🤵♂️ 个人主页:@Lingxw_w的个人主页
✍🏻作者简介:计算机研究生在读,研究方向复杂网络和数据挖掘,阿里云专家博主,华为云云享专家,CSDN专家博主、人工智能领域优质创作者,安徽省优秀毕业生
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
1、强化学习是什么
1.1 定义
1.2 基本组成
1.3 马尔可夫决策过程
2、强化学习的应用
3、常见的强化学习算法
3.1 Q-learning算法
3.2 Q-learning的算法步骤
3.3 Pytorch代码实现
1、强化学习是什么
1.1 定义
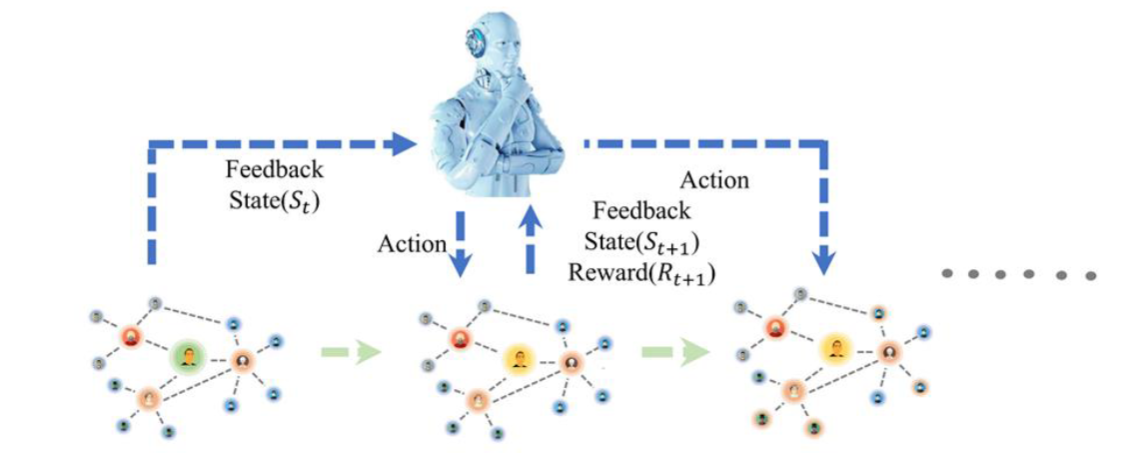
强化学习(Reinforcement Learning,RL)是一种机器学习方法,其目标是通过智能体(Agent)与环境的交互学习最优行为策略,以使得智能体能够在给定环境中获得最大的累积奖励。
强化学习在许多领域都有应用,例如机器人控制、游戏智能、自动驾驶、资源管理等。通过与环境的交互和试错学习,强化学习使得智能体能够在复杂、不确定的环境中做出优化的决策,并逐步提升性能。
1.2 基本组成
强化学习的基本组成部分包括:
智能体(Agent):在强化学习中,智能体是学习和决策的主体,它通过与环境的交互来获取知识和经验,并根据获得的奖励信号进行学习和优化。
环境(Environment):环境是智能体所处的外部世界,它可以是真实的物理环境,也可以是虚拟的模拟环境。智能体通过观察环境的状态,执行动作,并接收来自环境的奖励或惩罚信号。
状态(State):状态表示环境的某个特定时刻的观察或描述,它包含了智能体需要的所有信息来做出决策。
动作(Action):动作是智能体在某个状态下采取的行为,它会对环境产生影响并导致状态的转换。
奖励(Reward):奖励是环境根据智能体的行为给予的反馈信号,用于指导智能体学习合适的策略。奖励可以是正数(奖励)也可以是负数(惩罚),智能体的目标是最大化累积奖励。
1.3 马尔可夫决策过程
(Markov Decision Process,MDP)强化学习中常用的建模框架,用于描述具有马尔可夫性质的序贯决策问题。它是基于马尔可夫链(Markov Chain)和决策理论的组合。
在马尔可夫决策过程中,智能体与环境交互,通过采取一系列动作来影响环境的状态和获得奖励。MDP的关键特点是马尔可夫性质,即当前状态的信息足以决定未来状态的转移概率。这意味着在MDP中,未来的状态和奖励仅取决于当前状态和采取的动作,而与过去的状态和动作无关。
2、强化学习的应用
强化学习旨在解决以下类型的问题:
决策问题:强化学习可以用于解决需要做出一系列决策的问题。例如,自动驾驶车辆需要在不同交通情况下选择合适的行驶策略,智能机器人需要学习在复杂环境中执行任务的最佳策略。
控制问题:强化学习可用于控制系统的优化。例如,通过学习最优策略来调整电力网格的能源分配,或者在金融投资中确定最佳的投资组合。
资源管理:强化学习可以应用于资源管理问题,如动态网络管理、数据中心的负载平衡、无线通信中的频谱分配等。智能体可以通过与环境的交互来学习如何最优地利用和分配有限的资源。
序列决策问题:强化学习适用于需要在连续时间步骤中做出决策的问题。例如,在自然语言处理中,可以使用强化学习来训练智能体生成合适的文本回复,或者在推荐系统中根据用户行为动态调整推荐策略。
探索与开发:强化学习可以用于探索未知环境和发现新知识。通过与环境的交互,智能体可以通过试错学习来积累经验并发现最优策略。
3、常见的强化学习算法
- Q-learning:一种基于值函数(Q函数)的强化学习算法,通过迭代更新Q值来学习最优策略。
- SARSA:另一种基于值函数的强化学习算法,与Q-learning类似,但在更新Q值时采用了一种“状态-动作-奖励-下一状态-下一动作(State-Action-Reward-State-Action)”的更新策略。
- 策略梯度(Policy Gradient):一类直接学习策略函数的方法,通过优化策略函数的参数来提高智能体的性能。
- 深度强化学习(Deep Reinforcement Learning):将深度学习方法与强化学习相结合,利用神经网络来表示值函数或策略函数,以解决具有高维状态空间的复杂任务。
3.1 Q-learning算法
Q-learning是一种经典的强化学习算法,用于解决马尔可夫决策过程(Markov Decision Process,MDP)的问题。它是基于值函数的强化学习算法,通过迭代地更新Q值来学习最优策略。
在Q-learning中,智能体与环境的交互过程由状态、动作、奖励和下一个状态组成。智能体根据当前状态选择一个动作,与环境进行交互,接收到下一个状态和相应的奖励。Q-learning的目标是学习一个Q值函数,它估计在给定状态下采取特定动作所获得的长期累积奖励。
Q值函数表示为Q(s, a),其中s是状态,a是动作。初始时,Q值可以初始化为任意值。Q-learning使用贝尔曼方程(Bellman equation)来更新Q值,以逐步逼近最优的Q值函数:
Q(s, a) = Q(s, a) + α * (r + γ * max[Q(s', a')] - Q(s, a))
在上述方程中,α是学习率(learning rate),决定了每次更新的幅度;r是当前状态下执行动作a所获得的奖励;γ是折扣因子(discount factor),用于权衡即时奖励和未来奖励的重要性;s'是下一个状态,a'是在下一个状态下的最优动作。
3.2 Q-learning的算法步骤
- 初始化Q值函数。
- 在每个时间步骤中,根据当前状态选择一个动作。
- 执行动作,观察奖励和下一个状态。
- 根据贝尔曼方程更新Q值函数。
- 重复2-4步骤,直到达到预定的停止条件或收敛。
通过多次迭代更新Q值函数,Q-learning最终能够收敛到最优的Q值函数。智能体可以根据Q值函数选择具有最高Q值的动作作为策略,以实现最优的行为决策。
Q-learning是一种基于模型的强化学习方法,不需要对环境的模型进行显式建模,适用于离散状态空间和动作空间的问题。对于连续状态和动作空间的问题,可以通过函数逼近方法(如深度Q网络)来扩展Q-learning算法。
3.3 Pytorch代码实现
基于PyTorch的Q-learning算法来解决OpenAI Gym中的CartPole环境。
首先,导入所需的库,包括gym用于创建环境,random用于随机选择动作,以及torch和torch.nn用于构建和训练神经网络。
import gym
import random
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F定义了一个Q网络(QNetwork)作为强化学习算法的近似函数。该网络具有三个全连接层,其中前两个层使用ReLU激活函数,最后一层输出动作值。forward方法用于定义网络的前向传播。
# 定义Q网络
class QNetwork(nn.Module):
def __init__(self, state_dim, action_dim):
super(QNetwork, self).__init__()
self.fc1 = nn.Linear(state_dim, 64)
self.fc2 = nn.Linear(64, 64)
self.fc3 = nn.Linear(64, action_dim)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x接下来,定义了一个QLearningAgent类。在初始化中,指定了状态维度、动作维度、折扣因子和探索率等超参数。同时创建了两个Q网络:q_network和target_network。target_network用于计算目标Q值。还定义了优化器和损失函数。
# Q-learning算法
class QLearningAgent:
def __init__(self, state_dim, action_dim, gamma, epsilon):
self.state_dim = state_dim
self.action_dim = action_dim
self.gamma = gamma # 折扣因子
self.epsilon = epsilon # 探索率
# 初始化Q网络和目标网络
self.q_network = QNetwork(state_dim, action_dim)
self.target_network = QNetwork(state_dim, action_dim)
self.target_network.load_state_dict(self.q_network.state_dict())
self.target_network.eval()
self.optimizer = optim.Adam(self.q_network.parameters())
self.loss_fn = nn.MSELoss()
def update_target_network(self):
self.target_network.load_state_dict(self.q_network.state_dict())
def select_action(self, state):
if random.random() < self.epsilon:
return random.randint(0, self.action_dim - 1)
else:
state = torch.FloatTensor(state)
q_values = self.q_network(state)
return torch.argmax(q_values).item()
def train(self, replay_buffer, batch_size):
if len(replay_buffer) < batch_size:
return
# 从回放缓存中采样一个小批量样本
samples = random.sample(replay_buffer, batch_size)
states, actions, rewards, next_states, dones = zip(*samples)
states = torch.FloatTensor(states)
actions = torch.LongTensor(actions)
rewards = torch.FloatTensor(rewards)
next_states = torch.FloatTensor(next_states)
dones = torch.FloatTensor(dones)
# 计算当前状态的Q值
q_values = self.q_network(states)
q_values = q_values.gather(1, actions.unsqueeze(1)).squeeze(1)
# 计算下一个状态的Q值
next_q_values = self.target_network(next_states).max(1)[0]
expected_q_values = rewards + self.gamma * next_q_values * (1 - dones)
# 计算损失并更新Q网络
loss = self.loss_fn(q_values, expected_q_values.detach())
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
select_action方法用于根据当前状态选择动作。以epsilon的概率选择随机动作,以探索环境;以1-epsilon的概率选择基于当前Q值的最优动作。
# 创建环境
env = gym.make('CartPole-v1')
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.ntrain方法用于训练Q网络。它从回放缓存中采样一个小批量样本,并计算当前状态和下一个状态的Q值。然后计算损失并进行优化。
接下来,创建CartPole环境并获取状态和动作的维度。
然后,实例化一个QLearningAgent对象,并设置相关的超参数。
接下来,进行训练循环。在每个回合中,重置环境,然后在每个时间步中执行以下步骤:
- 根据当前状态选择一个动作。
- 执行动作,观察下一个状态、奖励和终止信号。
- 将状态、动作、奖励、下一个状态和终止信号存储在回放缓存中。
- 调用agent的
train方法进行网络训练。
每隔一定的回合数,通过update_target_network方法更新目标网络的权重。
# 创建Q-learning智能体
agent = QLearningAgent(state_dim, action_dim, gamma=0.99, epsilon=0.2)
# 训练
replay_buffer = []
episodes = 1000
batch_size = 32
for episode in range(episodes):
state = env.reset()
done = False
total_reward = 0
while not done:
action = agent.select_action(state)
next_state, reward, done, _ = env.step(action)
replay_buffer.append((state, action, reward, next_state, done))
state = next_state
total_reward += reward
agent.train(replay_buffer, batch_size)
if episode % 10 == 0:
agent.update_target_network()
print(f"Episode: {episode}, Total Reward: {total_reward}")
最后,使用训练好的智能体进行测试。在测试过程中,根据当前状态选择动作,并执行动作,直到终止信号出现。同时可通过env.render()方法显示环境的图形界面。
# 使用训练好的智能体进行测试
state = env.reset()
done = False
total_reward = 0
while not done:
env.render()
action = agent.select_action(state)
state, reward, done, _ = env.step(action)
total_reward += reward
print(f"Test Total Reward: {total_reward}")
env.close()代码执行完毕后,关闭环境并显示测试的总奖励。
总体而言,这段代码实现了基于PyTorch的Q-learning算法,并将其应用于CartPole环境。通过训练,智能体可以学习到一个最优策略,使得杆子保持平衡的时间尽可能长。
汇总的代码:
import gym
import random
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
# 定义Q网络
class QNetwork(nn.Module):
def __init__(self, state_dim, action_dim):
super(QNetwork, self).__init__()
self.fc1 = nn.Linear(state_dim, 64)
self.fc2 = nn.Linear(64, 64)
self.fc3 = nn.Linear(64, action_dim)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# Q-learning算法
class QLearningAgent:
def __init__(self, state_dim, action_dim, gamma, epsilon):
self.state_dim = state_dim
self.action_dim = action_dim
self.gamma = gamma # 折扣因子
self.epsilon = epsilon # 探索率
# 初始化Q网络和目标网络
self.q_network = QNetwork(state_dim, action_dim)
self.target_network = QNetwork(state_dim, action_dim)
self.target_network.load_state_dict(self.q_network.state_dict())
self.target_network.eval()
self.optimizer = optim.Adam(self.q_network.parameters())
self.loss_fn = nn.MSELoss()
def update_target_network(self):
self.target_network.load_state_dict(self.q_network.state_dict())
def select_action(self, state):
if random.random() < self.epsilon:
return random.randint(0, self.action_dim - 1)
else:
state = torch.FloatTensor(state)
q_values = self.q_network(state)
return torch.argmax(q_values).item()
def train(self, replay_buffer, batch_size):
if len(replay_buffer) < batch_size:
return
# 从回放缓存中采样一个小批量样本
samples = random.sample(replay_buffer, batch_size)
states, actions, rewards, next_states, dones = zip(*samples)
states = torch.FloatTensor(states)
actions = torch.LongTensor(actions)
rewards = torch.FloatTensor(rewards)
next_states = torch.FloatTensor(next_states)
dones = torch.FloatTensor(dones)
# 计算当前状态的Q值
q_values = self.q_network(states)
q_values = q_values.gather(1, actions.unsqueeze(1)).squeeze(1)
# 计算下一个状态的Q值
next_q_values = self.target_network(next_states).max(1)[0]
expected_q_values = rewards + self.gamma * next_q_values * (1 - dones)
# 计算损失并更新Q网络
loss = self.loss_fn(q_values, expected_q_values.detach())
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
# 创建环境
env = gym.make('CartPole-v1')
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
# 创建Q-learning智能体
agent = QLearningAgent(state_dim, action_dim, gamma=0.99, epsilon=0.2)
# 训练
replay_buffer = []
episodes = 1000
batch_size = 32
for episode in range(episodes):
state = env.reset()
done = False
total_reward = 0
while not done:
action = agent.select_action(state)
next_state, reward, done, _ = env.step(action)
replay_buffer.append((state, action, reward, next_state, done))
state = next_state
total_reward += reward
agent.train(replay_buffer, batch_size)
if episode % 10 == 0:
agent.update_target_network()
print(f"Episode: {episode}, Total Reward: {total_reward}")
# 使用训练好的智能体进行测试
state = env.reset()
done = False
total_reward = 0
while not done:
env.render()
action = agent.select_action(state)
state, reward, done, _ = env.step(action)
total_reward += reward
print(f"Test Total Reward: {total_reward}")
env.close()
相关博客专栏订阅链接
【机器学习】——房屋销售的探索性数据分析
【机器学习】——数据清理、数据变换、特征工程
【机器学习】——决策树、线性模型、随机梯度下降
【机器学习】——多层感知机、卷积神经网络、循环神经网络
【机器学习】——模型评估、过拟合和欠拟合、模型验证
【机器学习】——模型调参、超参数优化、网络架构搜索
【机器学习】——方差和偏差、Bagging、Boosting、Stacking
【机器学习】——模型调参、超参数优化、网络架构搜索