目录
- 1 概述
- 1.1 发展历程
- 1.2 预训练+监督学习
- 预训练的好处
- 1.3 增强式学习
- 1.4 对训练数据的记忆
- 1.5 更新参数
- 1.6 AI内容检测
- 1.7 保护隐私
- 1.8 gpt和bert
- 穷人怎么用gpt
- 2 生成式模型
- 2.1 生成方式
- 2.1.1 各个击破 Autoregressive
- 2.1.2 一次到位 Non-autoregressive
- 2.1.3 两者结合
- 2.2 预训练和微调
- 2.3 指示学习 instruction learning 和 上下文学习 in-context learning
- 2.2.1 上下文学习 in-context learning
- 2.2.2 指示学习 instruction learning
- 2.2.3 chain of thought (CoT) prompting
- 让模型自动生成prompt
- 2.3 训练数据的预处理
- 2.4 Human Teaching (强化学习)
- KNN+LM
- 2.5 信心越高,正确率越高
- 让AI 解释AI
- 如何判断解释的好不好?
- 大致流程
1 概述
怎么学习?——给定输入和输出:
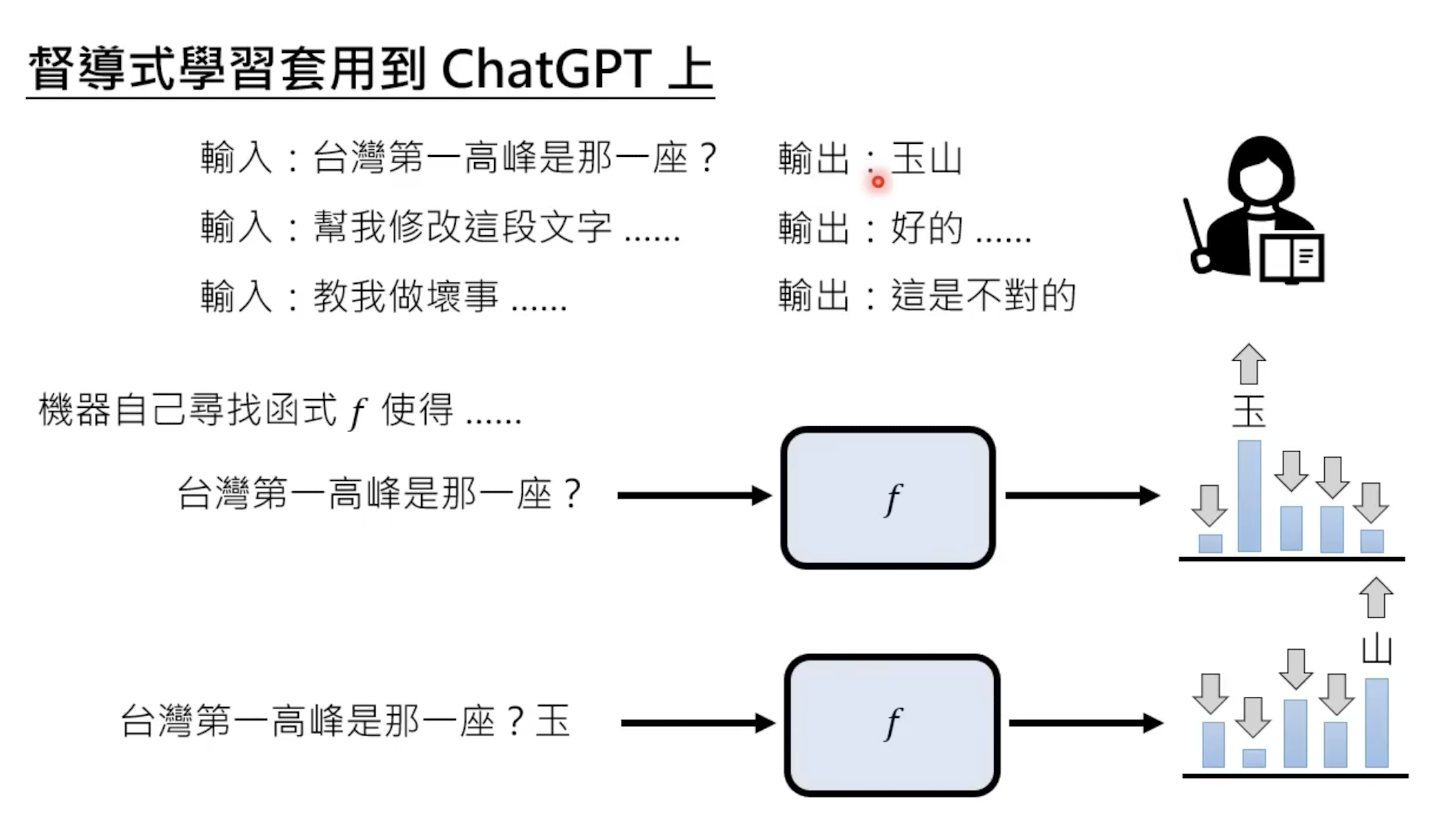
但是这样做不现实,因为这样输入-输出需要成对的资料,而chatgpt 成功解决了这一个难题。
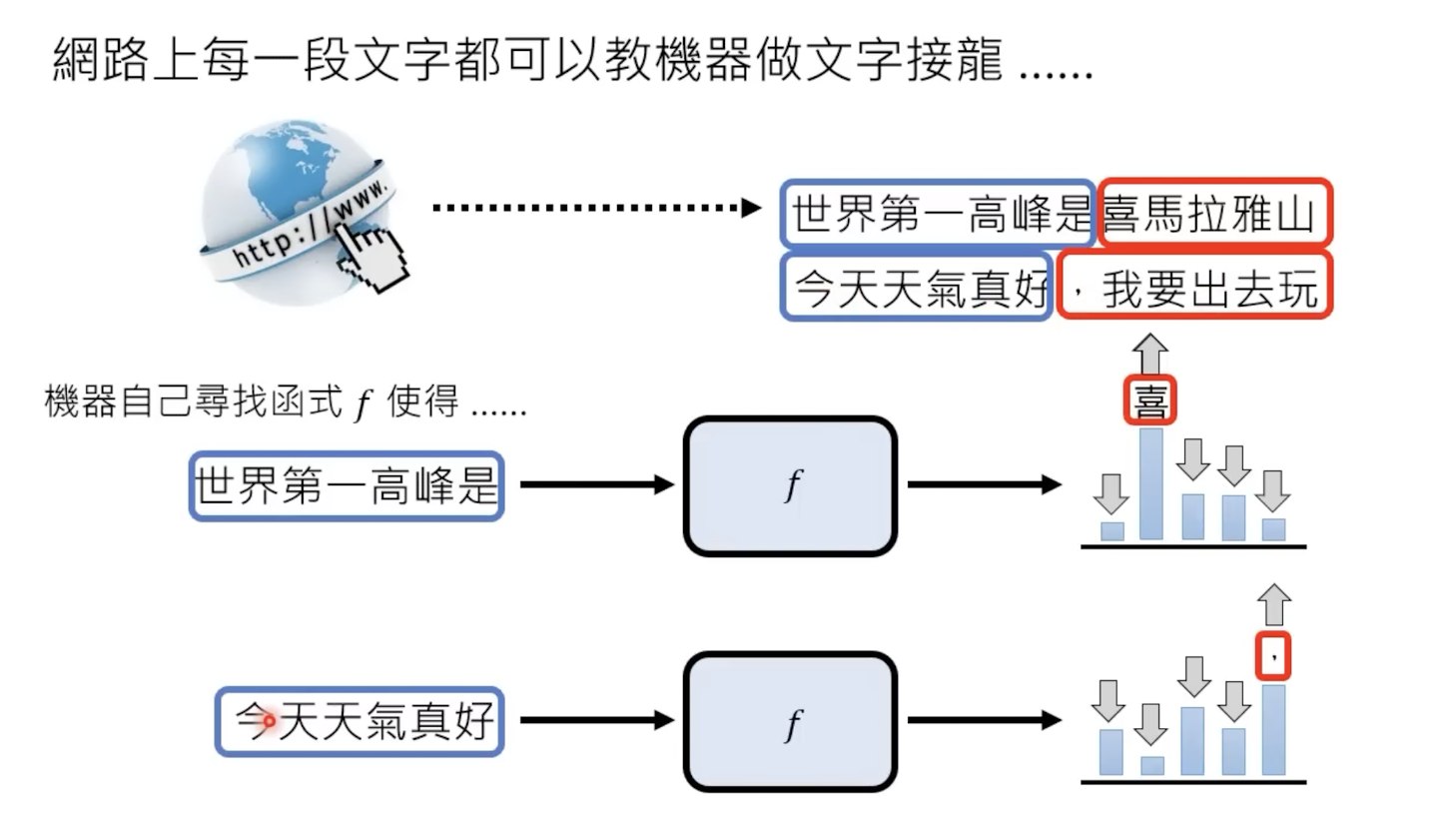
chatgpt不需要成对的资料,只需要一段有用的资料,便可以自己学习内容,如下:
1.1 发展历程
初代和第二代gpt

第二代到第三代

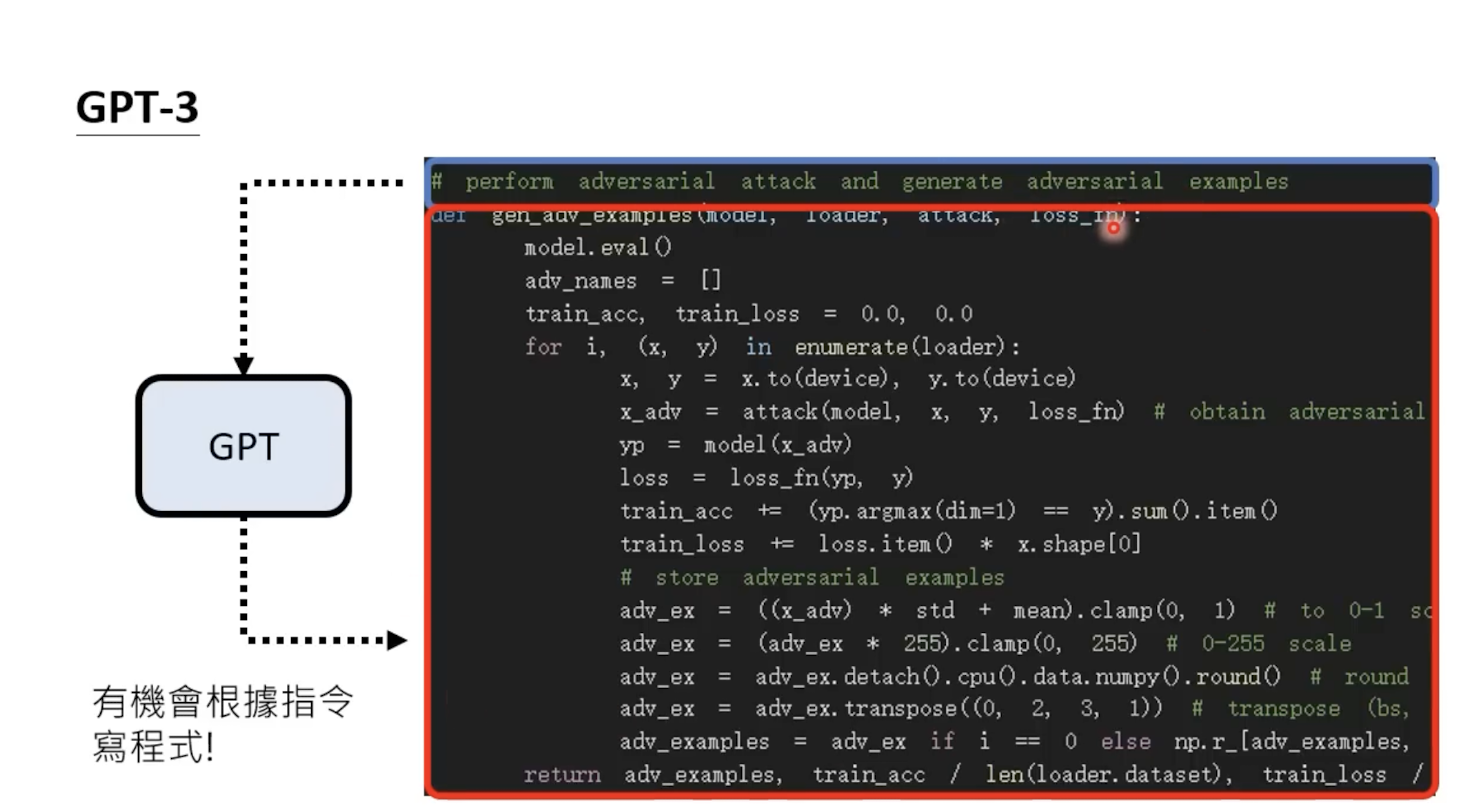
gpt3还会写代码
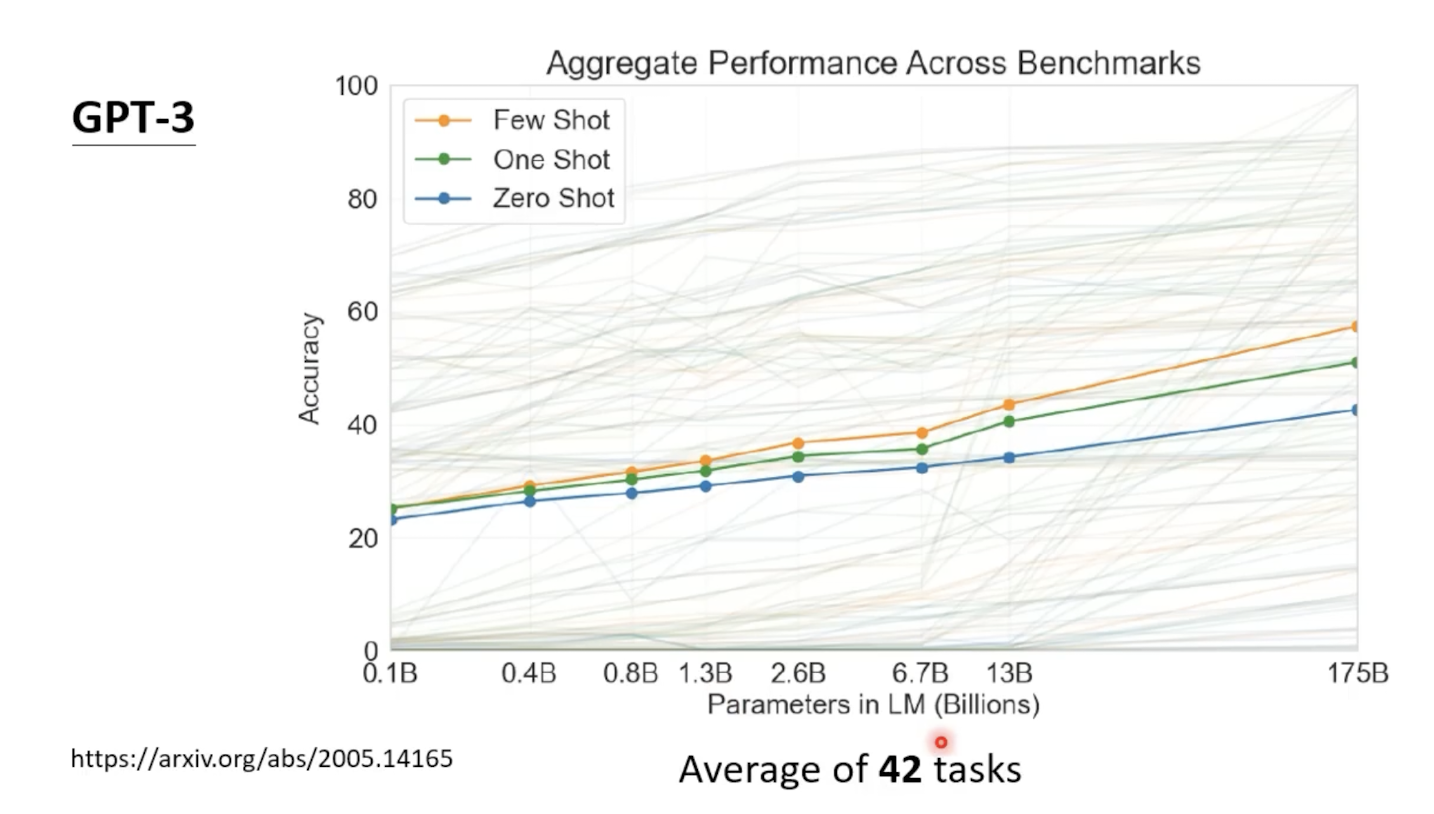
其性能表现
但是gpt3也有缺点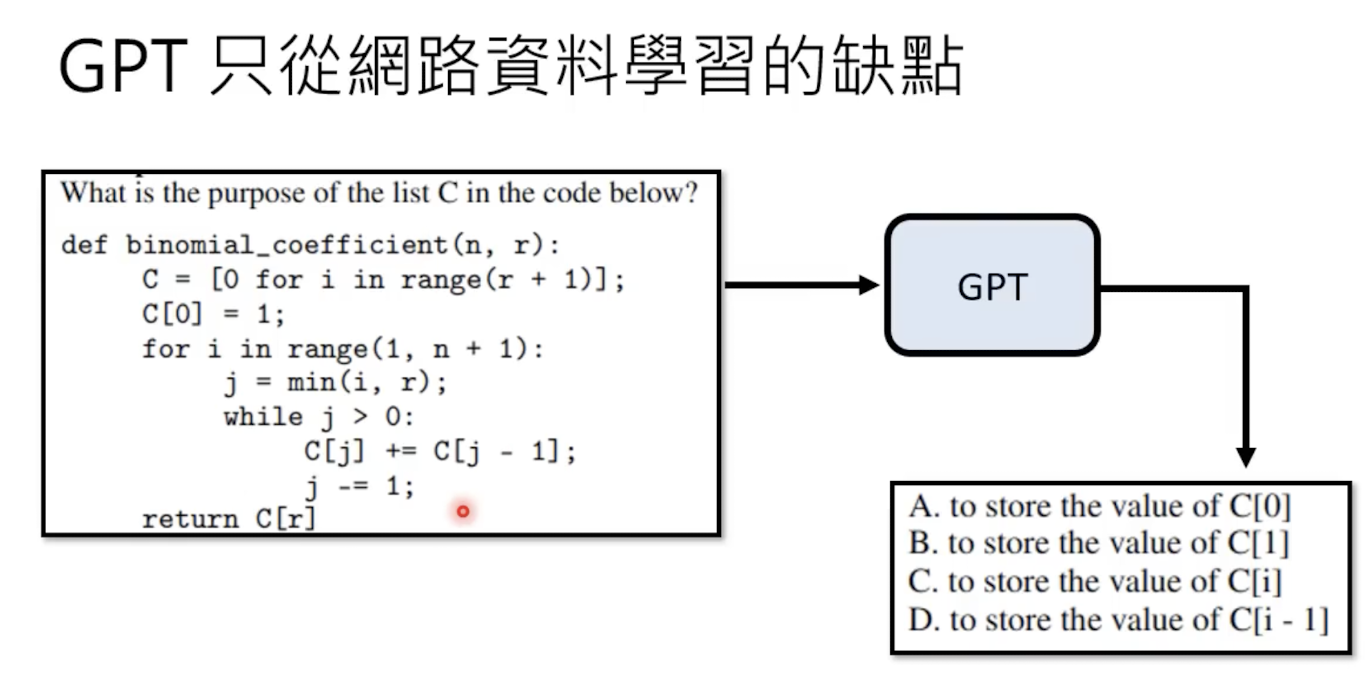
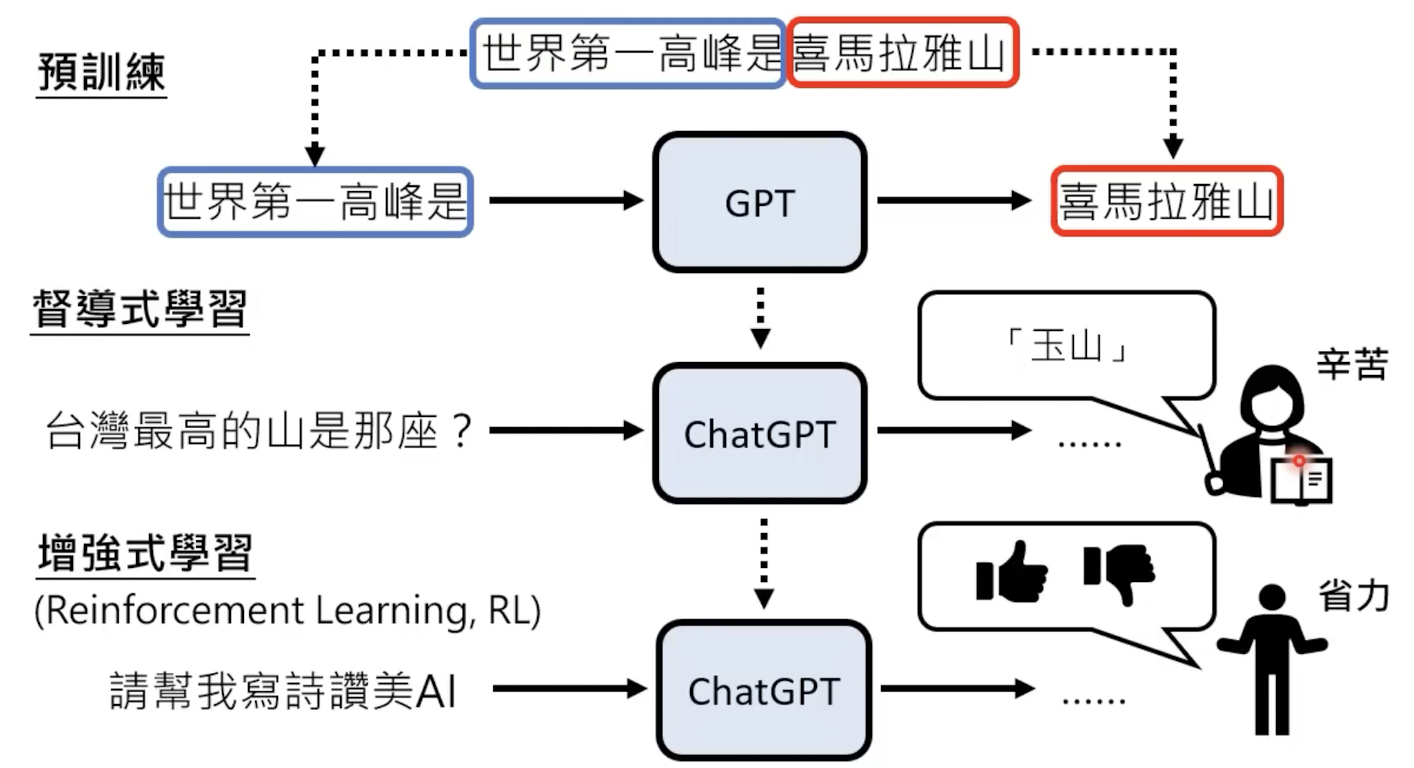
1.2 预训练+监督学习
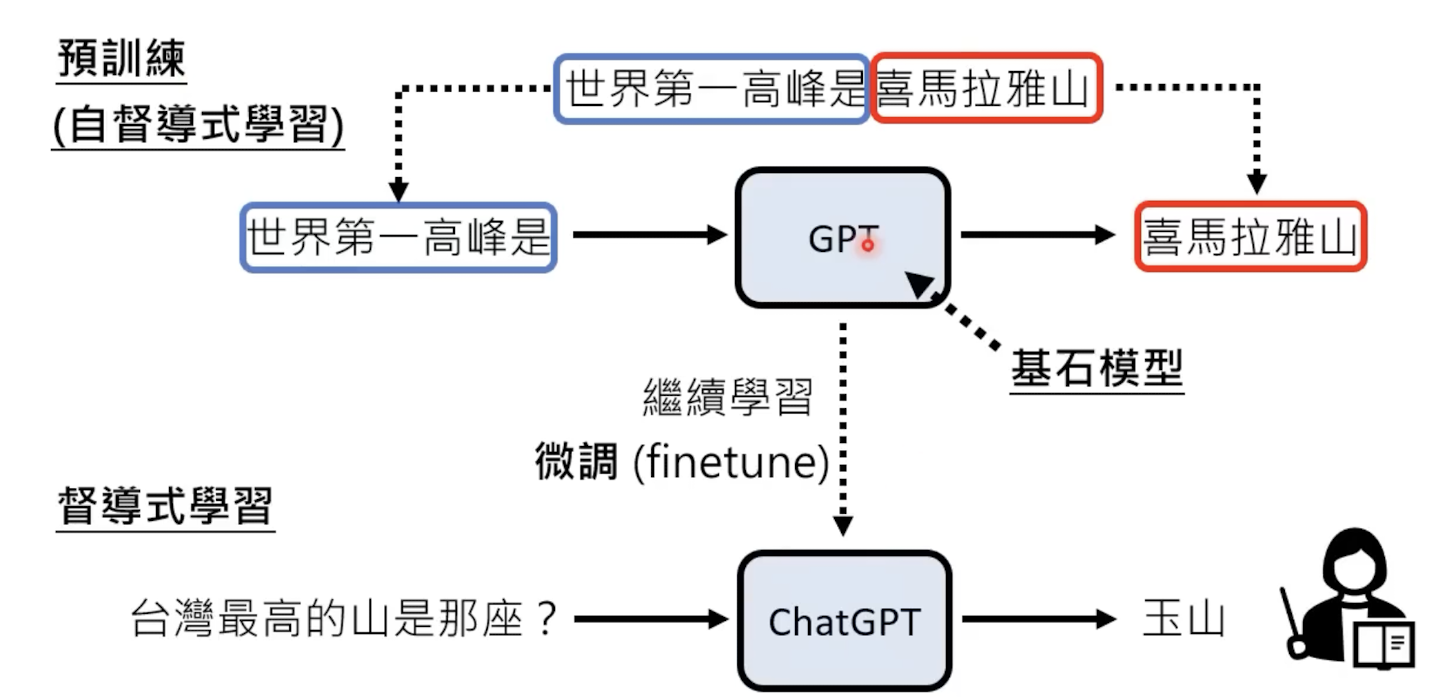
想要实现chat的功能,就得经过一个监督式学习(问答),就要在预训练后,增加一个监督学习的流程,赋予模型问答能力:
预训练的好处
在多种语言上做过多训练以后,某一语言的任务会帮助其他语言学会同样的任务。

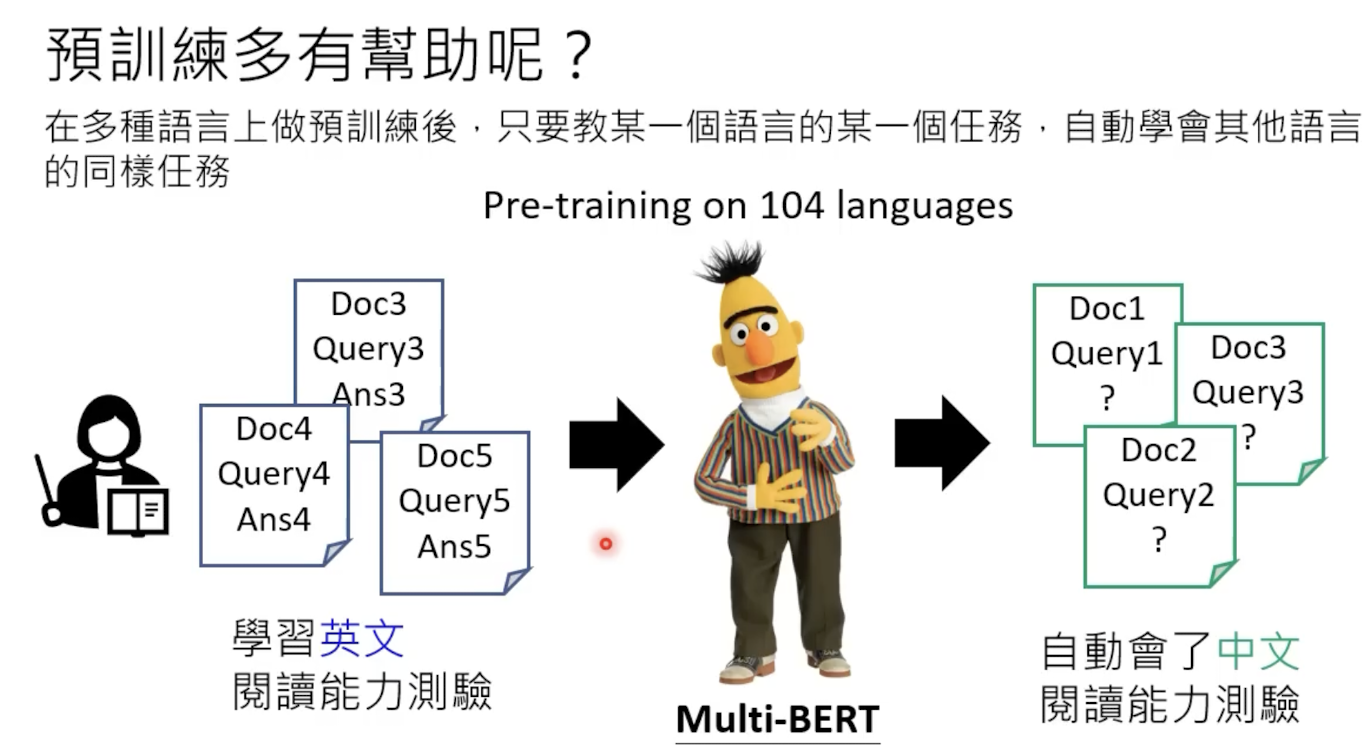
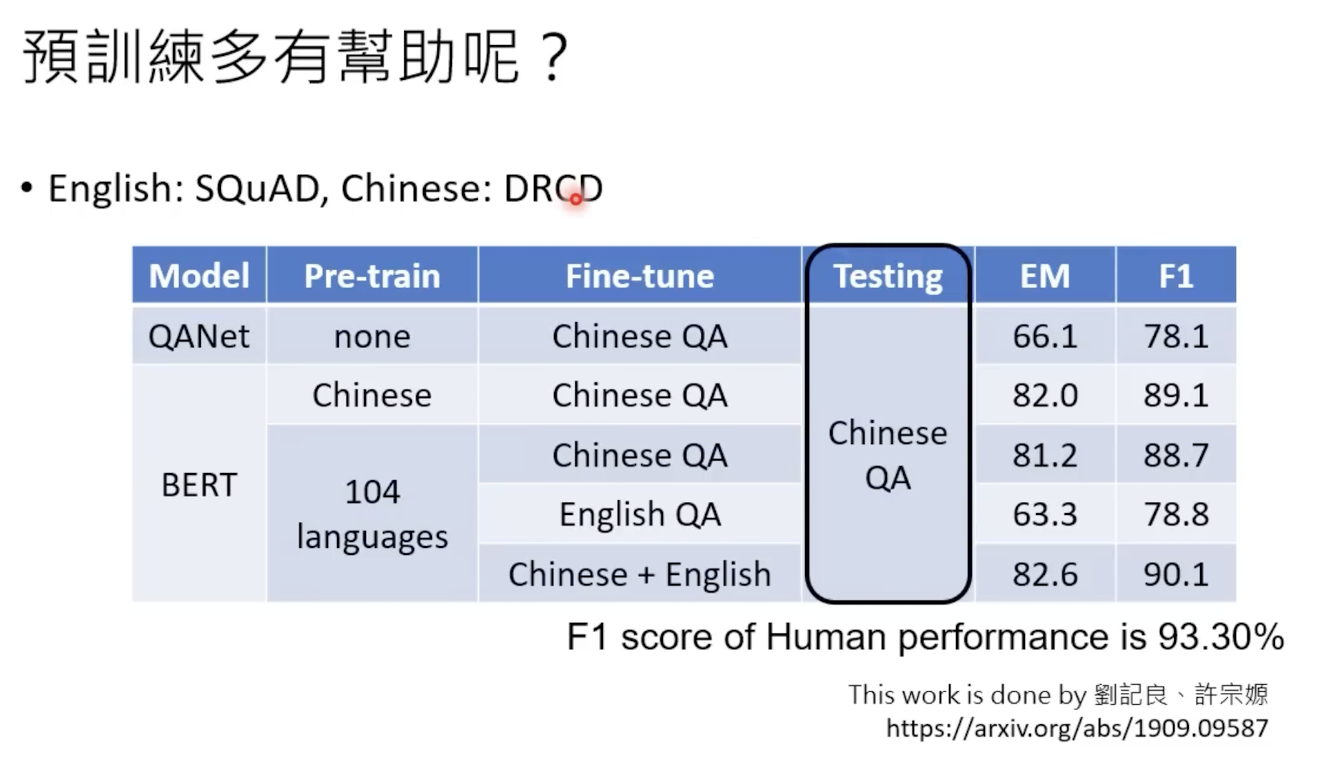
实验数据如下:
1.3 增强式学习
chatgpt还引入了增强式学习,给好的回答更多奖赏回馈。
1.4 对训练数据的记忆
其能够记得训练数据的部分信息:

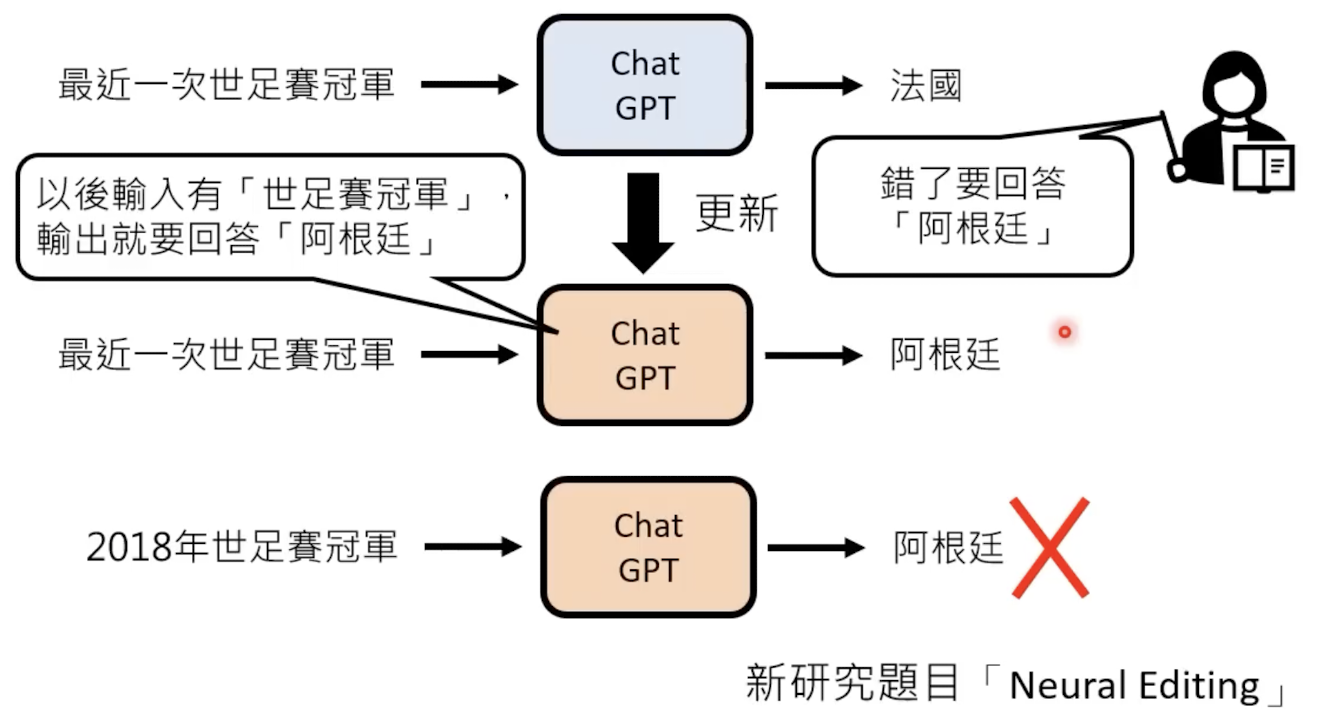
1.5 更新参数
可以通过对话改变其记忆:
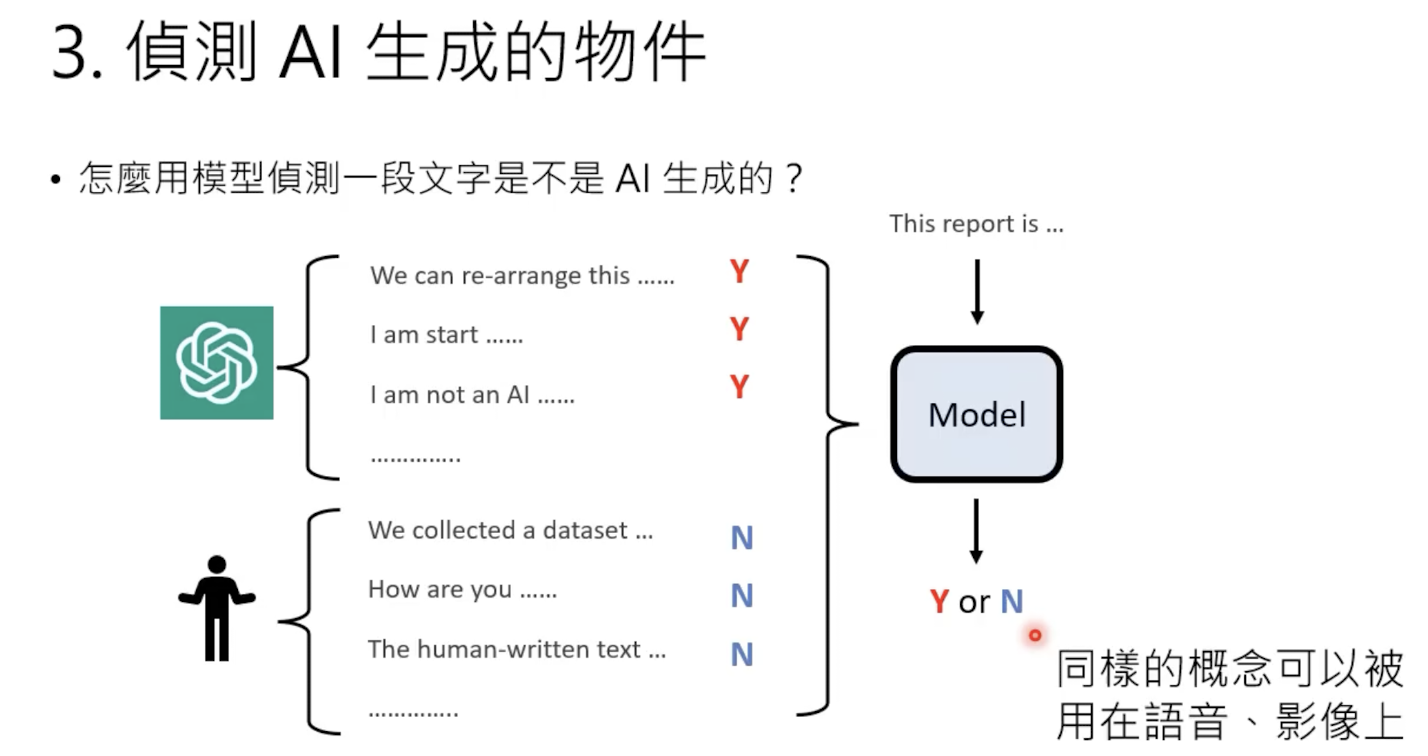
1.6 AI内容检测
检测某一段文字是否为AI生成的,最简单的做法是这样:
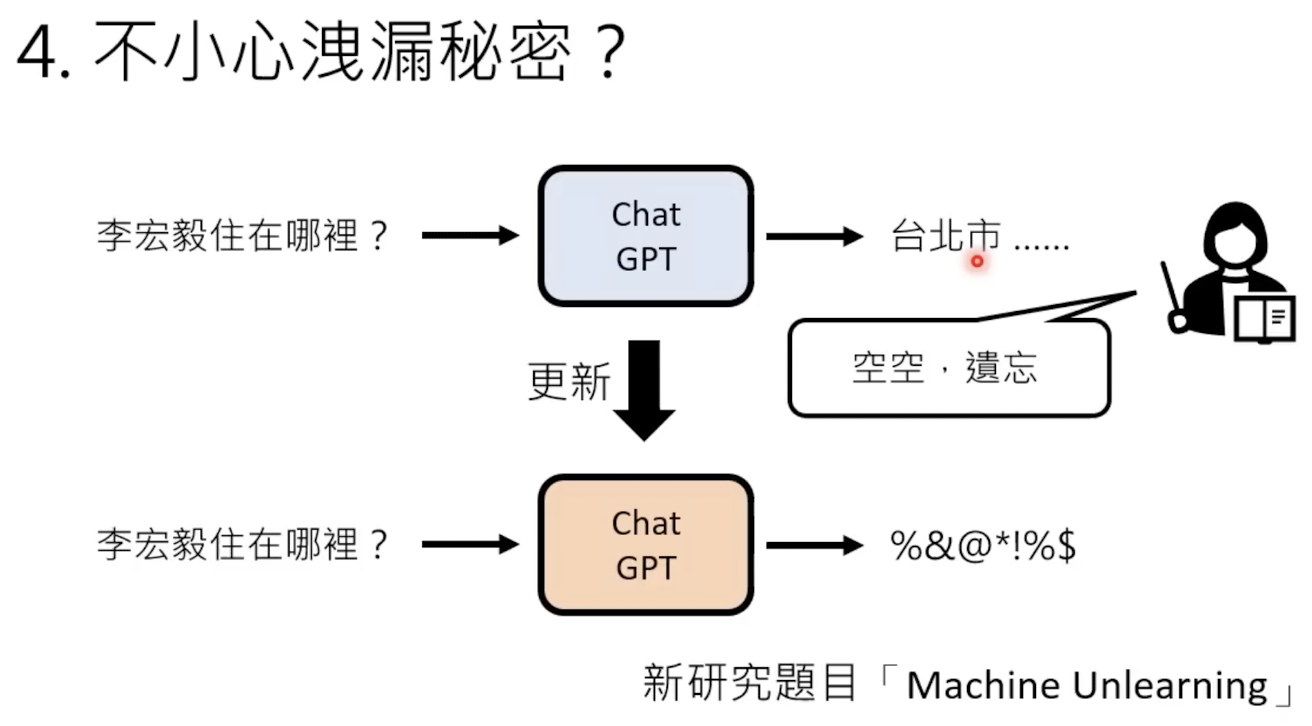
1.7 保护隐私
有时候模型会泄漏训练数据,需要遗忘学习:
1.8 gpt和bert
一个是做文字接龙,一个是做文字填空:

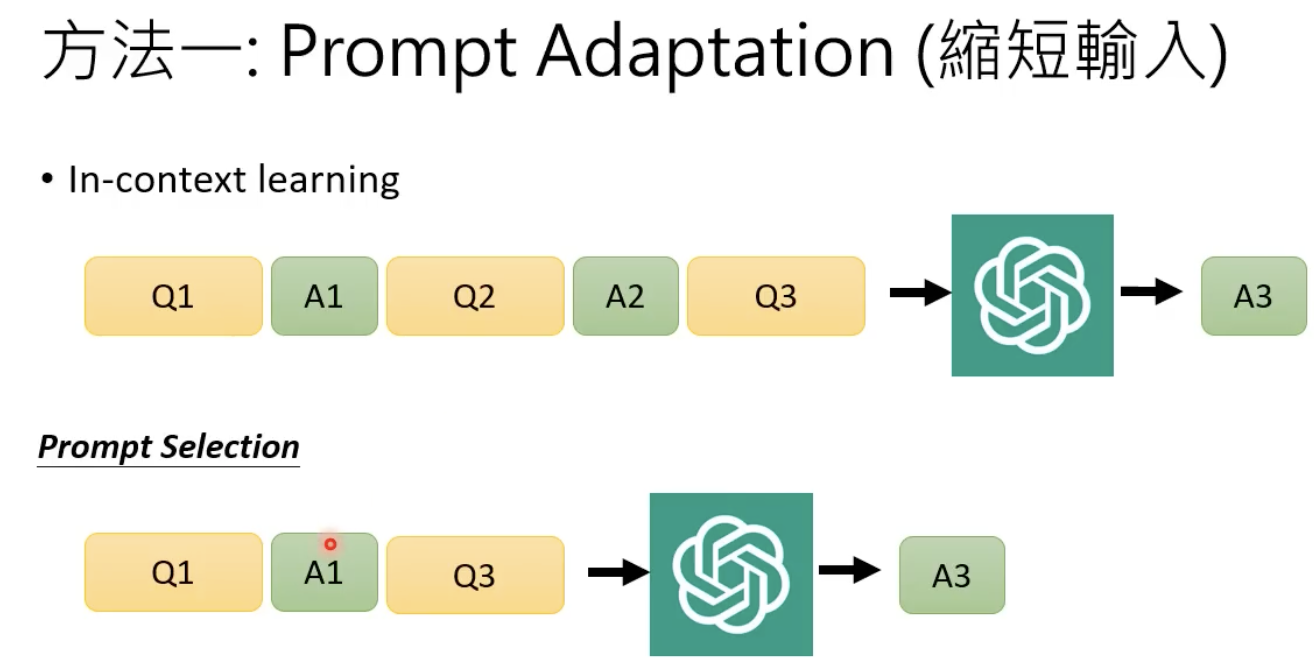
穷人怎么用gpt
方法1 缩短输入
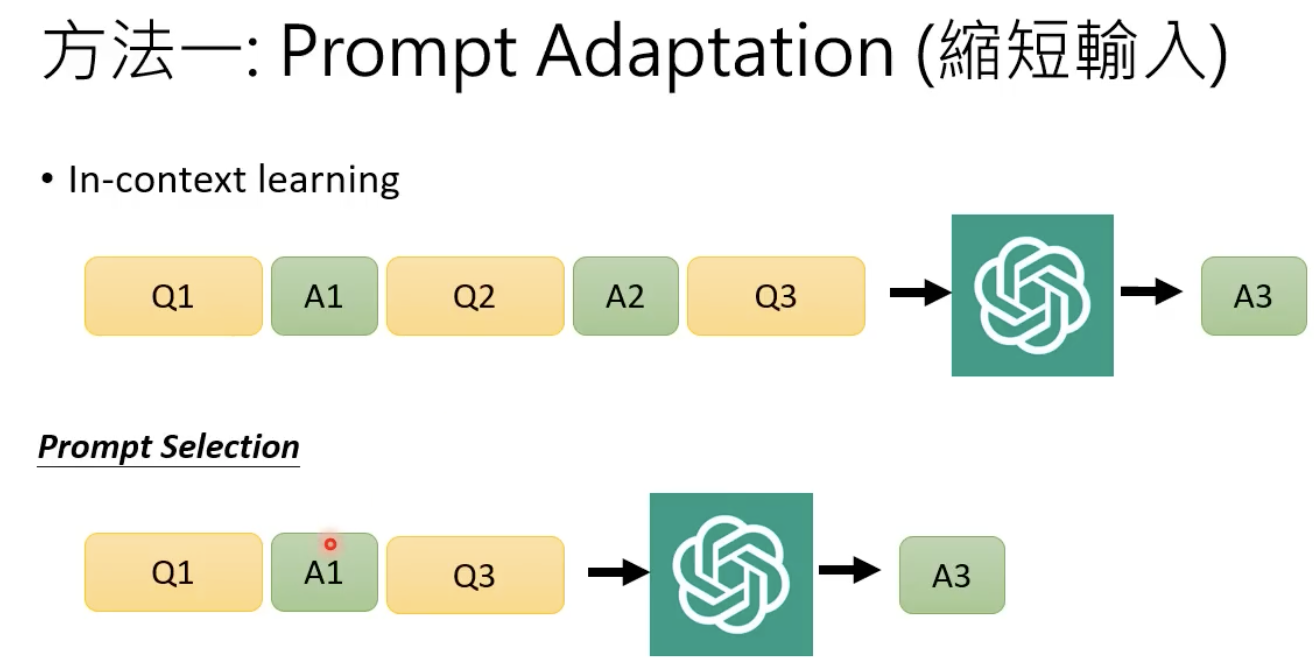
把多个问题一起丢进去:
方法2 自建模型
方法3 LLM cascade
2 生成式模型
主要分为以下三种,注意英文的token指的不是单个完整的单词,而是要把一个单词拆分成前缀后缀的形式,拆解成更小的单位:
2.1 生成方式
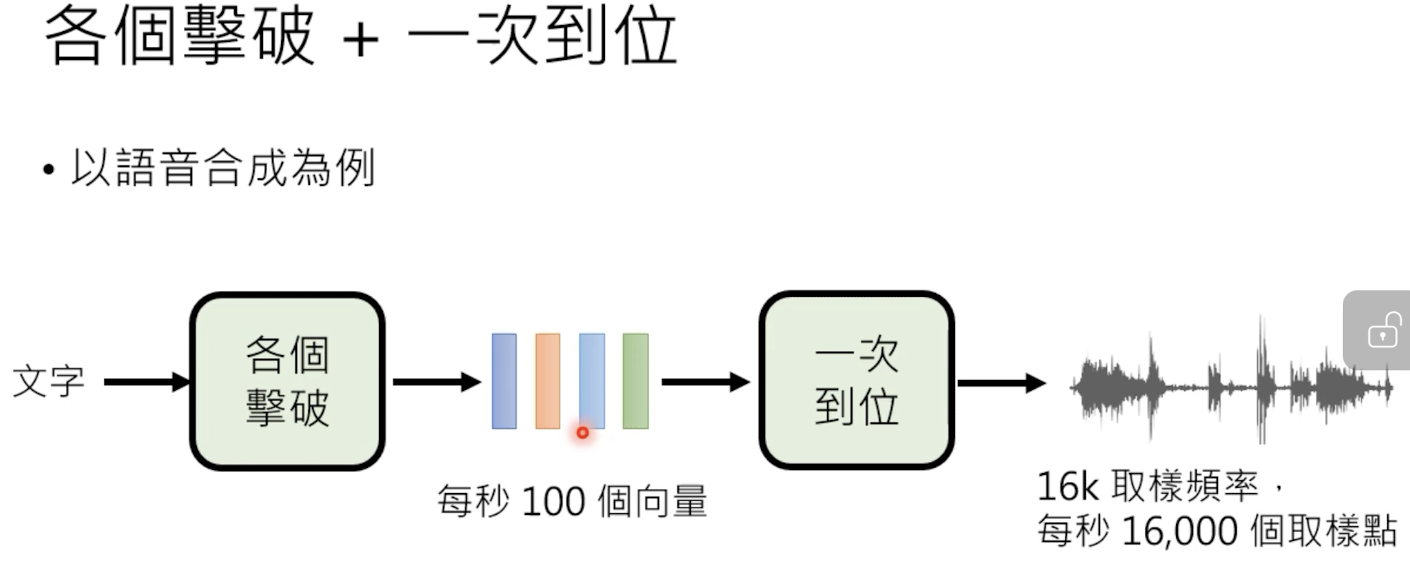
生成式有两种策略——各个击破和一次到位,下面先介绍各个击破
2.1.1 各个击破 Autoregressive
每次生成一个(token),然后按照序列形式把全部完整的内容生成:
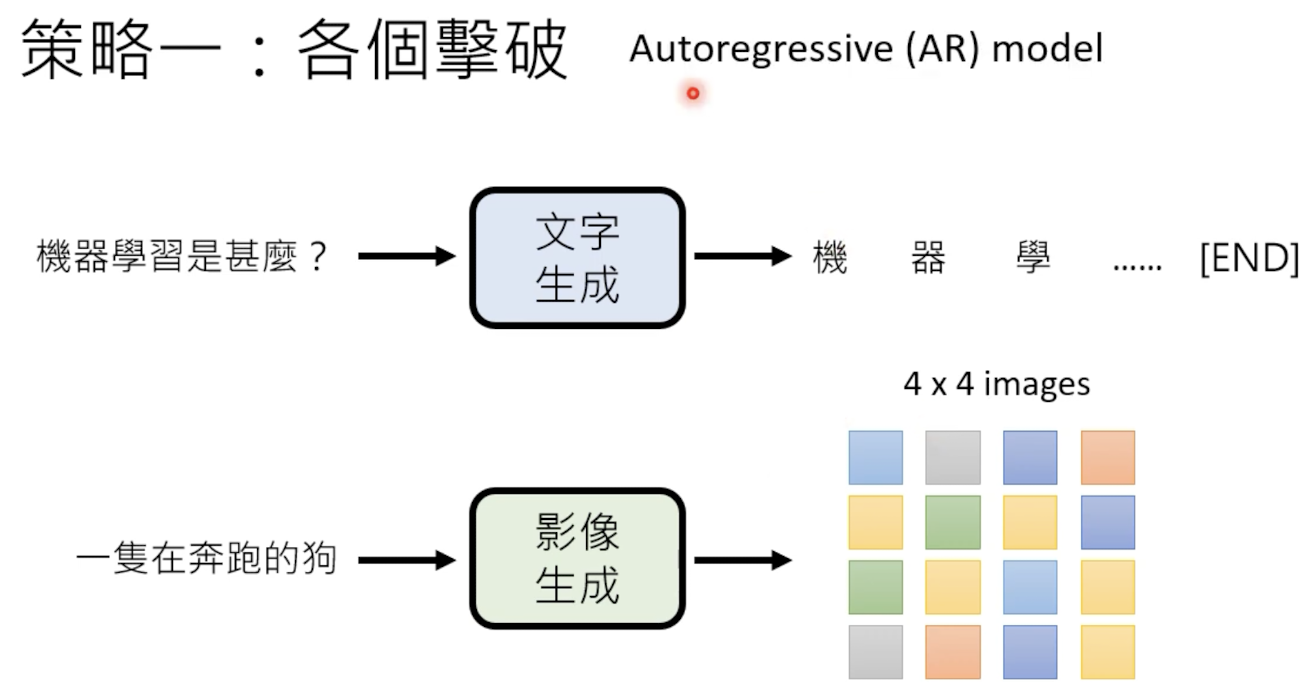
这种方式生成效果好,但是所需要的时间长。%
2.1.2 一次到位 Non-autoregressive
x需要先设定最大输出长度,由于不需要每次都保证输出的内容一样长,需要一个end标志符表示结束。
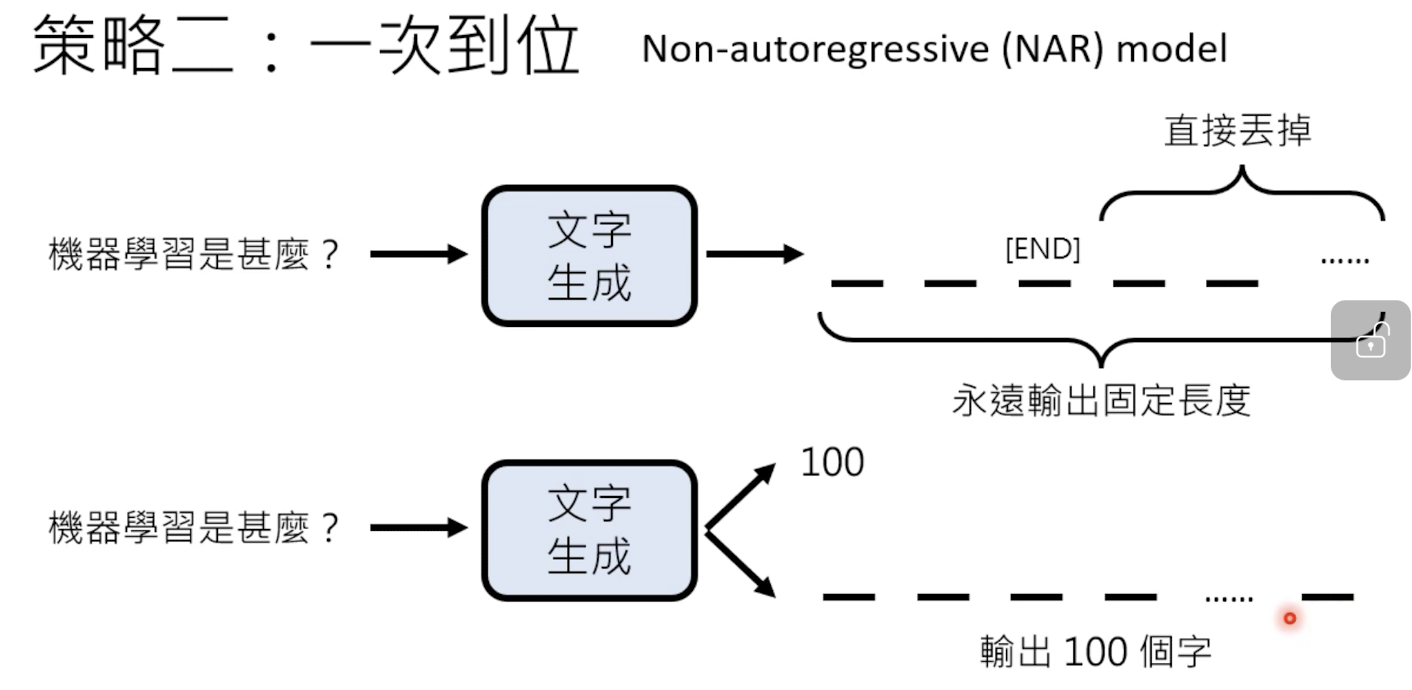
两者比较:
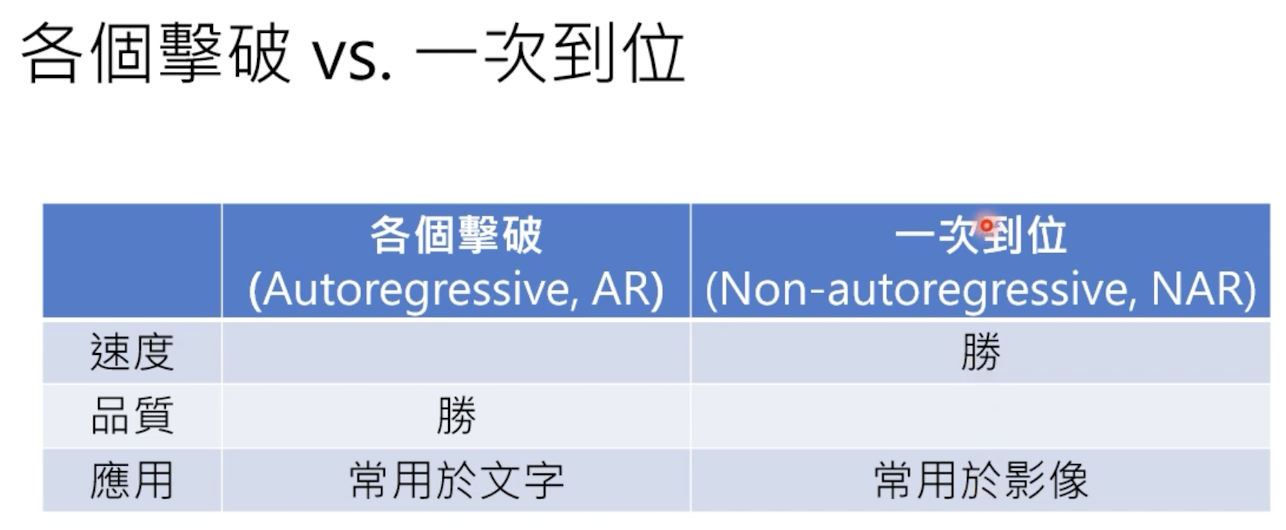
2.1.3 两者结合
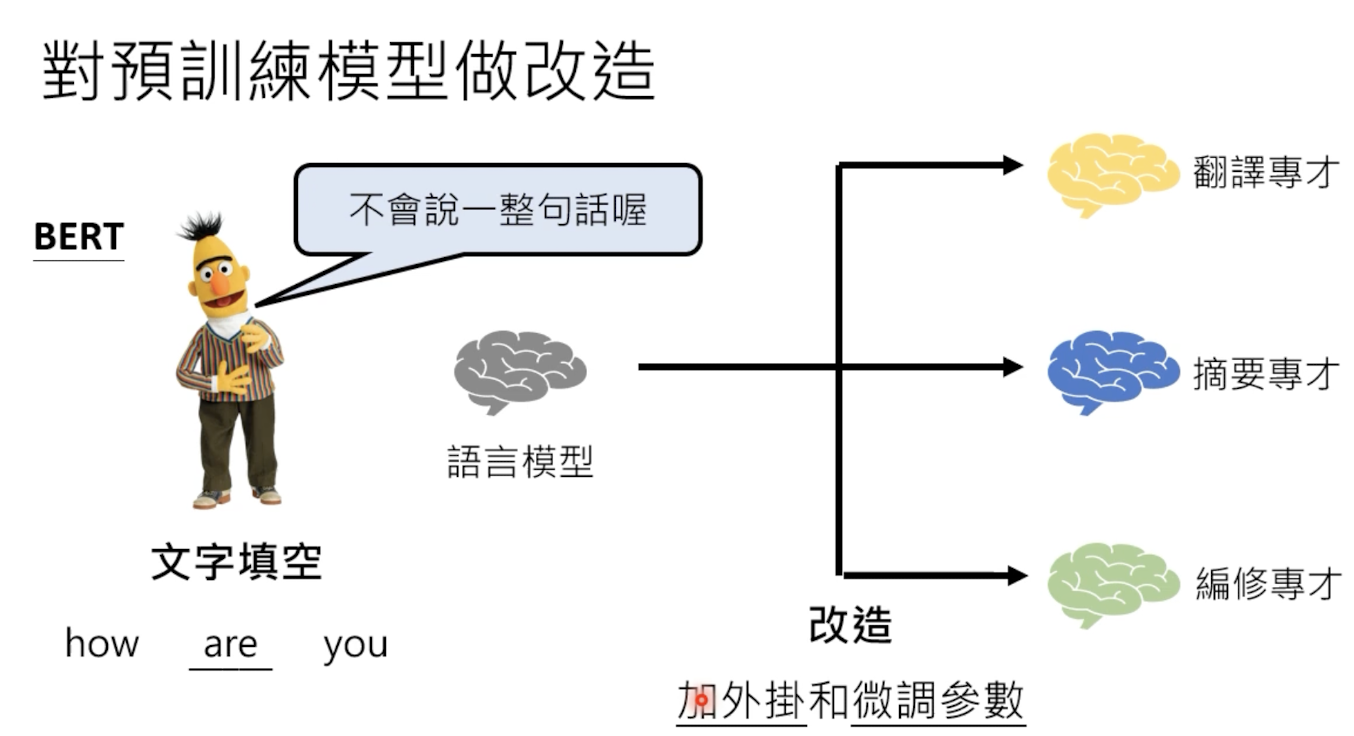
2.2 预训练和微调
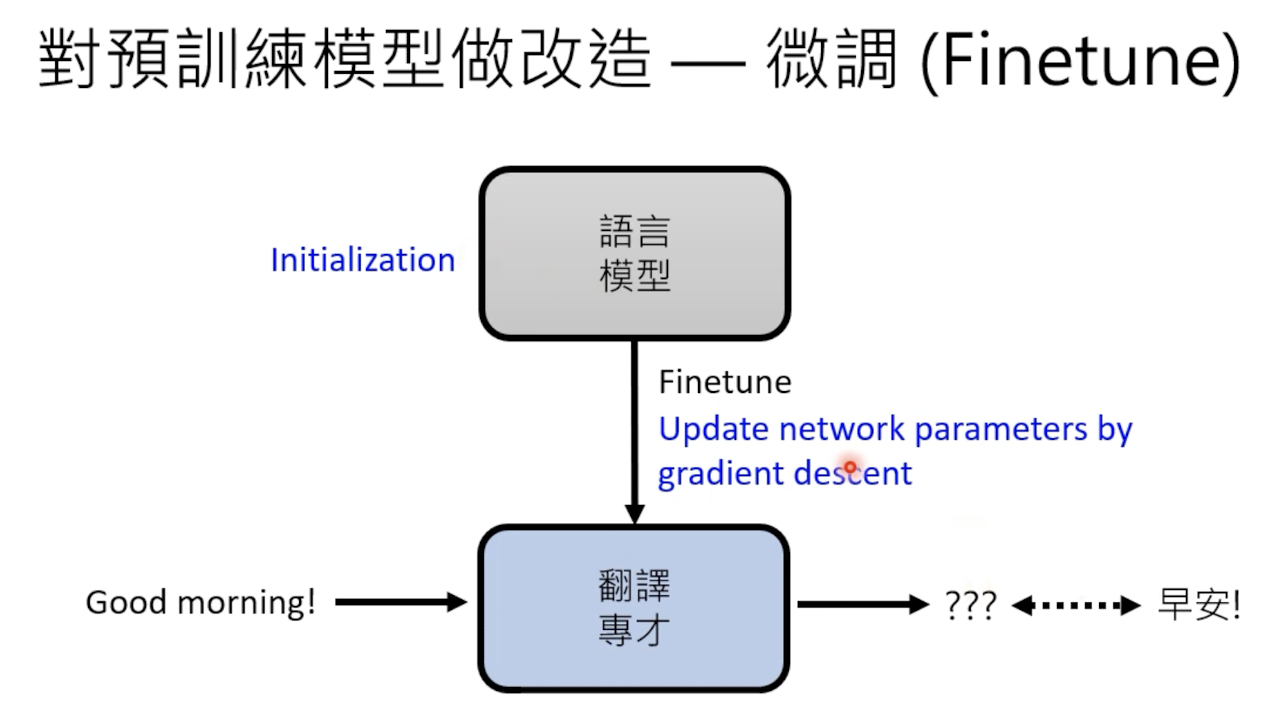
一般都是先训练一个通用模型,然后在某些任务上做微调(finetune)。
2.3 指示学习 instruction learning 和 上下文学习 in-context learning
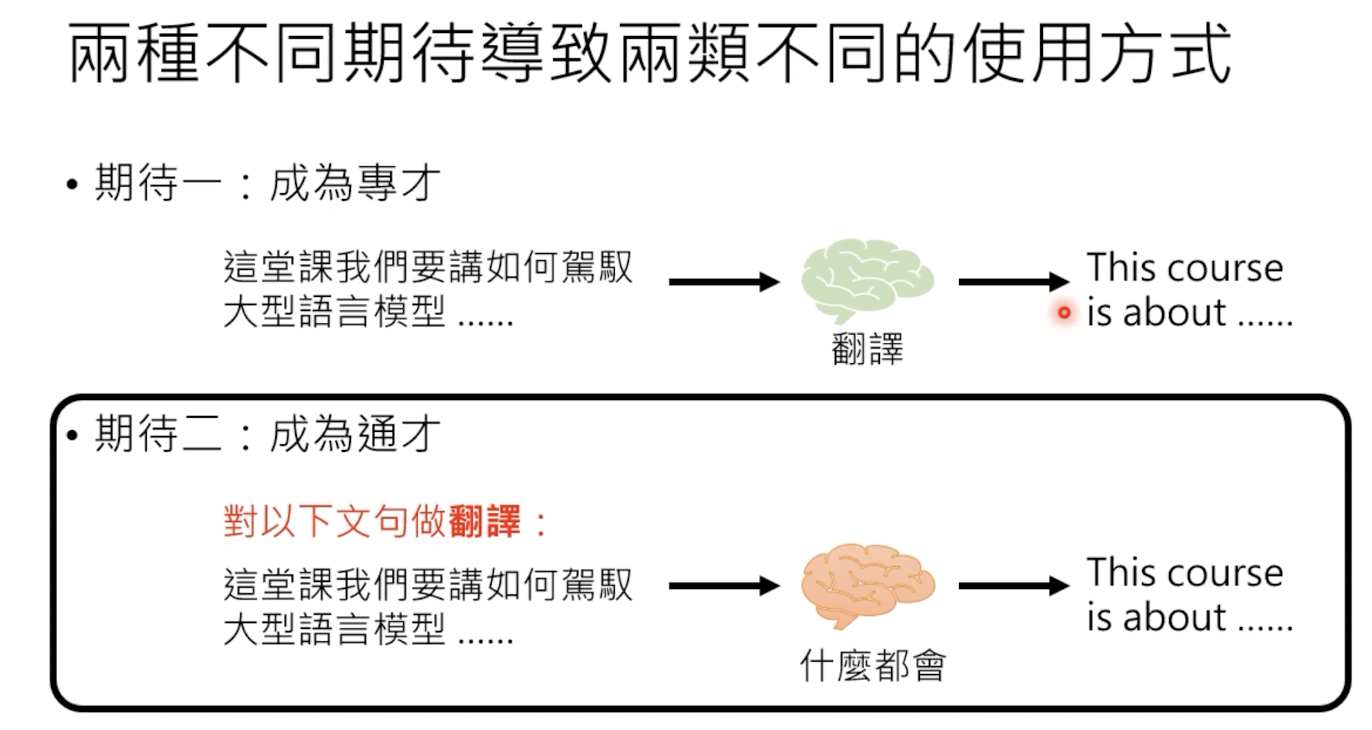
和chatgpt进行交互的时候,我们的promt可能包可以分为两种情况:指示学习 instruction learning 和 上下文学习 in-context learning。所以在模型训练阶段,我们需要制造一些成对的语料数据加强模型的这两种学习的能力。

前者是给模型一些指示,当模型进行学习和回答,后者是通过一些例子,让模型进行学习和回答。
2.2.1 上下文学习 in-context learning
即让机器在例子中进行学习。为got提供一些例子,比如情感分析中:
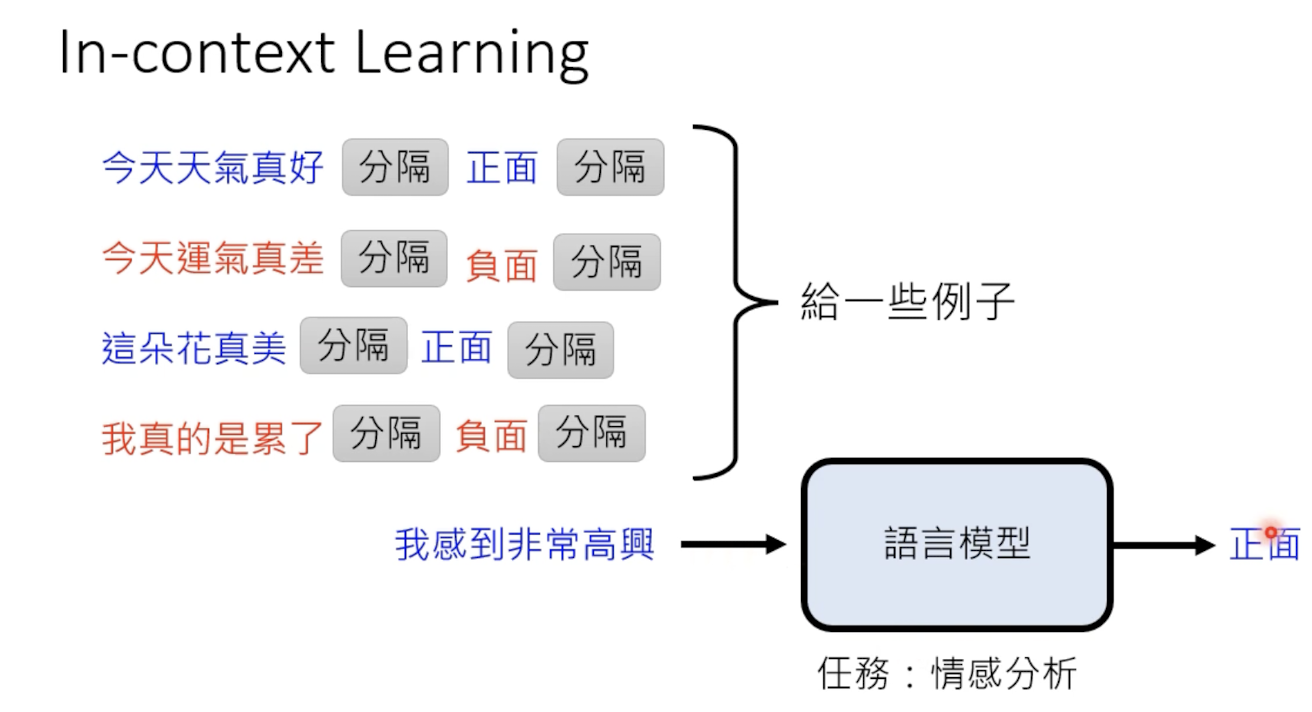
但是不同于传统的模型更新(梯度下降),这里gpt的学习,不会更改其模型参数。
通过例子,虽然不会提升多少情感分析的能力,而是为了唤醒gpt的情感分析能力,这个结果来自一篇文献的实验结论。
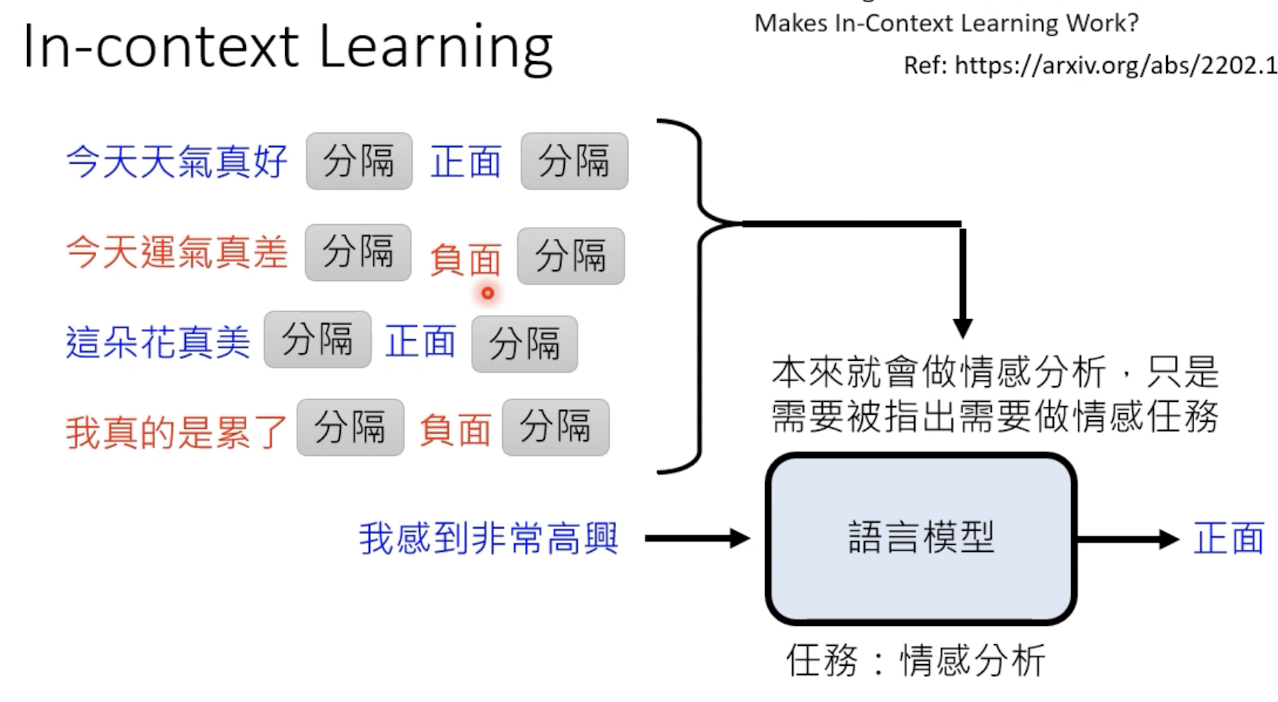
2.2.2 指示学习 instruction learning
让gpt能够看懂指令:
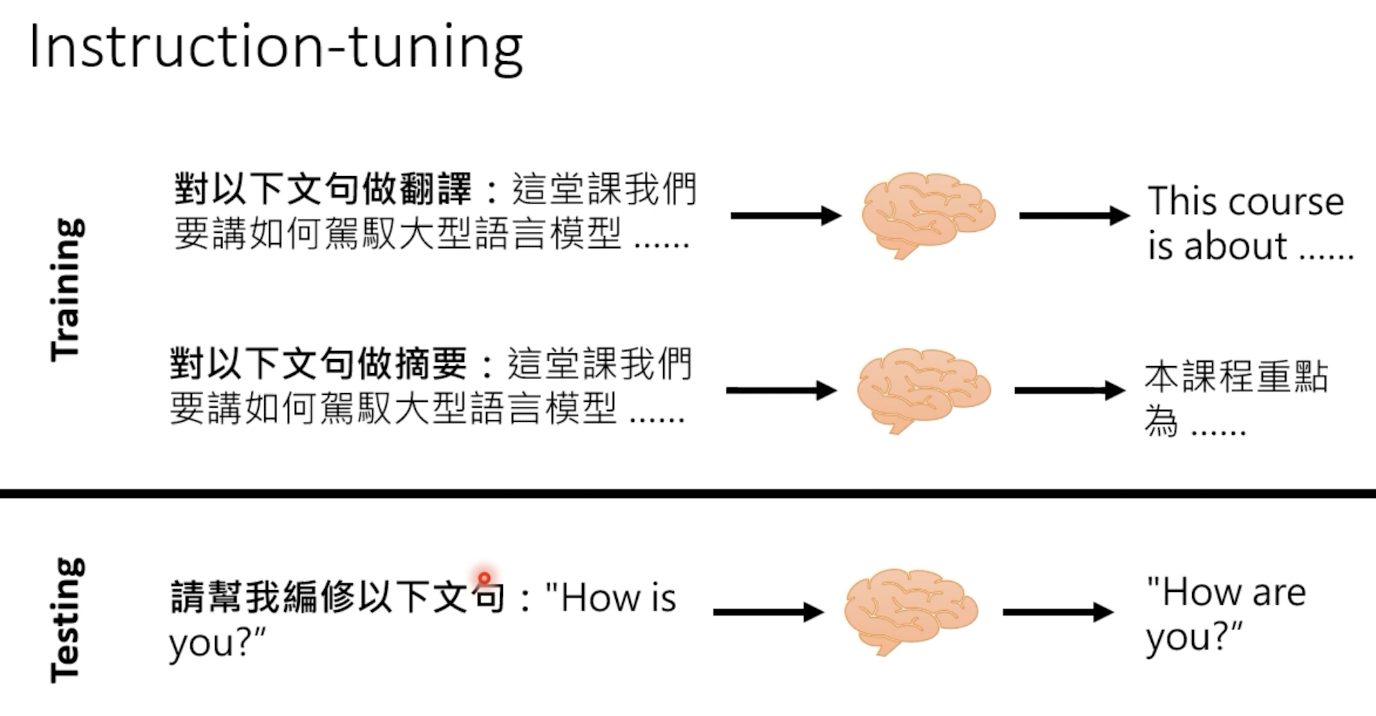
一个指示学习的例子:判断这句话的情感:给女朋友买了这个项链,她很喜欢。选项:A=好;B=一般;C=差。
训练阶段和测试阶段,可以是不同的任务的指示。
用人类的语言训练:
2.2.3 chain of thought (CoT) prompting
让模型给出推理过程,这样能够让模型做出更正确的答案。

让模型具备这个能力,就得在模型训练阶段给出这样的“带有推理过程”的语料。

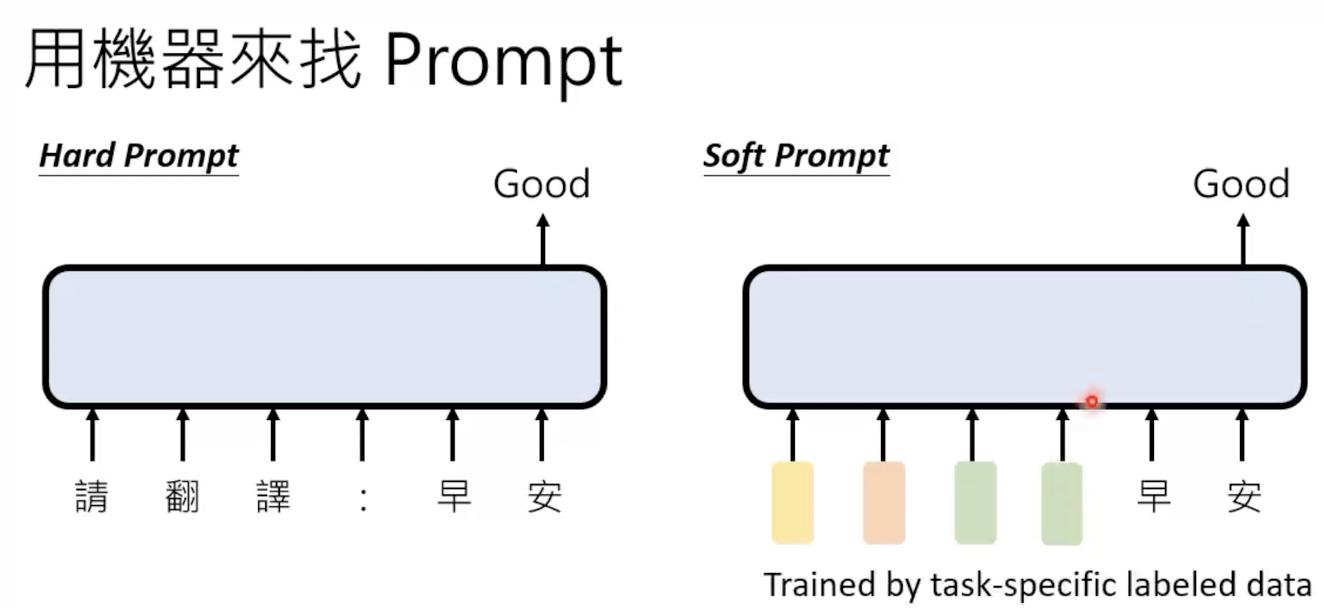
让模型自动生成prompt
这里的promt也可以理解为指令。
1。 使用 soft prompt
之前我们讲的都是hard prompt,但其实还有soft prompt,给一堆向量而不是人类语言。
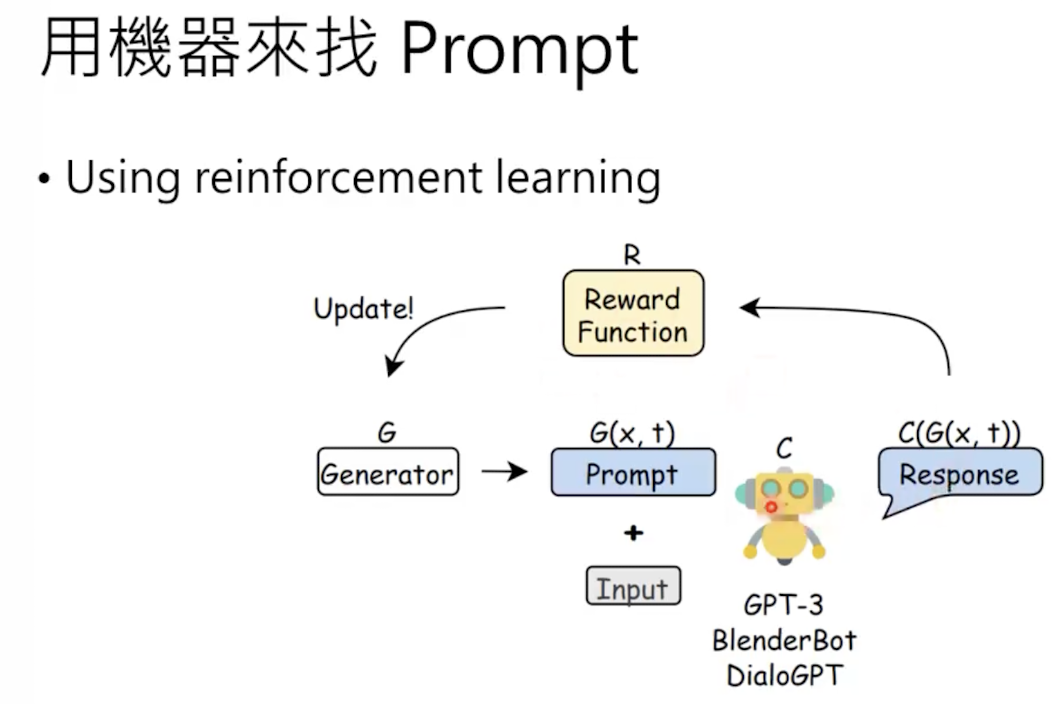
2. 使用强化学习。
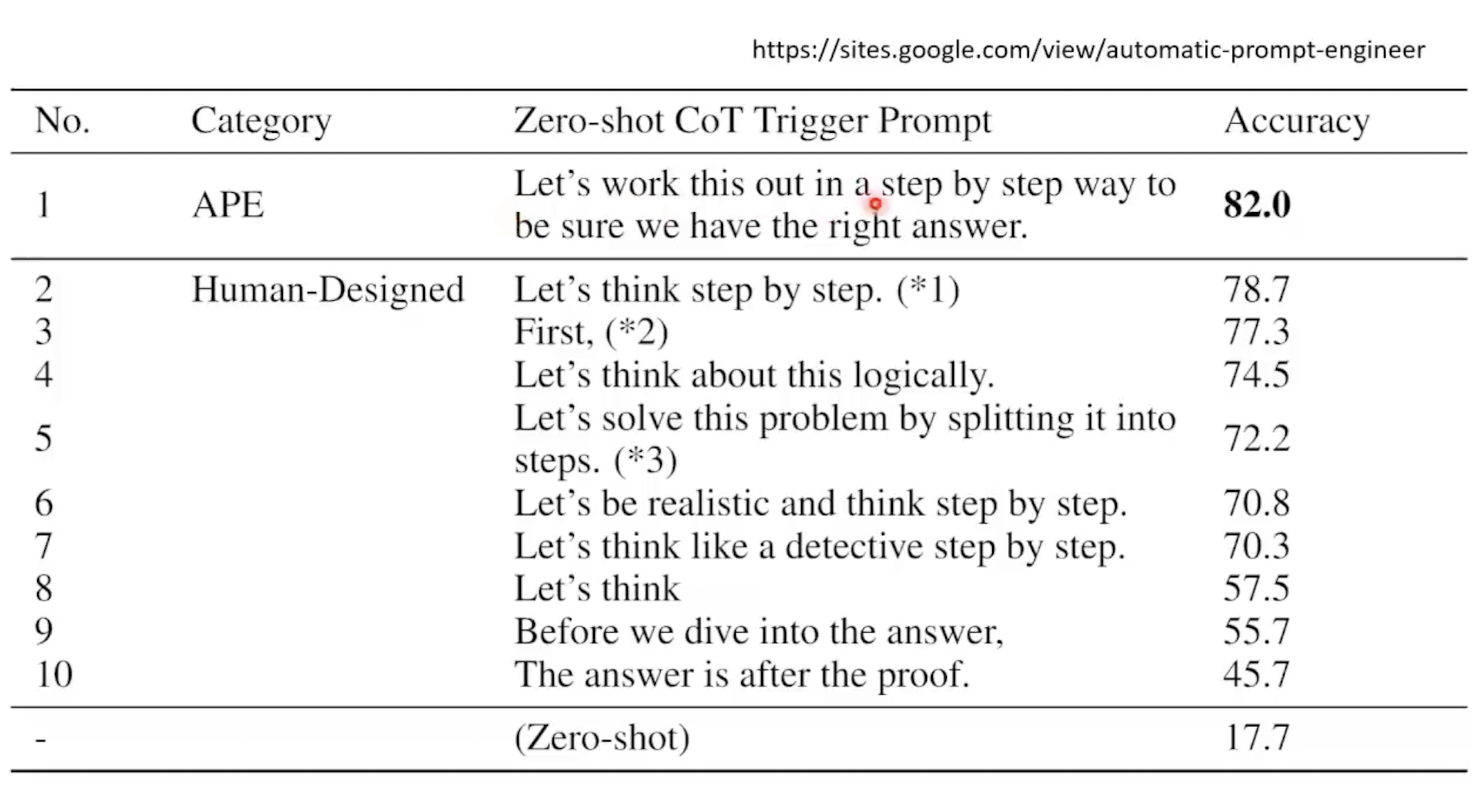
3. 让模型自己寻找,下一些特殊指令:

最佳指令可以极大的提升模型的性能:
2.3 训练数据的预处理
数据的收集和处理需要用到以下内容:
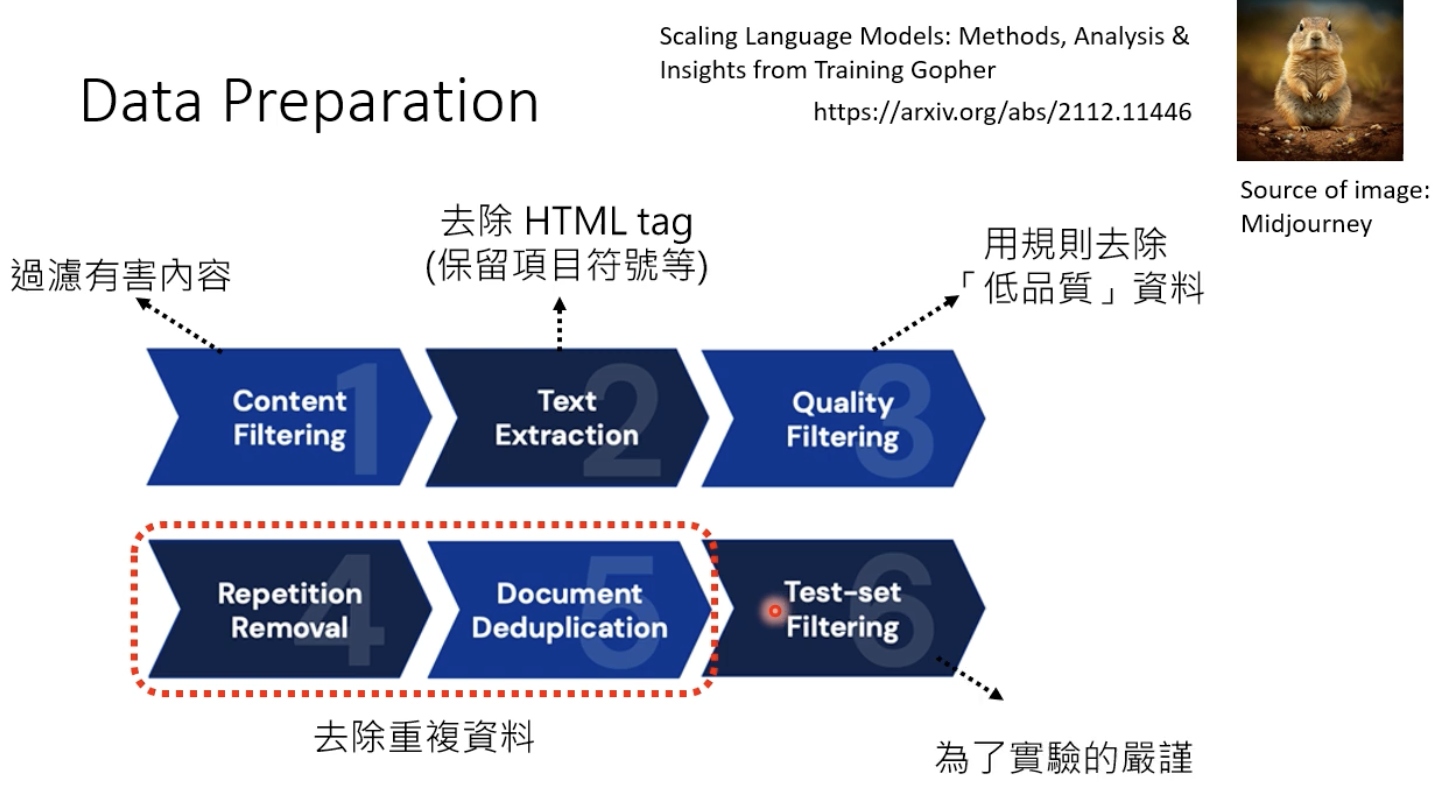
去掉重复资料的重要性:假设一段话在训练数据中出现了6w多次,会发现模型很容易说出这些话,因此应该避免这种情况。
在固定运算资源的情况下,如何选择模型规模和数据集规模?有人做了相关实验,一条线表示固定的运算资源情况下的结果,纵轴的越小越好:
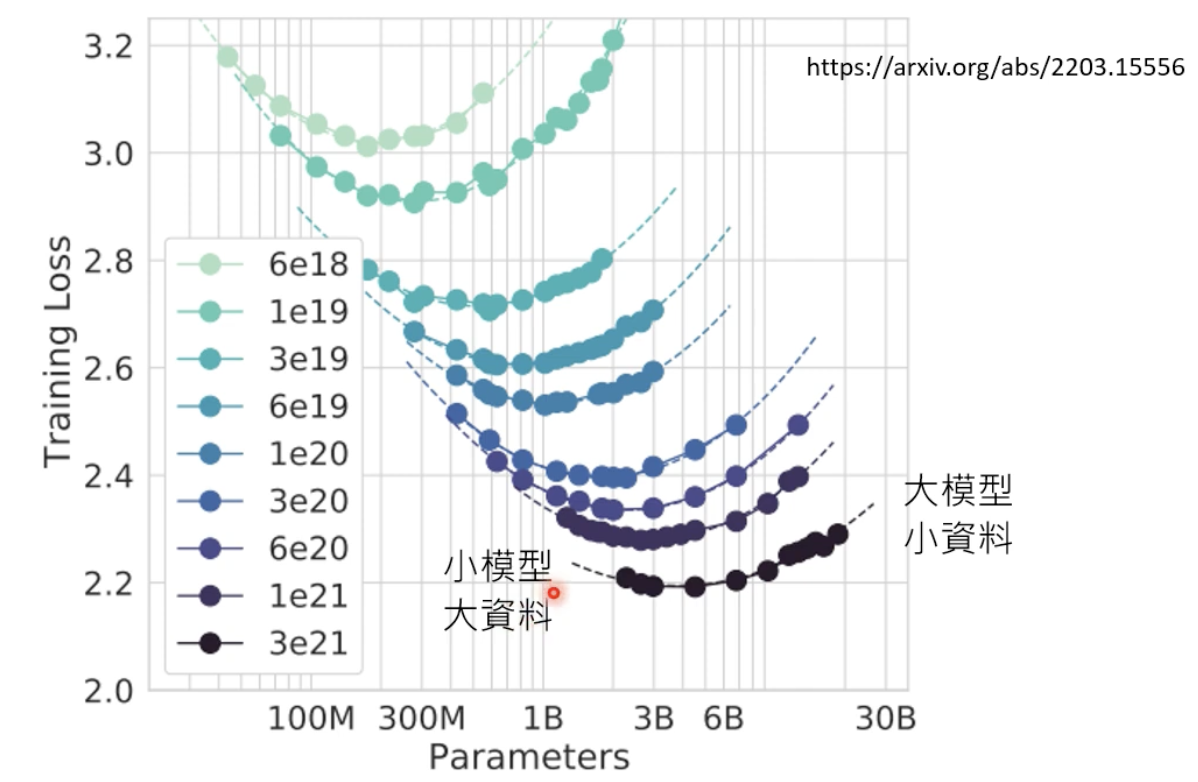
所以要找到每个U型曲线的最低点,把这些最低点串起来可以得到如下的图:
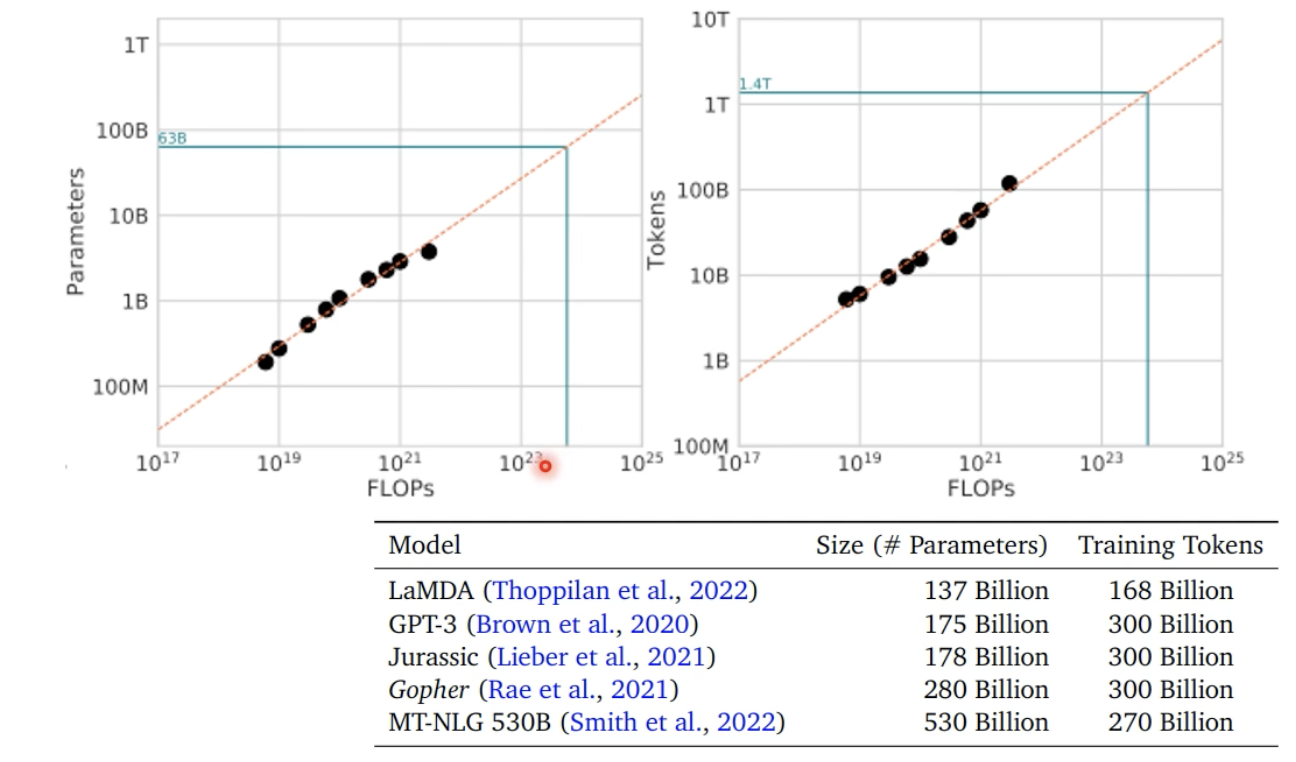
模型规模和资料最佳适配比:
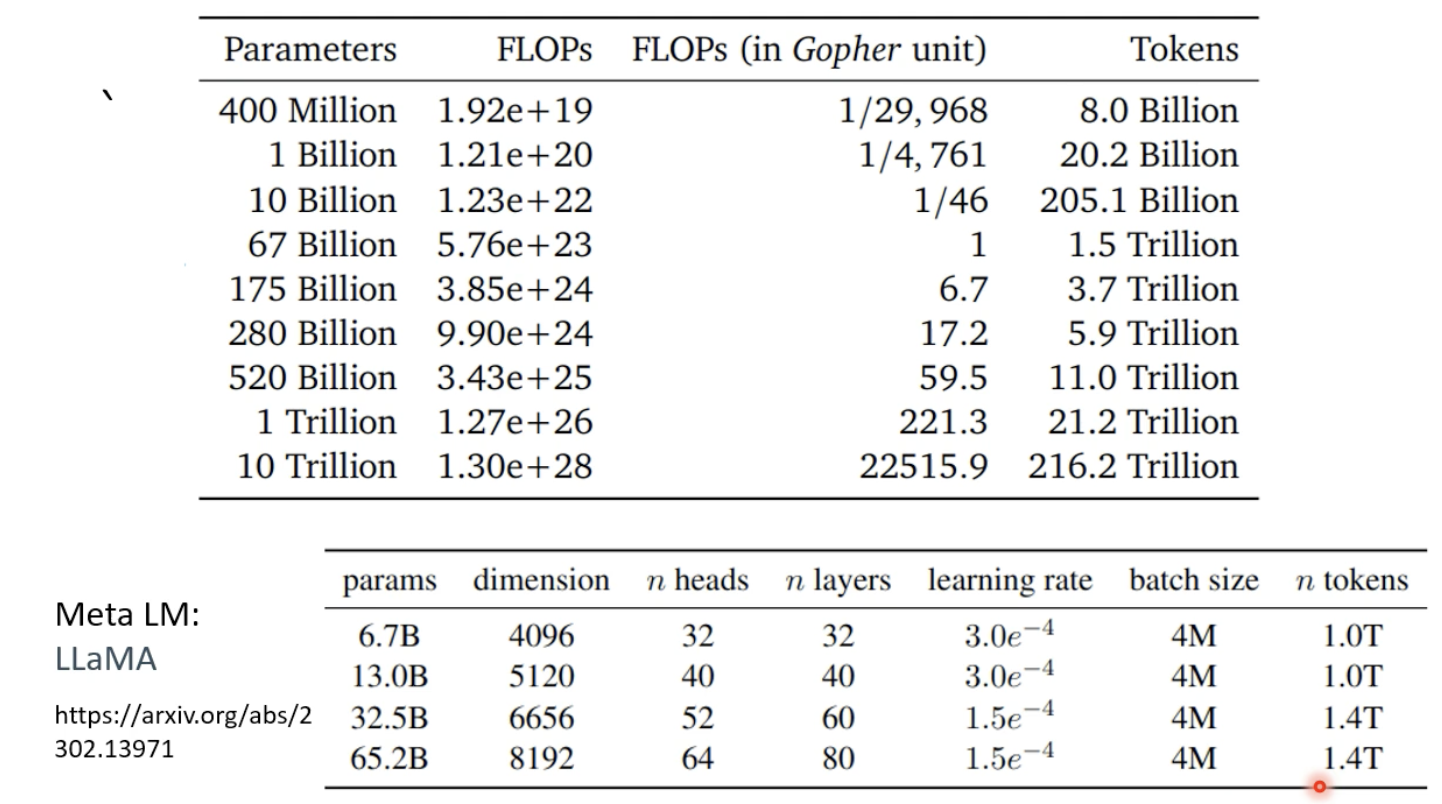
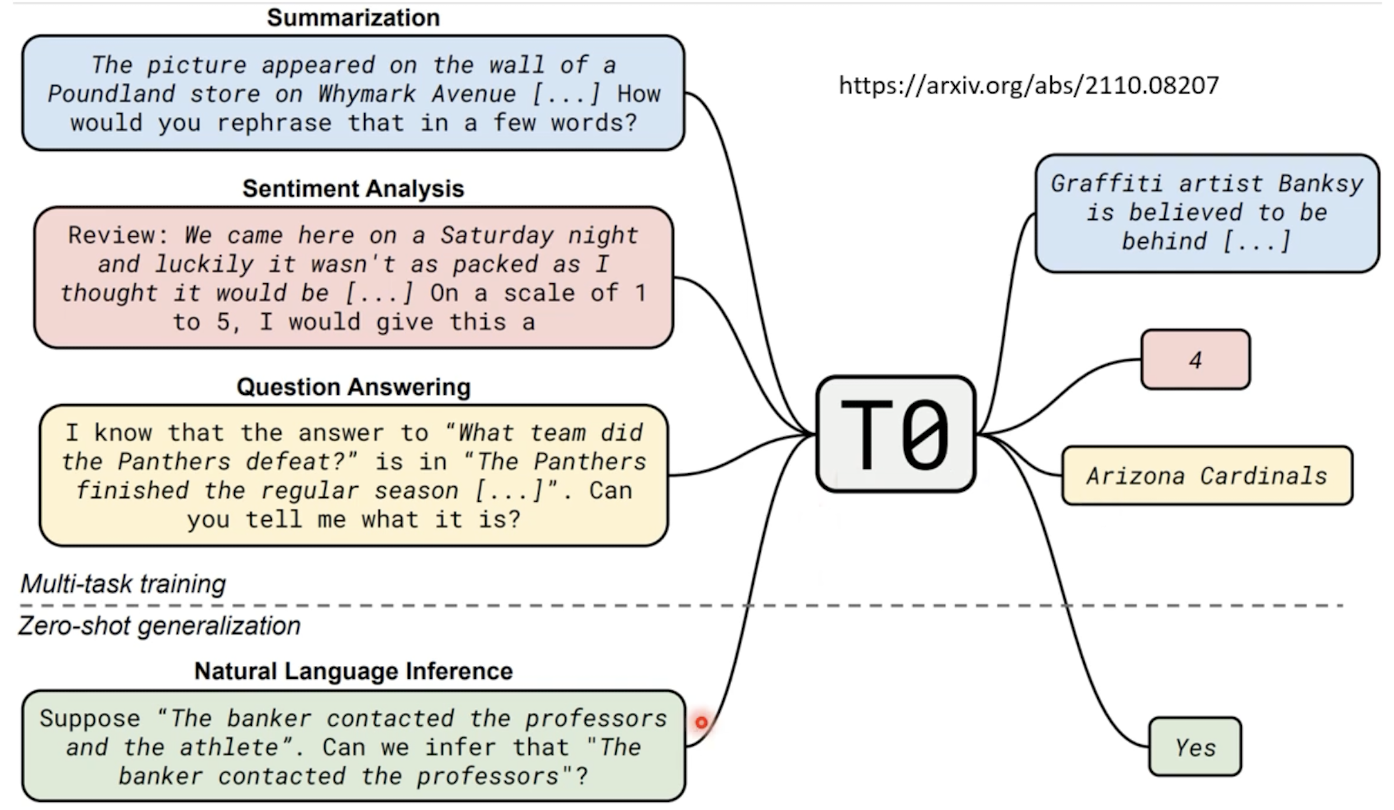
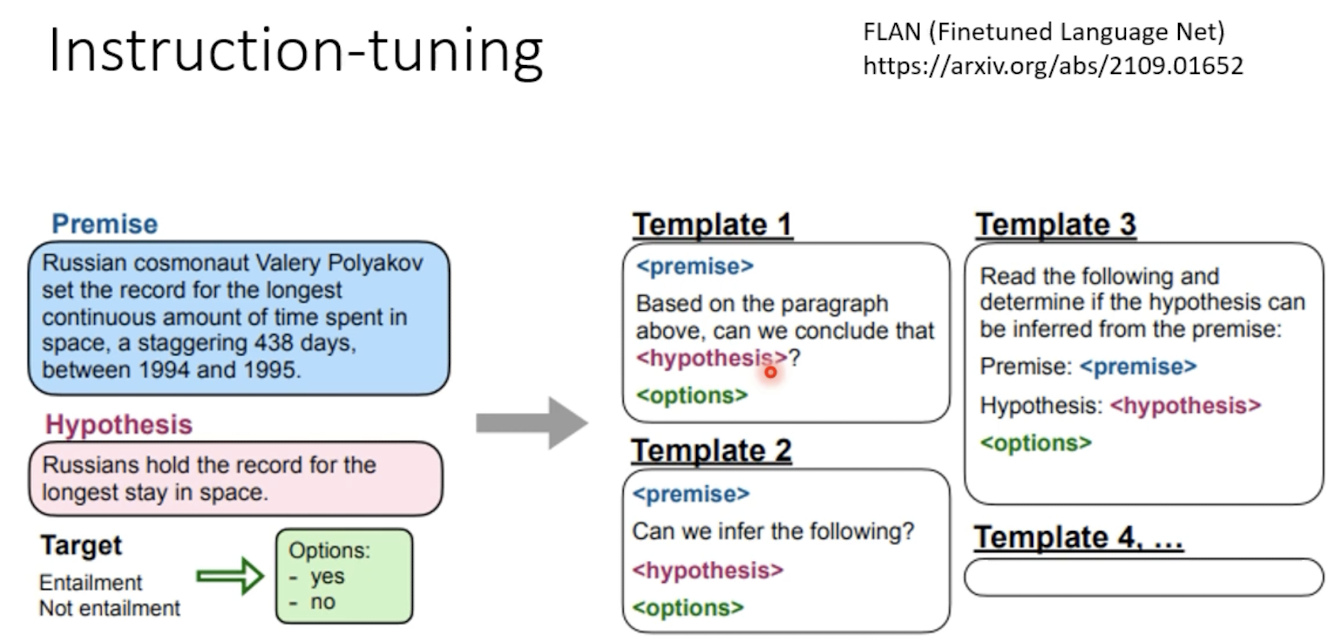
除此以外,指示学习(instruction-tuning)也可以大大提升模型的性能。
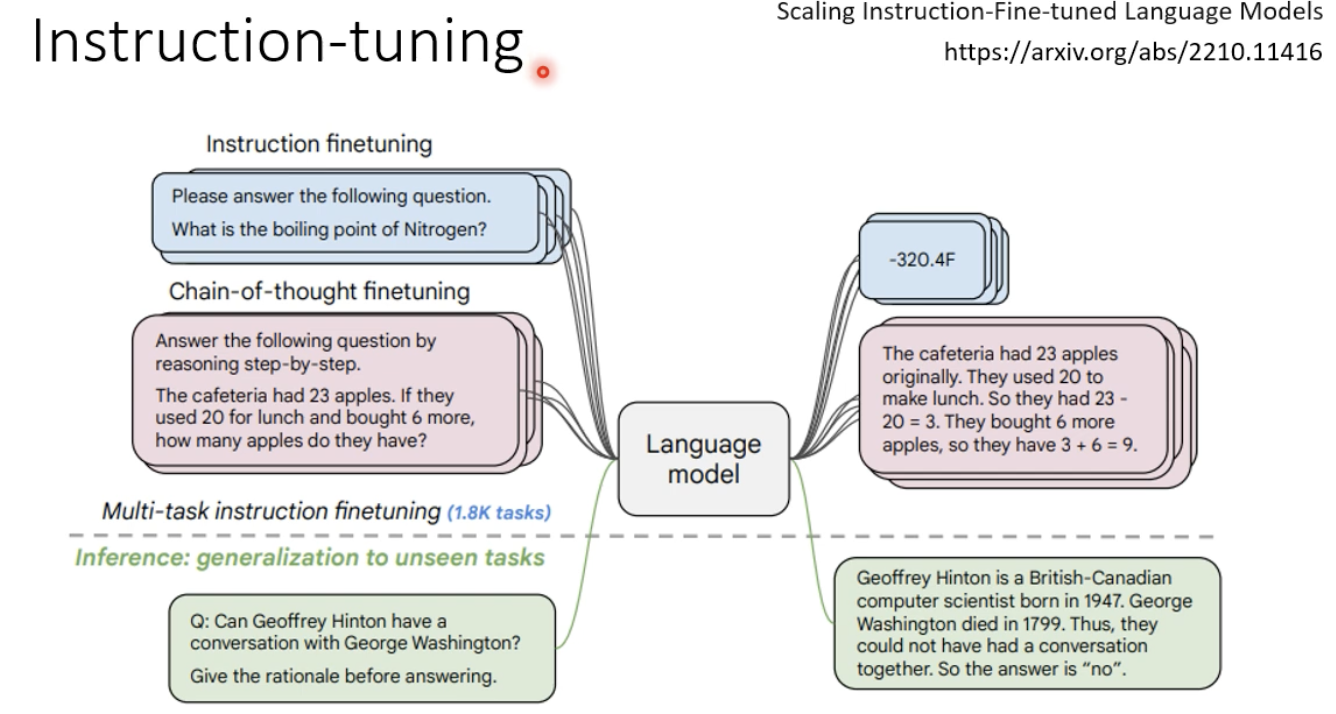
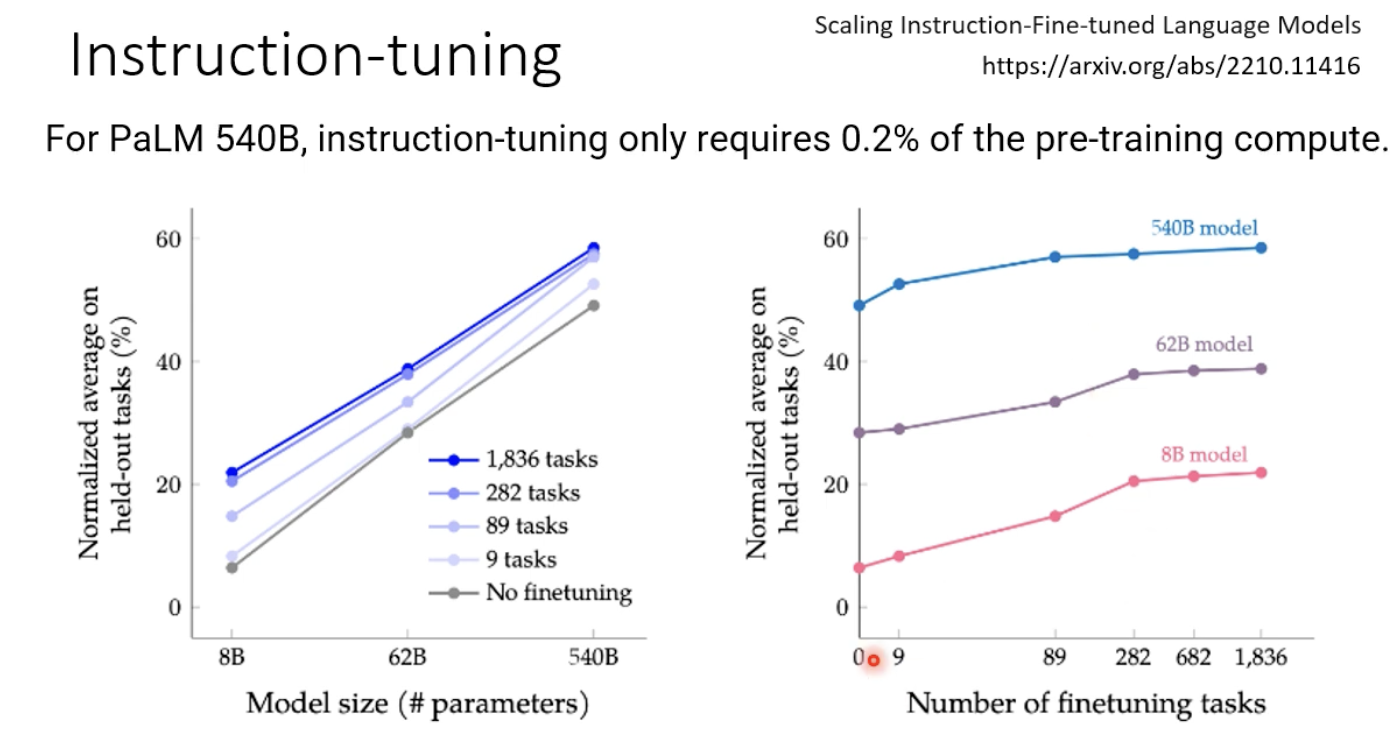
2.4 Human Teaching (强化学习)
这也是一种辅助模型训练的技术(强化学习),可以有效提高模型的性能,让小模型吊打大模型的性能。
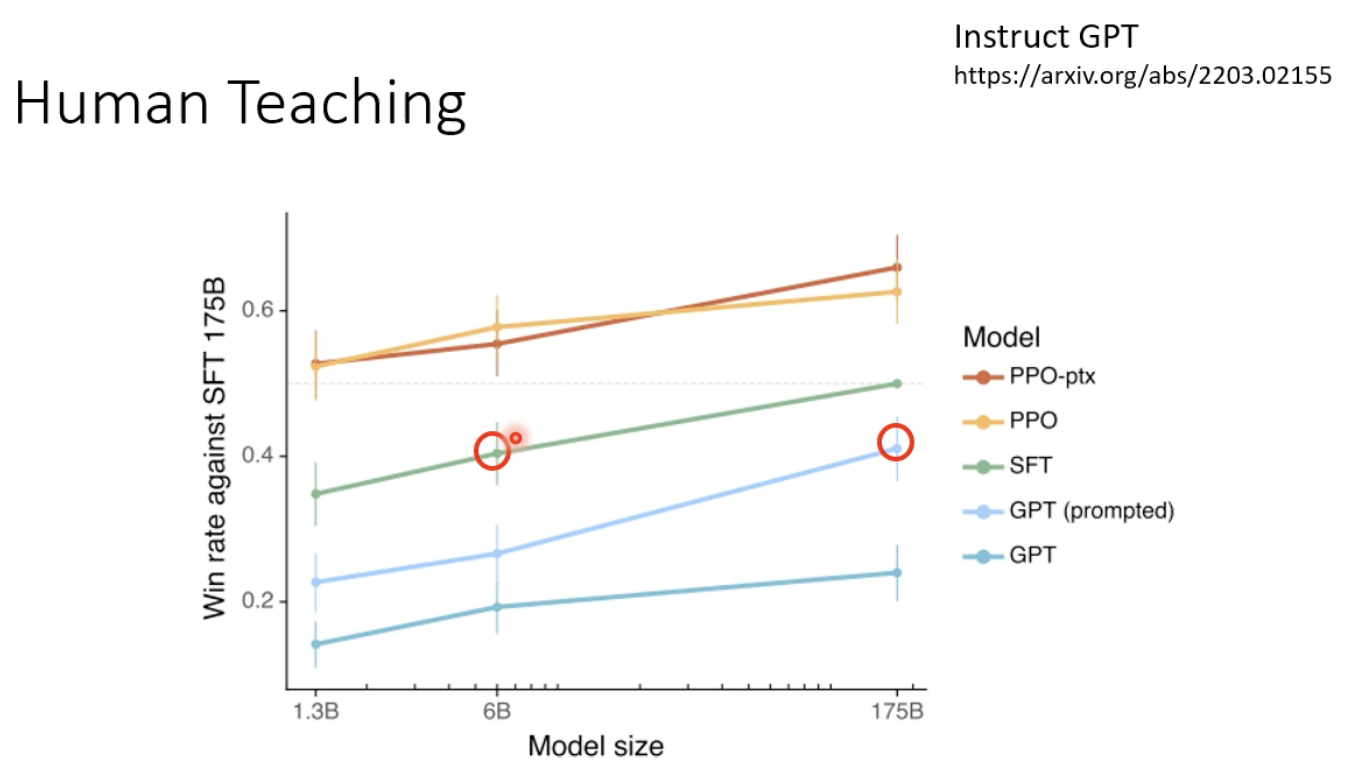
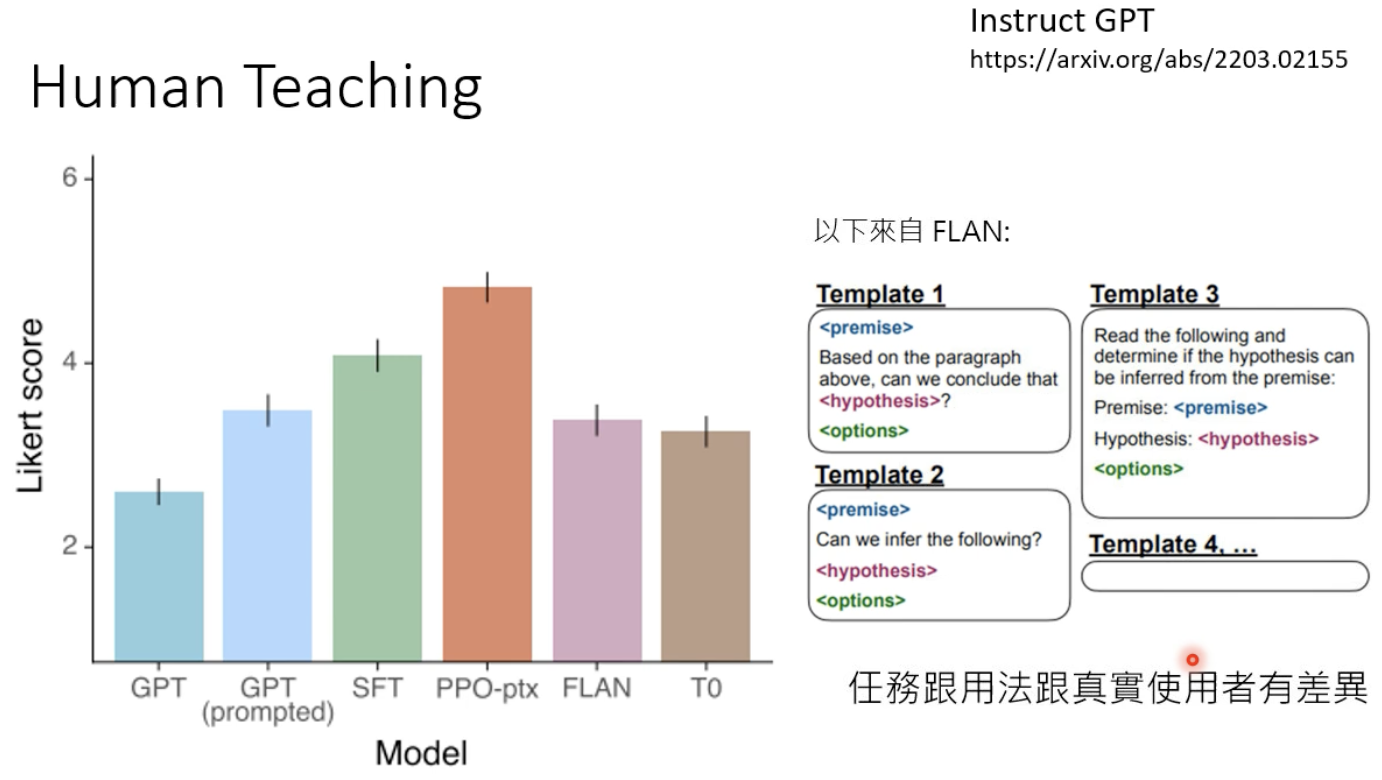
KNN+LM
一般的LM是这样的运作方式:
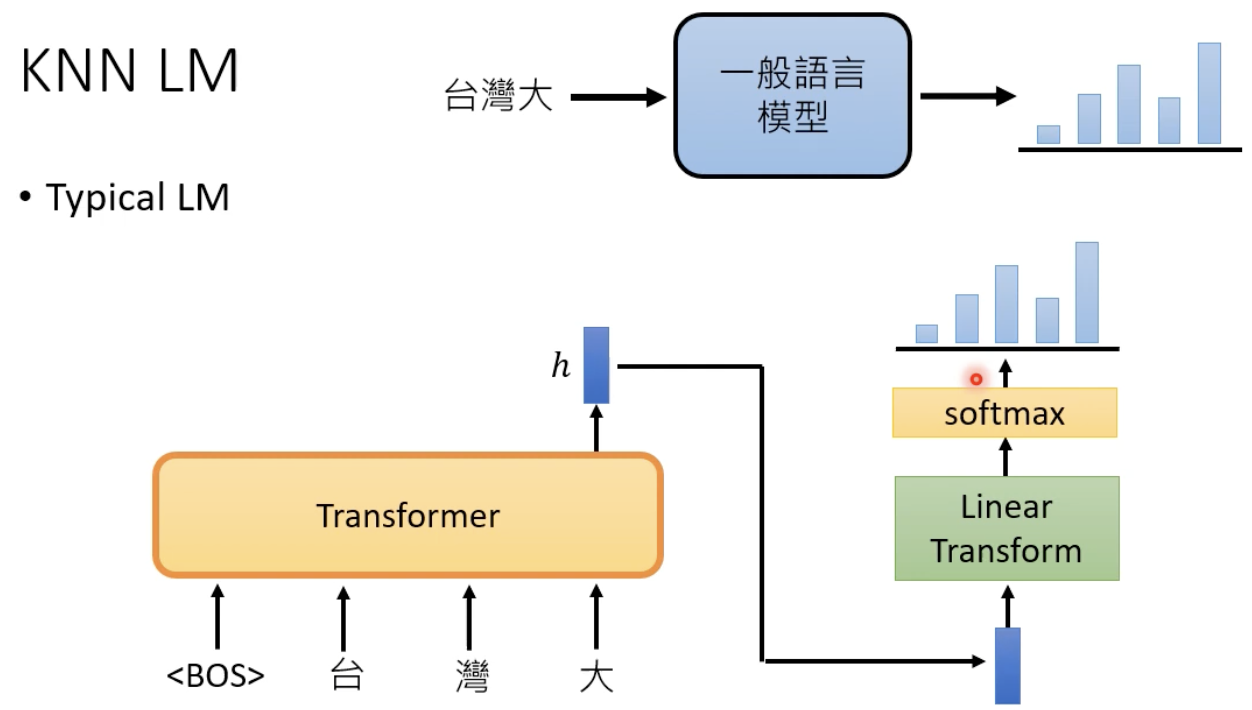
而KNN+LM是这样的,寻找embedding的相似度
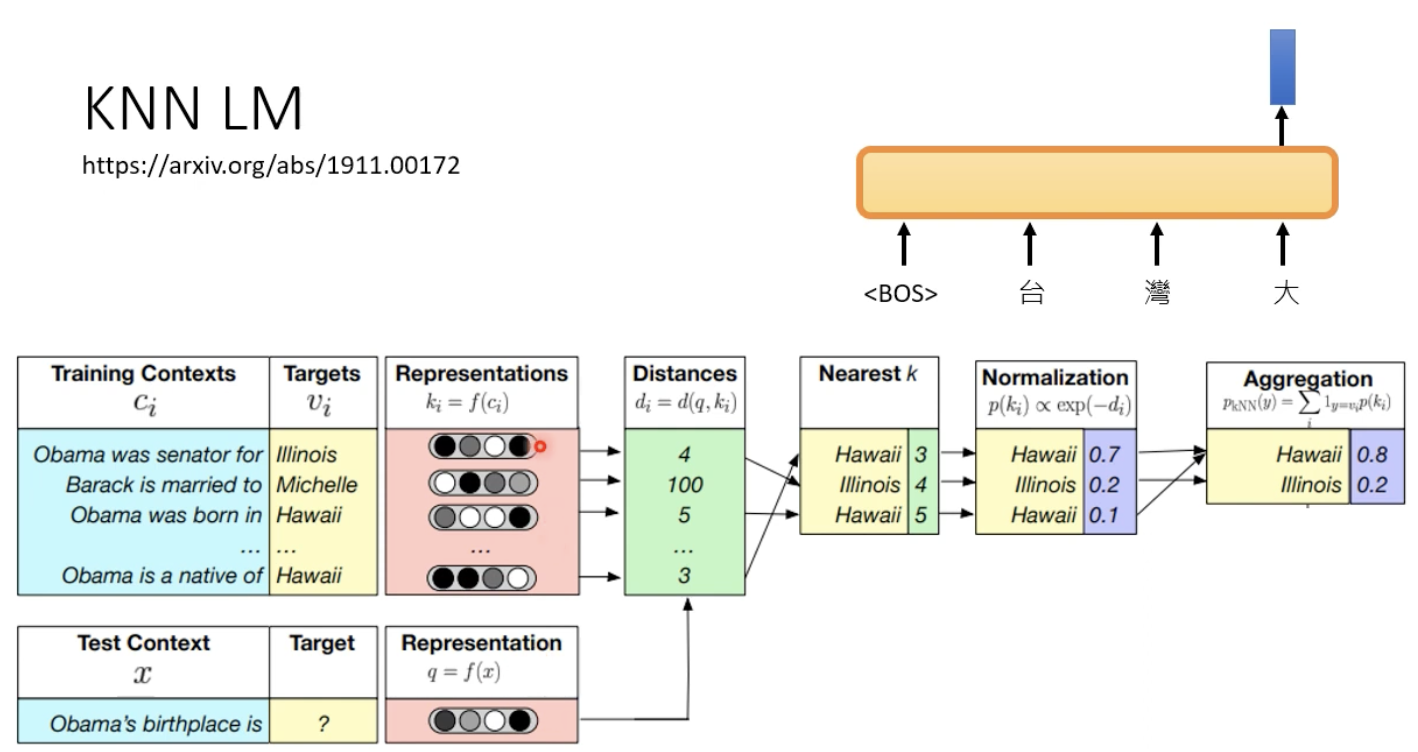
这样做会带来什么神奇的效果?
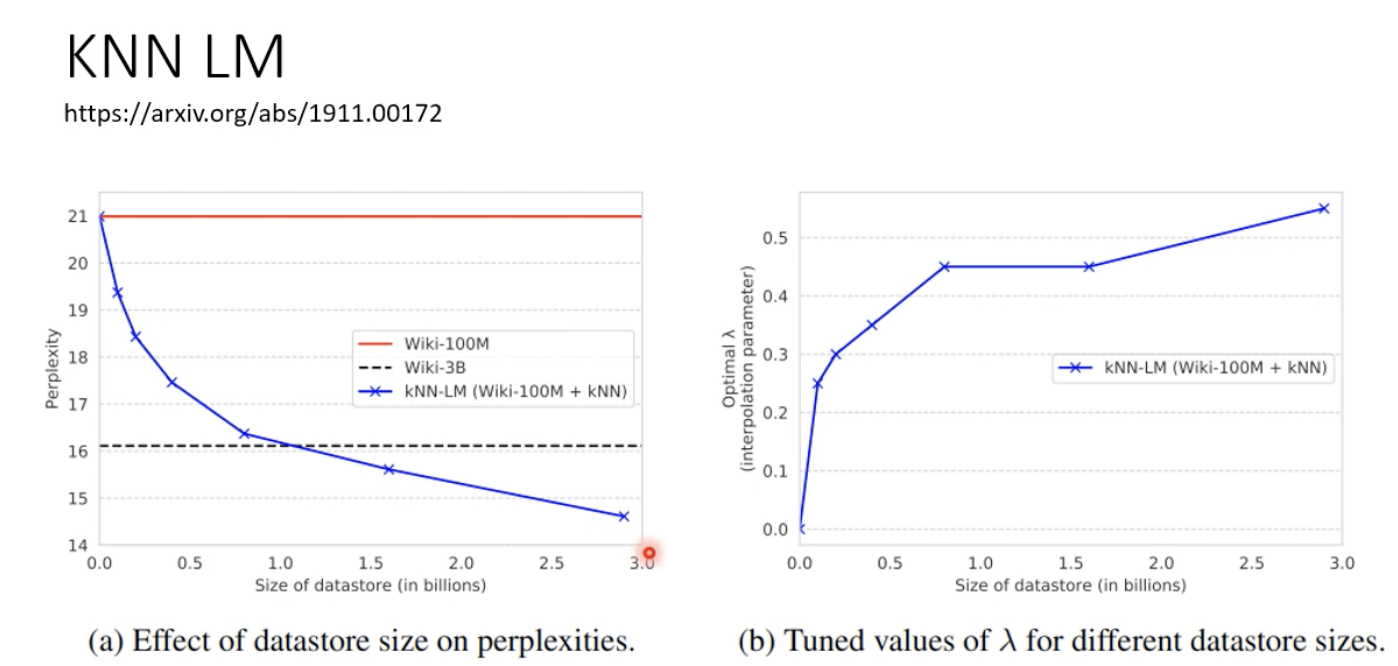
但是这种语言模型非常的慢
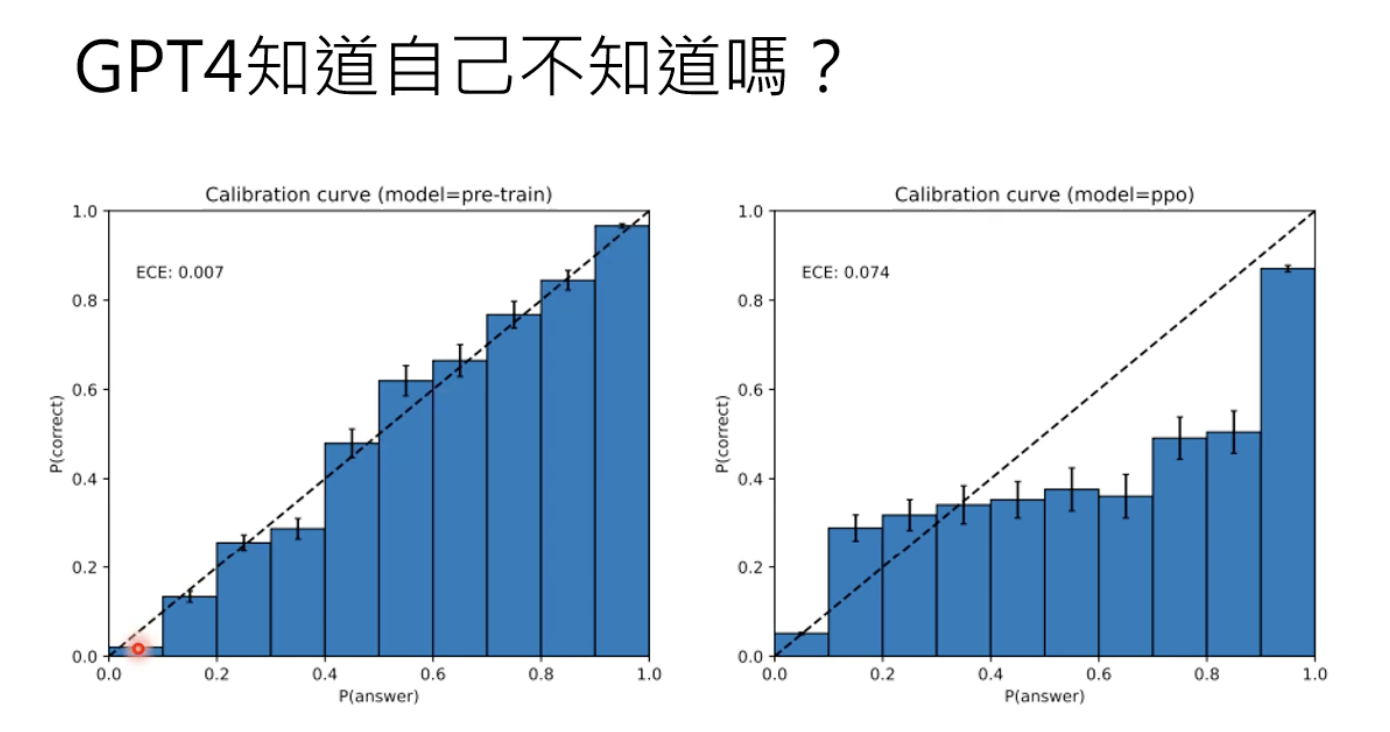
2.5 信心越高,正确率越高
让AI 解释AI
来解读一下这篇文章:

解释什么?——知道每一个神经元的作用、和哪些词关联度最大:
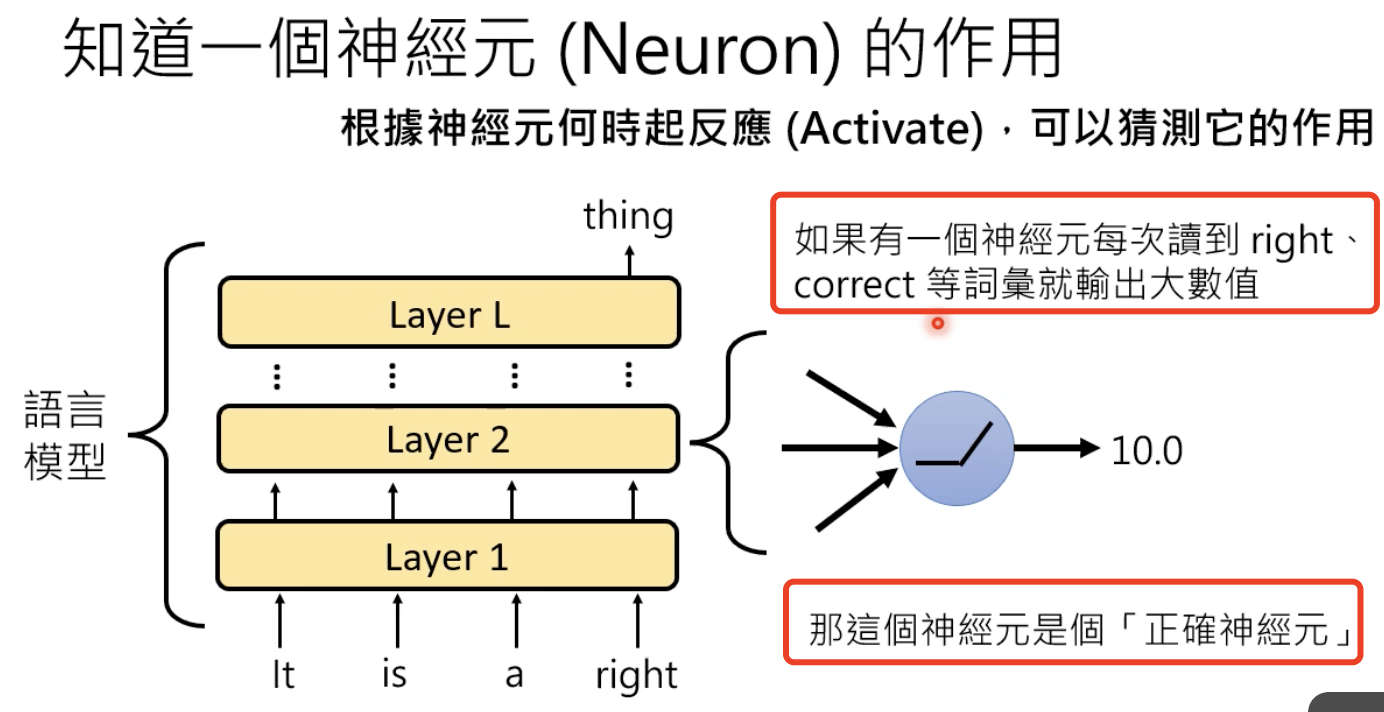
有工作发现了某一个神经元遇到以下词时输出会很大,通过观察发现,下一个会出现“an”:

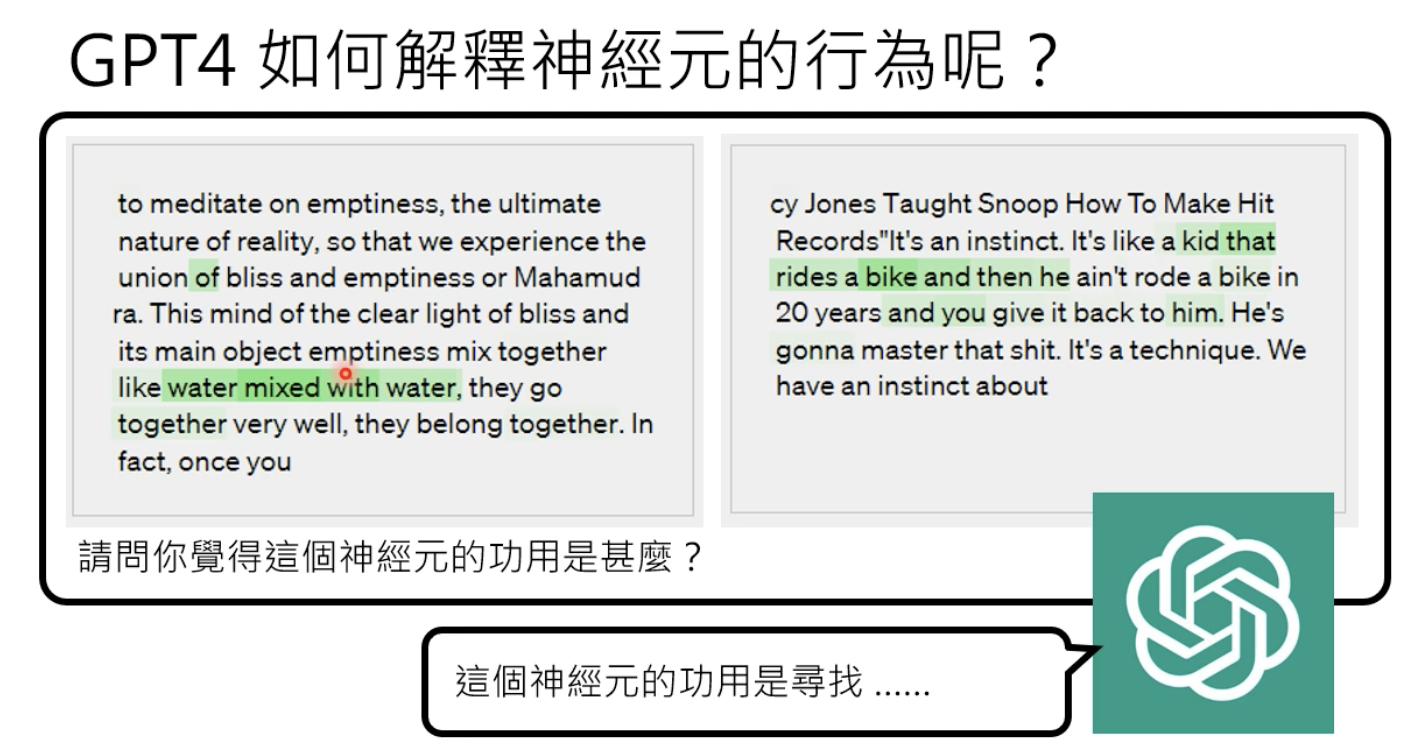
如何操作?输入以下promt:

能得到以下结果:

其他结果:

如何判断解释的好不好?

然后去gpt2模型找到那个神经元检查一下:
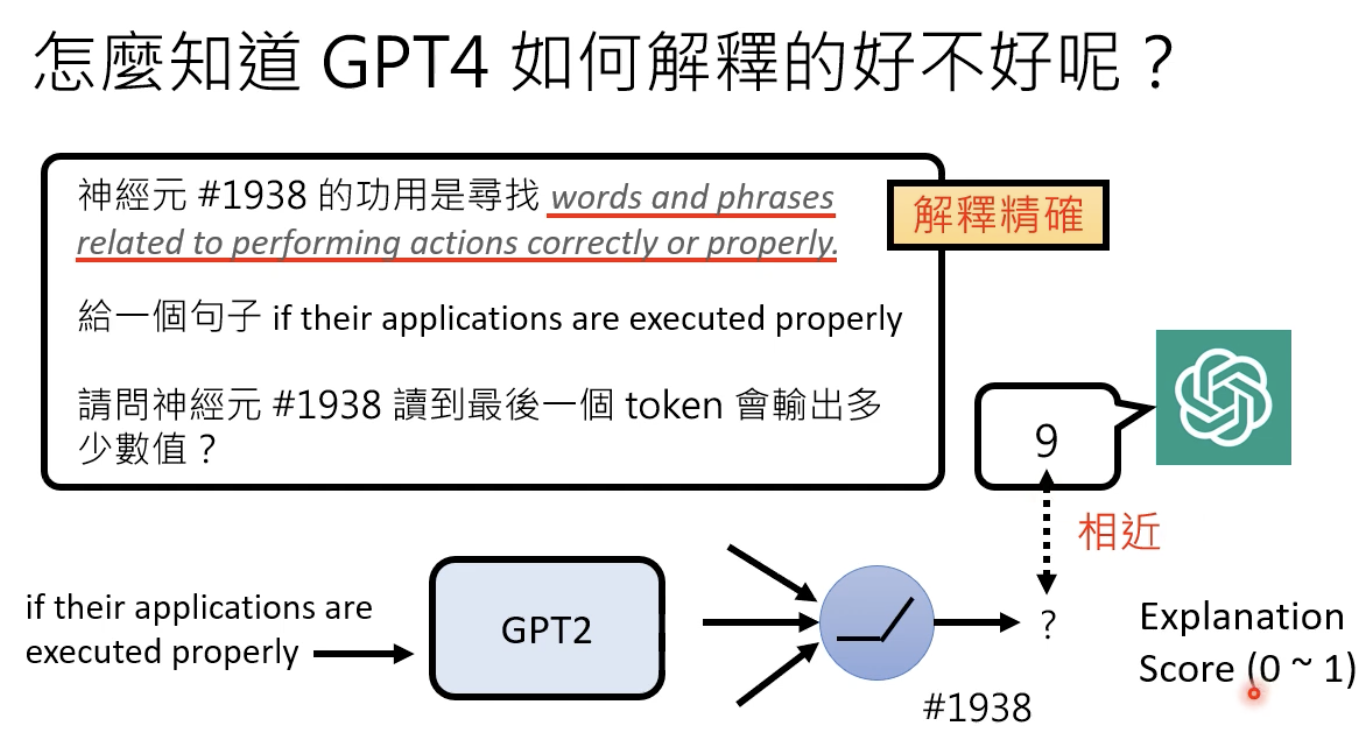
完整的prompt

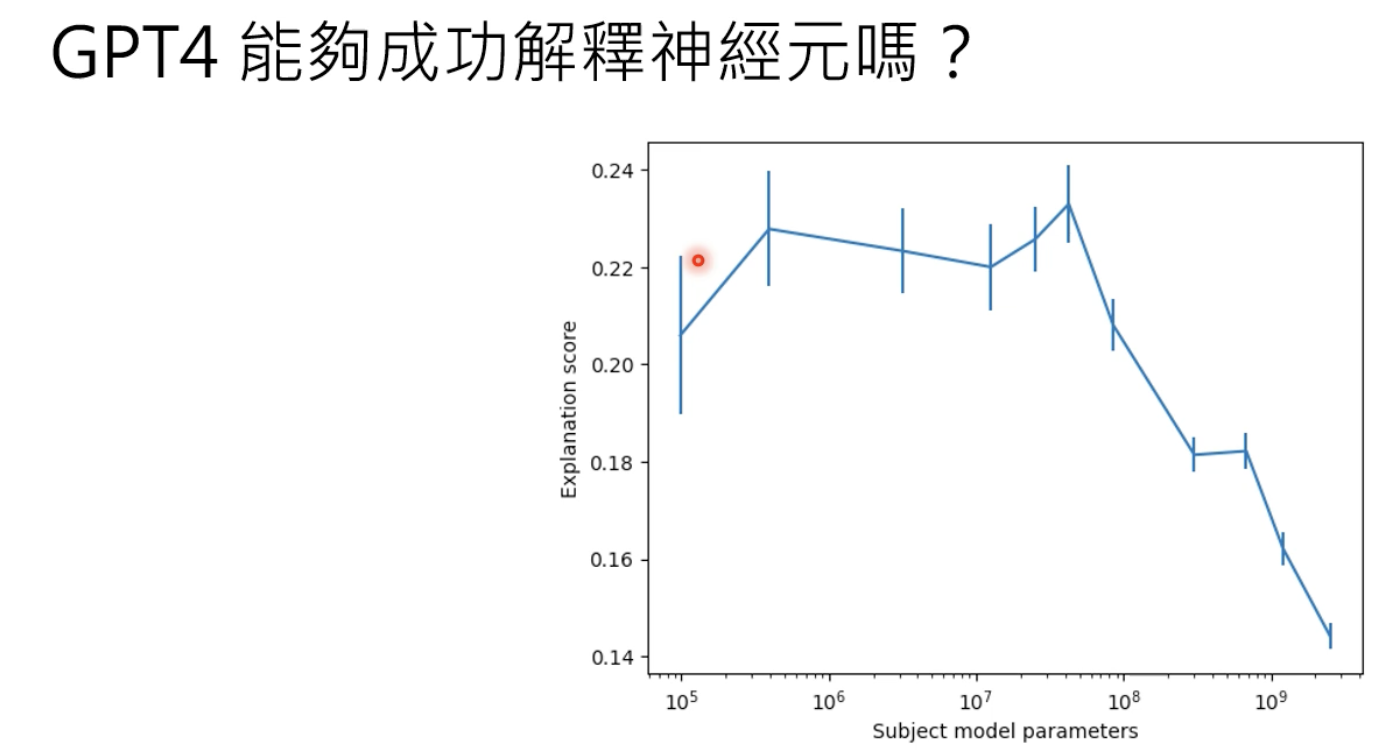
纵轴表示可解释性的分数,分数越高,可解释性越好,结论是小模型更容易解释、越底层的神经元越容易解释。
大致流程
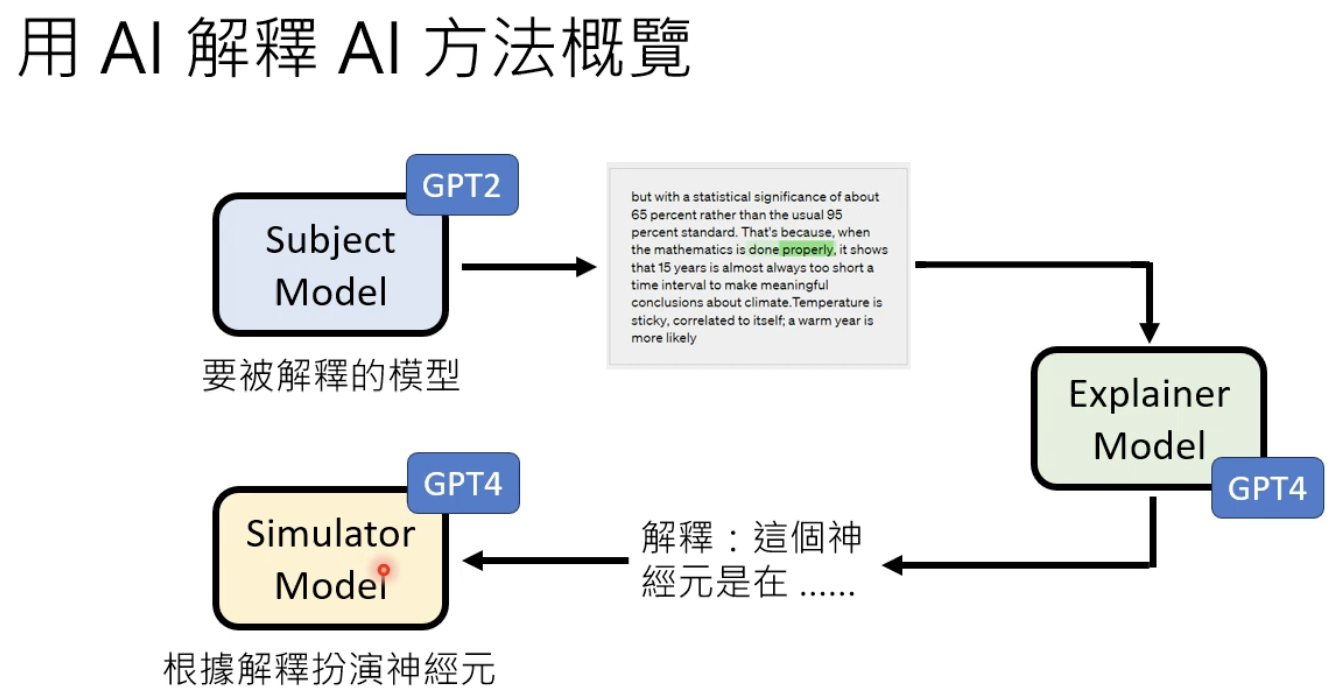
让模型扮演一个神经元:
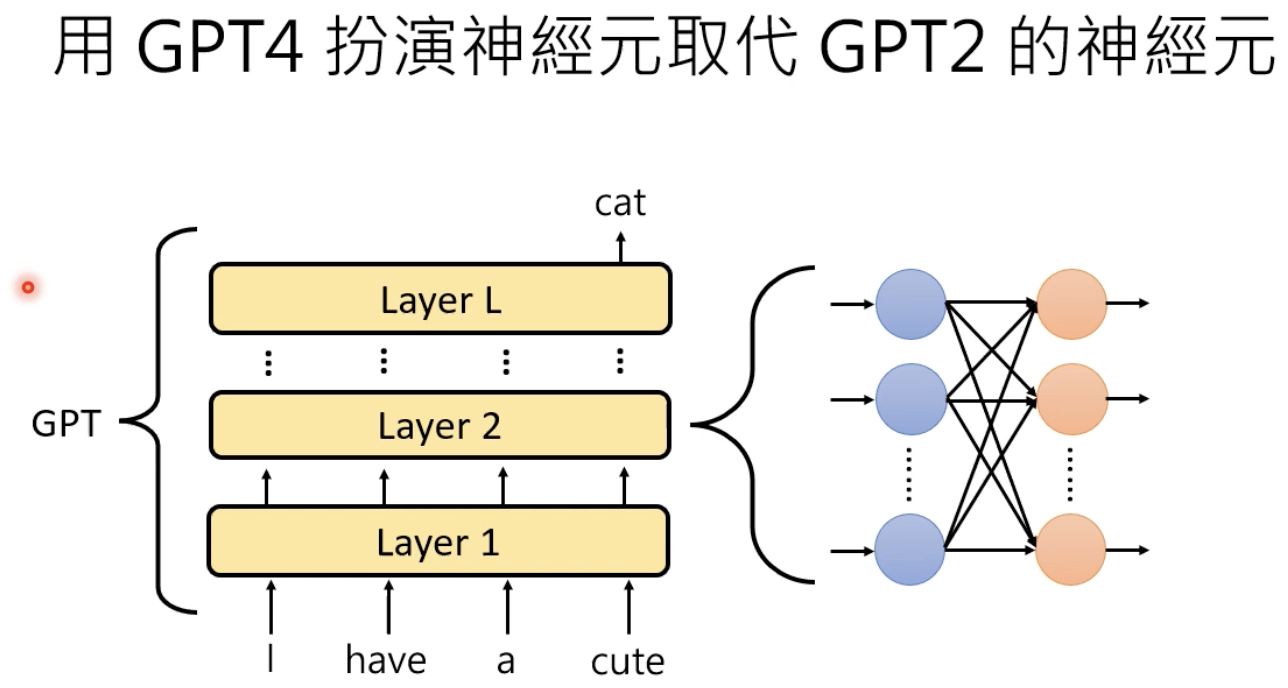
寻找神经元在什么时候激活值较大: