一、生成数据表
二、数据表信息查看
三、数据表清洗
四、数据预处理
————————————————
目录
五、数据提取
1.按索引提取单行的数值
2.按索引提取区域行数值
3.重设索引
4.设置日期为索引
5.提取4日之前的所有数据
6.使用iloc按位置区域提取数据
7.适应iloc按位置单独提起数据
8.使用ix按索引标签和位置混合提取数据
9.判断city列的值是否为北京
10.判断city列里是否包含beijing和shanghai,然后将符合条件的数据提取出来
11.提取前三个字符,并生成数据表
六、数据筛选
1.使用“与”进行筛选
2.使用“或”进行筛选
3.使用“非”条件进行筛选
4.对筛选后的数据按city列进行计数
5.使用query函数进行筛选
6.对筛选后的结果按prince进行求和
七、数据汇总
1.对所有的列进行计数汇总
2.按城市对id字段进行计数
3.对两个字段进行汇总计数
4.对city字段进行汇总,并分别计算prince的合计和均值
八、数据统计
1.简单的数据采样
2.手动设置采样权重
3.采样后不放回
4.采样后放回
5.数据表描述性统计
6.计算列的标准差
7.计算两个字段间的协方差
8.数据表中所有字段间的协方差
9..两个字段的相关性分析
10.数据表的相关性分析
九、数据输出
1.写入Excel
2.写入到CSV
五、数据提取
主要用到的三个函数:loc,iloc和ix。
loc函数按标签值进行提取,iloc按位置进行提取,ix可以同时按标签和位置进行提取。
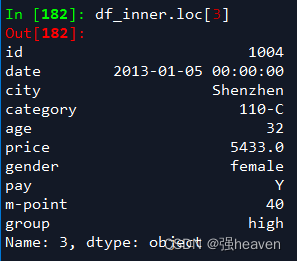
1.按索引提取单行的数值
df_inner.loc[3]
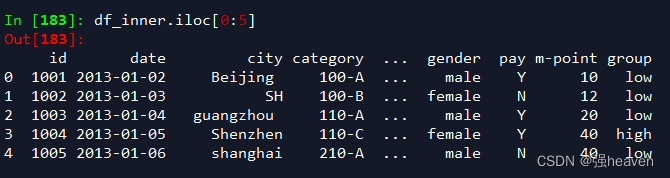
2.按索引提取区域行数值
df_inner.iloc[0:5]
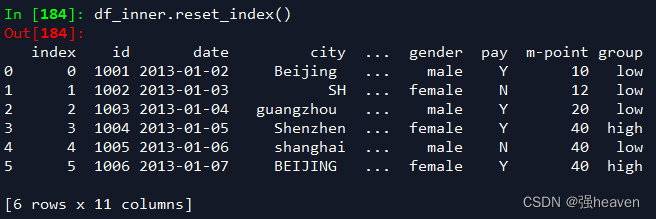
3.重设索引
df_inner.reset_index()
4.设置日期为索引
df_inner=df_inner.set_index('date')

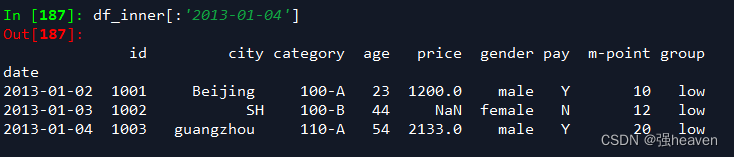
5.提取4日之前的所有数据
df_inner[:'2013-01-04']
6.使用iloc按位置区域提取数据
df_inner.iloc[:3,:2] #冒号前后的数字不再是索引的标签名称,而是数据所在的位置,从0开始,前三行,前两列。

7.适应iloc按位置单独提起数据
df_inner.iloc[[0,2,5],[4,5]] #提取第0、2、5行,4、5列

8.使用ix按索引标签和位置混合提取数据
df_inner.ix[:'2013-01-03',:4] #2013-01-03号之前,前四列数据
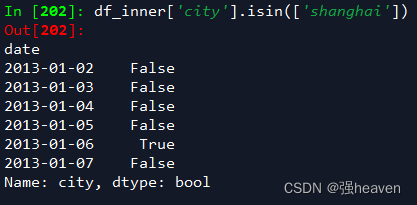
9.判断city列的值是否为北京
df_inner['city'].isin(['shanghai'])
10.判断city列里是否包含beijing和shanghai,然后将符合条件的数据提取出来
df_inner.loc[df_inner['city'].isin(['beijing','shanghai'])]

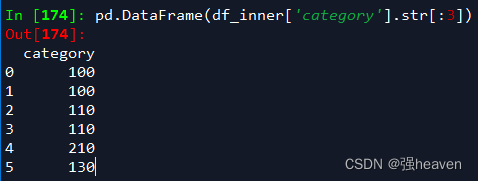
11.提取前三个字符,并生成数据表
pd.DataFrame(df_inner['category'].str[:3])
六、数据筛选
使用与、或、非三个条件配合大于、小于、等于对数据进行筛选,并进行计数和求和。
df_inner['price']=df_inner['price'].fillna(df_inner['price'].mean())
df_inner['city']=df_inner['city'].str.lower()
df_inner['city']=df_inner['city'].map(str.strip)
df_inner['city']=df_inner['city'].replace('sh', 'shanghai')
df_inner['group'] = np.where(df_inner['price'] > 3000,'high','low')
df_inner.reset_index()
df_inner=df_inner.set_index('date')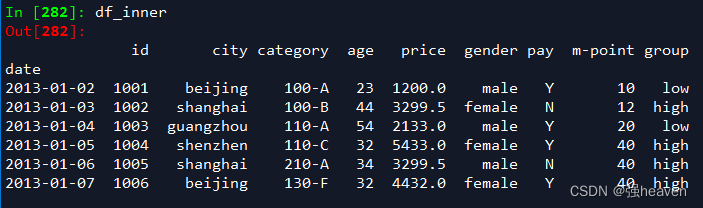
1.使用“与”进行筛选
df_inner.loc[(df_inner['age'] > 25) & (df_inner['city'] == 'shanghai'), ['id','city','age','category','gender']]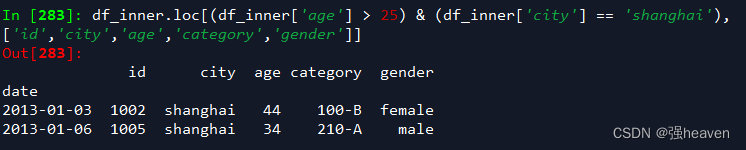
2.使用“或”进行筛选
df_inner.loc[(df_inner['age'] > 25) | (df_inner['city'] == 'shanghai'), ['id','city','age','category','gender']] 
3.使用“非”条件进行筛选
df_inner.loc[(df_inner['city'] != 'beijing'), ['id','city','age','category','gender']].sort(['id'])

4.对筛选后的数据按city列进行计数
df_inner.loc[(df_inner['city'] != 'beijing'), ['id','city','age','category','gender']].sort(['id']).city.count()
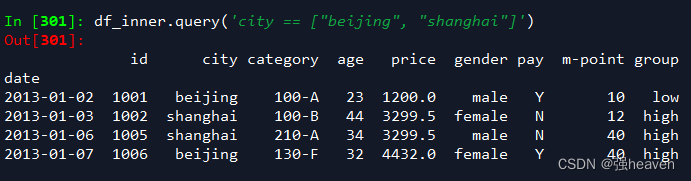
5.使用query函数进行筛选
df_inner.query('city == ["beijing", "shanghai"]')
6.对筛选后的结果按prince进行求和
df_inner.query('city == ["beijing", "shanghai"]').price.sum()

七、数据汇总
主要函数是groupby和pivote_table
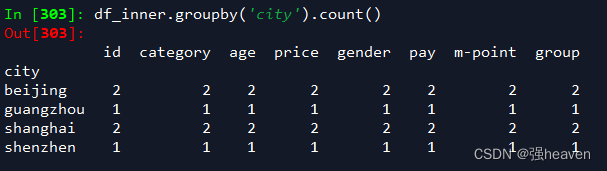
1.对所有的列进行计数汇总
df_inner.groupby('city').count()
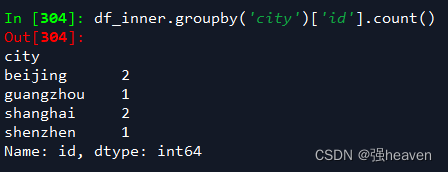
2.按城市对id字段进行计数
df_inner.groupby('city')['id'].count()
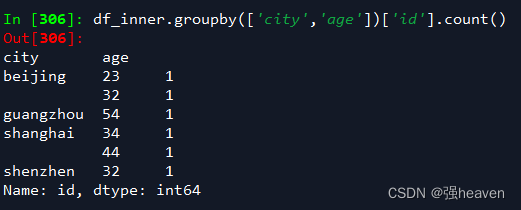
3.对两个字段进行汇总计数
df_inner.groupby(['city','age'])['id'].count()
7.16-20
4.对city字段进行汇总,并分别计算prince的合计和均值
df_inner.groupby('city')['price'].agg([len,np.sum, np.mean]) 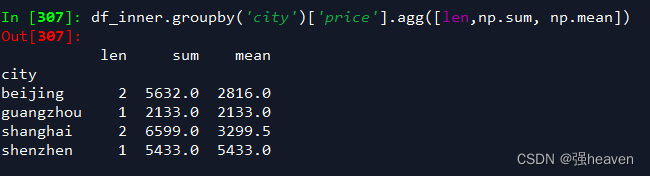
八、数据统计
数据采样,计算标准差,协方差和相关系数
1.简单的数据采样
df_inner.sample(n=3)
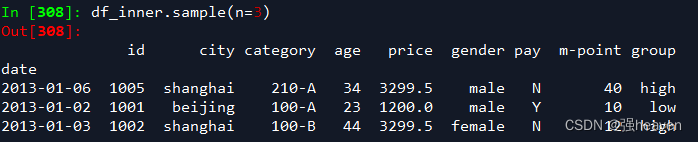
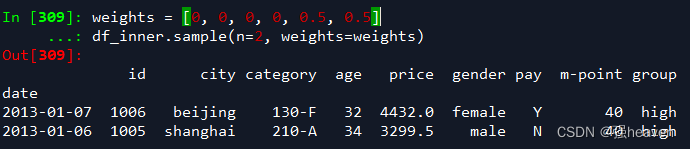
2.手动设置采样权重
weights = [0, 0, 0, 0, 0.5, 0.5]
df_inner.sample(n=2, weights=weights)
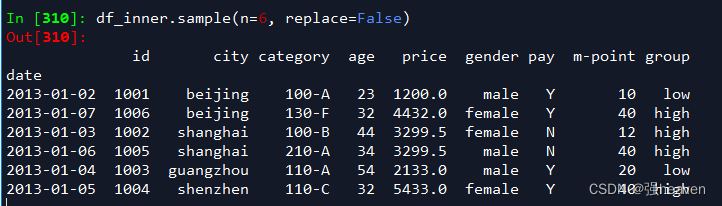
3.采样后不放回
df_inner.sample(n=6, replace=False)
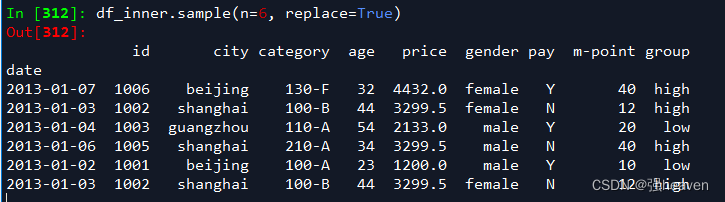
4.采样后放回
df_inner.sample(n=6, replace=True)
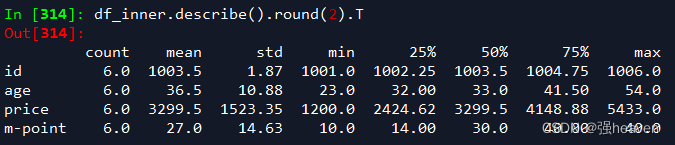
5.数据表描述性统计
df_inner.describe().round(2).T #round函数设置显示小数位,T表示转置
6.计算列的标准差
df_inner['price'].std()
![]()
7.计算两个字段间的协方差
df_inner['price'].cov(df_inner['m-point'])

8.数据表中所有字段间的协方差
df_inner.cov()

9..两个字段的相关性分析
df_inner['price'].corr(df_inner['m-point']) #相关系数在-1到1之间,接近1为正相关,接近-1为负相关,0为不相关

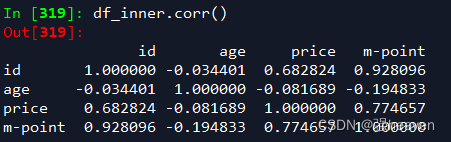
10.数据表的相关性分析
df_inner.corr()
九、数据输出
分析后的数据可以输出为xlsx格式和csv格式
1.写入Excel
df_inner.to_excel('excel_filename.xlsx', sheet_name='pandas_ok')
2.写入到CSV
df_inner.to_csv('csv_filename.csv') ————————————————
参考链接:https://blog.csdn.net/yiyele/article/details/80605909