0、论文背景
本文在CCVIL的基础上,讨论了问题的分解效果对于CC框架的影响。由于VIL本身是一项计算成本昂贵的任务,因此应该避免在VIL上花费过多的时间而对CCEA没有显著的好处。我们进行实证研究来解决三个密切相关的问题: 1)更好的问题分解会导致更好的CCEAs性能?2)何时改进问题分解会有利于CCEAs?3)改进问题分解会在多大程度上提高CCEAs的性能。
Chen W, Tang K. Impact of problem decomposition on cooperative coevolution[C]//2013 IEEE Congress on Evolutionary Computation. IEEE, 2013: 733-740.
1、问题提出的动机
有关CCVIL,请参见博客:CCVIL。
1)检测更多可变的交互是否一定会导致ccea的更好的性能?这是第一个问题。需要找到这个问题的答案,为进一步探索更好的VIL方法奠定基础。
2)什么时候检测更多的可变交互作用可以有利于CCEA?
问题分解导致原始问题的过度简化,从而将CCEA陷入到局部最优;合并两组变量形成一个更大的组,使新的子问题更难解决,CCEA需要更长的时间才能收敛。因此,我们假设检测更多的内在变量交互作用并不总是能提高CCEA的性能,所以提出了第二个问题。
3)检测更多变量交互的好处到底是什么?提出该问题的原因是为检测更多可变的交互作用付出代价真的值得吗?
2、实验的设置
本文将所有变量之间的关系放到数组中,数组的元素只有0或1,0表示变量之间不存在关系,1表示变量之间存在交互作用。该数组大小为
,N表示变量个数。
接下来我们需要定义一个变量作为量化人为制造交互变量程度:。它表示在
中有多大比例的数组元素是根据CEC2010中分组的具体状况确定的,而其他比例的数组元素全部设置为0。
具体的实验流程如下:

3、实验的结果与分析
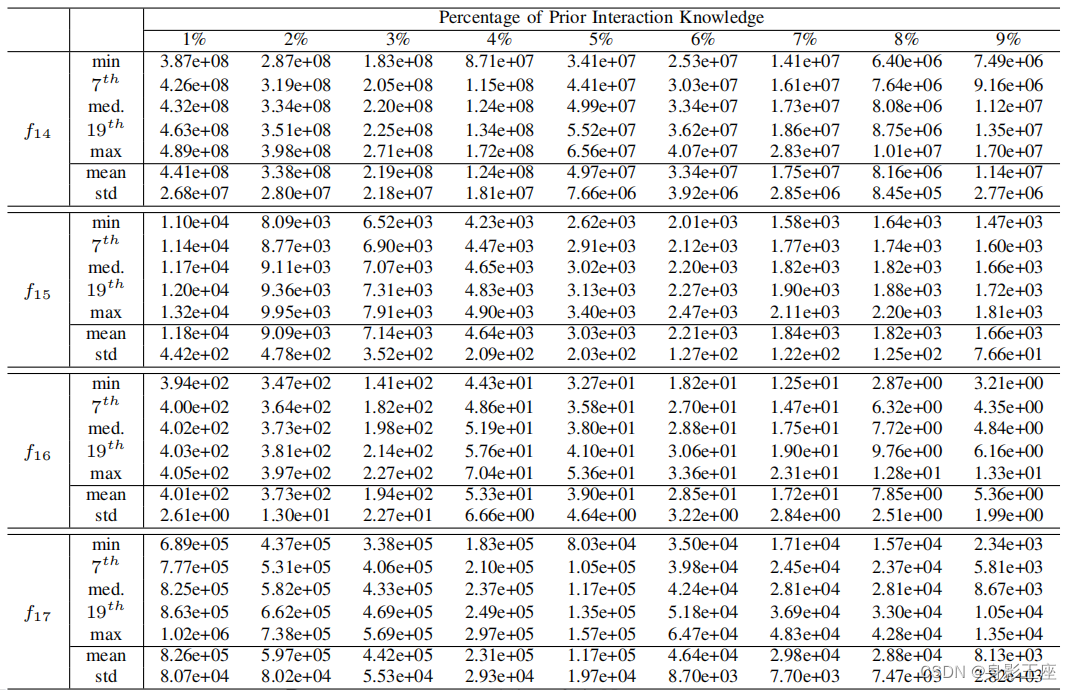
首先将设置为0%~100%。实验结果如下:
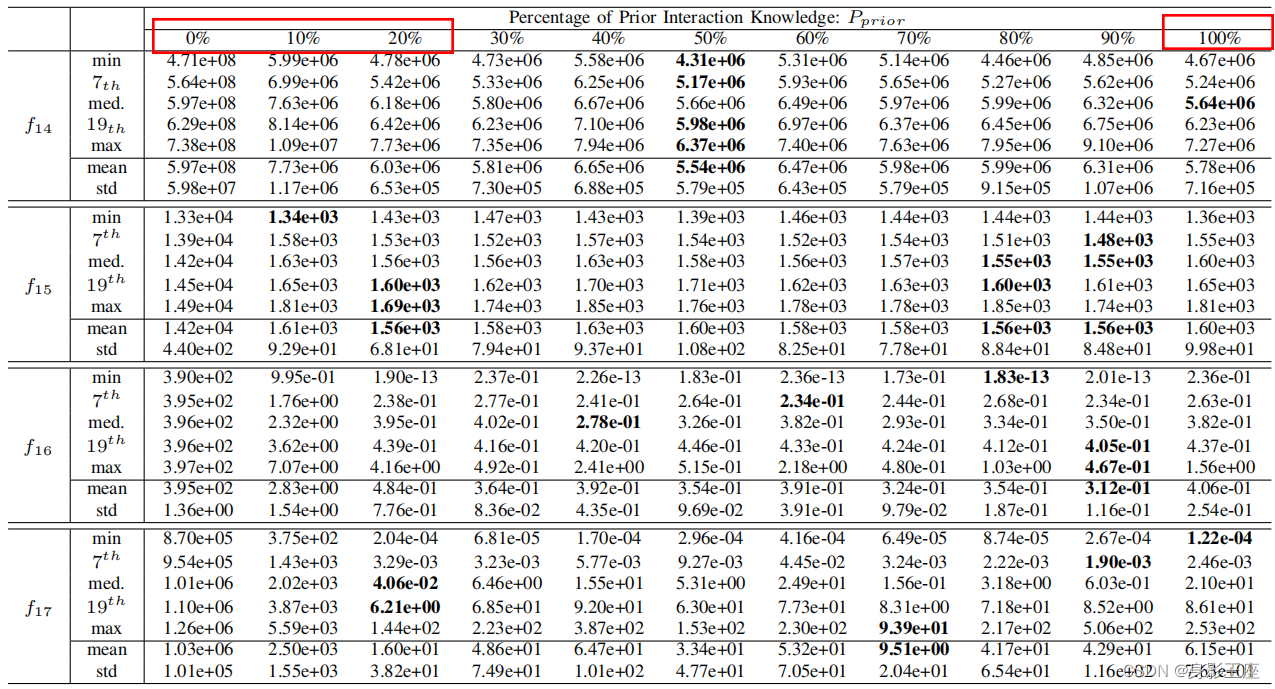
得出如下结论:
- 结合先验分组知识通常可以提高CCEA的性能。然而,提高
似乎主要在区间内有用[0%,10%]。
- 最优问题分解不一定会产生最佳解。因此,第一个问题的答案是:检测更多的可变相互作用可以帮助CCEA找到更好的解决方案,但这并不总是正确的。
- 关于更差的问题分解的假设有时可以得到质量更好的解,这也被验证。
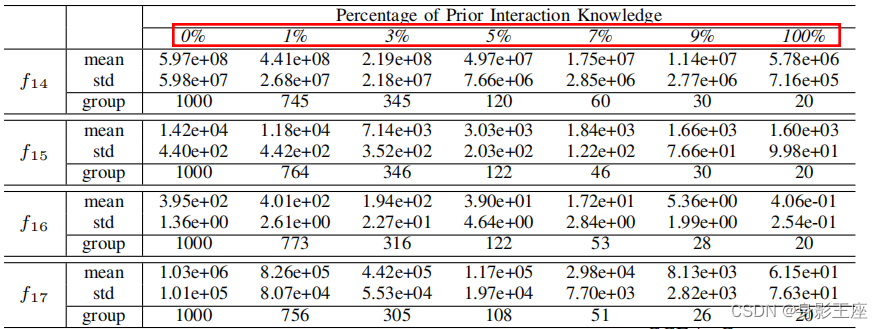
接着将设置为0%~10%。实验结果如下:
得出如下结论:
- 检测更多可变的相互作用几乎总是能增强CCEA。
- 只使用10%的先验知识,就可以提高适应度的几个数量级。至少在一定程度上,努力学习可变的互动确实是值得的。
得出如下结论:
给定为9%,相应的分解策略,产生约25个亚种群,已经非常接近最优的,应该有20个亚种群。这就是为什么
的进一步提高在提高CCEA的性能方面几乎没有取得什么进展的原因。
从实验数据中可以得出以下结论:
- 检测更多的可变相互作用通常有利于CCEAs,但也可能恶化CCEAs的性能。
- 当获得的关于内在变量交互作用的知识不足(少于总交互作用的10%)时,了解更多的内在变量交互作用确实会单调地提高ccea的性能。
- 通过仅检测10%的关于变量交互作用的知识,由CCEA得到的解的适应度可以提高几个数量级。
4、实验的实现与简单验证
function CG=CellG(A,ng)
% 函数输入为A为邻接矩阵,ng为所含最少智能体个数的连通分量,如ng为2则输出含智能体个数大于等于2的连通分量;
G=graph(A);
[bin,binsize] = conncomp(G);
b=find(binsize>=ng);
[~,m]=size(b);
CG=cell(m,1);
if m>0
for i=1:m
[~,com]=find(bin==b(i));
CG(i,1)={com};
end
end
end
clc; clearvars; close all;
addpath('CEC2010\')
addpath('CEC2010\datafiles\');
addpath('CEC2010\javarandom\bin\');
addpath('CEC2010\javarandom\src\');
truegroup = load('f14_opm.mat', 'p');
truegroup = truegroup.p;
global initial_flag
NS = 100; % 种群数
dim = 1000; % 种群维度
upperBound = [100, 5, 32, 100, 5, 32, 100, 100, 100, 5, 32, 100, 100, 100, 5, 32, 100, 100, 100, 100];
lowerBound = [-100, -5, -32, -100, -5, -32, -100, -100, -100, -5, -32, -100, -100, -100, -5, -32, -100, -100, -100, -100];
bestYhistory = []; % 保存每次迭代的最佳值
matrix = zeros(dim, dim); % 真实变量之间的关系矩阵
for i0 = 1 : 20
start = (i0 - 1) * 50 + 1;
Ends = i0 * 50;
for i2 = start : Ends
for i3 = (i2 + 1) : Ends
matrix(truegroup(i2), truegroup(i3)) = 1;
matrix(truegroup(i3), truegroup(i2)) = 1;
end
end
end
matrix1 = zeros(dim, dim); % 辅助查找行号列号矩阵
ss = 1;
for i5 = 1 : dim
for i6 = (i5 + 1) : dim
matrix1(i5, i6) = ss;
ss = ss + 1;
end
end
sumA = dim * (dim - 1) / 2;
Aintr = randperm(sumA);
pr = ceil(0.2 * sumA);
Prior = Aintr(1 : pr);
priormatrix = zeros(dim, dim); % 部分交互变量之间的关系矩阵
for i4 = 1 : pr
A = Prior(i4);
[row, col] = find(matrix1 == A);
priormatrix(row, col) = matrix(row, col);
priormatrix(col, row) = matrix(col, row);
end
groupInfor=CellG(priormatrix,1);
s = size(groupInfor, 1); % 子控件数目
for funcNum = 14
initial_flag = 0; % 换一个函数initial_flag重置为0
sampleX = lhsdesign(NS, dim) .* (upperBound(funcNum) - lowerBound(funcNum)) + lowerBound(funcNum) .* ones(NS, dim); % 生成NS个种群,并获得其评估值
lastSampleX = sampleX;
sampleY = benchmark_func(sampleX, funcNum);
[bestY, bestIndex] = min(sampleY); % 获取全局最小值以及对应的种群
lastBestY = bestY;
bestX = sampleX(bestIndex, :);
bestYhistory = [bestYhistory; bestY];
evalue = 60;
while evalue < 3 * 10 ^ 6
for i1 = 1 : s
group = groupInfor{i1};
dim = size(group,2);
NPi = dim + 10;
Geni = dim + 5;
index = randperm(NS);
subX = sampleX(index(1:NPi), group);
[subX, subY] = JADE(subX, sampleY(index(1:NPi)), bestX, group, Geni, dim, lowerBound(funcNum), upperBound(funcNum), @(x)benchmark_func(x, funcNum));
evalue = evalue + NPi * Geni;
sampleX(index(1:NPi), group) = subX;
sampleY(index(1:NPi)) = benchmark_func(sampleX(index(1:NPi), :), funcNum);
evalue = evalue + NPi;
[bestY, bestIndex] = min(sampleY); % 获取全局最小值以及对应的种群
bestX = sampleX(bestIndex, :);
end
bestYhistory = [bestYhistory; bestY];
fprintf('evalue:%d\n', evalue);
end
end
plot(bestYhistory);
save('20%bestYhistory.mat','bestYhistory');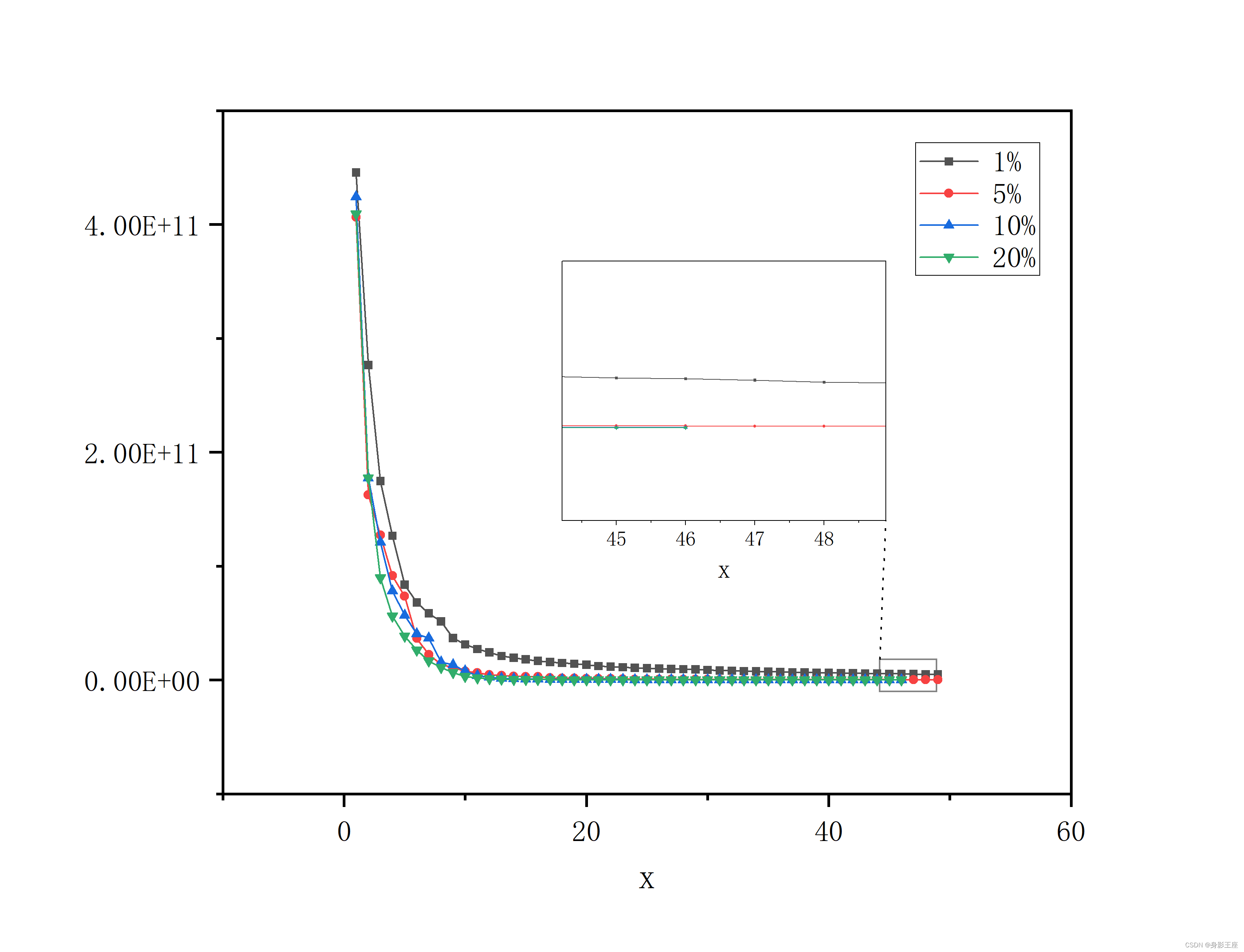
如有错误,还望批评指教!




![[附源码]Python计算机毕业设计Django学习帮扶网站设计与实现](https://img-blog.csdnimg.cn/edce3a23a54b47c4bc3eb0ec207a2e39.png)