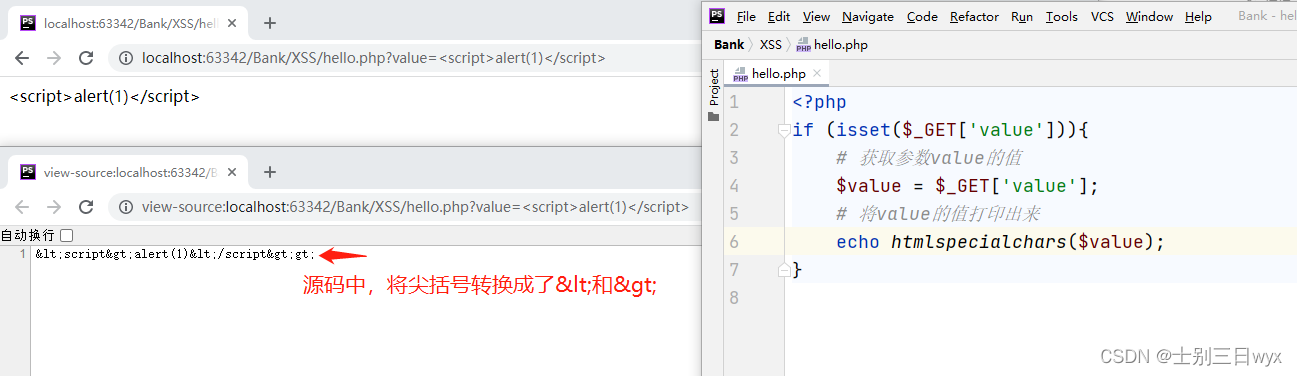
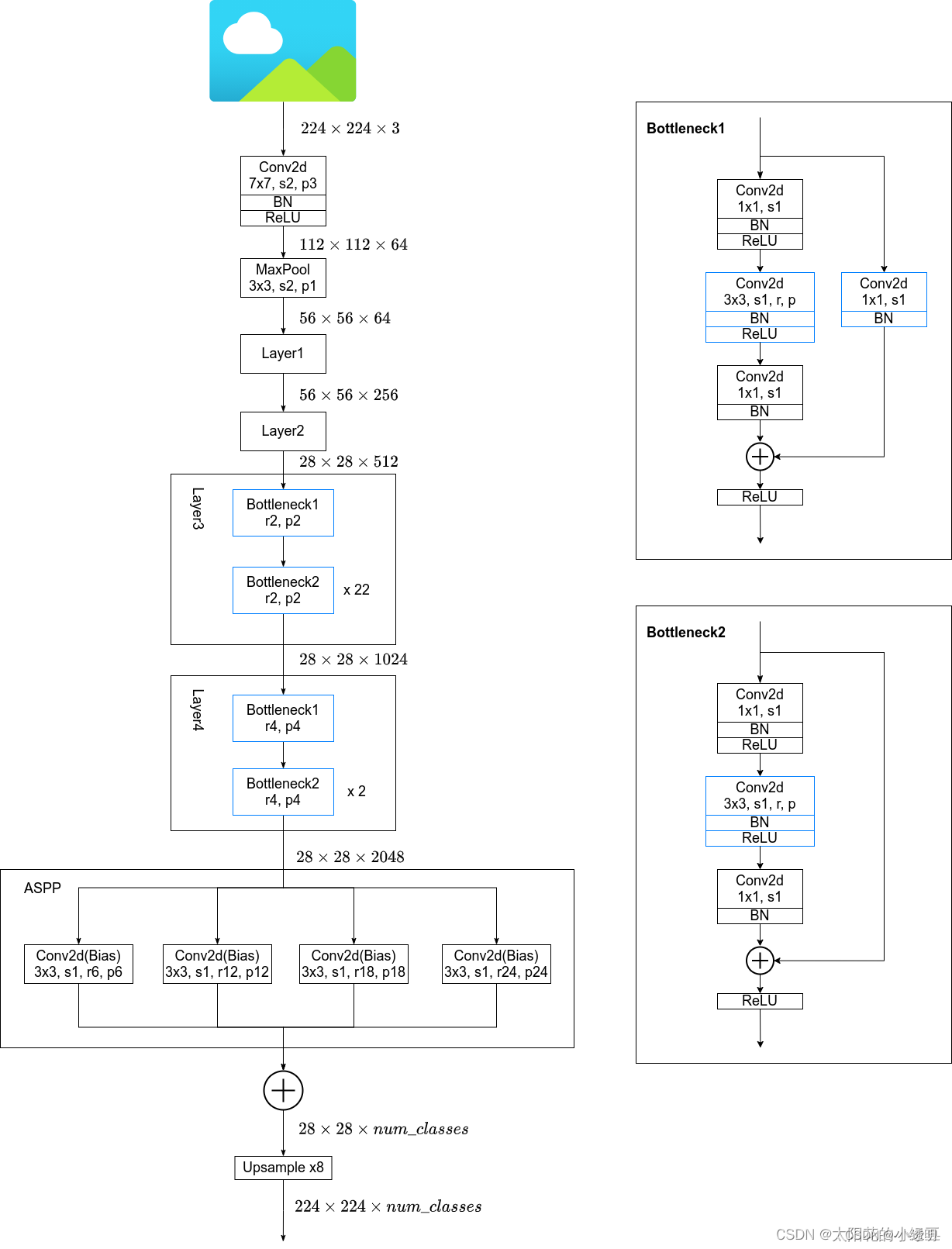
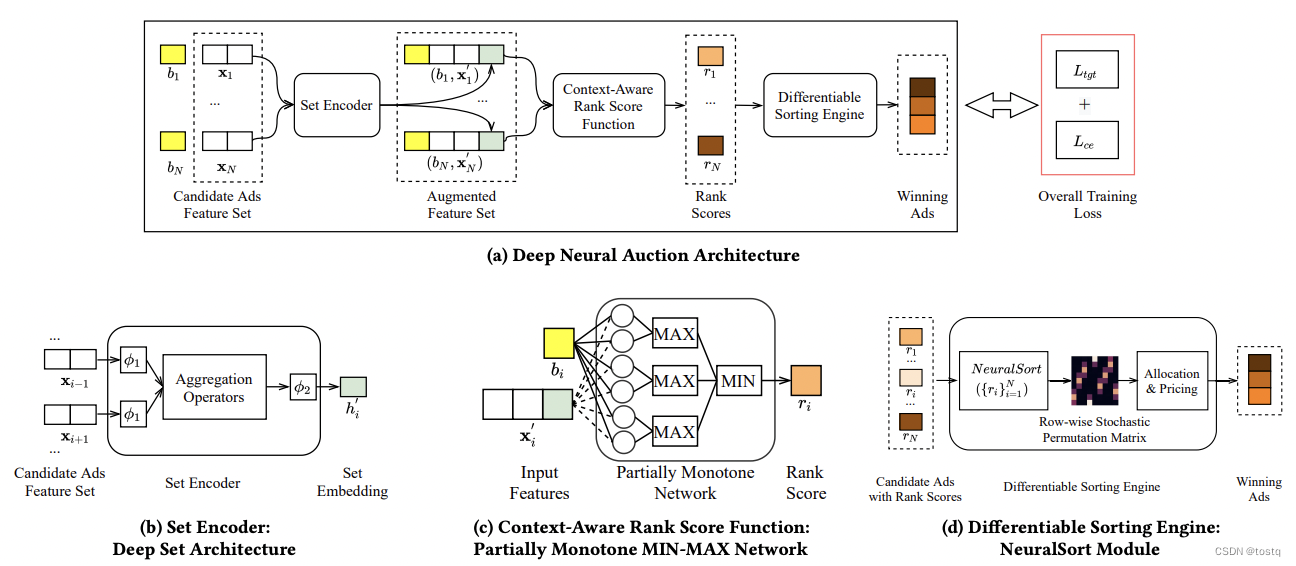
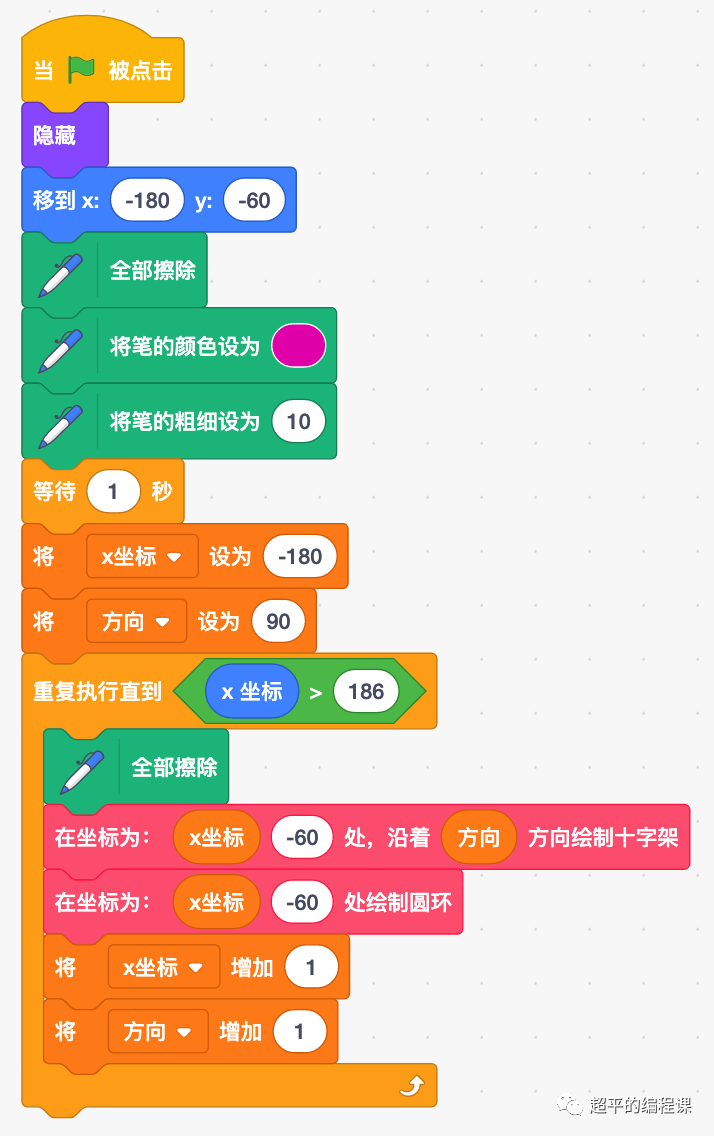
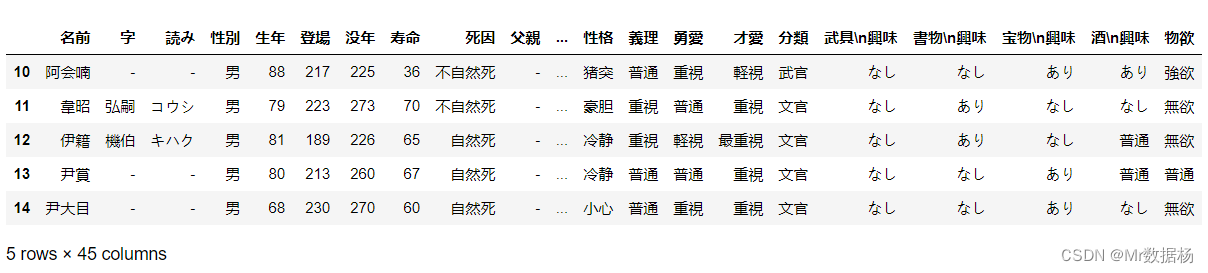
针对CNN优化的总结
- 使用没有 batchnorm 的 ELU 非线性或者有 batchnorm 的 ReLU。
- 用类似1*1的网络结构预训练RGB数据, 能得到更好的效果。
- 使用线性学习率衰退策略。
- 使用平均和最大池化层的和。
- 使用大约 128(0.005) 到 256 (0.01)的 mini-batch 大小。如果这对你的 GPU 而言太大,将学习率按比例降到这个大小就行。
- 使用卷积层代替之前的MLP中的线性层,并用平均池化层预测。
- 当研究增加训练集大小的时候,需要确定数据集对性能提升的平衡点。
- 数据的质量要比数据大小更重要。
- 如果你不能增加输入图像的大小,在随后的层上减少步幅(stride),这样做有同样的效果。
- 如果你的网络有复杂和高度优化的架构,像是 GoogLeNet,那修改一定要谨慎。
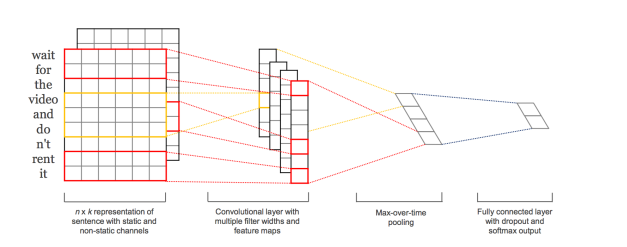
有助于充分利用 DNN 的小技巧
记得要 shuffle。不要让你的网络通过完全相同的 minibatch,如果框架允许,在每个 epoch 都 shuffle 一次。
扩展数据集。DNN 需要大量的数据,而且模型在小的数据集上很容易过拟合。我强烈建议你要扩展原始的数据集。如果你的是一个视觉任务,可以增加噪点、增白,减少像素,旋转或色移,模糊,等等可以扩展的一切。有一点不好的是,假如你扩展得太大,可能训练的数据大多数是相同的。我创建了一个应用随机变换的层来解决这个问题,这样就不会有相同的样本。若果你用的是语音数据,可以进行移位和失真处理。
在整个数据集上训练之前,先在非常小的子数据集上训练进行过拟合,这样你会知道你的网络可以收敛。这个 tip 来自 Karpathy。
始终使用 dropout 将过拟合的几率最小化。在大小 > 256 (完全连接层或卷积层)之后就应该使用 dropout。关于这一点有一篇很好的论文:Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning [Gal Yarin & Zoubin Ghahramani,2015].
避免 LRN 池化,MAX 池化会更快。
避免 Sigmoid/TanH 的门,它们代价昂贵,容易饱和,而且可能会停止反向传播。实际上,你的网络越深,就越应该避免使用 Sigmoid 和 TanH。可以使用更便宜而且更有效的 ReLU 和 PreLU 的门,正如在 Yoshua Bengio 等人的论文 Deep Sparse Rectifier Neural Networks 中所提到的,这两者能够促进稀疏性,而且它们的反向传播更加鲁棒。
在最大池化之前不要使用 ReLU 或 PreLU ,而是在保存计算之后使用它。
不要使用 ReLU ,它们太旧了。虽然他们是非常有用的非线性函数,可以解决很多问题。但是,你可以试试用它微调一个新模型,由于 ReLU 阻碍反向传播,初始化不好,你没法得到任何微调效果。但是你应该用 PreLU 以及一个非常小的乘数,通常是0.1。使用 PreLU 的话收敛更快,而且不会像 ReLU 那样在初始阶段被卡住。ELU 也很好,但成本高。
经常使用批标准化。参考论文:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift [Sergey Ioffe & Christian Szegedy,2015]。这会很有效。批标准化允许更快的收敛(非常快)以及更小的数据集。这样你能够节省时间和资源。
虽然大多数人喜欢删除平均值,不过我不喜欢。我喜欢压缩输入数据为[-1,+1]。这可以说是训练和部署方面的技巧,而不是针对提升性能的技巧。
要能适用更小的模型。假如你是像我这样部署深度学习模型,你很快就会体会到把千兆字节规模的模型推给用户或地球另一端的服务器的痛苦。哪怕要牺牲一些准确度,也应该小型化。
假如你使用比较小的模型,可以试试 ensemble。通常 ensemble 5个网络能够提升准确度约3%。
尽可能使用 xavier 初始化。你可以只在大的完全连接层上使用它,然后避免在 CNN 层上使用。有关这点的解释可以阅读这篇文章:An Explanation of Xavier Initialization(by Andy Jones)
如果你的输入数据有空间参数,可以试试端到端的 CNN。可以阅读这篇论文:SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size [Forrest N. Iandola et. al. 2016],它介绍了一种新的方法,而且性能非常好,你可以尝试应用上面提到的tips。
修改你的模型,只要可能就使用 1x1 的 CNN 层,它的位置对提高性能很有帮助。
假如没有高端的 GPU,就不要尝试训练任何东西了。
假如你要利用模型或你自己的层来制作模板,记得把所有东西参数化,否则你得重建所有二进制文件。
最后,要明白你在做什么。深度学习就像是机器学习里的中子弹,它不是任何任务、任何时候都有效的。了解你正在使用的结构以及你试图达成的目的,才不至于盲目地复制模型。
提升算法性能思路
这个列表里提到的思路并非完全,但是一个好的开始。
我的目的是给出很多可以尝试的思路,希望其中的一或两个你之前没有想到。你经常只需要一个好的想法就能得到性能提升。
如果你能从其中一个思路中得到结果,请在评论区告诉我。我很高兴能得知这些好消息。
如果你有更多的想法,或者是所列思路的拓展,也请告诉我,我和其他读者都将受益!有时候仅仅是一个想法或许就能使他人得到突破。
我将此博文分为四个部分:
1. 通过数据提升性能
2. 通过算法提升性能
3. 通过算法调参提升性能
4. 通过嵌套模型提升性能
通常来讲,随着列表自上而下,性能的提升也将变小。例如,对问题进行新的架构或者获取更多的数据,通常比调整最优算法的参数能带来更好的效果。虽然并不总是这样,但是通常来讲是的。
我已经把相应的链接加入了博客的教程中,相应网站的问题中,以及经典的Neural Net FAQ中。
部分思路只适用于人工神经网络,但是大部分是通用的。通用到足够你用来配合其他技术来碰撞出提升模型性能的方法。
OK,现在让我们开始吧。
1. 通过数据提升性能
对你的训练数据和问题定义进行适当改变,你能得到很大的性能提升。或许是最大的性能提升。
以下是我将要提到的思路:
-
获取更多数据
-
创造更多数据
-
重放缩你的数据
-
转换你的数据
-
特征选取
-
重架构你的问题
1.1 获取更多数据
你能获取更多训练数据吗?
你的模型的质量通常受到你的训练数据质量的限制。为了得到最好的模型,你首先应该想办法获得最好的数据。你也想尽可能多的获得那些最好的数据。
有更多的数据,深度学习和其他现代的非线性机器学习技术有更全的学习源,能学得更好,深度学习尤为如此。这也是机器学习对大家充满吸引力的很大一个原因(世界到处都是数据)。
更多的数据并不是总是有用,但是确实有帮助。于我而言,如果可以,我会选择获取更多的数据。
可以参见以下相关阅读:
· Datasets Over Algorithms(www.edge.org/response-detail/26587)
1.2 创造更多数据
上一小节说到了有了更多数据,深度学习算法通常会变的更好。有些时候你可能无法合理地获取更多数据,那你可以试试创造更多数据。
-
如果你的数据是数值型向量,可以随机构造已有向量的修改版本。
-
如果你的数据是图片,可以随机构造已有图片的修改版本(平移、截取、旋转等)。
-
如果你的数据是文本,类似的操作……
这通常被称作数据扩增(data augmentation)或者数据生成(data generation)。
你可以利用一个生成模型。你也可以用一些简单的技巧。例如,针对图片数据,你可以通过随机地平移或旋转已有图片获取性能的提升。如果新数据中包含了这种转换,则提升了模型的泛化能力。
这也与增加噪声是相关的,我们习惯称之为增加扰动。它起到了与正则化方法类似的作用,即抑制训练数据的过拟合。
以下是相关阅读:
-
Image Augmentation for Deep Learning With Keras(http://machinelearningmastery.com/image-augmentation-deep-learning-keras/)
-
What is jitter? (Training with noise)(ftp://ftp.sas.com/pub/neural/FAQ3.html#A_jitter)
1.3 重缩放(rescale)你的数据
这是一个快速获得性能提升的方法。
当应用神经网络时,一个传统的经验法则是:重缩放(rescale)你的数据至激活函数的边界。
如果你在使用sigmoid激活函数,重缩放你的数据到0和1的区间里。如果你在使用双曲正切(tanh)激活函数,重缩放数据到-1和1的区间里。
这种方法可以被应用到输入数据(x)和输出数据(y)。例如,如果你在输出层使用sigmoid函数去预测二元分类的结果,应当标准化y值,使之成为二元的。如果你在使用softmax函数,你依旧可以通过标准化y值来获益。
这依旧是一个好的经验法则,但是我想更深入一点。我建议你可以参考下述方法来创造一些训练数据的不同的版本:
-
归一化到0和1的区间。
-
重放缩到-1和1的区间
-
标准化(译者注:标准化数据使之成为零均值,单位标准差)
然后对每一种方法,评估你的模型的性能,选取最好的进行使用。如果你改变了你的激活函数,重复这一过程。
在神经网络中,大的数值累积效应(叠加叠乘)并不是好事,除上述方法之外,还有其他的方法来控制你的神经网络中数据的数值大小,譬如归一化激活函数和权重,我们会在以后讨论这些技术。
以下为相关阅读:
-
Should I standardize the input variables (column vectors)?(ftp://ftp.sas.com/pub/neural/FAQ2.html#A_std)
-
How To Prepare Your Data For Machine Learning in Python with Scikit-Learn(http://machinelearningmastery.com/prepare-data-machine-learning-python-scikit-learn/)
1.4 数据变换
这里的数据变换与上述的重缩放方法类似,但需要更多工作。
你必须非常熟悉你的数据。通过可视化来考察离群点。
猜测每一列数据的单变量分布。
-
列数据看起来像偏斜的高斯分布吗?考虑用Box-Cox变换调整偏态。
-
列数据看起来像指数分布吗?考虑用对数变换。
-
列数据看起来有一些特征,但是它们被一些明显的东西遮盖了,尝试取平方或者开平方根来转换数据
-
你能离散化一个特征或者以某种方式组合特征,来更好地突出一些特征吗?
依靠你的直觉,尝试以下方法。
-
你能利用类似PCA的投影方法来预处理数据吗?
-
你能综合多维特征至一个单一数值(特征)吗?
-
你能用一个新的布尔标签去发现问题中存在一些有趣的方面吗?
-
你能用其他方法探索出目前场景下的其他特殊结构吗?
神经网层擅长特征学习(feature engineering)。它(自己)可以做到这件事。但是如果你能更好的发现问题到网络中的结构,神经网层会学习地更快。你可以对你的数据就不同的转换方式进行抽样调查,或者尝试特定的性质,来看哪些有用,哪些没用。
以下是相关阅读:
-
How to Define Your Machine Learning Problem(http://machinelearningmastery.com/how-to-define-your-machine-learning-problem/)
-
Discover Feature Engineering, How to Engineer Features and How to Get Good at It(http://machinelearningmastery.com/discover-feature-engineering-how-to-engineer-features-and-how-to-get-good-at-it/)
-
How To Prepare Your Data For Machine Learning in Python with Scikit-Learn(http://machinelearningmastery.com/prepare-data-machine-learning-python-scikit-learn/)
1.5 特征选择
一般说来,神经网络对不相关的特征是具有鲁棒的(校对注:即不相关的特征不会很大影响神经网络的训练和效果)。它们会用近似于0的权重来弱化那些没有预测能力的特征的贡献。
尽管如此,这些无关的数据特征,在训练周期依旧要耗费大量的资源。所以你能去除数据里的一些特征吗?
有许多特征选择的方法和特征重要性的方法,这些方法能够给你提供思路,哪些特征该保留,哪些特征该剔除。最简单的方式就是对比所有特征和部分特征的效果。
同样的,如果你有时间,我建议在同一个网络中尝试选择不同的视角来看待你的问题,评估它们,来看看分别有怎样的性能。
-
或许你利用更少的特征就能达到同等甚至更好的性能。而且,这将使模型变得更快!
-
或许所有的特征选择方法都剔除了同样的特征子集。很好,这些方法在没用的特征上达成了一致。
-
或许筛选过后的特征子集,能带给特征工程的新思路。
以下是相关阅读:
-
An Introduction to Feature Selection(http://machinelearningmastery.com/an-introduction-to-feature-selection/)
-
Feature Selection For Machine Learning in Python(http://machinelearningmastery.com/feature-selection-machine-learning-python/)
1.6 重新架构你的问题
有时候要试试从你当前定义的问题中跳出来,想想你所收集到的观察值是定义你问题的唯一方式吗?或许存在其他方法。或许其他构建问题的方式能够更好地揭示待学习问题的结构。
我真的很喜欢这个尝试,因为它迫使你打开自己的思路。这确实很难,尤其是当你已经对当前的方法投入了大量的时间和金钱时。
但是咱们这么想想,即使你列出了3-5个可供替代的建构方案,而且最终还是放弃了它们,但这至少说明你对当前的方案更加自信了。
-
看看能够在一个时间窗(时间周期)内对已有的特征/数据做一个合并。
-
或许你的分类问题可以成为一个回归问题(有时候是回归到分类)。
-
或许你的二元输出可以变成softmax输出?
-
或许你可以转而对子问题进行建模。
仔细思考你的问题,最好在你选定工具之前就考虑用不同方法构建你的问题,因为此时你对解决方案并没有花费太多的投入。除此之外,如果你在某个问题上卡住了,这样一个简单的尝试能释放更多新的想法。
而且,这并不代表你之前的工作白干了,关于这点你可以看看后续的模型嵌套部分。
以下为相关阅读:
-
How to Define Your Machine Learning Problem(http://machinelearningmastery.com/how-to-define-your-machine-learning-problem/)
2.通过算法提升性能
机器学习当然是用算法解决问题。
所有的理论和数学都是描绘了应用不同的方法从数据中学习一个决策过程(如果我们这里只讨论预测模型)。
你已经选择了深度学习来解释你的问题。但是这真的是最好的选择吗?在这一节中,我们会在深入到如何最大地发掘你所选择的深度学习方法之前,接触一些算法选择上的思路。
下面是一个简要列表:
-
对算法进行抽样调查
-
借鉴已有文献
-
重采样方法
下面我解释下上面提到的几个方法。
2.1 对算法进行抽样调查
其实你事先无法知道,针对你的问题哪个算法是最优的。如果你知道,你可能就不需要机器学习了。那有没有什么数据(办法)可以证明你选择的方法是正确的?
让我们来解决这个难题。当从所有可能的问题中平均来看各算法的性能时,没有哪个算法能够永远胜过其他算法。所有的算法都是平等的,下面是在no free lunch theorem中的一个总结。
或许你选择的算法不是针对你的问题最优的那个
我们不是在尝试解决所有问题,算法世界中有很多新热的方法,可是它们可能并不是针对你数据集的最优算法。
我的建议是收集(证据)数据指标。接受更好的算法或许存在这一观点,并且给予其他算法在解决你的问题上“公平竞争”的机会。
抽样调查一系列可行的方法,来看看哪些还不错,哪些不理想。
-
首先尝试评估一些线性方法,例如逻辑回归(logistic regression)和线性判别分析(linear discriminate analysis)。
-
评估一些树类模型,例如CART, 随机森林(Random Forest)和Gradient Boosting。
-
评估一些实例方法,例如支持向量机(SVM)和K-近邻(kNN)。
-
评估一些其他的神经网络方法,例如LVQ, MLP, CNN, LSTM, hybrids等
选取性能最好的算法,然后通过进一步的调参和数据准备来提升。尤其注意对比一下深度学习和其他常规机器学习方法,对上述结果进行排名,比较他们的优劣。
很多时候你会发现在你的问题上可以不用深度学习,而是使用一些更简单,训练速度更快,甚至是更容易理解的算法。
以下为相关阅读:
-
A Data-Driven Approach to Machine Learning(http://machinelearningmastery.com/a-data-driven-approach-to-machine-learning/)
-
Why you should be Spot-Checking Algorithms on your Machine Learning Problems(http://machinelearningmastery.com/why-you-should-be-spot-checking-algorithms-on-your-machine-learning-problems/)
-
Spot-Check Classification Machine Learning Algorithms in Python with scikit-learn(http://machinelearningmastery.com/spot-check-classification-machine-learning-algorithms-python-scikit-learn/)
2.2 借鉴已有文献
方法选择的一个捷径是借鉴已有的文献资料。可能有人已经研究过与你的问题相关的问题,你可以看看他们用的什么方法。
你可以阅读论文,书籍,博客,问答网站,教程,以及任何能在谷歌搜索到的东西。
写下所有的想法,然后用你的方式把他们研究一遍。
这不是复制别人的研究,而是启发你想出新的想法,一些你从没想到但是却有可能带来性能提升的想法。
发表的研究通常都是非常赞的。世界上有非常多聪明的人,写了很多有趣的东西。你应当好好挖掘这个“图书馆”,找到你想要的东西。
以下为相关阅读:
-
How to Research a Machine Learning Algorithm(http://machinelearningmastery.com/how-to-research-a-machine-learning-algorithm/)
-
Google Scholar(http://scholar.google.com/)
2.3 重采样方法
你必须知道你的模型效果如何。你对模型性能的估计可靠吗?
深度学习模型在训练阶段非常缓慢。这通常意味着,我们无法用一些常用的方法,例如k层交叉验证,去估计模型的性能。
-
或许你在使用一个简单的训练集/测试集分割,这是常规套路。如果是这样,你需要确保这种分割针对你的问题具有代表性。单变量统计和可视化是一个好的开始。
-
或许你能利用硬件来加速估计的过程。例如,如果你有集群或者AWS云端服务(Amazon Web Services)账号,你可以并行地训练n个模型,然后获取结果的均值和标准差来得到更鲁棒的估计。
-
或许你可以利用hold-out验证方法来了解模型在训练后的性能(这在早停法(early stopping)中很有用,后面会讲到)。
-
或许你可以先隐藏一个完全没用过的验证集,等到你已经完成模型选择之后再使用它。
而有时候另外的方式,或许你能够让数据集变得更小,以及使用更强的重采样方法。
-
有些情况下你会发现在训练集的一部分样本上训练得到的模型的性能,和在整个数据集上训练得到的模型的性能有很强的相关性。也许你可以先在小数据集上完成模型选择和参数调优,然后再将最终的方法扩展到全部数据集上。
-
或许你可以用某些方式限制数据集,只取一部分样本,然后用它进行全部的建模过程。
以下为相关阅读:
-
Evaluate the Performance Of Deep Learning Models in Keras(http://machinelearningmastery.com/evaluate-performance-deep-learning-models-keras/)
-
Evaluate the Performance of Machine Learning Algorithms in Python using Resampling(http://machinelearningmastery.com/evaluate-performance-machine-learning-algorithms-python-using-resampling/)
3. 通过算法调参提升性能
这通常是工作的关键所在。你经常可以通过抽样调查快速地发现一个或两个性能优秀的算法。但是如果想得到最优的算法可能需要几天,几周,甚至几个月。
为了获得更优的模型,以下是对神经网络算法进行参数调优的几点思路:
-
诊断(Diagnostics)
-
权重初始化(Weight Initialization)
-
学习速率(Learning Rate)
-
激活函数
-
网络拓扑(Network Topology)
-
批次和周期(Batches and Epochs)
-
正则化
-
优化和损失
-
早停法
你可能需要训练一个给定“参数配置”的神经网络模型很多次(3-10次甚至更多),才能得到一个估计性能不错的参数配置。这一点几乎适用于这一节中你能够调参的所有方面。
关于超参数优化请参阅博文:
-
How to Grid Search Hyperparameters for Deep Learning Models in Python With Keras(http://machinelearningmastery.com/grid-search-hyperparameters-deep-learning-models-python-keras/)
3.1 诊断
如果你能知道为什么你的模型性能不再提高了,你就能获得拥有更好性能的模型。
你的模型是过拟合还是欠拟合?永远牢记这个问题。永远。
模型总是会遇到过拟合或者欠拟合,只是程度不同罢了。一个快速了解模型学习行为的方法是,在每个周期,评估模型在训练集和验证集上的表现,并作出图表。
-
如果训练集上的模型总是优于验证集上的模型,你可能遇到了过拟合,你可以使用诸如正则化的方法。
-
如果训练集和验证集上的模型都很差,你可能遇到了欠拟合,你可以提升网络的容量,以及训练更多或者更久。
-
如果有一个拐点存在,在那之后训练集上的模型开始优于验证集上的模型,你可能需要使用早停法。
经常画一画这些图表,学习它们来了解不同的方法,你能够提升模型的性能。这些图表可能是你能创造的最有价值的(模型状态)诊断信息。
另一个有用的诊断是网络模型判定对和判定错的观察值。
-
对于难以训练的样本,或许你需要更多的数据。
-
或许你应该剔除训练集中易于建模的多余的样本。
-
也许可以尝试对训练集划分不同的区域,在特定区域中用更专长的模型。
以下为相关阅读:
-
Display Deep Learning Model Training History in Keras(http://machinelearningmastery.com/display-deep-learning-model-training-history-in-keras/)
-
Overfitting and Underfitting With Machine Learning Algorithms(http://machinelearningmastery.com/overfitting-and-underfitting-with-machine-learning-algorithms/)
3.2 权重初始化
经验法则通常是:用小的随机数进行初始化。
在实践中,这可能依旧效果不错,但是对于你的网络来说是最佳的吗?对于不同的激活函数也有一些启发式的初始化方法,但是在实践应用中并没有太多不同。
固定你的网络,然后尝试多种初始化方式。
记住,权重是你的模型真正的参数,你需要找到他们。有很多组权重都能有不错的性能表现,但我们要尽量找到最好的。
-
尝试所有不同的初始化方法,考察是否有一种方法在其他情况不变的情况下(效果)更优。
-
尝试用无监督的方法,例如自动编码(autoencoder),来进行预先学习。
-
尝试使用一个已经存在的模型,只是针对你的问题重新训练输入层和输出层(迁移学习(transfer learning))
需要提醒的一点是,改变权重初始化方法和激活函数,甚至优化函数/损失函数紧密相关。
以下为相关阅读:
-
Initialization of deep networks(http://deepdish.io/2015/02/24/network-initialization/)
3.3 学习率
调整学习率很多时候也是行之有效的时段。
以下是可供探索的一些想法:
-
实验很大和很小的学习率
-
格点搜索文献里常见的学习速率值,考察你能学习多深的网络。
-
尝试随周期递减的学习率
-
尝试经过固定周期数后按比例减小的学习率。
-
尝试增加一个动量项(momentum term),然后对学习速率和动量同时进行格点搜索。
越大的网络需要越多的训练,反之亦然。如果你添加了太多的神经元和层数,适当提升你的学习速率。同时学习率需要和训练周期,batch size大小以及优化方法联系在一起考虑。
以下为相关阅读:
-
Using Learning Rate Schedules for Deep Learning Models in Python with Keras(http://machinelearningmastery.com/using-learning-rate-schedules-deep-learning-models-python-keras/)
-
What learning rate should be used for backprop?(ftp://ftp.sas.com/pub/neural/FAQ2.html#A_learn_rate)
3.4 激活函数
你或许应该使用修正激活函数(rectifier activation functions)。他们也许能提供更好的性能。
在这之前,最早的激活函数是sigmoid和tanh,之后是softmax, 线性激活函数,或者输出层上的sigmoid函数。我不建议尝试更多的激活函数,除非你知道你自己在干什么。
尝试全部三种激活函数,并且重缩放你的数据以满足激活函数的边界。
显然,你想要为输出的形式选择正确的传递函数,但是可以考虑一下探索不同表示。例如,把在二元分类问题上使用的sigmoid函数切换到回归问题上使用的线性函数,然后后置处理你的输出。这可能需要改变损失函数使之更合适。详情参阅数据转换那一节。
以下为相关阅读:
-
Why use activation functions?(ftp://ftp.sas.com/pub/neural/FAQ2.html#A_act)
3.5 网络拓扑
网络结构的改变能带来好处。
你需要多少层以及多少个神经元?抱歉没有人知道。不要问这种问题…
那怎么找到适用你的问题的配置呢?去实验吧。
-
尝试一个隐藏层和许多神经元(广度模型)。
-
尝试一个深的网络,但是每层只有很少的神经元(深度模型)。
-
尝试上述两种方法的组合。
-
借鉴研究问题与你的类似的论文里面的结构。
-
尝试拓扑模式(扇出(fan out)然后扇入(fan in))和书籍论文里的经验法则(下有链接)
选择总是很困难的。通常说来越大的网络有越强的代表能力,或许你需要它。越多的层数可以提供更强的从数据中学到的抽象特征的能力。或许需要它。
深层的神经网络需要更多的训练,无论是训练周期还是学习率,都应该相应地进行调整。
以下为相关阅读:
这些链接会给你很多启发该尝试哪些事情,至少对我来说是的。
-
How many hidden layers should I use?(ftp://ftp.sas.com/pub/neural/FAQ3.html#A_hl)
-
How many hidden units should I use?(ftp://ftp.sas.com/pub/neural/FAQ3.html#A_hu)
3.6 Batches和周期
batch size大小会决定最后的梯度,以及更新权重的频度。一个周期(epoch)指的是神经网络看一遍全部训练数据的过程。
你是否已经试验了不同的批次batch size和周期数?
之前,我们已经讨论了学习率,网络大小和周期之间的关系。
在很深的网络结构里你会经常看到:小的batch size配以大的训练周期。
下面这些或许能有助于你的问题,也或许不能。你要在自己的数据上尝试和观察。
-
尝试选取与训练数据同大小的batch size,但注意一下内存(批次学习(batch learning))
-
尝试选取1作为batch size(在线学习(online learning))
-
尝试用格点搜索不同的小的batch size(8,16,32,…)
-
分别尝试训练少量周期和大量周期。
考虑一个接近无穷的周期值(持续训练),去记录到目前为止能得到的最佳的模型。
一些网络结构对batch size更敏感。我知道多层感知器(Multilayer Perceptrons)通常对batch size是鲁棒的,而LSTM和CNNs比较敏感,但是这只是一个说法(仅供参考)。
以下为相关阅读:
-
What are batch, incremental, on-line … learning?(ftp://ftp.sas.com/pub/neural/FAQ2.html#A_styles)
-
Intuitively, how does mini-batch size affect the performance of (stochastic) gradient descent?(https://www.quora.com/Intuitively-how-does-mini-batch-size-affect-the-performance-of-stochastic-gradient-descent)
3.7 正则化
正则化是一个避免模型在训练集上过拟合的好方法。
神经网络里最新最热的正则化技术是dropout方法,你是否试过?dropout方法在训练阶段随机地跳过一些神经元,驱动这一层其他的神经元去捕捉松弛。简单而有效。你可以从dropout方法开始。
-
格点搜索不同的丢失比例。
-
分别在输入,隐藏层和输出层中试验dropout方法
-
dropout方法也有一些拓展,比如你也可以尝试drop connect方法。
也可以尝试其他更传统的神经网络正则化方法,例如:
-
权重衰减(Weight decay)去惩罚大的权重
-
激活约束(Activation constraint)去惩罚大的激活值
你也可以试验惩罚不同的方面,或者使用不同种类的惩罚/正则化(L1, L2, 或者二者同时)
以下是相关阅读:
-
Dropout Regularization in Deep Learning Models With Keras(http://machinelearningmastery.com/dropout-regularization-deep-learning-models-keras/)
-
What is Weight Decay?(ftp://ftp.sas.com/pub/neural/FAQ3.html#A_decay)
3.8 优化和损失
最常见是应用随机梯度下降法(stochastic gradient descent),但是现在有非常多的优化器。你试验过不同的优化(方法)过程吗?
随机梯度下降法是默认的选择。先好好利用它,配以不同的学习率和动量。
许多更高级的优化方法有更多的参数,更复杂,也有更快的收敛速度。好与坏,是不是需要用,取决于你的问题。
为了更好的利用好一个给定的(优化)方法,你真的需要弄明白每个参数的意义,然后针对你的问题通过格点搜索不同的的取值。困难,消耗时间,但是值得。
我发现了一些更新更流行的方法,它们可以收敛的更快,并且针对一个给定网络的容量提供了一个快速了解的方式,例如:
-
ADAM
-
RMSprop
你还可以探索其他优化算法,例如,更传统的(Levenberg-Marquardt)和不那么传统的(genetic algorithms)。其他方法能够为随机梯度下降法和其他类似方法提供好的出发点去改进。
要被优化的损失函数与你要解决的问题高度相关。然而,你通常还是有一些余地(可以做一些微调,例如回归问题中的均方误(MSE)和平均绝对误差(MAE)等),有时候变换损失函数还有可能获得小的性能提升,这取决于你输出数据的规模和使用的激活函数。
以下是相关阅读:
-
An overview of gradient descent optimization algorithms(http://sebastianruder.com/optimizing-gradient-descent/)
-
What are conjugate gradients, Levenberg-Marquardt, etc.?(ftp://ftp.sas.com/pub/neural/FAQ2.html#A_numanal)
-
On Optimization Methods for Deep Learning, 2011 PDF(http://ai.stanford.edu/~ang/papers/icml11-OptimizationForDeepLearning.pdf)
3.9 Early Stopping/早停法
一旦训练过程中出现(验证集)性能开始下降,你可以停止训练与学习。这可以节省很多时间,而且甚至可以让你使用更详尽的重采样方法来评估你的模型的性能。
早停法是一种用来避免模型在训练数据上的过拟合的正则化方式,它需要你监测模型在训练集以及验证集上每一轮的效果。一旦验证集上的模型性能开始下降,训练就可以停止。
如果某个条件满足(衡量准确率的损失),你还可以设置检查点(Checkpointing)来储存模型,使得模型能够继续学习。检查点使你能够早停而非真正的停止训练,因此在最后,你将有一些模型可供选择。
以下是相关阅读:
-
How to Check-Point Deep Learning Models in Keras(http://machinelearningmastery.com/check-point-deep-learning-models-keras/)
-
What is early stopping?(ftp://ftp.sas.com/pub/neural/FAQ3.html#A_stop)
4. 通过嵌套模型提升性能
你可以组合多个模型的预测能力。刚才提到了算法调参可以提高最后的性能,调参之后这是下一个可以提升的大领域。
事实上,你可以经常通过组合多个“足够好的”模型来得到优秀的预测能力,而不是通过组合多个高度调参的(脆弱的)模型。
你可以考虑以下三个方面的嵌套方式:
-
组合模型
-
组合视角
-
堆叠(Stacking)
4.1 组合模型
有时候我们干脆不做模型选择,而是直接组合它们。
如果你有多个不同的深度学习模型,在你的研究问题上每一个都表现的还不错,你可以通过取它们预测的平均值来进行组合。
模型差异越大,最终效果越好。例如,你可以应用非常不同的网络拓扑或者不同的技术。
如果每个模型都效果不错但是不同的方法/方式,嵌套后的预测能力将更加鲁棒。
每一次你训练网络,你初始化不同的权重,然后它会收敛到不同的最终权重。你可以多次重复这一过程去得到很多网络,然后把这些网络的预测值组合在一起。
它们的预测将会高度相关,但是在那些难以预测的特征上,它会给你一个意外的小提升。
以下是相关阅读:
-
Ensemble Machine Learning Algorithms in Python with scikit-learn(http://machinelearningmastery.com/ensemble-machine-learning-algorithms-python-scikit-learn/)
-
How to Improve Machine Learning Results(http://machinelearningmastery.com/how-to-improve-machine-learning-results/)
4.2 组合视角
同上述类似,但是从不同视角重构你的问题,训练你的模型。
同样,目标得到的是效果不错但是不同的模型(例如,不相关的预测)。得到不同的模型的方法,你可以依赖我们在数据那一小节中罗列的那些非常不同的放缩和转换方法。
你用来训练模型的转换方法越不同,你构建问题的方式越不同,你的结果被提升的程度就越高。
简单使用预测的均值将会是一个好的开始。
4.3 stacking/堆叠
你还可以学习如何最佳地组合多个模型的预测。这称作堆叠泛化(stacked generalization),或者简短来说就叫堆叠。
通常上,你使用简单线性回归方法就可以得到比取预测平均更好的结果,像正则化的回归(regularized regression),就会学习如何给不同的预测模型赋权重。基线模型是通过取子模型的预测均值得到的,但是应用学习了权重的模型会提升性能。
-
Stacked Generalization (Stacking)(http://machine-learning.martinsewell.com/ensembles/stacking/)
其余的可参考资源
别的地方有很多很好的资源,但是几乎没有能将所有想法串联在一起的。如果你想深入研究,我列出了如下资源和相应的博客,你能发现很多有趣的东西。
-
Neural Network FAQ(ftp://ftp.sas.com/pub/neural/FAQ.html)
-
How to Grid Search Hyperparameters for Deep Learning Models in Python With Keras(http://machinelearningmastery.com/grid-search-hyperparameters-deep-learning-models-python-keras/)
-
Must Know Tips/Tricks in Deep Neural Networks(http://lamda.nju.edu.cn/weixs/project/CNNTricks/CNNTricks.html)
-
How to increase validation accuracy with deep neural net?(http://stackoverflow.com/questions/37020754/how-to-increase-validation-accuracy-with-deep-neural-net)