文章目录
- 一、所需的数据
- 1.1、生命周期数据
- 1.2、HTTP测速数据
- 1.3、系统异常数据
- 1.4、用户行为数据
- 1.5、用户日志
- 二、埋点与收集
- 2.1、数据埋点
- 2.1、数据上报
- 2.3、数据监控
对于一个应用来说,除了前期的开发和设计,在项目上线后端维护很重要,其中就包括监控体系的搭建。
系统需要具备发布灰度过程中的监控以及用户问题的反馈和定位等能力。
这些问题可以从2个点解决:数据采集 和 数据上报与监控
- 一般来说我们之所以要搭建前端监控体系,主要是为了解决2个问题:
1. 如何及时发现问题?
2. 如何快速定位并解决问题?
- 主要是通过对以下信息的观察:
- 页面的整体访问情况,包括常见的PV、UV、用户操作行为
- 页面的性能情况,包括页面加载耗时、接口耗时等各项数据统计
- 最有效的解决方案:
- 对相似的问题进行归类
- 思考这类问题出现的原因有哪些
- 尝试从源头组织他们的出现
一、所需的数据
- 系统的质量主要看这三方面:
- 页面访问速度
- 页面稳定性/异常
- 外部服务调用情况
- 我们所要关注的数据主要是这这个
1. 系统的生命周期数据:可用于观察页面性能情况、整体访问情况等
2. HTTP测速数据:可用于观察外部服务调用情况、页面性能优化等
3. 系统异常数据:可用于观察系统稳定性、系统异常问题
4. 用户行为数据:可用于观察页面稳定性,整体访问情况等
5. 用户日志:用于进行用户反馈的问题排查
1.1、生命周期数据
- 前端应用的生命周期指页面加载的关键时间点
- 通常包括页面打开、更新、关闭等耗时数据
- 通过
PerformanceTiming属性中获取到一些生命周期相关的数据
- 用于页面跳转:navigationStart、unloadEventStart、unloadEventEnd等
- 用于页面加载:domloading、domInteractiv、loadEventStart、loadEventEnd、domcontentLoadedEventStart、domContentLoadedEventEn
- 获取页面关键加载点:通过document的DOMcontentLoaded、readystatechange等事件
- 但是由于框架的使用,页面的渲染过程、页面间的切换等逻辑都交给了框架进行控制
// 以vue的生命周期为例
- beforeCreate、created
- beforeMount、mounted
- beforeUpdate、updated
- beforeDestroy、destroyed
- 除了框架的生命周期以外,我们还可以使用
MutationObserver接口,提供了监听页面DOM树变化的能力
// 注册监听函数
const observer = new MutationObserver((mutations)=>{
console.log(`时间:${performance.now()}`,DOM树发生了变化:)
mutations.forEach(item=>{
console.log(item.type)
})
})
// 开始监听
observer.observe(document,{
childList: true,
subtree: true,
})
1.2、HTTP测速数据
- HTTP 请求相关的数据,同样可以通过
PerformanceTiming属性获取,包括HTTP跳转开始/结束、域名查询开始/结束等各种时间戳 - 通过这些数据我们可以观察后端服务是否稳定,是否还有优化空间。
1.3、系统异常数据
- 常见的前端异常有:
1. 逻辑错误:开发实现功能的时候,逻辑梳理不符合预期
2. 代码健壮性:代码边距情况考虑不周,异常逻辑执行错误
3. 网络错误:用户网络异常、后台服务异常等错误
4. 系统错误:代码运行环境兼容性问题导致出错
5. 页面内容异常:缺少内容、绑定事件异常、样式异常等
- 前面4种异常可以使用以下方法拦截
- window.onerror:获取项目中的错误和分析堆栈,将错误信息自动上报到后台服务中
- document.addEventlistener(err)
- XMLHttpRequest status
- 第5种异常
- 可观察页面中用户操作的数据、页面访问的数据是否异常。
- 一般情况下,可以通过回归测试,UI界面测试等方式在上线前进行避免
1.4、用户行为数据
- 用户行为数据一般指:
- 页面浏览量或点击量
- 用户在每一个页面的停留时间
- 用户通过什么入口来访问的该页面
- 用户在页面中的一些操作行为
- 主要用来:
- 行为数据的统计可以用来监控页面的功能是否正常
- 针对性的调整页面功能,更好的发挥页面的作用
- 统计出用户在时间轴上的操作顺序,以及每个步骤的操作时间、操作内容等
- 通过可视化系统直观的展示用户的链路情况
- 用户链路相关信息还可以用来点位问题,比如配合用户日志进行分析
1.5、用户日志
- 当系统出现异常,我们一般会使用日志进行定位,需要提前在代码中打印日志,否则当我们需要定位问题的时候,才发现我们没有输出相关日志。
- 有些问题由于复现困难,在后续补上日志发布后也未必能够复现,这样就比较被动。
- 这种前端可以通过提前添加装饰器:
- 比如在每个功能模块运行时,通过约定的格式来打印输入参数、执行信息、输出参数
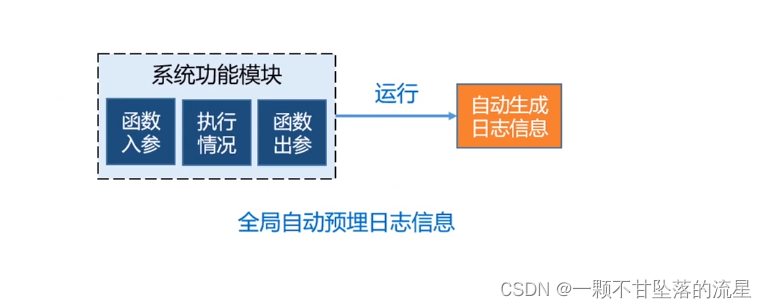
- 系统运行所输出的日志可以通过2种方式存放
1. 上报到服务器:
- 由于日志内容很多,如果全量上报到服务器会导致存储成本过大,同时频繁的上报也会增加接口的维护成本
- 除此之外,由于网络原因等还可能导致部分或全部的日志丢失等问题
2. 本地存储:
- 该方案需要引导用户手动操作提交本地日志、或者通过服务端下发配置自动上传,才可以获取到日志内容,从而可以进行具体的问题定位;
- 如果无法联系用户,或者缓存被清理的情况下,则可能由于异常无法重现无法修复。
- 在资源运行的情况下也可以两种方式配合一起使用
二、埋点与收集
2.1、数据埋点
- 通常情况下我们会根据使用场景来将这些方案配合使用
- 不管使用哪种埋点方式,我们都需要对数据进行标准化处理
- 也需要将采集的数据,按照服务端约定好的协议格式进行转换
- 配合本地缓存的方式,将数据进行缓存,在应用恢复的时候进行数据的上报
| 埋点方案 | 使用方式 | 自定义数据 | 业界成熟产品 | 更新代价 | 使用成本 |
|---|---|---|---|---|---|
| 代码埋点 | 手动编码 | 可自定义 | 友盟、百度统计等第三方数据统计服务商 | 需要版本更新 | 高 |
| 可视化埋点 | 可视化圈选 | 较难自定义 | Mixpanel | 需要下发配置 | 中 |
| 无痕埋点 | 嵌入SDK | 难以自定义 | GrowingIO | 不需要 | 低 |
2.1、数据上报
- 数据上报示意图:
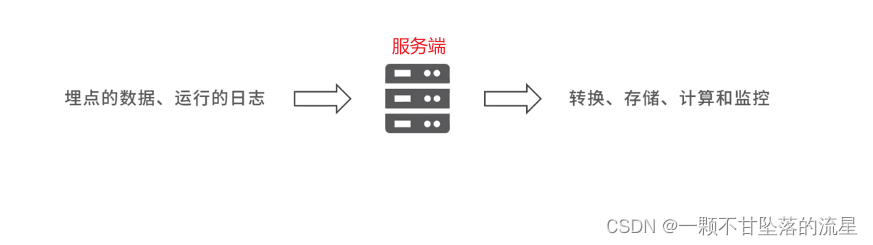
- 为了避免数据的上报过于频繁,增加服务端压力,我们可以在本地进行数据的整合(比如通过队列或数组的形式)
- 定期定量的上报
- 过于频繁的请求可能会影响到用户其他正常请求的体验,通常我们需要将收集到的数据存储到本地。
- 当收集到一定数据之后再打包一次性上报,或者按照一定的频率打包上传
- 打包上传将多次数据合并为一次,就可以减轻服务器的压力
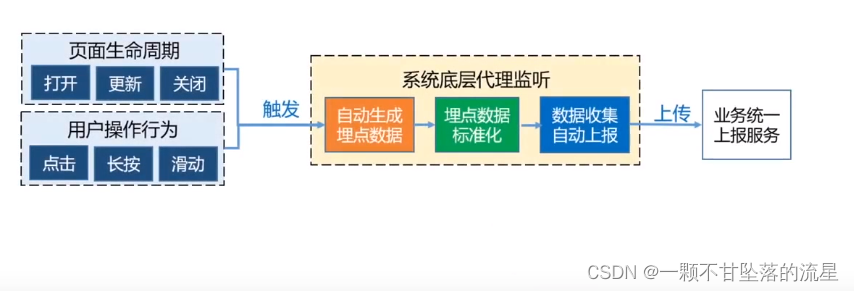
- 关键生命周期上报
通过关键点监听这些事件,获取相关数据,并进行标准化处理后,上报到服务端
- 用户主动提交
- 当用户触发上传的操作后,可以将本地的数据和日志一并进行提交
- 系统生命周期相关数据、系统错误数据、用户行为数据等需要及时的进行上报
- 用户主动提交的行为可能更适合日志的上报
2.3、数据监控
通过对监控数据、配置告警阈值等方式,结合邮件、机器人等方式推送到相关的人员
- 通过上报的页面整体情况和用户行为数据:
- 实时对各个操作信息进行分析,得到用户的操作链路
- 每个页面和功能操作步骤间的耗时和转换率,并进行有效的监控
- 当页面出现异常的时候,可以及时的发现,并进行告警,从而快速的解决问题
- 前端监控在发布和灰度的过程中也发挥着极其重要的作用
- 对于链路复杂的前端应用,通过开发自测的方式保证功能是否正确是很低效的
- 人工测试也常常无法覆盖到所有的功能跟各个链路的分支
- 同时自动化测试也常常因为性价比等问题无法做到完善
- 因此在新版本上线时,除了对改动相关的功能进行自测,并使用自动化测试进行回归测试之外
- 我们还可以在上报数据的时候,更新当前系统的版本号,发布过程中,可以根据版本号来区分各个版本的曲线情况
- 在灰度过程中,我们可以关注以下信息
- 错误告警是否有新增错误,可通过错误内容找到报错位置修复
- 全版本监控观察:整体的功能点覆盖曲线是否正常,是否有异常涨跌
- 分版本监控观察:新版本是否所有功能都能正常访问、灰度占比是否正常,新旧版本的转换率是否一致







![[开发浏览器实战]关于Firefox火狐浏览器的说明一二(国内版 国际版区别 账号切换 插件-恢复关闭的标签页 插件-tempermonkey油猴)](https://img-blog.csdnimg.cn/5bc2170155fe4727aec041d9a9b7ab58.png)