embeddings
通用元组. 操作码、操作类型(int、float等)和参数从LLVM IR中提取。对提取出来的IR按以下方式进行预处理:首先,用更通用的信息抽象出标识符信息如Table 1所示, 接着类型信息抽象为表示忽略其宽度的基类型, 例如,LLVM IR的类型 i32 表示为int。

代码三元组. 从这些预处理数据中,形成了三种主要的关系:(1)TypeOf:操作码与指令类型之间的关系,(2)NextInst:当前指令的操作码与下一个指令的操作码之间的关系; (3)
A
r
g
i
Arg_i
Argi:操作码与其操作数之间的关系。
从实际的IR到三元组
<
h
,
r
,
t
>
<h, r, t>
<h,r,t> 如 Figure 2(a) 所示. 比如store i32 %a, i32* %a.addr, align 4这条指令, 转换为三元组就是<store, "TypeOf", IntegerTy>, <store, "NextInst", store>, <store, "Arg_1", VAR>, <store, "Arg_2", PTR>, 分别表示这是一个存储整型数据的store指令, 这条指令的下一条指令是store类型, 第一个操作数是变量, 第二个操作数是指针.
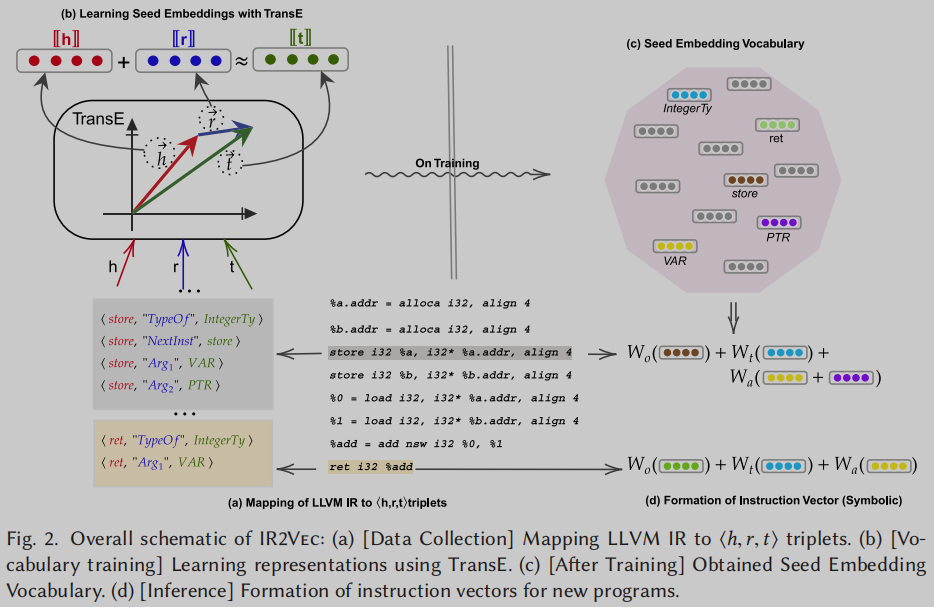
学习种子嵌入词汇表. 如Figure 2(b)所示, 生成的代码三元组作为TransE的输入进行学习, 生成Figure 2(c)所示的种子嵌入词汇表.
Instruction Vector
设指令
l
l
l 表示为
⟨
O
(
l
)
T
(
l
)
A
1
(
l
)
A
2
(
l
)
⋯
A
n
(
l
)
⟩
\left\langle O^{(l)} T^{(l)} A_1^{(l)} A_2^{(l)} \cdots A_n^{(l)}\right\rangle
⟨O(l)T(l)A1(l)A2(l)⋯An(l)⟩, 其中
O
O
O 为操作码,
T
T
T 为类型,
A
i
A_i
Ai为第
i
i
i个参数. 相对应的种子词典的向量表示为
⟦
O
(
l
)
⟧
,
⟦
T
(
l
)
⟧
,
⟦
A
i
(
l
)
⟧
.
\llbracket \mathbf{O}^{(l)} \rrbracket, \llbracket \mathbf{T}^{(l)} \rrbracket, \llbracket \mathbf{A}_{\mathbf{i}}^{(l)} \rrbracket .
[[O(l)]],[[T(l)]],[[Ai(l)]].
那么一条指令的向量表示可以由下式获取
W
o
⋅
⟦
O
(
l
)
⟧
+
W
t
⋅
⟦
T
(
l
)
⟧
+
W
a
⋅
(
⟦
A
1
(
l
)
⟧
+
⟦
A
2
(
l
)
⟧
+
⋯
+
⟦
A
n
(
l
)
⟧
)
W_o \cdot \llbracket \mathbf{O}^{(l)} \rrbracket+W_t \cdot \llbracket \mathrm{T}^{(l)} \rrbracket+W_a \cdot\left(\llbracket \mathrm{A}_1^{(l)} \rrbracket+\llbracket \mathrm{A}_2{ }^{(l)} \rrbracket+\cdots+\llbracket \mathrm{A}_{\mathbf{n}}{ }^{(l)} \rrbracket\right)
Wo⋅[[O(l)]]+Wt⋅[[T(l)]]+Wa⋅([[A1(l)]]+[[A2(l)]]+⋯+[[An(l)]])
其中
W
o
,
W
t
,
W
a
W_o, W_t, W_a
Wo,Wt,Wa是[0, 1]的标量, 加号(+)表示按元素排序的向量加法运算符, 点(.)表示标量乘法运算符。此外,
W
o
,
W
t
,
W
a
W_o, W_t, W_a
Wo,Wt,Wa的选择采用启发式,赋予操作码比类型更大的权重,赋予类型比参数更大的权重:
W
o
>
W
t
>
W
a
W_o > W_t > W_a
Wo>Wt>Wa
这个表示指令的合成向量就是符号编码中的指令向量。
Embedding Data Flow Information
LLVM IR中的指令可以定义一个变量或指针,这些变量或指针可以在程序的其他部分中使用。在LLVM IR中,变量(或指针)的使用集合产生了该特定变量(或指针)的use-def (UD)信息[29,44]。在命令式语言中,变量可以重新定义;也就是说,在程序的流程中,它有不同的生命周期。这样的重新定义据说会扼杀其早期的定义。在程序执行的流程中,只有活动定义的子集可以使用该变量。那些达到变量使用的定义称为达到定义。我们使用这样的流分析信息对指令向量建模,形成流感知编码。每个已经定义过的
A
j
A_j
Aj 都使用其到达定义的嵌入来表示。到达定义的指令向量,如果没有计算,将以需求驱动的方式计算。
Instruction Vector for Flow-Aware Encodings
如果
R
D
1
,
R
D
2
,
.
.
.
,
R
D
n
RD_1, RD_2, ..., RD_n
RD1,RD2,...,RDn是
A
j
(
l
)
A_j^{(l)}
Aj(l)的到达定义, 那么
⟦
A
j
(
l
)
⟧
\llbracket A_j^{(l)} \rrbracket
[[Aj(l)]]的向量表示由所有达到定义的嵌入进行累加计算
⟦
A
j
(
l
)
⟧
=
∑
i
=
1
n
⟦
R
D
i
⟧
\llbracket \mathrm{A}_{\mathbf{j}}{ }^{(l)} \rrbracket=\sum_{i=1}^n \llbracket \mathrm{RD}_{\mathbf{i}} \rrbracket
[[Aj(l)]]=i=1∑n[[RDi]]
对于定义不可用的情况(例如,函数参数),则使用学习过的种子嵌入词汇表中的“VAR”或“PTR”的通用实体表示。
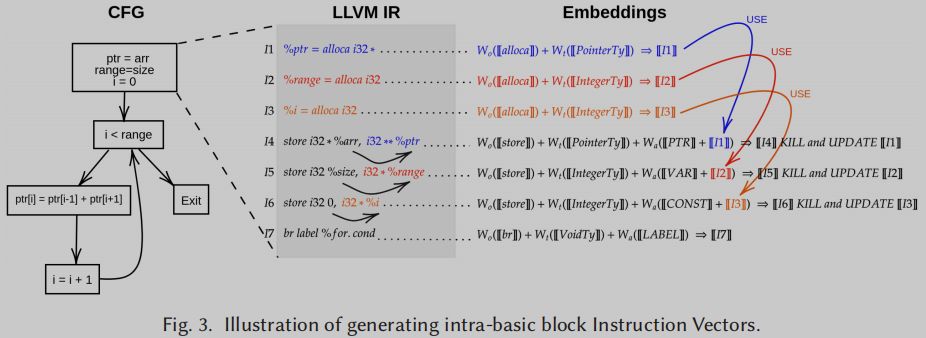
重新定义的变量之前的值会被kill掉, 而update指令都用达到定义(reaching definition)
Figure 3中演示了这个Kill和Update过程,以及使用达到定义来形成基本块内部(和跨)的指令向量.
I
1
,
I
2
,
I
3
I_1, I_2, I_3
I1,I2,I3在之后的store指令操作之后会被kill掉, update为新的变量
I
4
,
I
5
,
I
6
I_4, I_5, I_6
I4,I5,I6
对于多种可能的达到定义, 则考虑所有的达到定义, 累加计算指令嵌入, 比如下图中
j
j
j的达到定义有
I
2
,
I
3
,
I
9
I_2, I_3, I_9
I2,I3,I9, 则计算也是累加
I
2
,
I
3
,
I
9
I_2, I_3, I_9
I2,I3,I9的嵌入
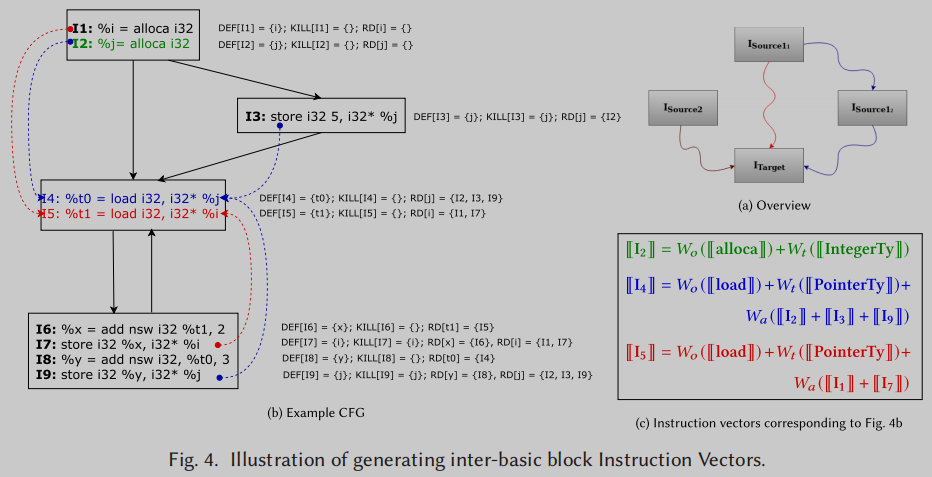
这样就生成了流感知的指令嵌入.
Resolving Circular Dependencies
在形成指令向量时,如果两个写指令写入相同的位置,且(重)定义彼此可达,则可能会产生两个写指令之间的循环依赖关系。
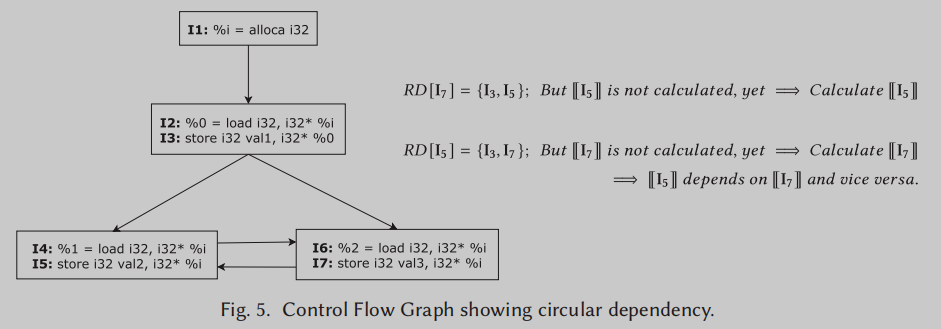
Figure 5的例子所示,
I
5
I_5
I5的计算依赖
I
7
I_7
I7,
I
7
I_7
I7的计算依赖
I
5
I_5
I5, 形成循环依赖. 这个问题可以通过将相应的嵌入方程作为一组联立方程交给求解器来解决。上图的循环依赖可以联立为以下方程组
⟦
I
4
⟧
=
W
o
(
⟦
load
⟧
)
+
W
t
(
⟦
IntegerTy
⟧
)
+
W
a
(
⟦
I
3
⟧
+
⟦
I
7
⟧
)
⟦
I
5
⟧
=
W
o
(
⟦
store
⟧
)
+
W
t
(
⟦
IntegerTy
⟧
)
+
W
a
(
⟦
VAR
⟧
)
+
W
a
(
⟦
I
3
⟧
+
⟦
I
7
⟧
)
⟦
I
7
⟧
=
W
o
(
⟦
store
⟧
)
+
W
t
(
⟦
IntegerTy
⟧
)
+
W
a
(
⟦
VAR
⟧
)
+
W
a
(
⟦
I
3
⟧
+
⟦
I
5
⟧
)
\begin{aligned} & \llbracket \mathbf{I}_4 \rrbracket=W_o(\llbracket \text { load } \rrbracket)+W_t(\llbracket \text { IntegerTy } \rrbracket)+W_a\left(\llbracket \mathbf{I}_3 \rrbracket+\llbracket \mathbf{I}_7 \rrbracket\right) \\ & \llbracket \mathbf{I}_5 \rrbracket=W_o(\llbracket \text { store } \rrbracket)+W_t(\llbracket \text { IntegerTy } \rrbracket)+W_a(\llbracket \operatorname{VAR} \rrbracket)+W_a\left(\llbracket \mathrm{I}_3 \rrbracket+\llbracket \mathbf{I}_7 \rrbracket\right) \\ & \llbracket \mathbf{I}_7 \rrbracket=W_o(\llbracket \text { store } \rrbracket)+W_t(\llbracket \text { IntegerTy } \rrbracket)+W_a(\llbracket \operatorname{VAR} \rrbracket)+W_a\left(\llbracket \mathrm{I}_3 \rrbracket+\llbracket \mathbf{I}_5 \rrbracket\right) \end{aligned}
[[I4]]=Wo([[ load ]])+Wt([[ IntegerTy ]])+Wa([[I3]]+[[I7]])[[I5]]=Wo([[ store ]])+Wt([[ IntegerTy ]])+Wa([[VAR]])+Wa([[I3]]+[[I7]])[[I7]]=Wo([[ store ]])+Wt([[ IntegerTy ]])+Wa([[VAR]])+Wa([[I3]]+[[I5]])
一个三元一次方程组, 嵌入可以通过该方程组求出. 当然作为一般情况讨论, 需要分三种情况来考虑嵌入方程组.
(1) 唯一解:在这种情况下,用直接的方式获得解。
(2) 无限多解:在这种情况下,任何一个得到的解都可以被认为是结果。
(3) 无解:在这种情况下,为了得到一个解,我们扰动Wa的值为Wa = Wa−δ,以便修正系统收敛到一个解,其中δ随机选择。
最后生成指令嵌入的算法如下

Construction of Code Vectors
在为基本块的每条指令计算指令向量之后,我们通过使用那些没有被杀死的指令的嵌入来计算累积的基本块向量。对于一个基本块
B
B
i
BB_i
BBi,其表示形式计算为在
B
B
i
BB_i
BBi中的活指令
L
I
1
、
L
I
2
、
…
,
L
I
m
LI_1、LI_2、…, LI_m
LI1、LI2、…,LIm的嵌入之和。
⟦
B
B
i
⟧
=
∑
k
=
1
m
⟦
L
I
k
⟧
\llbracket \mathbf{B B}_{\mathbf{i}} \rrbracket=\sum_{k=1}^m \llbracket \mathbf{L I}_{\mathbf{k}} \rrbracket
[[BBi]]=k=1∑m[[LIk]]
而函数的嵌入为其所有基本块嵌入之和
⟦
F
⟧
=
∑
i
=
1
b
⟦
B
B
i
⟧
\llbracket \mathbf{F} \rrbracket=\sum_{i=1}^b \llbracket \mathbf{BB}_{\mathbf{i}} \rrbracket
[[F]]=i=1∑b[[BBi]]

而表示程序
P
P
P的代码向量被计算为其所有函数的嵌入之和:
⟦
P
⟧
=
∑
i
=
1
f
⟦
F
i
⟧
\llbracket \mathbf{P} \rrbracket=\sum_{i=1}^f \llbracket \mathrm{F}_{\mathrm{i}} \rrbracket
[[P]]=i=1∑f[[Fi]]
实验
dataset
使用SPEC CPU 17[12]基准测试和Boost库[15]作为学习表示的数据集。并随机改变编译器优化级别(-O[0-3], -Os, -Oz),这些基准测试中的程序被转换为LLVM IR。然后根据之前提到的规则创建IR的三元组, 接着用一个开源的TransE来学习这些三元组的嵌入.
我们编写了一个LLVM分析通道,从IR中提取泛型元组,以便将它们映射成三元组。数据集中有大约134M个三元组,其中有约8K个三元组是唯一关系; 从中得到64个嵌入被学习的不同的实体。接着使用SGD优化器进行1500 epochs 的训练,获得300维的嵌入向量。这64个不同实体的学习嵌入形成种子嵌入。我们启发式地将
W
o
W_o
Wo,
W
t
W_t
Wt 和
W
a
W_a
Wa 分别设置为
1
,
0.5
,
0.2
1,0.5,0.2
1,0.5,0.2。使用另一个LLVM通道计算不同级别的向量。
Evaluation of Seed Embeddings
对种子嵌入进行分析,以验证实体之间的语义关系是否通过形成聚类有效捕获。这些簇表明IR2Vec能够捕获指令和参数的特征。与获得的种子嵌入相对应的实体根据它们执行的操作的性质被分类为组——包含整数和浮点类型算术操作的算术操作符、访问内存的指针操作符、执行逻辑操作的逻辑操作符、构成基本块最后一条指令的终止操作符、执行类型转换的Casting操作符、类型信息和参数。将300维数据可视化为二维,我们使用2-PCA,得到的簇如图6所示。
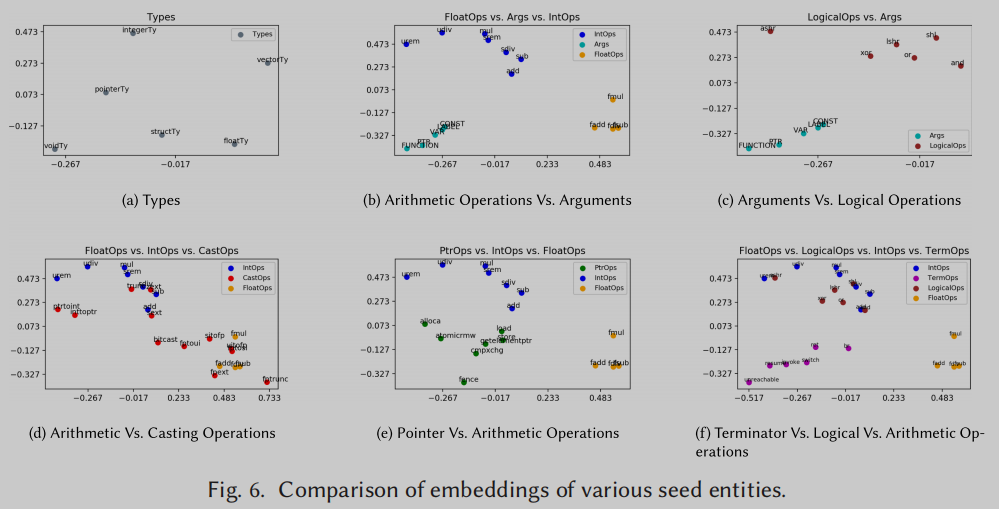
在图6(b)中,我们展示了所有基于整数的算术运算符都被分组在一起,并与基于浮点的运算符明显分离。可以说,运算符之间的类比被捕获了。例如,(add, fadd)之间的距离类似于(sub, fsub)之间的距离。从图6(b)、6(e)和6(f)还可以看出,算术操作符与参数、指针操作符和终止操作符明显分离。类似地,从图6©中,我们可以看到逻辑运算符也与参数明显分离。在图6(d)中,我们展示了算术运算符和强制转换运算符之间的关系。可以清楚地看到,基于整数的强制转换操作符(如trunc、zext、sext等)与整数操作符组合在一起,而基于浮点的强制转换操作符(如fptrunc、fpext、fptoui等)与浮点操作符组合在一起。观察图6(d)和图6(e),可以看到ptrtoint和inttotpr更接近整数操作符和指针操作符。图6(e)还演示了算术操作符明显不同于指针操作符。逻辑运算符作用于整数,因此它们与整数运算符组合在一起,如图6(f)所示。
总之,这些聚类表明,获得的种子嵌入确实是有意义的,因为它们捕获了LLVM实体的内在语法和语义关系。
Heterogeneous Device Mapping
Grewe等人[26]提出了异构设备映射任务,将OpenCL内核映射到异构系统中的最佳目标设备—CPU或GPU。在这个实验中,我们使用IR2Vec得到的嵌入映射OpenCL内核到它的最优目标。
将IR2Vec在两个平台(AMD Tahiti 7970和NVIDIA GTX 970)上获得的预测精度和加速比与Grewe等人的手工特征提取方法[26]以及DeepTune[21]和inst2vec[13]的最新方法进行了比较。
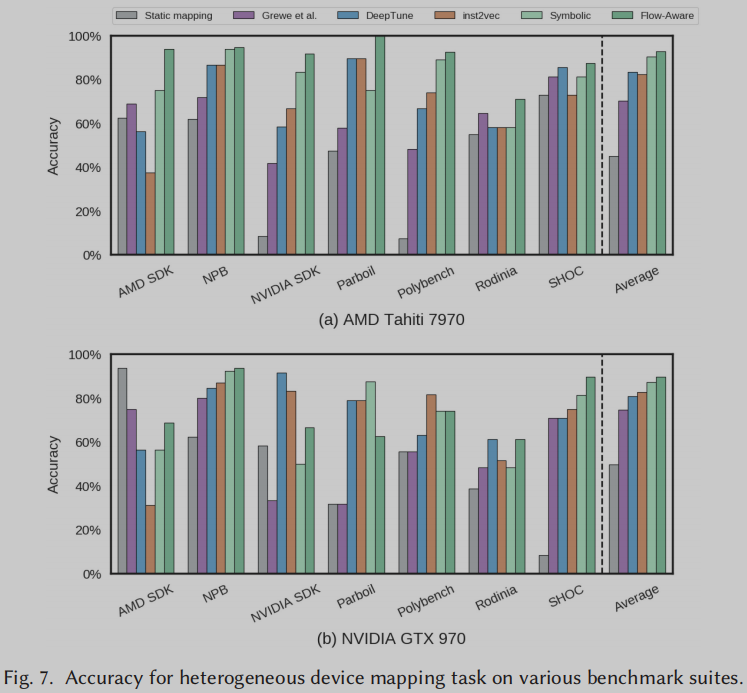
精度计算为模型对内核正确的设备映射预测占测试期间预测总数的百分比。在图7中,我们展示了使用IR2Vec和其他方法生成的编码进行映射的准确性。流感知和符号编码分别取得了91.26%和88.72%的平均准确率。
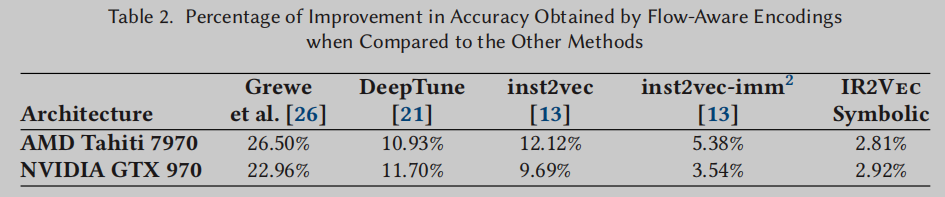
在表2中,我们展示了流感知编码比其他方法获得的准确率提高的百分比。可以观察到,流感知编码比其他方法获得了更高的性能[13,21,26]。在AMD Tahiti 7970上,我们的流感知编码在所有7个基准测试套件中实现了最高的精度。此外,我们的符号编码在4/7基准测试套件中获得了第二高的成绩。类似地,在NVIDIA GTX 970中,流感知编码在3/7的情况下实现了最高精度,而符号编码在4/7的情况下实现了最高或第二高的精度。
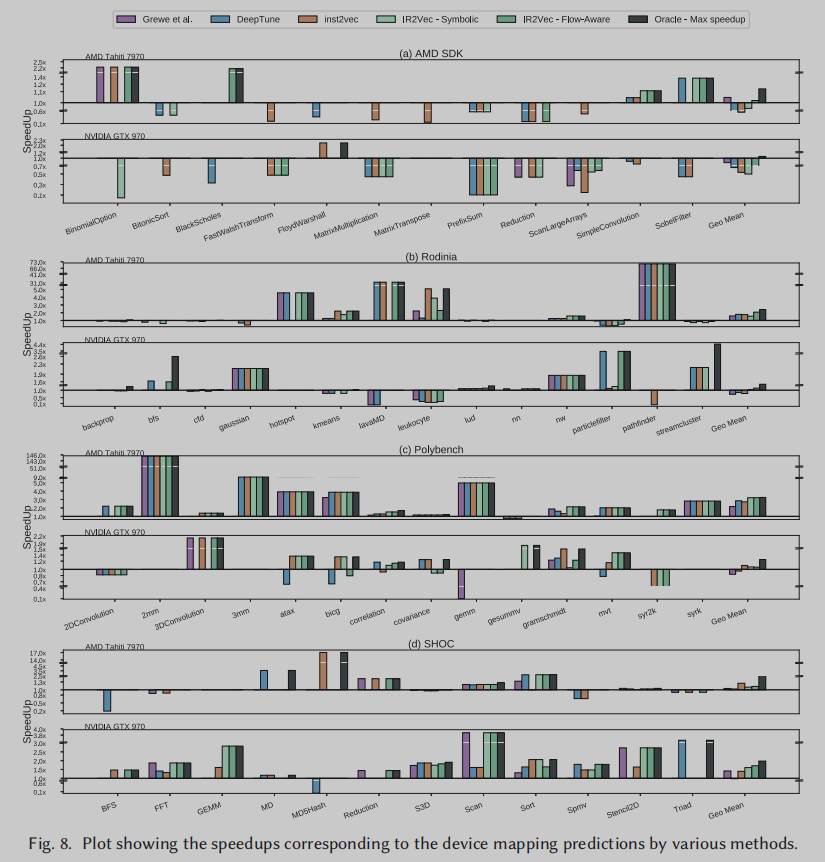
加速效果。在Figure 8中,我们展示了在考虑的两个平台上与静态映射作为基线相比所实现的加速。通过流感知编码,我们在AMD Tahiti和NVIDIA GTX上分别取得了约88.38%和77.65%的最大加速比,而在AMD Tahiti上的加速比为70.76%,在inst2vec的NVIDIA GTX上的加速比为70.66%,在AMD Tahiti的加速比为72.90%,在Deeptune的NVIDIA GTX上的加速比为66.79%。(使用符号编码,在AMD Tahiti和NVIDIA GTX上分别取得了80.11%和72.03%的最大加速比。)
Prediction of Optimal Thread Coarsening Factor
线程粗化[57]是通过融合两个或多个并发线程来增加单个线程所做的工作的过程。线程粗化因子对应于可以融合在一起的线程数量。选择一个最优的线程粗化因子可以显著提高GPU设备上的[40]速度,而简单的粗化会导致速度大幅下降。一个内核的线程粗化因子虽然在GPU上提供了最好的加速,但在另一个设备上(在供应商内部或跨供应商)使用相同的粗化因子时,由于该设备的体系结构特征[41,55],可能会产生最差的性能。
在这个实验中,我们遵循Magni等人[41]提出的实验设置来预测特定于GPU设备的给定内核的最佳线程粗化因子.
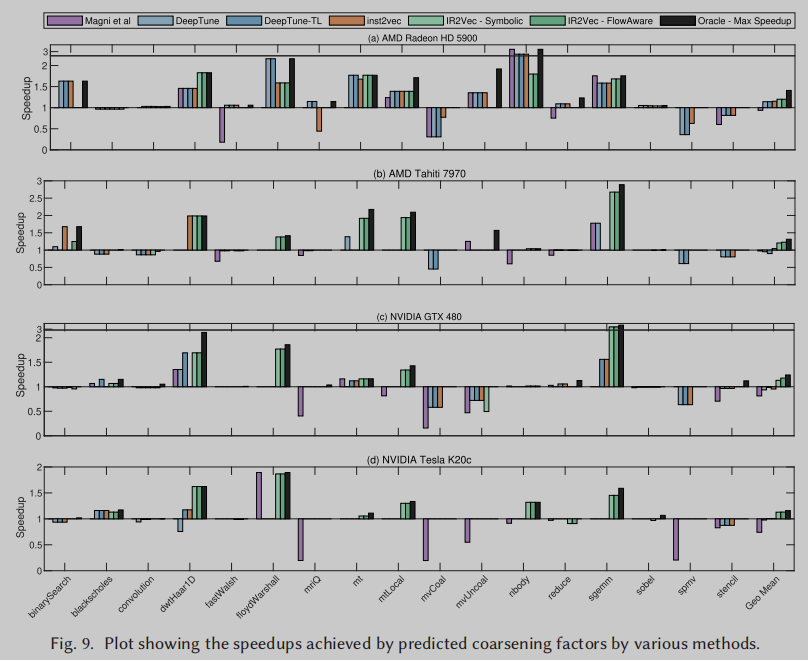
在Figure 9中,我们展示了我们的编码和早期工作在四个不同平台上实现的加速效果——AMD Radeon HD 5900, AMD Tahiti 7970, NVIDIA GTX 480和NVIDIA Tesla K20c。在AMD Radeon上,与inst2vec[13]和带有迁移学习(DeepTune- tl)[21]的DeepTune模型所实现的1.15×和1.14×的最先进的加速相比,我们的两种编码都实现了1.2×的加速。IR2Vec是第一个在NVIDIA GTX 480上实现正向加速的工作.

平均来看,在考虑的四种平台上,这两种编码都优于早期的线程粗化因子预测方法。
IR2Vec-PERSPECTIVES
Training Characteristics
设备映射任务. 在P100 GPU上,IR2Vec对设备映射任务的训练时间约为5秒,而DeepTune[21]和NCC[13]分别需要约10小时和12小时的训练时间。这导致训练时间减少约≈7200×-8640×,而性能没有下降。早期的工作需要大量的训练时间,因为它们涉及训练大量的参数:DeepTune[21]使用≈77K的参数,而NCC[13]使用≈69K的参数。相比之下,IR2Vec的预测使用梯度提升,它是少量浅层决策树的集合。之所以能够减少时间,主要是因为IR2Vec获得的嵌入使我们能够有效地使用梯度提升算法,而不是计算密集和需要数据的神经网络.
线程粗化任务. 与DeepTune- tl所需的训练时间≈11小时,以及DeepTune和NCC方法所需的训练时间≈1小时(以及使用的77K和69K参数)相比,所提出模型所需的训练时间≈10秒。这导致训练时间减少了≈360×-3960×,并再次实现了良好的加速。
Symbolic vs. Flow-Aware
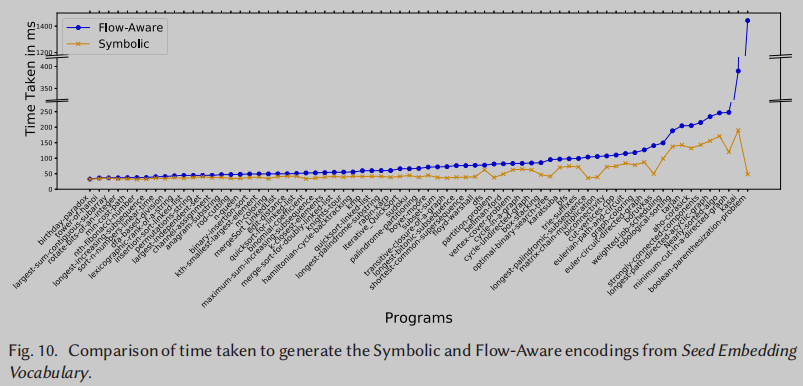
Figure 10显示了从样本集的种子嵌入词汇表生成符号编码和流感知编码所需时间的比较。可以观察到,平均而言,流感知编码需要比符号编码多1.86倍的时间。
Exposure to OOV Words
当在推理过程中遇到未见过的基础输入结构的组合时,它将不是词汇表的一部分,并导致词汇表外(OOV)数据点。在这种情况下,大多数模型都以类似的方式处理所有OOV单词,即模糊地指定一个公共表示,这可能会导致性能下降。因此,为了避免OOV点,重要的是在训练阶段暴露底层实体的各种(所有可能的)组合。例如,对于在IR语句级生成嵌入,应该在训练期间暴露所有可能形成语句的操作码、类型和参数的组合。
IR2Vec在IR的实体级别(Entity level)形成嵌入,因此它足以暴露只有O(|操作码| + |类型| + |操作数|)的训练空间,以避免OOV点。
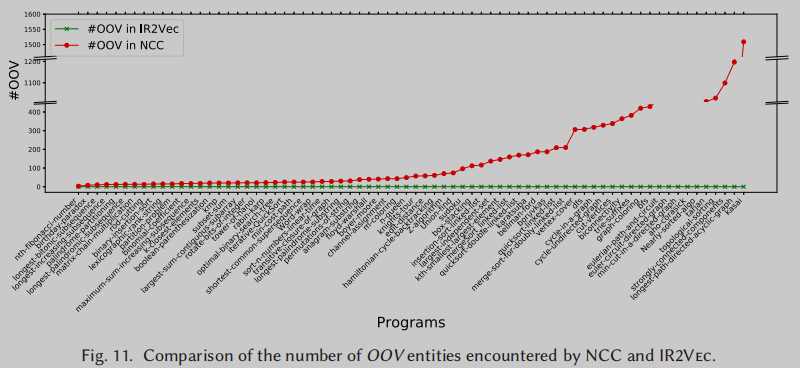
在使用的同一组程序时,NCC和IR2Vec遇到的OOV实体数量的比较如Figure 11所示。可以看出,我们的方法即使在训练数据较少的情况下也不会遇到任何oov,因此获得了良好的可伸缩性。
总结
Related Works
[1] Miltiadis Allamanis, Earl T. Barr, Christian Bird, and Charles Sutton. 2014. Learning natural coding conventions. In Proceedings of the 22nd ACM SIGSOFT International Symposium on Foundations of Software Engineering (FSE 2014). ACM, 281–293.
[2] Miltiadis Allamanis, Earl T. Barr, Christian Bird, and Charles Sutton. 2015. Suggesting accurate method and class names. In Proc. of the 2015 10th Joint Meeting on Foundations of Software Engineering (ESEC/FSE 2015). ACM, 38–49.
[3] Miltiadis Allamanis, Earl T. Barr, Premkumar Devanbu, and Charles Sutton. 2018. A survey of machine learning for big code and naturalness. ACM Computing Surveys (CSUR) 51, 4 (2018), 81.
[6] Miltiadis Allamanis, Hao Peng, and Charles A. Sutton. 2016. A convolutional attention network for extreme summarization of source code. In Proceedings of the 33nd International Conference on Machine Learning, (ICML 2016).
2091–2100. http://proceedings.mlr.press/v48/allamanis16.html.
[10] Yoshua Bengio, Aaron Courville, and Pascal Vincent. 2013. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 35, 8 (Aug. 2013), 1798–1828. DOI:https://doi.org/10.1109/TPAMI.2013.50
[12] James Bucek, Klaus-Dieter Lange, and Jóakim v. Kistowski. 2018. SPEC CPU2017: Next-generation compute benchmark. In Companion of the 2018 ACM/SPEC International Conference on Performance Engineering (ICPE’18). ACM, New York, 41–42. DOI:https://doi.org/10.1145/3185768.3185771
[13] Tal Ben-Nun, Alice Shoshana Jakobovits, and Torsten Hoefler. 2018. Neural code comprehension: A learnable representation of code semantics. In Proceedings of the 32nd International Conference on Neural Information Processing Systems (NIPS’18). Curran Associates Inc., 3589–3601. http://dl.acm.org/citation.cfm?id=3327144.3327276.
[14] Sushil Bajracharya, Joel Ossher, and Cristina Lopes. 2014. Sourcerer: An infrastructure for large-scale collection and analysis of open-source code. Sci. Comput. Program. 79 (Jan. 2014), 241–259. DOI:https://doi.org/10.1016/j.scico.2012.04.008
[15] Boost. 2018. Boost C++ Libraries. https://www.boost.org/. Accessed 2019-05-16.
[19] Jose Cambronero, Hongyu Li, Seohyun Kim, Koushik Sen, and Satish Chandra. 2019. When deep learning met code search. In Proceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE 2019). Association for Computing Machinery, New York, 964–974. DOI:https://doi.org/10.1145/3338906.3340458
[21] Chris Cummins, Pavlos Petoumenos, Zheng Wang, and Hugh Leather. 2017. End-to-end deep learning of optimization heuristics. In Proceedings of the 2017 26th International Conference on Parallel Architectures and Compilation Techniques (PACT). IEEE, 219–232.
[23] Grigori Fursin, Yuriy Kashnikov, Abdul Wahid Memon, Zbigniew Chamski, Olivier Temam, Mircea Namolaru, Elad Yom-Tov, Bilha Mendelson, Ayal Zaks, Eric Courtois, Francois Bodin, Phil Barnard, Elton Ashton, Edwin Bonilla, John Thomson, Christopher K. I. Williams, and Michael O’Boyle. 2011. Milepost GCC: Machine learning enabled self-tuning compiler. International Journal of Parallel Programming 39, 3 (01 Jun 2011), 296–327. DOI:https://doi.org/10.1007/s10766-010-0161-2
[25] Rahul Gupta, Soham Pal, Aditya Kanade, and Shirish Shevade. 2017. DeepFix: Fixing common C language errors by deep learning. In Proceedings of the 31st AAAI Conference on Artificial Intelligence (AAAI’17). AAAI Press, 1345–1351.http://dl.acm.org/citation.cfm?id=3298239.3298436
[26] Dominik Grewe, Zheng Wang, and Michael F. P. O’Boyle. 2013. Portable mapping of data parallel programs to
OpenCL for heterogeneous systems. In Proceedings of the 2013 IEEE/ACM International Symposium on Code Generation and Optimization, (CGO 2013), (Shenzhen, China, February 23-27), 2013. IEEE Computer Society, 22:1–22:10. DOI:https://doi.org/10.1109/CGO.2013.6494993
[27] Ameer Haj-Ali, Nesreen K. Ahmed, Ted Willke, Yakun Sophia Shao, Krste Asanovic, and Ion Stoica. 2020. NeuroVectorizer: End-to-end vectorization with deep reinforcement learning. In Proceedings of the 18th ACM/IEEE International Symposium on Code Generation and Optimization (CGO 2020). Association for Computing Machinery, New York, NY, USA, 242–255. DOI:https://doi.org/10.1145/3368826.3377928
[29] Matthew S. Hecht. 1977. Flow Analysis of Computer Programs. Elsevier Science Inc., New York, NY, USA.
[31] S. Iyer, I. Konstas, A. Cheung, and L. Zettlemoyer. 2016. Summarizing source code using a neural attention model. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2073–2083.
[34] V. Kashyap, D. B. Brown, B. Liblit, D. Melski, and T. Reps. 2017. Source forager: A search engine for similar source code. arXiv preprint arXiv:1706.02769 (2017).
[38] Sifei Luan, Di Yang, Celeste Barnaby, Koushik Sen, and Satish Chandra. 2019. Aroma: Code recommendation via structural code search. Proc. ACM Program. Lang. 3, (OOPSLA), Article 152 (Oct. 2019), 28 pages. DOI:https://doi.org/10.1145/3360578
[41] Alberto Magni, Christophe Dubach, and Michael O’Boyle. 2014. Automatic optimization of thread-coarsening for graphics processors. In Proceedings of the 23rd International Conference on Parallel Architectures and Compilation. ACM, 455–466.
[42] L. Mou, G. Li, L Zhang, T. Wang, and Z. Jin. 2016. Convolutional neural networks over tree structures for programming language processing. In Proceedings of the 13th AAAI Conference on Artificial Intelligence (AAAI’16). AAAI Press, 1287–1293.
[44] Steven S. Muchnick. 1997. Advanced Compiler Design and Implementation. Morgan Kaufmann Publishers Inc., San Francisco, CA.
[45] C. Mendis, C. Yang, Y. Pu, S. Amarasinghe, and M. Carbin. 2019. Compiler auto-vectorization with imitation learning. In Advances in Neural Information Processing Systems 32 (NeurIPS). Curran Associates, Inc., 14598–14609.
[48] H. G. Rice. 1953. Classes of recursively enumerable sets and their decision problems. Trans. Amer. Math. Soc. 74, 2 (1953), 358–366. http://www.jstor.org/stable/1990888.
[50] Maxim Rabinovich, Mitchell Stern, and Dan Klein. 2017. Abstract syntax networks for code generation and semantic parsing. arXiv preprint arXiv:1704.07535 (2017).
[52] N. Rosenblum, X. Zhu, and B. P. Miller. 2011. Who wrote this code? Identifying the authors of program binaries. In Proceedings of the 16th European Conference on Research in Computer Security (ESORICS’11). Springer-Verlag, Berlin, 172–189. http://dl.acm.org/citation.cfm?id=2041225.2041239
[53] M. Stephenson and S. Amarasinghe. 2005. Predicting unroll factors using supervised classification. In Proceedings of the International Symposium on Code Generation and Optimization. 123–134. DOI:https://doi.org/10.1109/CGO.2005.29
[54] Douglas Simon, John Cavazos, Christian Wimmer, and Sameer Kulkarni. 2013. Automatic construction of inlining heuristics using machine learning In Proceedings of the 2013 IEEE/ACM International Symposium on Code Generation and Optimization (CGO’13). IEEE Computer Society, 1–12. DOI:https://doi.org/10.1109/CGO.2013.6495004
[55] Nicolai Stawinoga and Tony Field. 2018. Predictable thread coarsening. ACM Trans. Arch. Code Optim. 15, 2, Article 23 (June 2018), 26 pages. DOI:https://doi.org/10.1145/3194242
[57] Vasily Volkov and James W. Demmel. 2008. Benchmarking GPUs to tune dense linear algebra. In Proceedings of the 2008 ACM/IEEE Conference on Supercomputing (SC’08). IEEE Press, Article 31, 11 pages.
[59] S. Wang, D. Chollak, D. Movshovitz-Attias, and L. Tan. 2016. Bugram: Bug detection with N-gram language models. In Proceedings of the 31st IEEE/ACM International Conference on Automated Software Engineering (ASE 2016). ACM, New York, 708–719. DOI:https://doi.org/10.1145/2970276.2970341
Insights
(1) 不同粒度之间的嵌入关系可以由累加实现, 指令嵌入累加可以表示基本块嵌入, 基本块嵌入累加则得到函数嵌入
(2) 利用LLVM IR可以适应不同编程语言和不同架构的处理器, 而且LLVM工具链本身提供很好的流信息支持, 比如数据流分析, 也可以自定义pass来提取需要的程序特征
(3) 评价嵌入的好坏, 可以使用PCA可视化, 观察相同类型的操作嵌入是否聚类到一起
(4) 使用非顺序模型提高训练效率
(5) IR2Vec可以通过寻找可疑的和模糊的模式来对程序是否恶意进行分类。它还可以用于检测带有漏洞的代码,识别代码的模式并将其替换为优化的等价库调用。