目录
一、应用场景
二、卷积神经网络的结构
1. 输入层(Input Layer)
2. 卷积层(Convolutional Layer)
3. 池化层(Pooling Layer)
最大池化(max_pooling)或平均池化( mean_pooling):
4. 全连接层(Fully Connected Layer)
5. 输出层(Output Layer)
三、 Relu激活函数
四、 Softmax激活函数
定义和公式:
五、损失函数(softmax_loss)
1、定义:
2. 作用(Function)
(1)衡量预测与真实标签之间的差异
(2)优化网络参数
(3)适用于多分类任务
(4)防止数值不稳定
(5)损失函数与Softmax的结合
3. 示例说明
4. 总结
六、前向传播(forward propagation)
cnn例子图解:
1.输入层---->卷积层
2.卷积层---->池化层
3.池化层---->全连接层
4.全连接层---->输出层
七、反向传播
八、参考文献
一、应用场景
卷积神经网络的应用不可谓不广泛,主要有两大类,数据预测和图片处理。数据预测自然不需要多说,图片处理主要包含有图像分类,检测,识别,以及分割方面的应用。
图像分类:场景分类,目标分类
图像检测:显著性检测,物体检测,语义检测等等
图像识别:人脸识别,字符识别,车牌识别,行为识别,步态识别等等
图像分割:前景分割,语义分割

二、卷积神经网络的结构
卷积神经网络主要是由输入层、卷积层、激活函数、池化层、全连接层、损失函数组成,表面看比较复杂,其实质就是特征提取以及决策推断。
要使特征提取尽量准确,就需要将这些网络层结构进行组合,比如经典的卷积神经网络模型AlexNet:5个卷积层+3个池化层+3个连接层结构。
卷积的作用就是提取特征,因为一次卷积可能提取的特征比较粗糙,所以多次卷积,以及层层纵深卷积,层层提取特征。
1. 输入层(Input Layer)
·输入层是CNN的起点,负责接收输入数据。在图像处理中,输入通常是一张RGB或灰度图像,其尺寸为宽度×高度×通道数(即 height × width × channels)。对于颜色图像,通道数为3(分别代表红、绿、蓝),而灰度图像通道数为1。
定义:输入层的形状直接决定了网络处理的原始数据的大小和格式。
作用:传递原始输入数据到网络中,为后续层提供基础数据。
示例:比如,输入一张224×224×3的图像(224像素宽,224像素高,3个颜色通道),输入层会将这些数据传入网络,供后续的卷积层处理。
2. 卷积层(Convolutional Layer)
卷积层是CNN的核心部分,负责从输入数据中提取局部特征。通过应用一组可学习的滤镜(kernel或filter),卷积层能够检测输入图像中的边缘、纹理或其他显著特征。
定义:每一卷积层由多个滤镜组成,每个滤镜负责检测特定类型的特征。滤镜在输入图像上滑动,计算局部区域的点积,得到特征图(feature map)。
作用:
- 特征提取:通过滤镜滑动,检测输入图像中的特征,如边缘、纹理等。
- 权重共享:每个滤镜的参数在整个输入图像上共享,减少了参数数量,提升了计算效率。
- 空间感受野:每个特征图中的每个单元只关注输入图像的局部区域,增强了网络对局部结构的感知能力。
示例:假设输入图像为224×224×3,使用3×3×3的滤镜,步长为1,无填充。卷积计算后,输出特征图的尺寸为222×222×n(n为滤镜数量),每个特征图对应一种特定的特征。
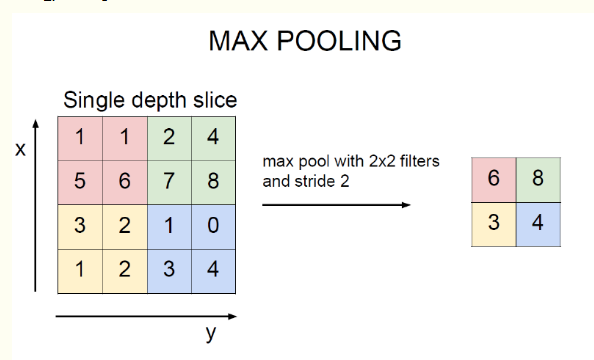
3. 池化层(Pooling Layer)
池化层的主要作用是降低特征图的尺寸,减少计算复杂度,同时提升网络的翻译不变性(即网络对输入图像的位置偏移的鲁棒性)。
定义:池化层通过在特征图上应用池化操作(如最大池化或平均池化),将局部区域的特征进行汇总,生成更小尺寸的特征图。
作用:
- 降维:通过池化操作减少特征图的空间尺寸,降低后续层的计算量。
- 防止过拟合:池化操作丢弃了部分特征,减少了网络的复杂度,有助于防止过拟合。
- 平移不变性:池化使得网络对目标位置的小范围偏移不那么敏感,增强了网络的稳健性。
示例:假设输入特征图为222×222×n,应用2×2的最大池化,步长为2。池化后的输出尺寸为111×111×n,特征图的尺寸减半,但保留了主要的特征信息。
最大池化(max_pooling)或平均池化( mean_pooling):
mean_pooling 就是输入矩阵池化区域求均值,这里要注意的是池化窗口在输入矩阵滑动的步长跟stride有关,一般stride = 2.
最右边7/4 => (1 + 1 + 2 + 3)/4

max_pooling 最大值池化,就是每个池化区域的最大值放在输出对应位置上。
4. 全连接层(Fully Connected Layer)
全连接层是传统的神经网络层,每个神经元都与前一层的所有神经元相连。在CNN中,全连接层通常用于将特征图展平(flatten)后,进行分类任务。
定义:全连接层接收展平的特征图作为输入,经过线性变换和激活函数,输出到下一个层或作为最终的预测输出。
作用:
- 特征整合:全连接层将来自不同区域和通道的特征进行综合,提供一个全局的特征向量。
- 分类任务:通过全连接层,网络可以进行多类别的分类,输出每个类别的概率分数。
示例:假设池化后的特征图为111×111×n,展平后为111×111×n = m个神经元。全连接层可能将m个输入映射到类别数为k的向量,每个元素表示对应类别的概率。
5. 输出层(Output Layer)
输出层是CNN的最后一层,负责产生最终的分类结果或输出其他需要的任务结果。
定义:输出层的结构和激活函数取决于具体任务。例如,在分类任务中,输出层通常使用Softmax激活函数(后面有介绍),输出一个类别概率分布;在回归任务中,可能直接输出原始值。
作用:
- 预测结果:将前面的全连接层的输出转化为最终的预测结果。
- 损失计算:输出层的输出与真实标签的对比,计算损失函数,指导网络的训练和参数优化。
示例:在分类任务中,输出层可能包含与类别数量相同的神经元,每个神经元对应一个类别的概率,如Softmax函数输出。
三、 Relu激活函数
1、 为什么要用激活函数?它的作用是什么?
由 y = w * x + b 可知,如果不用激活函数,每个网络层的输出都是一种线性输出,而我们所处的现实场景,其实更多的是各种非线性的分布。
这也说明了激活函数的作用是将线性分布转化为非线性分布,能更逼近我们的真实场景。
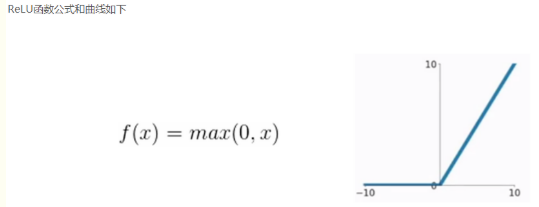
它的公式:f(x)=max(0,x)。也就是说,对于任何输入x,如果x大于0,输出就是x;如果x小于等于0,输出就是0。这样,ReLU函数可以将负数全部剪切为0,而正数保持不变。
那Relu函数在卷积神经网络中有什么作用呢?卷积神经网络主要用于处理图像数据,比如分类、检测等任务。在这些任务中,激活函数是用来引入非线性,使模型能够更好地拟合复杂的函数。
ReLU之前的激活函数,比如sigmoid或tanh,都有一个显著的问题:当输入很大的时候,梯度会变得非常小,导致训练速度变慢甚至停止。这被称为梯度消失问题。相比之下,ReLU函数在x>0时的梯度始终为1,这意味着在前向传播和后向传播过程中,梯度不会消失,这有助于加快训练速度。
此外,ReLU能够保留输入的正部分,而将负部分置为0。这种稀疏性有助于减少计算量,因为不需要处理所有的负值。这也是为什么ReLU在计算效率上优于其他激活函数。
不过,ReLU也有一些缺点。比如,当输入全是负数的时候,神经元会死亡,即输出总是0,无法更新权重。为了克服这个问题,出现了修正线性单元的变种,比如Leaky ReLU和ELU。
总的来说,ReLU在卷积神经网络中起到了引入非线性、加快训练速度、减少计算量的重要作用。它帮助神经网络更好地拟合复杂的函数,提升模型的准确性和效率。
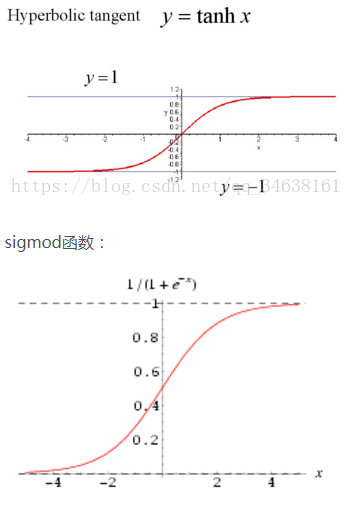
sigmoid或tanh的梯度消失问题原因:
由下图可知:他们在x大于某个值时,输出值y就变成了一个恒定值,因为求梯度时需要对函数求一阶偏导数,而不论是sigmoid,还是tanhx,他们的偏导都为0(看斜率),也就是存在所谓的梯度消失问题,最终也就会导致权重参数w , b 无法更新。相比之下,Relu就不存在这样的问题,另外在 x > 0 时,Relu求导 = 1,这对于反向传播计算dw,db,是能够大大的简化运算的。
使用sigmoid还会存在梯度爆炸的问题,比如在进行前向传播和反向传播迭代次数非常多的情况下,sigmoid因为是指数函数,其结果中某些值会在迭代中累积,并成指数级增长,最终会出现NaN而导致溢出。
四、 Softmax激活函数
Softmax函数是一种常见的激活函数,主要用于分类任务中将模型的输出转化为概率分布。它的图像展示了输入向量如何被转换为概率向量。
定义和公式:

Softmax函数将一个向量转换为概率分布,使得每个元素的值在0到1之间,并且所有元素的和为1。这在分类任务中非常有用,因为它可以将模型的输出转化为类别概率。
首先,让我画一个简单的图例。假设我们有一个输入向量,比如 SVM 训练得到的两个得分分别为 2 和 5。应用Softmax函数,这两个得分会被转换为两个概率值,分别是 e²/(e² + e⁵) ≈ 0.065 和 e⁵/(e² + e⁵) ≈ 0.935。这两个值加起来正好是1,表示第二个类别(得分5)的概率远大于第一个类别。
接下来,我想分析一下Softmax函数的性质。Softmax函数的一个重要特点是对输入的相对值感兴趣。即使输入的绝对值很大,只要相对比例不变,输出的概率分布也不变。例如,如果两个得分都是乘以一个相同的常数,比如2和10,Softmax的结果仍然保持相同的概率分布。这是因为在这个过程中,e²和e¹⁰的计算已经考虑了相对大小。
-
作用:
- 将输入的每个元素指数化,确保所有输出值为正数。
- 对指数化后的值求和,使得所有输出值之和为1,符合概率分布的特性。
-
图像解释:
- 输入空间:假设输入是一个二维向量(z₁, z₂),在复平面上表现为二维空间。
- 输出空间:Softmax函数将二维输入映射到二维概率输出(p₁, p₂),满足 𝑝1+𝑝2=1
- 图像表现:
- 在输入空间中,随着z₁和z₂的变化,p₁和p₂的值也会变化,在图上形成一个曲面。
- 当z₁远大于z₂时,p₁趋近于1,p₂趋近于0。
- 当z₂远大于z₁时,p₂趋近于1,p₁趋近于0。
- 当z₁等于z₂时,p₁ = p₂ = 0.5。
-
直观理解:
- 最大值凸显:Softmax函数会放大较大的输入值,压缩较小的输入值,使得最大的输入对应最高的概率。
- 平滑过渡:即使输入之间差距不大,输出的概率也会有平滑的变化,避免结果过于剧烈改变。
-
实际应用:
- 分类问题:Softmax函数常用于神经网络的输出层,将模型对各类别的原始输出转化为概率分布,便于进行分类决策。
- 多类别任务:适用于多于两个类别的分类问题,能够清晰地表示每个类别的概率。
通过以上分析,Softmax函数的图像展示了它在转换输入到概率输出中的核心作用,特别是在分类任务中的灵活性和有效性。
五、损失函数(softmax_loss)
1、定义:
在卷积神经网络(CNN)中,softmax 损失函数(也称为交叉熵损失函数)是用来衡量模型预测结果与真实标签之间的差异的损失函数。它在分类任务中被广泛使用,尤其是当输出需要解释为概率分布时。以下是其定义和作用的详细解释:


2. 作用(Function)
(1)衡量预测与真实标签之间的差异
损失函数的作用是量化模型预测结果与真实标签之间的差距。通过最小化损失函数,模型能够调整参数(权重和偏置),从而更好地拟合数据。
(2)优化网络参数
在训练过程中,优化器(如Adam、SGD等)通过计算损失函数对参数的梯度(导数),使用反向传播算法更新参数,以使损失最小化。
(3)适用于多分类任务
Softmax损失函数常用于多分类任务(类别数 K>2)。它的输出是每个类别的概率,便于解释和比较。
(4)防止数值不稳定
在计算过程中,使用log(𝑎𝑖𝑗)log(aij) 并结合交叉熵损失可以避免数值不稳定问题,例如当𝑎𝑖𝑗aij趋近于0时,log(𝑎𝑖𝑗)log(aij) 的值不会变得过于极端。
(5)损失函数与Softmax的结合
Softmax函数将输出值转换为概率分布,而损失函数则将这些概率与真实标签进行比较,计算损失。两者的结合使得模型能够在训练过程中逐步调整参数,以提高预测的准确性。
3. 示例说明

4. 总结
- 定义:Softmax损失函数是结合了Softmax激活函数和交叉熵损失的函数,用于衡量模型预测结果与真实标签之间的差异。
- 作用:
- 作为优化目标,引导模型调整参数以最小化损失。
- 适用于多分类任务,输出概率分布便于解释和比较。
通过理解Softmax损失函数的定义和作用,可以更好地理解卷积神经网络在分类任务中的工作原理及其优化过程。
详细可以看下面:
Softmax函数详解与推导 - 理想几岁 - 博客园。
常见损失函数解析-CSDN博客
六、前向传播(forward propagation)
前向传播是 Feedforward 的过程,即从输入层开始,经过一系列的卷积层、池化层、全连接层,最后到达输出层,得到预测结果。理解前向传播有助于理解整个网络的工作流程及其设计原理。
首先,输入层接收原始图像数据。假设输入图像是一个 维的矩阵,通常表示为高度(height)、宽度(width)、通道数(channels)。对于灰度图像,通道数为1;对于彩色图像,通道数为3(对应RGB三通道)。
随后,卷积层开始处理输入数据。每个卷积层包含多个滤镜(也称为卷积核)。滤镜的尺寸通常远小于输入图像的尺寸(例如3x3或5x5),且滤镜的数目可以是多个。滤镜在输入图像上滑动,计算每个位置的点积,生成特征图(feature map)。特征图表示输入在某个特定特征上的响应,例如边缘或纹理。
卷积过程的一个关键点是权重共享,即每个滤镜在图像的每个位置上使用相同的权重,这减少了模型的参数数量,提高了计算效率。
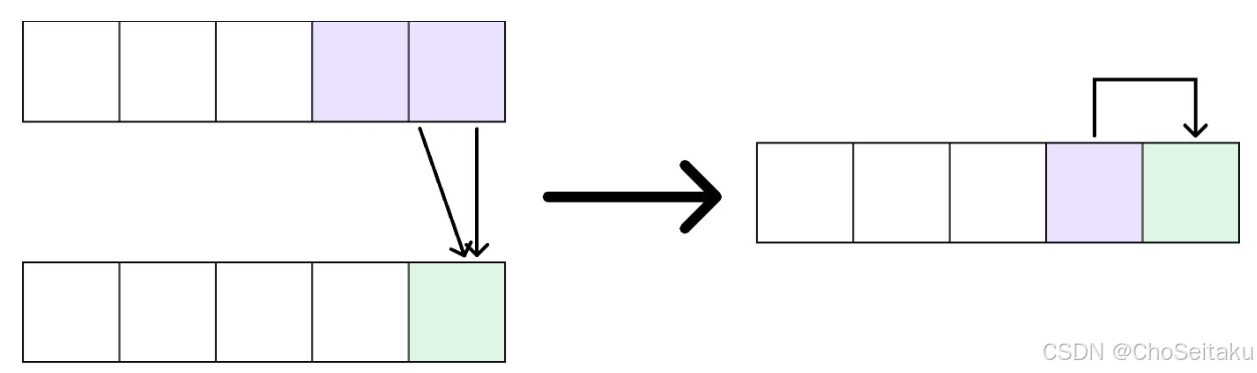
接下来是池化层,常用的有最大池化(max pooling)和平均池化(average pooling)。池化层通过下采样减少输入的数据量,降低计算复杂度,并提高模型的平移不变性(scale invariance)。例如,一个2x2的池化操作会将每个2x2的区域简化为一个值(最大值或平均值),从而将特征图的高度和宽度各减少一半。
全连接层(Fully Connected Layer,FC)的作用是将前面所有层提取到的特征进行整合,最后输出一个类别概率分布。全连接层的神经元与前一层的所有神经元相连,因此需要将前一层的特征图展平(flattening)为一维向量。
最后,输出层通过Softmax激活函数将输出转换为类别概率分布,以表示每个类别的预测概率。损失函数(Loss Function)计算模型预测结果与真实标签之间的差异,作为优化目标。
通过前向传播,模型能够从输入数据中提取特征,逐步变换数据,最终得到预测结果。为了优化模型,需要通过反向传播(Backpropagation)计算损失函数对各个参数的梯度,进行参数更新,以最小化损失函数。
在实际应用中,设计不同的卷积层、池化层数目和尺寸,调整激活函数的类型,选择合适的全连接层数目等,都是影响模型性能的重要因素。通过合理设计和调试,可以构建出高效、准确的卷积神经网络模型。
下图为简单的卷积神经网络的前向传播: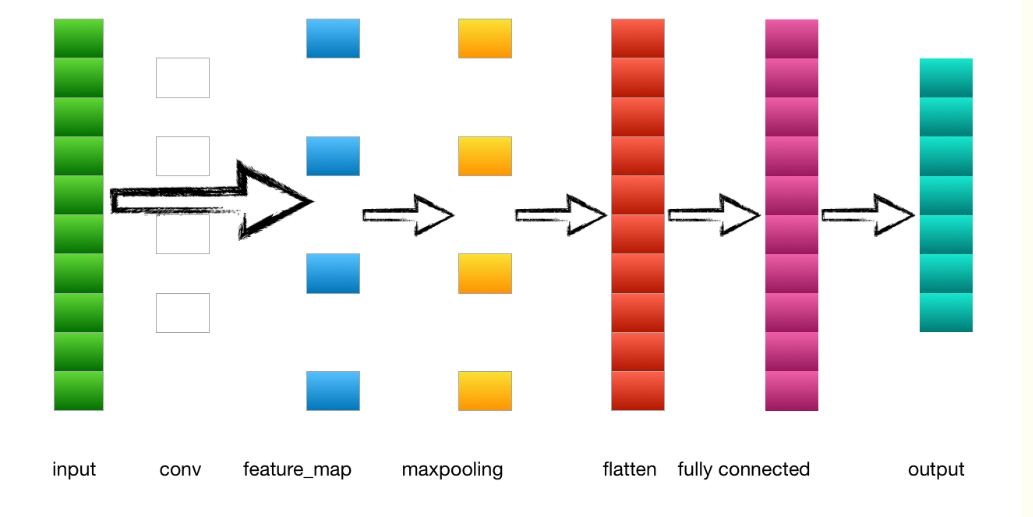
cnn例子图解:
1.输入层---->卷积层
输入是一个4*4 的image,经过两个2*2的卷积核进行卷积运算后,变成两个3*3的feature_map
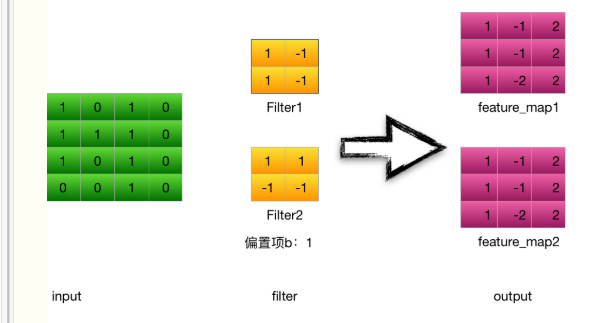
计算步骤:
以卷积核filter1为例(stride = 1 ):


2.卷积层---->池化层

3.池化层---->全连接层
池化层的输出到flatten层把所有元素“拍平”,然后到全连接层。
4.全连接层---->输出层
全连接层到输出层就是正常的神经元与神经元之间的邻接相连,通过softmax函数计算后输出到output,得到不同类别的概率值,输出概率值最大的即为该图片的类别。
七、反向传播
卷积神经网络(Convolutional Neural Network,简称 CNN)中反向传播(Backpropagation)的作用主要是用于更新网络中的参数(权重和偏置),以最小化损失函数,从而使模型能够学习到数据中的特征和模式,具体如下:
计算梯度:反向传播算法基于链式法则,从输出层开始,将误差逐层反向传播到输入层。在这个过程中,它会计算损失函数关于每个参数的梯度。通过计算梯度,反向传播可以确定每个参数对损失函数的影响程度,即参数的变化会如何影响模型的输出误差。
更新参数:根据计算得到的梯度,反向传播算法会相应地更新网络中的参数。通常使用梯度下降(Gradient Descent)或其变体(如随机梯度下降 SGD、Adagrad、Adadelta 等)来根据梯度调整参数的值。具体来说,会沿着梯度的反方向更新参数,使得损失函数的值逐渐减小。这样,经过多次迭代后,模型的参数会逐渐调整到能够使损失函数最小化的状态,从而使模型能够更好地拟合训练数据,提高模型的准确性和泛化能力。
八、参考文献
【深度学习系列】卷积神经网络详解(二)——自己手写一个卷积神经网络 - Charlotte77 - 博客园
深度学习之卷积神经网络(CNN)详解与代码实现(一) - w_x_w1985 - 博客园