先放张图
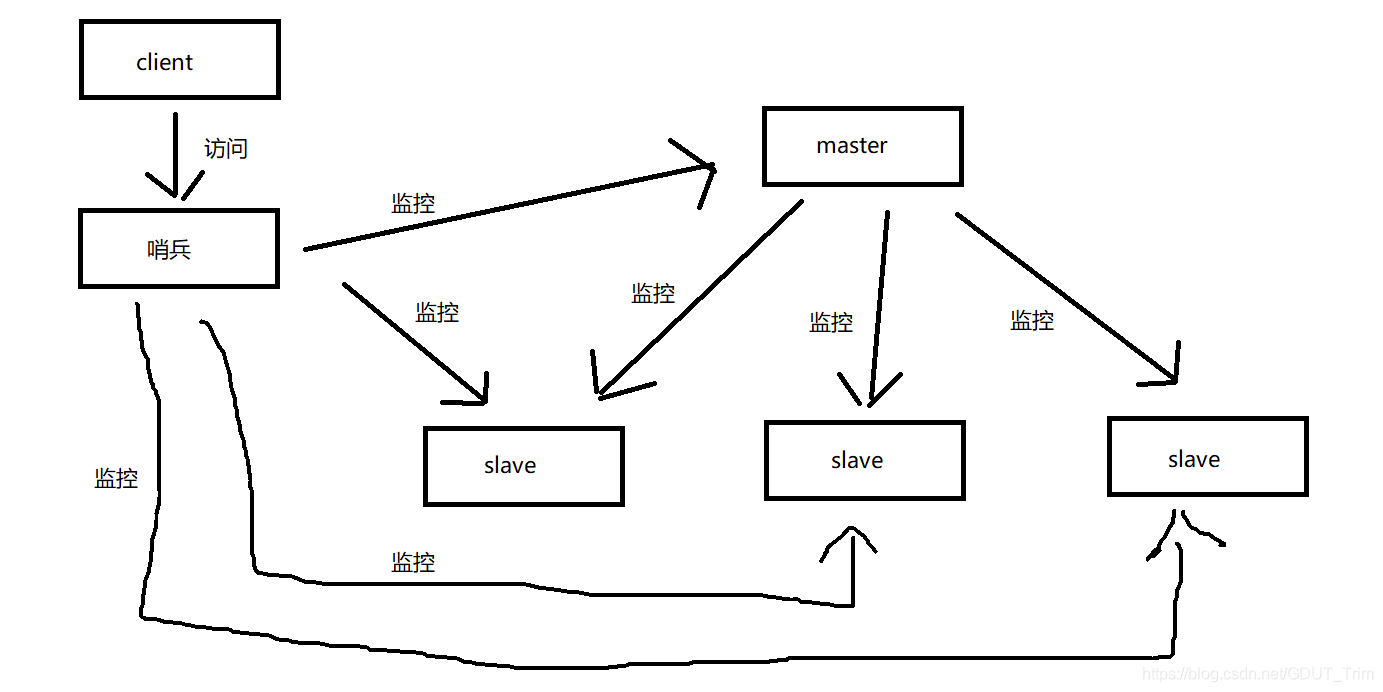
上图就是典型的哨兵模式
-
salve:从服务器,需要进行同步主服务器的数据
-
master:主服务器,负责执行客户端的请求,将数据更新信息发送给从服务器,保持数据一致
-
哨兵:接受客户端请求,并将其转给主服务器,同时对所有服务器进行监控
1、哨兵为什么要对所有服务器监控?
因为哨兵要知道哪些服务器挂掉,如果主服务器挂掉,就需要进行选举,选出一台从服务器替代主服务器(自动切换主从),如果从服务器挂掉,选举时就不会考虑该从服务器,也就是主要执行的工作是状态检测和故障切换,不需要进行人工切换主从服务器。
2、如果哨兵挂掉怎么办?
可以多建几个哨兵,实现高可用性,但要注意的是,客户端访问的时候,只会访问一个哨兵。
3、哨兵的局限性?
-
哨兵只是单纯解决了切换主从服务器的问题,可以进行自动切换,不需要进行手动切换,仍然没有根本性解决并发量高的问题
-
会有访问瞬断的问题(切换主从服务器需要时间,虽然短暂,但这段时间仍然会停止服务)
高可用集群
Redis使用的集群模式就是高可用集群
还是先上图

介绍图中的几个对象
-
Redis-Cluster:接受客户端的请求,并且进行负载均衡,将请求按照负载均衡规则分配给各个Master(每一个小集群)
-
Master与其slave:一个小集群,与上面哨兵模式提到的集群类似
1、为什么叫高可用集群?哪里高可用了?
高可用这个概念是相对来说的,并不能真正百分百实现,当小集群的Master挂掉时,小集群内部会进行选举切换,但在这个瞬断期间,Redis并不会停止服务,只是不会将请求分给挂断的集群去处理,会分发给其他集群进行处理,高可用性比哨兵模式会好很多。
但是仍然会有请求失败,比如一个请求刚好请求给其中一个Master,Master还没执行完就挂掉了,这也会造成请求丢失,所以没有百分百的高可用。
2、优点是什么?
优点就是前面所说的高可用性提高了,减少了停止服务时间。
3、内部通信原理是什么?
比如现在有一个添加键值对对象的请求是给到了集群A去实现,那么假如现在有一个访问刚添加的键值对对象的请求,不是给到了集群A而是给到了集群B,那么此时就会进行转换集群,也就是从集群B中转换到了集群A,然后再进行读取(因为集群B并没有那个键值对信息,只有集群A有)
这里使用虚拟机,系统为Centos7。
由于我已经安装好了Redis,这里就不进行介绍Redis的安装,自行百度吧。
这里我要创建3个小集群,每个小集群一个主服务器,一个从服务器,也就是三主三从架构
主要步骤如下
-
创建文件夹
-
复制配置文件,并修改
-
命令运行
创建文件夹
这里我是在Redis安装目录进行的
#创建集群文件夹
mkdir redis-cluster
#进入到集群目录
cd redis-cluster
#创建各个小集群的文件夹
mkdir 8001
mkdir 8002
mkdir 8003
mkdir 8004
mkdir 8005
mkdir 8006
复制默认配置文件,并修改一些选项
需要需改的选项
-
daemonize yes 开启后台启动
-
port 800x 对应各个端口号(由于是单机集群,所以只能使用端口号替代不同服务)
-
bind xxxx(这里必须要绑定ip地址,不能使用localhost,也就是127.0.0.1)
-
dir /usr/local/redis-cluster/800x/(绑定数据文件存放的位置,否则会出现混乱,这里绑定的文件夹就是上面创建的文件夹的位置)
-
cluster-enabled yes(开启集群)
-
cluster-config-file nodes-800x.conf (这个是集群节点信息文件,这里的800x和port要进行对应)
-
cluster-node-timeout 15000(小集群超过多长时间不响应就会被退出集群,单位为毫秒)
-
appendonly yes(开启AOF持久化操作)
这里是每个小集群都要去复制执行喔
**复制命令
cp redis.conf …/800x
**使用vim进行搜索
/搜索内容 + 回车
**使用vim进行统一修改
:%s/要修改的内容/修改成什么内容/g + 回车
**比如,将所有的8001修改成8002
:%s/8001/8002/g






开启所有服务器
**使用redis的redis-server脚本进行开启
**注意这里要将8001,8002,8003,8004,8005,8006都开启
/usr/local/redis/bin/redis-server /usr/local/redis-cluster/800x/redis.conf
开启完毕后,我们可以看后台进程
ps -ef|grep redis

可以看到,已经全部启动起来了,而且后面还标有cluster,但是到现在这一步,并没有完成搭建,还需使用Ruby命令
UT_Trim/article/details/116138403)使用Ruby命令开启集群
这里先下载Ruby
yum install ruby
yum install rubygems
gem install redis --version 3.0.0 (这里要用3.0以上的版本,因为Redis3.0才开启集群支持)
接下来我们查找一下redis-cli在哪里
find / -name redis-cli

**进入到该目录
cd /usr/local/redis/bin
**执行该命令
./redis-cli --cluster create 192.168.3.31:8001 192.168.3.31:8002 192.168.3.31:8003 192.168.3.31:8004 192.168.3.31:8005 192.168.3.31:8006 --cluster-replicas 1 -a 0110x3

这里要对参数进行说明
–cluster-replicas 1 :代表执行主从集群配置,而且主服务器和从服务器为1比1,-a是因为我设置了密码验证,所以要加上
下面为开启成功的信息
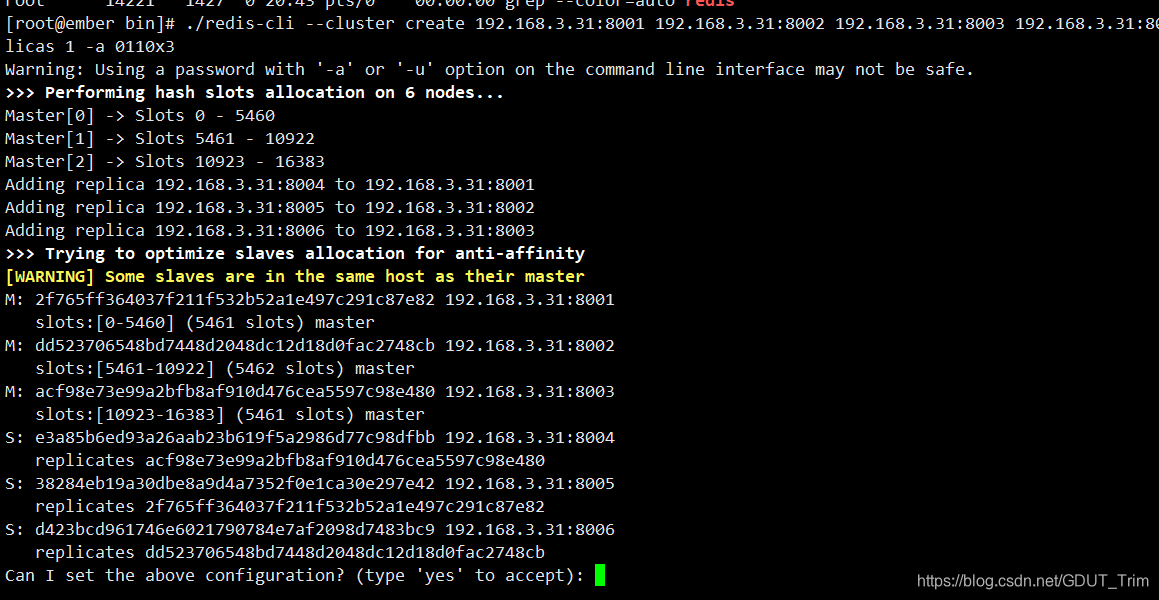
但还真正建立,需要输入Yes确定后,就会显示主从关系之间的信息

验证集群是否开启成功
随便连上一个主服务器
#随便连一个客户端
./redis-cli -c -h 193.168.3.31 -p 800x -a 密码
#输入下面命令查看
cluster info
cluster node

这里要注意几个参数
-
cluster_size:主服务器个数
-
cluser_known_nodes:从服务器个数
 这里也要注意几个参数
这里也要注意几个参数
- slave后面的一串id,对应的是其主服务器的id
至此搭建就完毕了
下面进行测试一下吧

从上面一大段测试栗子,可以看到,进行插入键值对是不断进行轮换的结点,这也是负载均衡的一种方式,成为轮询。
对应所有端口号进行杀掉所有Redis进程即可







![[开发浏览器实战]关于Firefox火狐浏览器的说明一二(国内版 国际版区别 账号切换 插件-恢复关闭的标签页 插件-tempermonkey油猴)](https://img-blog.csdnimg.cn/5bc2170155fe4727aec041d9a9b7ab58.png)