本文属于专栏《构建工业级QPS百万级服务》
性能优化,是工业应用中的重要一环。因为当我们的重要目的之一是盈利时,那么成本就十分重要。而性能优化的前提是,我们知道哪一部分功能,是最耗费资源的,才能用20%的精力去解决80%的问题。
在我使用过热点分析的工具中,最喜欢的是google profiler,因为它的信息足够详细。这里我们基于《c++11获取系统时间最快的方式》增加了3行代码,来测试这段逻辑的性能。增加代码分别是第8,51,58行
1 #include <iostream>
2 #include <chrono>
3 #include <ctime>
4 #include <sys/time.h>
5 #include <thread>
6 #include <vector>
7 #include <functional>
8 #include <gperftools/profiler.h>
9
10 using namespace std;
11 using namespace std::chrono;
12
13 const int TEST_TIMES = 1000 * 1000 * 10;
14
15 long long getCurrentTimeByClockGetTime() {
16 struct timespec spec;
17 clock_gettime(CLOCK_REALTIME, &spec);
18 return spec.tv_sec * 1000LL + spec.tv_nsec / 1000000;
19 }
20
21 long long getCurrentTimeByGetTimeOfDay() {
22 struct timeval tv;
23 gettimeofday(&tv, NULL);
24 return tv.tv_sec * 1000LL + tv.tv_usec / 1000;
25 }
26
27 long long getCurrentTimeByChrono() {
28 return duration_cast<milliseconds>(high_resolution_clock::now().time_since_epoch()).count();
29 }
30
31 void testFunction(const std::function<void()>& testFunc, const std::string& testName) {
32 long long start = getCurrentTimeByChrono();
33 for (int i = 0; i < TEST_TIMES; ++i) {
34 testFunc();
35 }
36 long long end = getCurrentTimeByChrono();
37 cout << "Using " << testName << " in thread " << this_thread::get_id() << ": " << end - start << " ms\n";
38 }
39
40 void testMultiThread(int thread_num, const std::function<void()>& testFunc, const std::string& testName) {
41 vector<thread> threads;
42 for (int i = 0; i < thread_num; ++i) {
43 threads.emplace_back(testFunction, testFunc, testName);
44 }
45 for (auto& t : threads) {
46 t.join();
47 }
48 }
49
50 int main() {
51 ProfilerStart("test.prof");
52 testMultiThread(1, getCurrentTimeByChrono, "chrono::high_resolution_clock");
53 testMultiThread(10, getCurrentTimeByChrono, "chrono::high_resolution_clock");
54 testMultiThread(1, getCurrentTimeByGetTimeOfDay, "gettimeofday");
55 testMultiThread(10, getCurrentTimeByGetTimeOfDay, "gettimeofday");
56 testMultiThread(1, getCurrentTimeByClockGetTime, "clock_gettime");
57 testMultiThread(10, getCurrentTimeByClockGetTime, "clock_gettime");
58 ProfilerStop();
59 }我们还需要执行一下命令,来安装google profiler。其中git仓库的目录和上面文件同级
- git clone https://github.com/gperftools/gperftools.git(下载开源库gperftools/gperftools)
- git checkout gperftools-2.5(切换到Tag 2.5)
- cd gperftools/ && bash -x autogen.sh && ./configure && make -j(编译google profiler)
- g++ test.cpp -std=c++11 -pthread -I gperftools/src/ gperftools/.libs/libprofiler.a(编译应用)
当前目录会生成文件test.prof,然后执行命令
- pprof --pdf a.out test.prof > test.pdf(pprof通过命令sudo yum install gperftools gperftools-devel安装)
此时目录结构如下
![]()
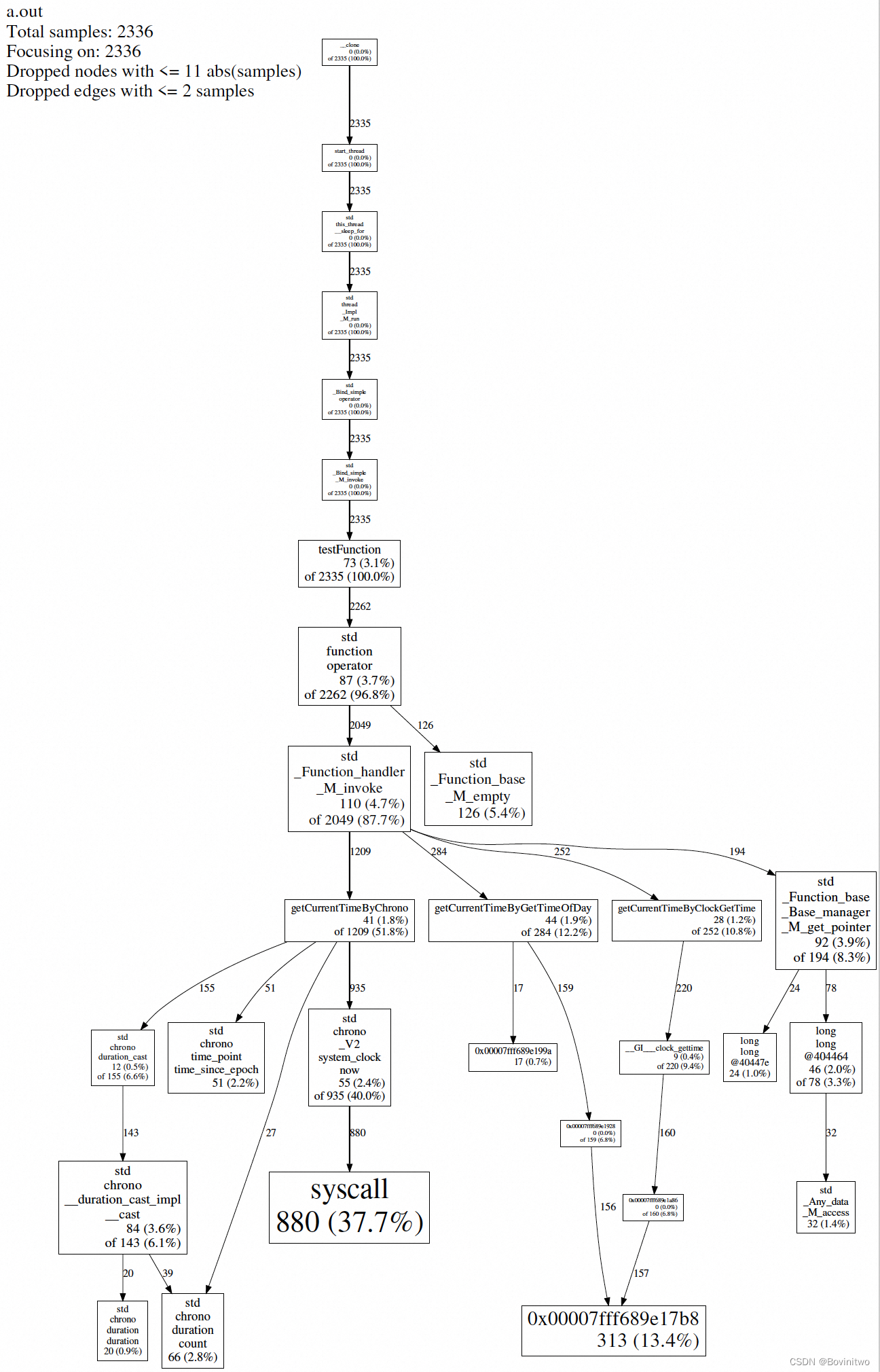
test.pdf打开如下图示例,可以看到每个函数的调用频率,以及顺序依赖关系。其统计原理就是等间隔时间采样,确认当前时间正在执行的函数栈,然后对每个函数栈统计运行次数。如下图中最大的方块syscall,是chrono调用的,这就是chrono慢的原因,因为它会在内核态和用户态之间切换。整个应用的执行过程37.7%的时间,都在执行该函数。