最近阅读《软件性能测试、分析与调优实践之路》一书,个人认为性能调优章节为整部书的精华,该章节包括了性能测试调优模型、调优思想和调优技术。下面是摘抄整理自书中内容:
调优模型
下图为互联网中常见的用户请求的分层转发和处理的过程,在性能调优时就是 不断采集系统中的性能指标以及系统模型中各层的资源消耗,从中发现性能瓶颈和性能问题,然后对瓶颈和问题进行分析诊断来确定性能调优方案,最后通过性能压测进行验证调优方案是否有效,如果无效继续重复这个过程进行性能分析,直到调优方案有效,瓶颈和问题得到解决。
如果你想学习jmeter性能测试,我这边给你推荐一套视频,这个视频可以说是B站播放全网第一的jmeter接口测试教程,同时在线人数到达1000人,并且还有笔记可以领取及各路大神技术交流:798478386
15天学会性能测试,通俗易懂详细教学,Jmeter性能测试实战(集群压测,全链路压测,性能调优,瓶颈分析)极速掌握,干就完事!_哔哩哔哩_bilibili15天学会性能测试,通俗易懂详细教学,Jmeter性能测试实战(集群压测,全链路压测,性能调优,瓶颈分析)极速掌握,干就完事!共计27条视频,包括:1.【性能测试】什么是性能测试以及性能测试的价值和目的、2.【性能测试】真实企业性能测试指标详解以及指标测算、3.【性能测试】真实企业中性能测试流程以及细节剖析等,UP主更多精彩视频,请关注UP账号。 https://www.bilibili.com/video/BV1B14y1D7X9/?spm_id_from=333.337.search-card.all.click
https://www.bilibili.com/video/BV1B14y1D7X9/?spm_id_from=333.337.search-card.all.click
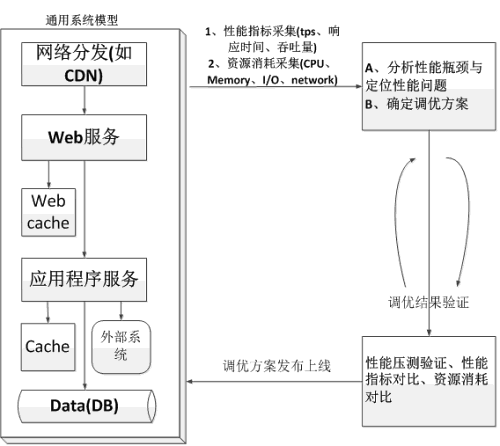
系统模型中相关的组件描述如下表所示:
| 组件 | 描述 |
| 网络分发 | 网络分发是高速发展的互联网时代常用的降低网络拥塞,快速响应用户请求的一种技术手段,最常用的网络分发就是CDN(Content Delivery Network,即内容分发网络),依靠部署在世界各地的边缘服务器,通过中心平台的负载均衡、源服务器内容分发、调度等功能模块,使世界各地用户就近获取所需内容,而不用每次都到中心平台的源服务器获取响应结果,比如南京的用户直接访问部署在南京的边缘服务器,而不需要访问部署在遥远的北方的北京的服务器 |
| Web服务器 | Web服务器用于部署Web服务,Web服务器的作用就是负责请求的响应和分发以及静态资源的处理 |
| Web服务 | Web服务指运行在Web服务器上的服务程序,最常见的Web服务就是Nginx和Apache |
| Web Cache | Web Cache指Web层的缓存,一般都是临时缓存HTML、CSS、图像等静态资源文件 |
| 应用服务器 | 应用服务器用于部署应用程序,如Tomcat、WildFly、普通的Java应用程序(如jar包服务),IIS等 |
| 应用程序服务 | 应用程序服务指运行在应用服务器上的程序,比如Java应用,C/C++应用、Python应用,一般用于处理用户的动态请求 |
| 应用缓存 | 应用缓存指应用程序层的缓存服务,常用的应用缓存技术有Redis、Memcached等,这些技术手段也是动态扩展的高并发分布式应用架构中经常使用的技术手段 |
| 数据库(DB) | 用于数据的存储,可以包括关系型数据库以及NoSql数据库(非关系型数据库),常见的关系型数据库有Mysql、Oracle、Sqlserver、DB2等,常见的NoSql数据库有Hbase、MongoDB、ElasticSearch等 |
| 外部系统 | 指当前系统依赖于其他的外部系统,需要从其他的外部系统中通过二次请求获取数据,外部系统有时候可能会存在很多个 |
调优思想
1、分层分析
分层分析指的就是 按照系统模型以及系统架构分层、按照调用链进行监控分析和问题排查,如下图所示:
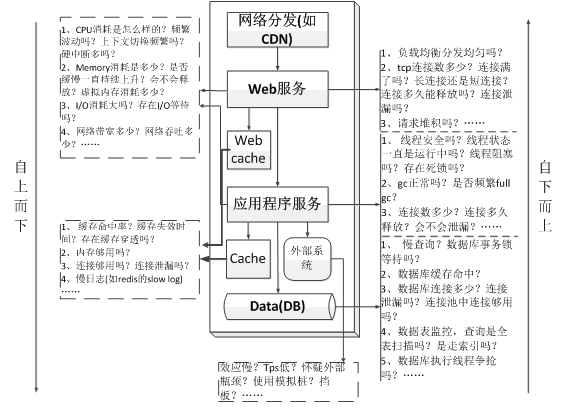
- 分层排查一般需要对系统的应用架构层次以及部署架构非常的熟悉,需要熟悉请求的处理链过程。
- 分层排查一般需要对每一层建立checklist,然后按照每层的checklist逐一进行分析。
- 分层排排查效率较低,但是往往能发现更多的性能问题。
- 分层排查可以自上而下也可以自下而上。
2、科学论证
通常包括发现问题、问题假设、预测、试验论证、分析:
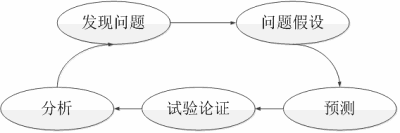
- 发现问题:指通过性能采集和监控,发现了性能瓶颈或者性能问题,比如并发用户数增大后TPS并不增加、每台应用服务器的CPU消耗相差特别大等。
- 问题假设:指根据自己的经验判断,假设是某个因素导致了出现瓶颈和问题。
- 预测:指根据问题假设,预测可能出现的一些现象或者特征。
- 试验论证:根据预测,去检查预期可能出现的现象或者特征
- 分析:根据获取到的实际现象或者特征进行分析,判断假设是否正确,如果不正确,就重新按照这个流程进行分析论证。
科学论证法进行性能分析与调优的示例如下图所示:

3、问题追溯与归纳总结
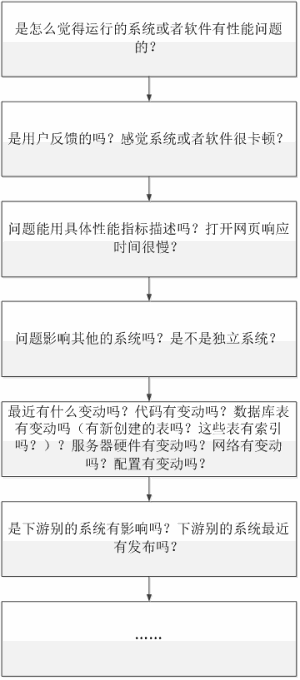
1、问题追溯分析
问题追溯分析指的是根据问题去追溯最近系统或者环境发生的变化,通过在追溯和描述中去逐步排查可能导致问题的原因,一般适用于生产已上线系统的版本发布或者环境变动导致的性能问题。
2、归纳总结
根据经验的总结,在出现某种性能瓶颈或者性能问题时根据以往总结的原因进行逐一排查。
调优技术
1、缓存调优

缓存调优的关键点:
- 如何让缓存的命中率更高?
- 如何注意防止缓存穿透?
- 如何控制好缓存的失效时间?
- 如何做好缓存的监控分析?比如slow log分析、连接数监控、内存使用监控。
- 如何防止缓存雪崩?
其中,缓存雪崩 指的是服务器在出现断电等极端异常情况后,缓存中的数据全部丢失,导致大量的请求全部需要从数据库中直接获取数据从而数据库压力过大造成数据库崩溃,防止缓存雪崩需要注意:
- 要处理好缓存数据全部丢失后,如何能快速把数据重新加载到缓存中。
- 缓存数据的分布式冗余备份,当出现数据丢失时,可以迅速切换使用备份数据。
2、同步转异步推送
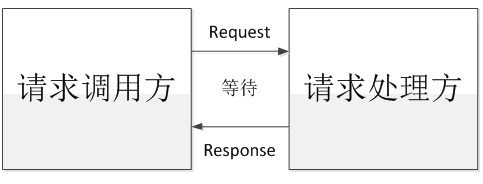
同步:指的是系统收到一个请求后,在该请求没有处理完成时,就一直不返回响应结果,直到处理完成了才返回响应结果。如下图所示:
异步:与同步相比,异步指的是系统收到一个请求后,只立即返回请求调用方请求接收成功,在请求处理完成后,再异步推送处理结果给调用方,或者请求调用方在间隔一定时间再重新来获取请求结果。如下图所示:
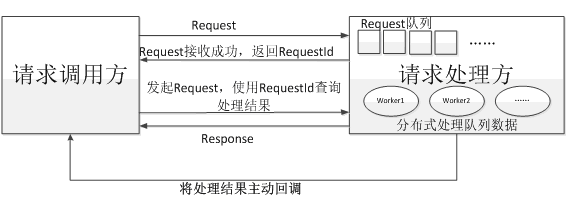
同步转异步主要是解决同步请求时的阻塞等待,一直处于阻塞等待的请求,往往会造成连接不能快速释放,从而导致高并发处理时,连接数不够用,通过队列异步接收请求后,请求处理方再进行分布式的并行处理,从而达到处理能力扩展,并且网络连接也可以快速释放。
3、拆分
拆分 指的是将系统中的复杂的业务调用拆分为多个简单的调用,一般遵循的原则如下:
- 对于高并发的业务请求调用都单独拆分为单个的子系统应用。
- 对于并发访问量接近的业务,可以按照产品业务进行拆分,相同的产品业务都归类到一个新的子系统中。

系统拆分带来的好处就是高并发的业务不会对低并发业务的性能造成影响,而且系统在硬件扩展时,也可以有针对性的进行扩展,避免资源的浪费。
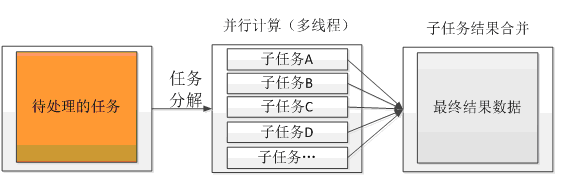
4、任务分解与并行计算
任务分解与并行计算指的是将一个任务拆分为多个子任务,然后将多个子任务并行进行计算处理,最后只需要再将并行计算的结果合并在一起返回即可。目的是通过并行计算的方式来增加处理性能。
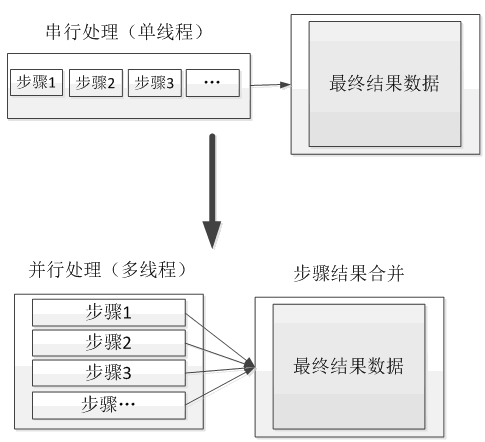
另外对于包含多个处理步骤的串行任务,也可以尽量按照如下图所示的方式转换为并行计算处理。
5、索引与分库分表
索引
指应用程序在查询时,尽量走数据库索引查询,数据库表在创建时也尽量对查询条件的字段建立合适的索引,这里强调一定是合适的索引,如果索引建立不合适,不仅对查询效率没有任何的帮助,反而会使数据库表在插入数据时变的更慢,因为一旦建立了索引后,数据在插入时,索引也会自动更新,这样就加大数据库的插入时的资源消耗。
分库
一般指的是一个数据库的存储已经很大了,查询和插入时I/O消耗非常大,此时就需要将数据库拆分成2个库来减轻读写时I/O的压力。
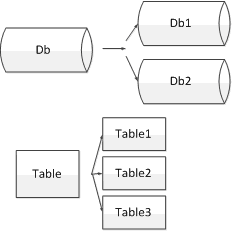
常见的分库分表方式如下:
- 按照冷热数据分离的方式:一般将使用频率非常高的数据称之为热数据,查询频率较低或者几乎不被查询的数据称之为冷数据,冷热数据分离后,热数据单独存储,这样数据量就会下降下来了,查询的性能自然也就提升了,而且还可以更方便的单独针对热数据做I/O的性能调优了。
- 按照时间维度的方式:比如可以按照实时数据和历史数据分库分表,也可以按照年份、月份等事件区间进行分库分表,目的是尽可能的减少库表中的数据量。
- 按照一定的算法计算的方式:此种方式一般适用于数据都是热数据的情况,比如数据无法做冷热分离,所有的数据都经常被查询,而且数据量又非常的大。此时就可以根据数据中的某个字段做算法计算(注意的是这个字段一般是数据查询时的检索条件字段),使得数据能均匀的落到不同的分表中去,查询时再根据查询条件字段做算法计算就可以快速的定位到是需要到哪个表中去进行查询。
数据分库分表后,带来的另一个好处就是,如果单次查询时,需要查询多个分表,那么此时就可以通过多线程并行的方式去查询每个分表,最后对每个分表的查询结果做一次合并即可,这样也可以使得查询的效率更高。