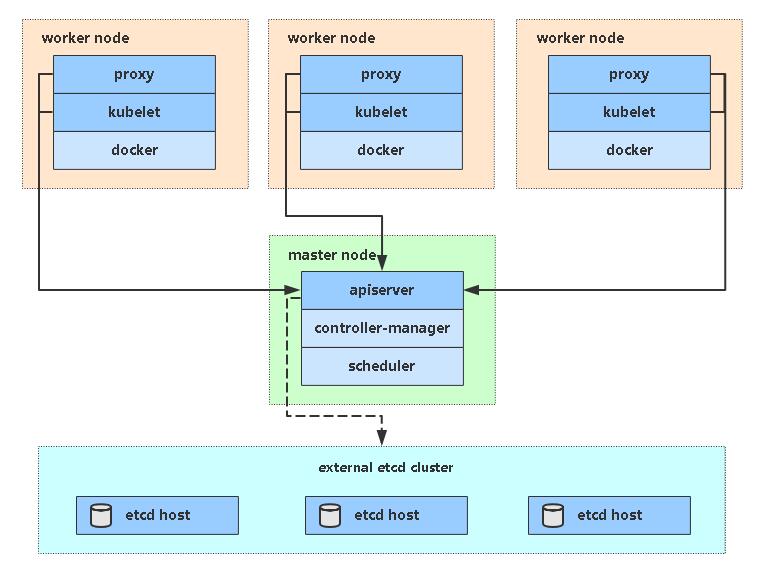
最近生成式AI风头有点大,这种技术只需要用文字就能作画,而且效果惊艳,堪比专业画师的作品。其中一些热门的方案包括DALL-E 2、Midjourney、BariumAI、D-ID AI、Stable Diffusion等等,这些工具简单、好玩,已经被无数网友所应用,创造出大量有意思、搞怪的艺术作品。

实际上,这种生成式AI不仅可以用来创作平面图像,也可以快速生成具有纹理的3D模型。目前,NVIDIA、谷歌已经在相关领域进行探索,比如利用文本、2D图像来生成3D模型。而Meta则采取不同的路径,训练AI将文本转化成视频,未来有望在VR中用语音生成3D场景或3D模型。这意味着,未来AR/VR场景也可以由AI生成,而这将大幅提升AR/VR生态的规模。
此前青亭网也曾报道过多款根据文字、语音生成3D场景和动画的方案,比如Anything World、Promethean AI等等。今年2月,Meta也曾预告一种根据语音描述来实时合成3D VR世界的方案:Builder Bot,你只需要对它说“沙滩”、“树”、“野餐布”等语音指令,就能将不同的场景元素召集到你周围。
Meta CEO马克·扎克伯格表示:Builder Bot将有望改变人们在VR中编程的方式,让计算变得更自然,未来有望用于Horizon屁股那太上,帮助用户快速创建场景和内容。
目前,Meta的Builder Bot还在测试阶段,与此同时,NVIDIA、谷歌等公司也陆续公布了一些用文本生成3D模型、3D场景的方案。
谷歌AIGC方案
去年12月,谷歌科研人员发布了一款基于NeRF 3D场景技术,以及OpenAI文本生成模型DALL·E、CLIP的3D生成系统:Dream Fields。该系统的点是无需照片样本就能生成3D图像,通过自然语言描述就可以合成全新的3D视角,重建3D立体图像,还可以生成多种物品组合成的复合结构。谷歌科研人员称,Dream Fields效果媲美3D数字背景,或是ArtStation平台的内容。

Dream Fields仅生成3D模型本身,而背景则采用随机合成图像。目前,Dream Fields可合成的物体包括船、花瓶、公共汽车、食物、家具等等。或是将牛油果和椅子合成,用大蒜扮演且,用皮卡丘做成牛油果椅子、茶壶等有趣的3D效果。
谷歌表示:随着3D渲染技术发展,越来越多的媒体内容开始采用3D形式。在游戏、VR应用、电影中,开发者们需要手动创作数千个3D模型,耗费大量时间和精力,成本相当高。
此前,开发者利用3D数据来合成点云、立体像素网格、三角形网格,以及基于GAN模型的隐函数。不过,由于有标记的3D形状数据有限,所以3D数据仅能合成少数的物体类型。相比之下,Dream 使用自然语言和简洁的创作界面即可合成3D图形,而且经过NeRF平滑插帧效果,3D图形具有足够高的空间分辨率,效果比立体像素、点云更好。
另外,Dream Fields通过预先训练的图像文本模型来生成3D图像,训练采用的数据来自于网络。

值得注意的是,谷歌还推出了类似的AI模型:DreamFusion,这个模型的特点是将AI图像分析模型Imagen与NeRF(神经辐射场)结合,也可以通过文本来合成带有网格的3D模型,兼容常见的3D渲染引擎、建模软件。
Imagen的优势在于使用2D文本图像即可训练,更容易规模化。DreamFusion会使用Imagen生成的多视角2D图像来学习3D渲染,实现用文本来合成3D模型。此外相比于Dream Fields,DreamFusion可合成更高质量、具有深度和法线的、可重新照明的3D模型,因此整体效果更逼真。而且,Dreamfision生成的多个3D模型可缝合到同一个场景中。
NVIDIA AIGC方案
近期,NVIDIA还推出了一个低门槛文本生成3D模型:Magic3D,号称适合任何人使用,无需建模经验、无需特殊培训。只需要40分钟左右,该模型就能生成一个带有色彩纹理的3D网格模型,经过调整后,可用于开发游戏或CGI艺术场景。

Magic3D 还可以执行基于提示的3D网格编辑。给定低分辨率3D模型和基本提示,可以更改文本以更改生成的模型。此外,Magic3D的作者展示了在几代人中保留同一主题(通常称为连贯性的概念)并将 2D 图像的样式(例如立体派绘画)应用于3D模型。
NVIDIA表示:通过Magic3D,我们希望让3D合成大众化,允许任何人开发3D内容。该公司CEO黄仁勋曾表示:尽管生成式AI才刚刚起步,但它将有望推动技术变革,其最大的应用场景之一,可能是元宇宙等3D虚拟平台,因为这些平台对于3D内容有大量需求,仅依赖人力开发并不够。
黄仁勋看好用AI生成虚拟场景的前景,其补充:生成式AI可帮助人们构建3D世界,未来其生成的内容还可以在不同的应用中重复使用。
对于3D虚拟生态来讲,生成式AI很关键,它可以帮助普通用户毫不费力的进行3D创作。现在,你可以用AI合成图像、视频,按照这个发展速度,未来也可以合成整个3D场景。而对于NVIDIA来讲,AI和Omniverse的研发是同时进行的,因为二者相辅相成,缺一不可。
AI生成WebAR
实际上,近期还有一个新的趋势,一些WebAR平台也在寻求用AI来生成AR内容的方式,比如Geenee AR、Niantic旗下的8th Wall等等。从技术上讲,WebAR平台可接入生成式AI模块,比如Geenee AR就推出了基于Stable Diffusion模型的AI WebAR内容创造套件RT3D AI SDK。该SDK与Geenee的WebAR全身追踪SDK结合,可用于丰富AR试穿体验,比如允许用户用语音来生成服装纹理,试穿各种图案设计。
而8th Wall则是使用Dall-E 2工具开发了多款WebAR应用,利用Dall-E 2,可自动生成动态的3D人脸模型,而利用8th Wall平台的Lightship VPS for Web定位功能,便可以将3D锚定到真实的空间中。当然,也可以使用8th Wall的WebAR SLAM功能World Effects来定位。

从8th Wall展示的AI生成WebAR内容来看,生成式AI和WebAR也可以很好的结合,AI合成的3D内容可通过WebAR平台加入实时反射、烘焙物理模拟、图像目标等功能,进一步优化AI合成AR内容的沉浸感。除了Dall-E 2外,8th Wall还使用BariumAI来生成3D模型的纹理。

除了WebAR外,生成式AI也可以用来开发VR场景,比如开发者Scottie Fox就曾尝试使用Stable Diffusion来生成VR场景。据悉,Fox将生成式AI与Touchdesigner编程语言、Intel MIDAS模型(可根据单个图像计算3D深度)结合,来合成环境的3D表示。不过,实时运行AI生成VR场景需要大量算力,据Fox称,demo场景是在NVIDIA 2080 Ti(11GB)上创建的。
实际上,Stability AI也在关注AI生成3D领域,比如与游戏工作室等公司合作,利用游戏的3D数据库来训练生成算法。该公司CEO Emad Mostaque表示:未来,生成AI模型的目标就是打造“全息甲板”,即大规模的VR虚拟空间。
总之,生成式AI不仅对WebAR有价值,未来如果和Horizon等UGC VR平台结合,将有望进一步简化内容创造的过程。


![[附源码]计算机毕业设计JAVA游戏账号交易平台](https://img-blog.csdnimg.cn/d02a035704774e2e90828338e2a92f01.png)








![[开发浏览器实战]关于Firefox火狐浏览器的说明一二(国内版 国际版区别 账号切换 插件-恢复关闭的标签页 插件-tempermonkey油猴)](https://img-blog.csdnimg.cn/5bc2170155fe4727aec041d9a9b7ab58.png)