这里写自定义目录标题
- 1.首先拉取paddleocr源代码
- 下载预训练模型
- 2.开始训练
- 更改yml配置文件
- 3.遇到的报错
- 1.ModuleNotFoundError: No module named 'Polygon'
- 2.最难解决的No module named 'lanms'
- 3.ImportError: cannot import name '_print_arguments' from 'paddle.distributed.utils等
- 4.报错UnicodeDecodeError: 'utf-8' codec can't decode byte 0xbc in position 2: invalid start byt
- 5.no kernel image is available for execution on the device paddle
- 6.Could not locate zlibwapi.dll. Please make sure it is in your library path
- 7.Out of memory error on GPU 0. Cannot allocate 60.000000MB memory on GPU 0, 9.999390GB memory has been allocated and available memory is only 0.000000B.
- 到这里即可完美的开始训练啦!!
- 非常好的常用问题官方解答手册
1.首先拉取paddleocr源代码
下载地址:https://gitee.com/paddlepaddle/PaddleOCR
下载预训练模型
- 参考文档
1.文本识别模型训练
本文提供了PaddleOCR文本识别任务的全流程指南,包括数据准备、模型训练、调优、评估、预测,各个阶段的详细说明:https://gitee.com/paddlepaddle/PaddleOCR/blob/release/2.6/doc/doc_ch/recognition.md#29-%E6%A8%A1%E5%9E%8B%E5%BE%AE%E8%B0%83

# GPU训练 支持单卡,多卡训练
# 训练icdar15英文数据 训练日志会自动保存为 "{save_model_dir}" 下的train.log
#单卡训练(训练周期长,不建议)
python3 tools/train.py -c configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml -o Global.pretrained_model=./pretrain_models/en_PP-OCRv3_rec_train/best_accuracy
#多卡训练,通过--gpus参数指定卡号
python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml -o Global.pretrained_model=./pretrain_models/en_PP-OCRv3_rec_train/best_accuracy
2.模型微调
https://gitee.com/paddlepaddle/PaddleOCR/blob/release/2.6/doc/doc_ch/finetune.md#/paddlepaddle/PaddleOCR/blob/release/2.6/doc/doc_ch/inference_ppocr.md

我要训练一个中文模型,在这里看到该预训练模型泛化性能最优,于是下载这个模型
https://gitee.com/link?target=https%3A%2F%2Fpaddleocr.bj.bcebos.com%2FPP-OCRv3%2Fchinese%2Fch_PP-OCRv3_rec_train.tar

- 其他模型地址:
https://gitee.com/paddlepaddle/PaddleOCR/blob/release/2.6/doc/doc_ch/models_list.md
3.实际案例
https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.6/applications/%E5%85%89%E5%8A%9F%E7%8E%87%E8%AE%A1%E6%95%B0%E7%A0%81%E7%AE%A1%E5%AD%97%E7%AC%A6%E8%AF%86%E5%88%AB/%E5%85%89%E5%8A%9F%E7%8E%87%E8%AE%A1%E6%95%B0%E7%A0%81%E7%AE%A1%E5%AD%97%E7%AC%A6%E8%AF%86%E5%88%AB.md#31-%E6%95%B0%E6%8D%AE%E5%87%86%E5%A4%87
2.开始训练
更改yml配置文件
Global:
debug: false
use_gpu: true
epoch_num: 800
log_smooth_window: 20
print_batch_step: 10
save_model_dir: wjp/output/rec_ppocr_v3_distillation
save_epoch_step: 3
eval_batch_step: [0, 2000]
cal_metric_during_train: true
pretrained_model:
checkpoints:
save_inference_dir:
use_visualdl: false
infer_img: doc/imgs_words/ch/word_1.jpg
character_dict_path: ppocr/utils/ppocr_keys_v1.txt
max_text_length: &max_text_length 70
infer_mode: false
use_space_char: true
distributed: true
save_res_path: wjp/output/rec/predicts_ppocrv3_distillation.txt
Optimizer:
name: Adam
beta1: 0.9
beta2: 0.999
lr:
name: Piecewise
decay_epochs : [700, 800]
values : [0.0005, 0.00005]
warmup_epoch: 5
regularizer:
name: L2
factor: 3.0e-05
Architecture:
model_type: &model_type "rec"
name: DistillationModel
algorithm: Distillation
Models:
Teacher:
pretrained:
freeze_params: false
return_all_feats: true
model_type: *model_type
algorithm: SVTR
Transform:
Backbone:
name: MobileNetV1Enhance
scale: 0.5
last_conv_stride: [1, 2]
last_pool_type: avg
Head:
name: MultiHead
head_list:
- CTCHead:
Neck:
name: svtr
dims: 64
depth: 2
hidden_dims: 120
use_guide: True
Head:
fc_decay: 0.00001
- SARHead:
enc_dim: 512
max_text_length: *max_text_length
Student:
pretrained:
freeze_params: false
return_all_feats: true
model_type: *model_type
algorithm: SVTR
Transform:
Backbone:
name: MobileNetV1Enhance
scale: 0.5
last_conv_stride: [1, 2]
last_pool_type: avg
Head:
name: MultiHead
head_list:
- CTCHead:
Neck:
name: svtr
dims: 64
depth: 2
hidden_dims: 120
use_guide: True
Head:
fc_decay: 0.00001
- SARHead:
enc_dim: 512
max_text_length: *max_text_length
Loss:
name: CombinedLoss
loss_config_list:
- DistillationDMLLoss:
weight: 1.0
act: "softmax"
use_log: true
model_name_pairs:
- ["Student", "Teacher"]
key: head_out
multi_head: True
dis_head: ctc
name: dml_ctc
- DistillationDMLLoss:
weight: 0.5
act: "softmax"
use_log: true
model_name_pairs:
- ["Student", "Teacher"]
key: head_out
multi_head: True
dis_head: sar
name: dml_sar
- DistillationDistanceLoss:
weight: 1.0
mode: "l2"
model_name_pairs:
- ["Student", "Teacher"]
key: backbone_out
- DistillationCTCLoss:
weight: 1.0
model_name_list: ["Student", "Teacher"]
key: head_out
multi_head: True
- DistillationSARLoss:
weight: 1.0
model_name_list: ["Student", "Teacher"]
key: head_out
multi_head: True
PostProcess:
name: DistillationCTCLabelDecode
model_name: ["Student", "Teacher"]
key: head_out
multi_head: True
Metric:
name: DistillationMetric
base_metric_name: RecMetric
main_indicator: acc
key: "Student"
ignore_space: False
Train:
dataset:
name: SimpleDataSet
data_dir: wjp\split_rec_label\train
ext_op_transform_idx: 1
label_file_list:
- wjp\split_rec_label\train.txt
transforms:
- DecodeImage:
img_mode: BGR
channel_first: false
- RecConAug:
prob: 0.5
ext_data_num: 2
image_shape: [48, 320, 3]
max_text_length: *max_text_length
- RecAug:
- MultiLabelEncode:
- RecResizeImg:
image_shape: [3, 48, 320]
- KeepKeys:
keep_keys:
- image
- label_ctc
- label_sar
- length
- valid_ratio
loader:
shuffle: true
batch_size_per_card: 16
drop_last: true
num_workers: 4
Eval:
dataset:
name: SimpleDataSet
data_dir: wjp\split_rec_label\val
label_file_list:
- wjp\split_rec_label\val.txt
transforms:
- DecodeImage:
img_mode: BGR
channel_first: false
- MultiLabelEncode:
- RecResizeImg:
image_shape: [3, 48, 320]
- KeepKeys:
keep_keys:
- image
- label_ctc
- label_sar
- length
- valid_ratio
loader:
shuffle: false
drop_last: false
batch_size_per_card: 16
num_workers: 4
训练指令
python tools/train.py -c wjp/ch_PP-OCRv3_rec_distillation.yml -o Global.pretrained_model=wjp/ch_PP-OCRv3_rec_train/best_accuracy
//-c参数放配置文件地址,-o参数放预训练模型地址
3.遇到的报错
运行的时候会提示缺各种各样的包只需要安装即可
pip install 包名 -i https://pypi.tuna.tsinghua.edu.cn/simple
1.ModuleNotFoundError: No module named ‘Polygon’
参考博客:https://blog.csdn.net/Retarded78_/article/details/119741620
到https://www.lfd.uci.edu/~gohlke/pythonlibs/下载相对应的版本即可
2.最难解决的No module named ‘lanms’
这个需要用源码自己编译,详细见我之前写的博客https://blog.csdn.net/Mintary/article/details/125387670?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522168595655416800182731690%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=168595655416800182731690&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2blogfirst_rank_ecpm_v1~rank_v31_ecpm-1-125387670-null-null.268v1koosearch&utm_term=lanms&spm=1018.2226.3001.4450
github源码地址:https://github.com/AndranikSargsyan/lanms-nova
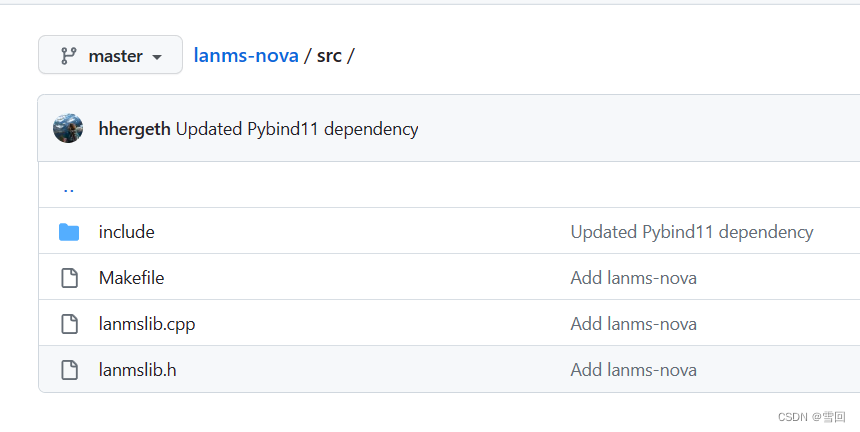
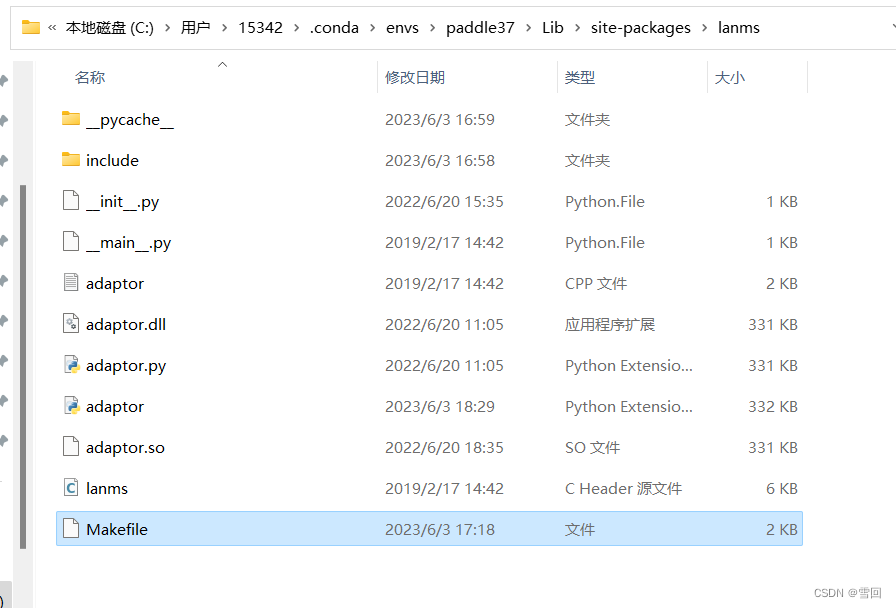
在这个文件夹进行编译,首先要根据实际情况更改makefile
CXXFLAGS = -I include -std=c++11 -O3 -I 'D:/ProgramData/anaconda3/include'//该conda环境python头文件夹地址
LDFLAGS = -L 'D:/ProgramData/anaconda3/libs'
DEPS = lanmslib.h
CXX_SOURCES = lanmslib.cpp include/clipper/clipper.cpp
LIB_SO = adaptor.pyd
$(LIB_SO): $(CXX_SOURCES) $(DEPS)
$(CXX) -o $@ $(CXXFLAGS) $(LDFLAGS) $(CXX_SOURCES) -lpython3 -lpython37 --shared -fPIC//根据libs库里的实际情况修改
clean:
rm -rf $(LIB_SO)
- 编译lanms库需要python库
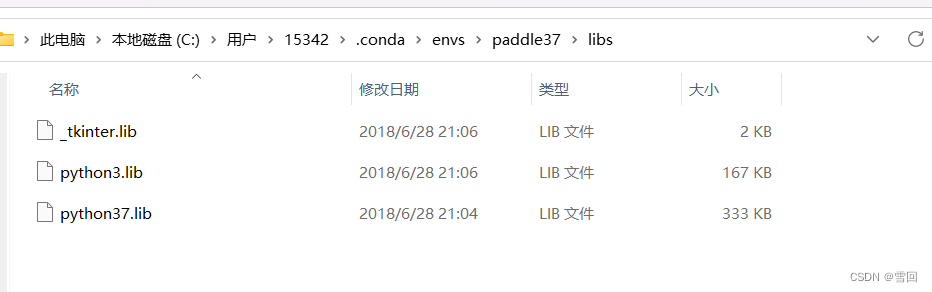
- 下载mingw(参考博客https://zhuanlan.zhihu.com/p/355510947)
在当前目录make编译出库
编译时报错::hypot’ has not been declared,解决办法见https://blog.csdn.net/qq_26705249/article/details/119023742即可编译成功
编译完成后将lanms整个文件夹放入该conda环境的site-packages里即可在该环境下调用
3.ImportError: cannot import name ‘_print_arguments’ from 'paddle.distributed.utils等
安装包的问题解决了,然后在PaddleOCR-release-2.6路径下开始运行训练命令
python3 tools/train.py -c configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml -o Global.pretrained_model=./pretrain_models/en_PP-OCRv3_rec_train/best_accuracy
会开始报类似ImportError: cannot import name ‘_print_arguments’ from 'paddle.distributed.utils的错,可以说我看了非常多的博客教程,都说是要升级paddle版本,而已知我使用的版本已经是当前最新的版本,所以这些博客并没有将问题解决,我使用自己的方法将该问题解决了

报错信息大概如图片所示,它会指明具体的报错文件路径与报错的行数,** 只需要将这些报错的import代码行注释掉即可**,我看了下这些缺少的都是utils文件夹内的文件,最新版根本就没有,是paddle库自己问题,这些用来import的包,大概都是用来写log的,注释掉并不会产生什么影响,然后代码里用到关于这个包的函数都是用来写log的,我直接将这些函数用print代替,这个报错就完美解决掉了。
4.报错UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xbc in position 2: invalid start byt
在训练的时候会读取标注文件,我的标注文件里面有中文,所以识别不了,同样是找到报错地方,然后按照https://blog.csdn.net/sunflower_sara/article/details/103957385这个博客讲的方法改就可以了。
5.no kernel image is available for execution on the device paddle
该类问题一般是cuda cudnn的版本与paddle库的版本对不上所导致的,但是一般会提示你应该装什么版本
Please NOTE: device: 0, GPU Compute Capability: 8.6, Driver API Version: 11.6, Runtime API Version: 11.6
W0605 14:02:02.797951 12376 gpu_resources.cc:91] device: 0, cuDNN Version: 8.0.
[2023/06/05 14:02:06] ppocr INFO: train dataloader has 11 iters
[2023/06/05 14:02:06] ppocr INFO: valid dataloader has 2 iters
[2023/06/05 14:02:08] ppocr INFO: load pretrain successful from wjp/ch_PP-OCRv3_rec_train/best_accuracy
[2023/06/05 14:02:08] ppocr INFO: During the training process, after the 0th iteration, an evaluation is run every 2000 iterations
W0605 14:02:27.800992 12376 gpu_resources.cc:201] WARNING: device: . The installed Paddle is compiled with CUDNN 8.4, but CUDNN version in your machine is 8.0, which may cause serious incompatible bug. Please recompile or reinstall Paddle with compatible CUDNN version.
我这个是paddlepaddle_gpu==2.3.2.post116,提示需要cuda11.6与cudnn8.4版本
比较好的安装教程https://blog.csdn.net/jhsignal/article/details/111401628
6.Could not locate zlibwapi.dll. Please make sure it is in your library path
解决办法:https://blog.csdn.net/Chaos_Happy/article/details/124064428
7.Out of memory error on GPU 0. Cannot allocate 60.000000MB memory on GPU 0, 9.999390GB memory has been allocated and available memory is only 0.000000B.
参考博客https://blog.csdn.net/zhuiyuanzhongjia/article/details/118361067
于是将训练的配置yml文件中的batch_size_per_card参数不断改小(除以2),直到不再报这个错即可。
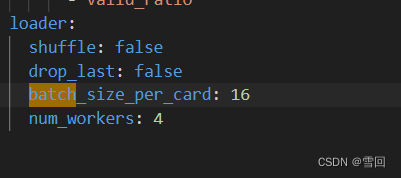
到这里即可完美的开始训练啦!!
非常好的常用问题官方解答手册
https://gitee.com/paddlepaddle/PaddleOCR/blob/release/2.6/doc/doc_ch/FAQ.md#12