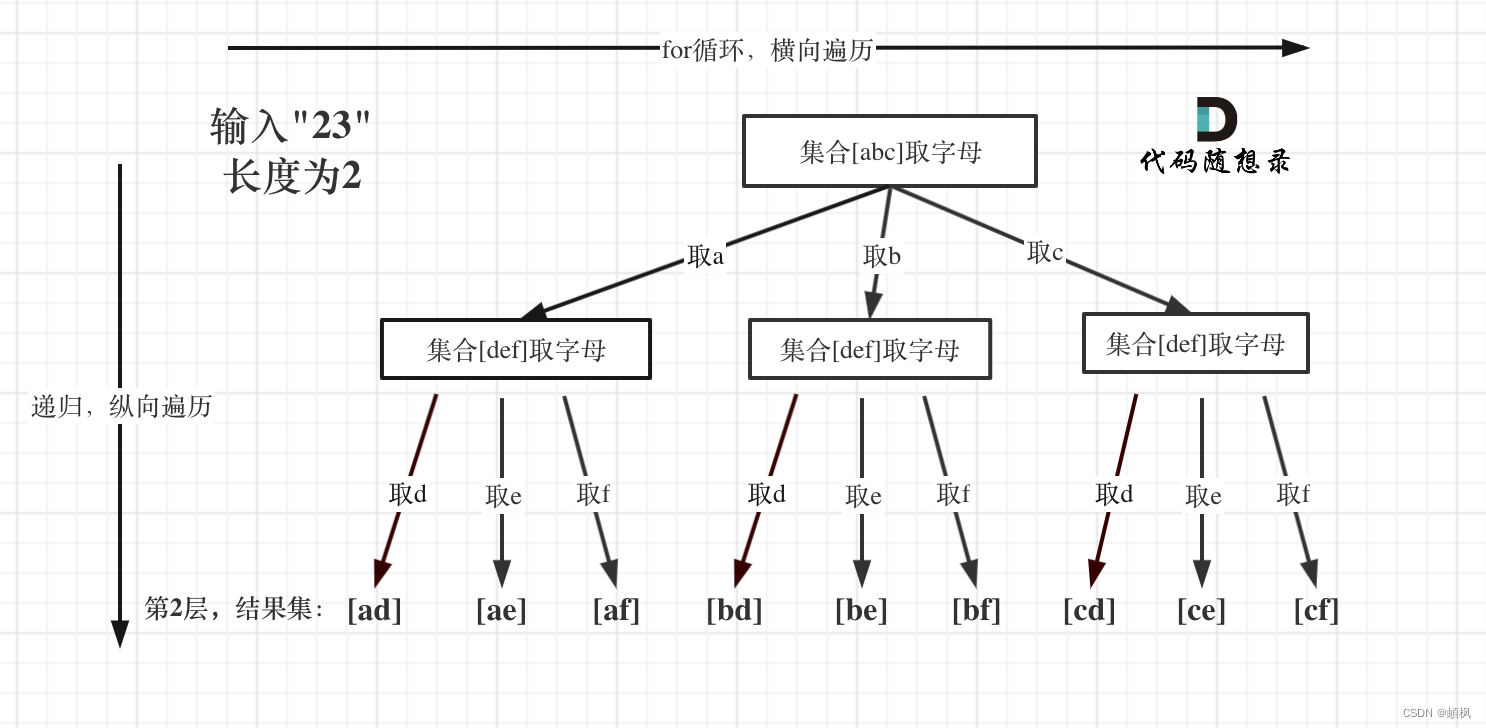
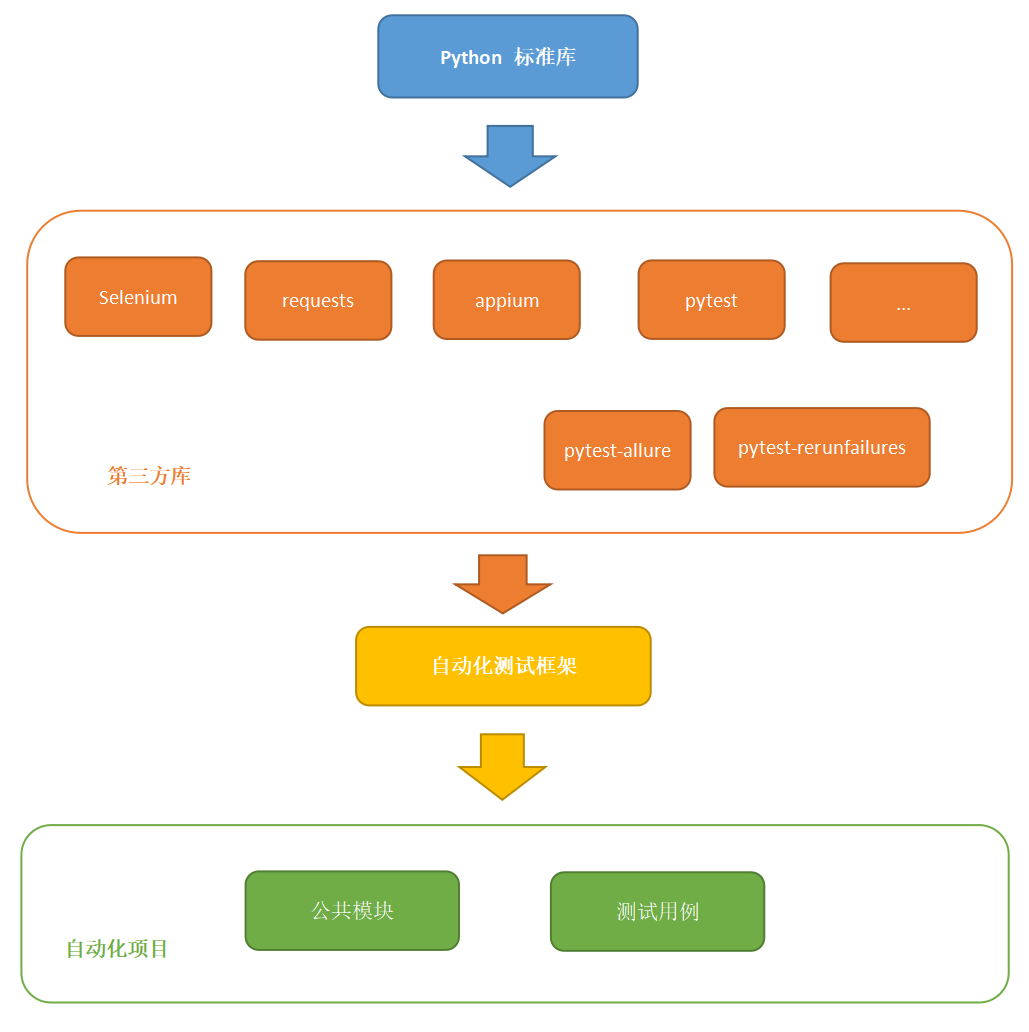
将从此图像中提取文本。我使用得是 PyCharm,您随意编辑器或IDE
1、下载所需得库和exe文件:
tesseract-ocr
可执行exe文件下载后,安装时无需指定安装目录。
http://jaist.dl.sourceforge.net/project/tesseract-ocr-alt/tesseract-ocr-setup-3.02.02.exe
自动分配目录文件夹:
https://github.com/tesseract-ocr/tessdata
创建文件后,让我们安装所需的 Python 包。单击底部的终端,然后键
pip install pytesseract
英文:eng、中文:chi_sim
C:\Program Files (x86)\Tesseract-OCR\tessdata
2、修改配置文件中tessdata.exe文件的位置
注意到在pip安装pytesseract成功后,找到 pytesseract.py 文件所在的目录,并用pycharm打开后查看:
命令行紧跟在导入库后的这句指定exe文件位置的命令:
tesseract_cmd = 'tesseract' 修改后是:
#tesseract_cmd = 'tesseract'
tesseract_cmd = r'C:\Program Files (x86)\Tesseract-OCR\tesseract.exe'
修改后正确找到 tesseract.exe 文件
该语句的位置见后示意:
#!/usr/bin/env python
import re
import shlex
import string
import subprocess
import sys
from contextlib import contextmanager
from csv import QUOTE_NONE
from errno import ENOENT
from functools import wraps
from glob import iglob
from io import BytesIO
from os import environ
from os import extsep
from os import linesep
from os import remove
from os.path import normcase
from os.path import normpath
from os.path import realpath
from pkgutil import find_loader
from tempfile import NamedTemporaryFile
from time import sleep
from packaging.version import InvalidVersion
from packaging.version import parse
from packaging.version import Version
from PIL import Image
#tesseract_cmd = 'tesseract'
tesseract_cmd = r'C:\Program Files (x86)\Tesseract-OCR\tesseract.exe'
修改后,就可以可以几行命令实现OCR图像到文本的转换了!
3、如何使用?
3 行代码就可以实现图像 -> 文本转换
首先创建一个新文件命名为 text-from-image.py

以上是需要处理的图片,存在text-from-image.py文件所在的目录下:
C:\Program Files (x86)\Tesseract-OCR\tesseract.exe
复制需要处理的图片到以上目录。
代码:
image = Image.open('Probability.png')
text = pytesseract.image_to_string(image,lang='eng')
print(text)
对话框输出:
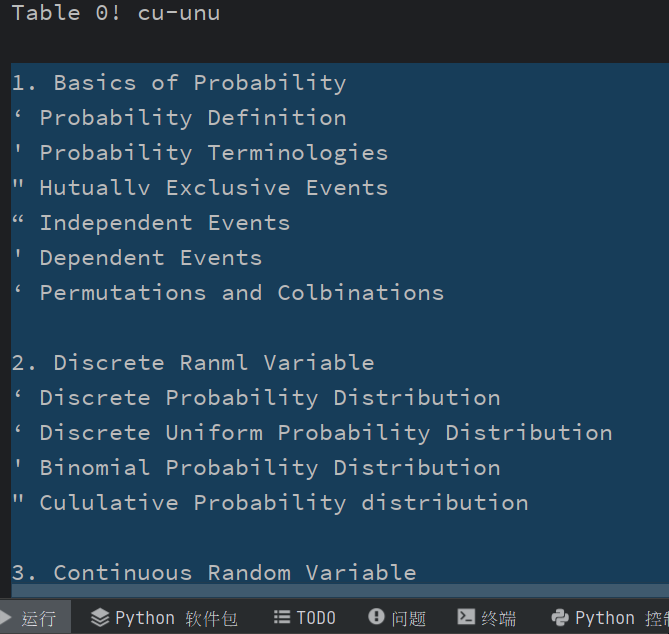
粘贴文本见后:
1. Basics of Probability
‘ Probability Definition
' Probability Terminologies
" Hutuallv Exclusive Events
“ Independent Events
' Dependent Events
‘ Permutations and Colbinations
2. Discrete Ranml Variable
‘ Discrete Probability Distribution
‘ Discrete Uniform Probability Distribution
' Binomial Probability Distribution
" Cululative Probability distribution
3. Continuous Random Variable
' Probability Density Function (PDF)
‘ Cululative Distribution Function (CDF)
Normal Probability Distribution
Standard Normal Distribution
注释:
pycharm选择py文件右键有查看文件目录位置。
然后,创建 image 的变量来读取和存储图像。图像与我们的 Python 文件位于同一目录中,因此我们只需要指定映像名称。
image = Image.open('image-to-text.png')
但是,如果映像位于另一个目录中,则必须指定完整路径。
例如,Mac 的“下载”中的图像将具有路径
/Users/your_username/Downloads/image-to-text.png
然后是文件名。
如果在 Windows 上,目录将是这样的
C:\\Users\Administrator\\Downloads\\image-to-text.png
请注意,在 Windows 上使用双反斜杠,而不是正斜杠。
然后,我们创建另一个称为text的变量,保存图像中的文本结果。
text = pytesseract.image_to_string( image )
然后,我们将结果打印。
print( text )
错误解决
如果跳过步骤 2、3 ,直接运行步骤3 的代码将有报错信息。
截屏

报错信息:
pytesseract.pytesseract.TesseractNotFoundError: tesseract is not installed or it's not in your PATH. See README file for more information.
没有安装tesseract或者tesseract不在你的路径中!
在pytesseract模块中找到pytesseract.py文件并修改它
找到:
tesseract_cmd = 'tesseract'
把它改为:
tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
tesseract_cmd给出的默认值实际上是tesseract的安装路径。
附录-1、如何.py to .exe ?
Pyinstaller
Pyinstaller是一个Python模块,用于将Python文件转换为可执行文件。
它将 Python 应用程序及其所有依赖项捆绑到一个包中。因此,您可以将 Python 文件转换为应用程序,用户可以在不安装 Python 及其包的情况下运行它。
若要使用,请先使用以下命令进行安装pyinstaller
pip install pyinstaller
成功安装后,将命令提示符重定向到包含 Python 脚本的文件夹。然后键入以下命令。
pyinstaller --onefile filename
好吧,如果我们看到您需要文件名和您的 Python 文件名。如下图所示,我将向您展示如何使用该命令将文件转换为。script.pyexe
我更推荐使用 auto-py-to-exe
它是一个 Gui 模块,其工作方式与工作相同,但在图形用户界面模式下。这意味着无需在 Python 文件位置文件夹中打开命令提示符并键入命令即可对其进行转换。
该模块将以更简单的方式进行对话。要安装此模块,请使用以下命令。
pip install auto-py-to-exe
安装此模块后,您需要通过在命令提示符下键入直接运行它,
cmd状态:pyinstaller
它将弹出如下所示的窗口
auto-py-to-exe
附-2 pytesseract源码
便于了解代码实现和功能.
https://github.com/madmaze/pytesseract
#!/usr/bin/env python
import re
import shlex
import string
import subprocess
import sys
from contextlib import contextmanager
from csv import QUOTE_NONE
from errno import ENOENT
from functools import wraps
from glob import iglob
from io import BytesIO
from os import environ
from os import extsep
from os import linesep
from os import remove
from os.path import normcase
from os.path import normpath
from os.path import realpath
from pkgutil import find_loader
from tempfile import NamedTemporaryFile
from time import sleep
from packaging.version import InvalidVersion
from packaging.version import parse
from packaging.version import Version
from PIL import Image
tesseract_cmd = 'tesseract'
numpy_installed = find_loader('numpy') is not None
if numpy_installed:
from numpy import ndarray
pandas_installed = find_loader('pandas') is not None
if pandas_installed:
import pandas as pd
DEFAULT_ENCODING = 'utf-8'
LANG_PATTERN = re.compile('^[a-z_]+$')
RGB_MODE = 'RGB'
SUPPORTED_FORMATS = {
'JPEG',
'JPEG2000',
'PNG',
'PBM',
'PGM',
'PPM',
'TIFF',
'BMP',
'GIF',
'WEBP',
}
OSD_KEYS = {
'Page number': ('page_num', int),
'Orientation in degrees': ('orientation', int),
'Rotate': ('rotate', int),
'Orientation confidence': ('orientation_conf', float),
'Script': ('script', str),
'Script confidence': ('script_conf', float),
}
TESSERACT_MIN_VERSION = Version('3.05')
TESSERACT_ALTO_VERSION = Version('4.1.0')
class Output:
BYTES = 'bytes'
DATAFRAME = 'data.frame'
DICT = 'dict'
STRING = 'string'
class PandasNotSupported(EnvironmentError):
def __init__(self):
super().__init__('Missing pandas package')
class TesseractError(RuntimeError):
def __init__(self, status, message):
self.status = status
self.message = message
self.args = (status, message)
class TesseractNotFoundError(EnvironmentError):
def __init__(self):
super().__init__(
f"{tesseract_cmd} is not installed or it's not in your PATH."
f' See README file for more information.',
)
class TSVNotSupported(EnvironmentError):
def __init__(self):
super().__init__(
'TSV output not supported. Tesseract >= 3.05 required',
)
class ALTONotSupported(EnvironmentError):
def __init__(self):
super().__init__(
'ALTO output not supported. Tesseract >= 4.1.0 required',
)
def kill(process, code):
process.terminate()
try:
process.wait(1)
except TypeError: # python2 Popen.wait(1) fallback
sleep(1)
except Exception: # python3 subprocess.TimeoutExpired
pass
finally:
process.kill()
process.returncode = code
@contextmanager
def timeout_manager(proc, seconds=None):
try:
if not seconds:
yield proc.communicate()[1]
return
try:
_, error_string = proc.communicate(timeout=seconds)
yield error_string
except subprocess.TimeoutExpired:
kill(proc, -1)
raise RuntimeError('Tesseract process timeout')
finally:
proc.stdin.close()
proc.stdout.close()
proc.stderr.close()
def run_once(func):
@wraps(func)
def wrapper(*args, **kwargs):
if wrapper._result is wrapper:
wrapper._result = func(*args, **kwargs)
return wrapper._result
wrapper._result = wrapper
return wrapper
def get_errors(error_string):
return ' '.join(
line for line in error_string.decode(DEFAULT_ENCODING).splitlines()
).strip()
def cleanup(temp_name):
"""Tries to remove temp files by filename wildcard path."""
for filename in iglob(f'{temp_name}*' if temp_name else temp_name):
try:
remove(filename)
except OSError as e:
if e.errno != ENOENT:
raise
def prepare(image):
if numpy_installed and isinstance(image, ndarray):
image = Image.fromarray(image)
if not isinstance(image, Image.Image):
raise TypeError('Unsupported image object')
extension = 'PNG' if not image.format else image.format
if extension not in SUPPORTED_FORMATS:
raise TypeError('Unsupported image format/type')
if 'A' in image.getbands():
# discard and replace the alpha channel with white background
background = Image.new(RGB_MODE, image.size, (255, 255, 255))
background.paste(image, (0, 0), image.getchannel('A'))
image = background
image.format = extension
return image, extension
@contextmanager
def save(image):
try:
with NamedTemporaryFile(prefix='tess_', delete=False) as f:
if isinstance(image, str):
yield f.name, realpath(normpath(normcase(image)))
return
image, extension = prepare(image)
input_file_name = f'{f.name}_input{extsep}{extension}'
image.save(input_file_name, format=image.format)
yield f.name, input_file_name
finally:
cleanup(f.name)
def subprocess_args(include_stdout=True):
# See https://github.com/pyinstaller/pyinstaller/wiki/Recipe-subprocess
# for reference and comments.
kwargs = {
'stdin': subprocess.PIPE,
'stderr': subprocess.PIPE,
'startupinfo': None,
'env': environ,
}
if hasattr(subprocess, 'STARTUPINFO'):
kwargs['startupinfo'] = subprocess.STARTUPINFO()
kwargs['startupinfo'].dwFlags |= subprocess.STARTF_USESHOWWINDOW
kwargs['startupinfo'].wShowWindow = subprocess.SW_HIDE
if include_stdout:
kwargs['stdout'] = subprocess.PIPE
else:
kwargs['stdout'] = subprocess.DEVNULL
return kwargs
def run_tesseract(
input_filename,
output_filename_base,
extension,
lang,
config='',
nice=0,
timeout=0,
):
cmd_args = []
if not sys.platform.startswith('win32') and nice != 0:
cmd_args += ('nice', '-n', str(nice))
cmd_args += (tesseract_cmd, input_filename, output_filename_base)
if lang is not None:
cmd_args += ('-l', lang)
if config:
cmd_args += shlex.split(config)
if extension and extension not in {'box', 'osd', 'tsv', 'xml'}:
cmd_args.append(extension)
try:
proc = subprocess.Popen(cmd_args, **subprocess_args())
except OSError as e:
if e.errno != ENOENT:
raise
else:
raise TesseractNotFoundError()
with timeout_manager(proc, timeout) as error_string:
if proc.returncode:
raise TesseractError(proc.returncode, get_errors(error_string))
def run_and_get_output(
image,
extension='',
lang=None,
config='',
nice=0,
timeout=0,
return_bytes=False,
):
with save(image) as (temp_name, input_filename):
kwargs = {
'input_filename': input_filename,
'output_filename_base': temp_name,
'extension': extension,
'lang': lang,
'config': config,
'nice': nice,
'timeout': timeout,
}
run_tesseract(**kwargs)
filename = f"{kwargs['output_filename_base']}{extsep}{extension}"
with open(filename, 'rb') as output_file:
if return_bytes:
return output_file.read()
return output_file.read().decode(DEFAULT_ENCODING)
def file_to_dict(tsv, cell_delimiter, str_col_idx):
result = {}
rows = [row.split(cell_delimiter) for row in tsv.strip().split('\n')]
if len(rows) < 2:
return result
header = rows.pop(0)
length = len(header)
if len(rows[-1]) < length:
# Fixes bug that occurs when last text string in TSV is null, and
# last row is missing a final cell in TSV file
rows[-1].append('')
if str_col_idx < 0:
str_col_idx += length
for i, head in enumerate(header):
result[head] = list()
for row in rows:
if len(row) <= i:
continue
if i != str_col_idx:
try:
val = int(float(row[i]))
except ValueError:
val = row[i]
else:
val = row[i]
result[head].append(val)
return result
def is_valid(val, _type):
if _type is int:
return val.isdigit()
if _type is float:
try:
float(val)
return True
except ValueError:
return False
return True
def osd_to_dict(osd):
return {
OSD_KEYS[kv[0]][0]: OSD_KEYS[kv[0]][1](kv[1])
for kv in (line.split(': ') for line in osd.split('\n'))
if len(kv) == 2 and is_valid(kv[1], OSD_KEYS[kv[0]][1])
}
@run_once
def get_languages(config=''):
cmd_args = [tesseract_cmd, '--list-langs']
if config:
cmd_args += shlex.split(config)
try:
result = subprocess.run(
cmd_args,
stdout=subprocess.PIPE,
stderr=subprocess.STDOUT,
)
except OSError:
raise TesseractNotFoundError()
# tesseract 3.x
if result.returncode not in (0, 1):
raise TesseractNotFoundError()
languages = []
if result.stdout:
for line in result.stdout.decode(DEFAULT_ENCODING).split(linesep):
lang = line.strip()
if LANG_PATTERN.match(lang):
languages.append(lang)
return languages
@run_once
def get_tesseract_version():
"""
Returns Version object of the Tesseract version
"""
try:
output = subprocess.check_output(
[tesseract_cmd, '--version'],
stderr=subprocess.STDOUT,
env=environ,
stdin=subprocess.DEVNULL,
)
except OSError:
raise TesseractNotFoundError()
raw_version = output.decode(DEFAULT_ENCODING)
str_version, *_ = raw_version.lstrip(string.printable[10:]).partition(' ')
str_version, *_ = str_version.partition('-')
try:
version = parse(str_version)
assert version >= TESSERACT_MIN_VERSION
except (AssertionError, InvalidVersion):
raise SystemExit(f'Invalid tesseract version: "{raw_version}"')
return version
def image_to_string(
image,
lang=None,
config='',
nice=0,
output_type=Output.STRING,
timeout=0,
):
"""
Returns the result of a Tesseract OCR run on the provided image to string
"""
args = [image, 'txt', lang, config, nice, timeout]
return {
Output.BYTES: lambda: run_and_get_output(*(args + [True])),
Output.DICT: lambda: {'text': run_and_get_output(*args)},
Output.STRING: lambda: run_and_get_output(*args),
}[output_type]()
def image_to_pdf_or_hocr(
image,
lang=None,
config='',
nice=0,
extension='pdf',
timeout=0,
):
"""
Returns the result of a Tesseract OCR run on the provided image to pdf/hocr
"""
if extension not in {'pdf', 'hocr'}:
raise ValueError(f'Unsupported extension: {extension}')
args = [image, extension, lang, config, nice, timeout, True]
return run_and_get_output(*args)
def image_to_alto_xml(
image,
lang=None,
config='',
nice=0,
timeout=0,
):
"""
Returns the result of a Tesseract OCR run on the provided image to ALTO XML
"""
if get_tesseract_version() < TESSERACT_ALTO_VERSION:
raise ALTONotSupported()
config = f'-c tessedit_create_alto=1 {config.strip()}'
args = [image, 'xml', lang, config, nice, timeout, True]
return run_and_get_output(*args)
def image_to_boxes(
image,
lang=None,
config='',
nice=0,
output_type=Output.STRING,
timeout=0,
):
"""
Returns string containing recognized characters and their box boundaries
"""
config = f'{config.strip()} batch.nochop makebox'
args = [image, 'box', lang, config, nice, timeout]
return {
Output.BYTES: lambda: run_and_get_output(*(args + [True])),
Output.DICT: lambda: file_to_dict(
f'char left bottom right top page\n{run_and_get_output(*args)}',
' ',
0,
),
Output.STRING: lambda: run_and_get_output(*args),
}[output_type]()
def get_pandas_output(args, config=None):
if not pandas_installed:
raise PandasNotSupported()
kwargs = {'quoting': QUOTE_NONE, 'sep': '\t'}
try:
kwargs.update(config)
except (TypeError, ValueError):
pass
return pd.read_csv(BytesIO(run_and_get_output(*args)), **kwargs)
def image_to_data(
image,
lang=None,
config='',
nice=0,
output_type=Output.STRING,
timeout=0,
pandas_config=None,
):
"""
Returns string containing box boundaries, confidences,
and other information. Requires Tesseract 3.05+
"""
if get_tesseract_version() < TESSERACT_MIN_VERSION:
raise TSVNotSupported()
config = f'-c tessedit_create_tsv=1 {config.strip()}'
args = [image, 'tsv', lang, config, nice, timeout]
return {
Output.BYTES: lambda: run_and_get_output(*(args + [True])),
Output.DATAFRAME: lambda: get_pandas_output(
args + [True],
pandas_config,
),
Output.DICT: lambda: file_to_dict(run_and_get_output(*args), '\t', -1),
Output.STRING: lambda: run_and_get_output(*args),
}[output_type]()
def image_to_osd(
image,
lang='osd',
config='',
nice=0,
output_type=Output.STRING,
timeout=0,
):
"""
Returns string containing the orientation and script detection (OSD)
"""
config = f'--psm 0 {config.strip()}'
args = [image, 'osd', lang, config, nice, timeout]
return {
Output.BYTES: lambda: run_and_get_output(*(args + [True])),
Output.DICT: lambda: osd_to_dict(run_and_get_output(*args)),
Output.STRING: lambda: run_and_get_output(*args),
}[output_type]()
def main():
if len(sys.argv) == 2:
filename, lang = sys.argv[1], None
elif len(sys.argv) == 4 and sys.argv[1] == '-l':
filename, lang = sys.argv[3], sys.argv[2]
else:
print('Usage: pytesseract [-l lang] input_file\n', file=sys.stderr)
return 2
try:
with Image.open(filename) as img:
print(image_to_string(img, lang=lang))
except TesseractNotFoundError as e:
print(f'{str(e)}\n', file=sys.stderr)
return 1
except OSError as e:
print(f'{type(e).__name__}: {e}', file=sys.stderr)
return 1
if __name__ == '__main__':
exit(main())
本文由 mdnice 多平台发布