《计算机操作系统(第三版)》(汤小丹)学习笔记
文章目录
- 5、进程通信(Inter-Process Communication)
- 5.1、进程通信的类型
- 5.1.1、共享存储器系统(Shared Memory System)
- 5.1.2、消息传递系统(Message Passing System)
- 5.1.3、管道通信系统(Pipe)
- 5.2、消息传递通信的实现方法
- 5.3、消息传递系统实现中的若干问题
- 5.4、消息缓冲队列通信机制
- 6、线程(Threads)
- 6.1、线程的基本概念
- 6.2、线程间的同步和通信
- 6.3、线程的实现方式
- 6.4、线程的实现
5、进程通信(Inter-Process Communication)
进程通信(IPC, Inter-Process Communication)是操作系统中实现不同进程间数据交换和信息传递的核心机制
信号量机制作为同步工具是卓有成效的,但作为通信工具,则不够理想,主要表现在下述两方面
- 效率低
- 通信对用户不透明
5.1、进程通信的类型
- 共享存储器系统(Shared Memory System)
- 消息传递系统(Message Passing System)
- 管道通信系统(Pipe)
5.1.1、共享存储器系统(Shared Memory System)
共享存储器系统(Shared Memory System)是进程通信的一种高效方式,其核心思想是让多个进程直接访问同一块物理内存区域。
(1)基于共享数据结构的通信方式
原理:
- 进程通过预定义的结构化数据对象(如链表、树、哈希表等)进行通信。这些数据结构在共享内存中创建,所有进程按约定规则读写特定字段。
特点:
- 强结构化:数据按固定格式组织,便于类型检查和错误预防
- 操作原子性:通常配合信号量实现关键操作的原子性(如插入/删除节点)
- 低灵活性:需提前定义数据结构,扩展性较差
典型场景:
- 实时系统监控(各进程更新统一的状态树)
- 多进程协作计算(如分布式算法中的共享参数表)
- 进程间传递复杂对象(如共享任务队列)
这种通信方式是低效的,只适用于传递相对少量的数据
(2)基于共享存储区的通信方式
原理:
- 将共享内存划分为多个独立存储区域(如缓冲区、堆等),各进程通过协商好的地址范围进行读写。
特点:
- 高度灵活:进程可自由管理自己的内存区域
- 弱结构化:数据格式由进程自行定义,适合动态数据
- 需显式同步:通常使用信号量或互斥锁保证数据一致性
典型场景:
- 大数据量实时传输(如音视频流处理)
- 动态内存分配(如多进程共享堆内存)
- 进程间传递二进制数据块(如图像传输)

选择建议
- 需要严格数据格式和类型安全时 → 选择共享数据结构
- 处理二进制流或动态内存分配时 → 选择共享存储区
- 高性能要求场景可结合两者:用共享数据结构管理元数据,用共享存储区传输实际数据
实际系统中常将两种方式结合使用,例如:用共享数据结构维护通信协议,用共享存储区传输原始数据,从而兼顾结构化和灵活性。
5.1.2、消息传递系统(Message Passing System)
进程通信中的消息传递系统(Message Passing System)是一种通过发送和接收结构化消息(message) 来实现进程间通信(IPC)的机制。与共享内存等直接访问内存的方式不同,消息传递系统强调通信的显式性和数据封装性,其设计核心思想可以概括为:“进程通过交换自包含的消息进行协作”。
计算机网络中 message 又称为报文
微内核与服务器之间的通信,无一例外地都采用了消息传递机制
一、核心组成要素
(1)消息(Message)
-
结构化数据单元,通常包含:
- 消息头:标识消息类型、发送者PID、优先级等元数据
- 消息体:实际传输的数据(支持多种数据类型,如整型、字符串、结构体等)
-
示例消息结构:
typedef struct {
int type; // 消息类型码
pid_t sender_pid; // 发送进程ID
union {
int int_data;
char* str_data;
struct complex_data* custom_data;
} payload; // 消息负载
} Message;
(2)消息队列(Message Queue)
-
内核管理的先进先出(FIFO)缓冲区
-
关键特性:
- 异步通信:发送方无需等待接收方立即处理
- 流量控制:队列满时阻塞发送方,空时阻塞接收方
- 多消息类型支持:通过type字段实现消息分类
(3)通信端口(Port)
- 进程用于接收消息的端点
- 两种主要类型:
- 临时端口:动态创建,通信结束后销毁
- 永久端口:预先定义,支持长期通信
二、实现方式分类
(1)直接通信(Direct Communication)
进程通过显式指定接收方PID发送消息
优点:通信路径明确,适合点对点通信
缺点:耦合度高,接收方PID变化需同步修改
// 发送消息
send(target_pid, &message, sizeof(message), 0);
// 接收消息
recv(source_pid, &message, sizeof(message), 0);
(2)间接通信(Indirect Communication)
通过共享消息队列/邮箱进行通信
优点:解耦发送方和接收方,支持一对多/多对多通信
缺点:需要额外机制管理队列访问
// 创建消息队列
mqd_t mq = mq_open("/my_queue", O_CREAT | O_RDWR, 0666, NULL);
// 发送消息到队列
mq_send(mq, (const char*)&message, sizeof(message), 0);
// 从队列接收消息
mq_receive(mq, (char*)&message, sizeof(message), NULL);
三、优缺点

5.1.3、管道通信系统(Pipe)
进程通信中的管道(Pipe)是一种经典的进程间通信(IPC)机制,基于生产者-消费者模型,允许具有共同祖先的进程通过共享文件描述符进行单向数据传输。其设计哲学可概括为:“数据像水流一样在管道中流动,从一端进入,另一端流出”。
一、核心特性解析
(1)单向通信
- 数据只能单向流动(从写端到读端)
- 若需双向通信,需创建两个管道
- 示例:
# 命令行管道示例(ls的输出作为grep的输入)
ls | grep ".txt"
(2)血缘关系限制
- 匿名管道(pipe()创建)仅适用于父子进程或兄弟进程
- 命名管道(FIFO,mkfifo()创建)允许无亲缘关系进程通信
(3)原子性保证
- 单次write()操作的数据量≤PIPE_BUF时(通常4096字节),保证原子写入
- 超过PIPE_BUF时可能分多次传输
(4)内核缓冲区
- 数据暂存在内核内存区域
- 读操作从缓冲区头部取数据
- 写操作从缓冲区尾部追加数据
二、与消息队列的对比

5.2、消息传递通信的实现方法
消息传递通信是进程间通信(IPC)的重要范式,其核心思想是通过结构化消息在进程间传递信息。根据通信过程中是否直接指定接收方,可分为直接通信和间接通信两种方式。
(1)直接通信方式
实现原理
点对点消息传递
- 发送进程需明确指定接收进程的标识符(如PID或端口号)
- 操作系统内核负责将消息直接投递到目标进程
#include <mqueue.h>
// 创建/打开消息队列
mqd_t mq = mq_open("/myqueue", O_CREAT | O_RDWR, 0666, NULL);
// 发送消息(直接指定接收队列)
char buffer[1024];
mq_send(mq, buffer, sizeof(buffer), 0);
// 接收消息(从指定队列获取)
ssize_t bytes = mq_receive(mq, buffer, sizeof(buffer), NULL);
特点分析

典型应用场景
- 实时系统:传感器数据采集与即时响应
- 客户端-服务器模型:已知固定服务端地址
- 任务调度系统:Worker 进程向 Manager 进程汇报状态
(2)间接通信方式
实现原理
通过共享数据结构通信
- 消息存储在消息队列、Mailbox(邮箱、信箱)或端口等中介结构中
- 发送方将消息存入队列,接收方从队列获取消息
#include <sys/msg.h>
// 创建/访问消息队列
int msgid = msgget(1234, 0666 | IPC_CREAT);
// 定义消息结构
struct msgbuf {
long mtype; // 消息类型
char mtext[512];
};
// 发送消息(指定消息类型)
struct msgbuf msg = {1, "Hello"};
msgsnd(msgid, &msg, sizeof(msg)-sizeof(long), 0);
// 接收消息(按类型过滤)
msgrcv(msgid, &msg, sizeof(msg)-sizeof(long), 1, 0);
特点分析

典型应用场景
- 分布式系统:微服务架构中的异步通信
- 事件驱动系统:GUI框架中的事件分发
- 批处理系统:任务队列中的作业调度
性能维度对比

信箱
在进程通信的信箱模型(Mailbox Model)中,信箱作为消息传递的中介,根据访问权限和使用方式可分为私用信箱、公用信箱和共享信箱。
私用信箱(Private Mailbox)
- 所有权:由进程独占创建,仅允许创建者访问
- 生命周期:随进程终止自动销毁
公用信箱(Public Mailbox)
- 所有权:由操作系统创建,可供多个进程访问
- 访问控制:通过权限位(如读/写/执行权限)管理
共享信箱(Shared Mailbox)
- 所有权:由多个协作进程共同创建和维护
- 同步机制:需显式处理并发访问(如信号量)

在利用信箱通信时,发送进程和接受进程之间存在以下四种关系
- 一对一
- 一对多(广播)
- 对多一(client / server interaction)
- 多对多(公用信箱)
5.3、消息传递系统实现中的若干问题
(1)通信链路(Communication Link)
在消息传递系统中,通信链路(Communication Link)是消息传输的通道,负责在发送方和接收方之间建立可靠的传输路径。其设计直接影响系统的性能、可靠性和扩展性
根据通信链路的链接方法,可以把通信链路分为
- 点—点通信链路
- 多点连接链路
根据通信方式的不同
- 单向通信链路
- 双向链路
根据容量的不同
- 无容量通信链路(无缓冲区)
- 有容量通信链路(有缓冲区)
(2)消息的格式(Message Format)
在消息传递系统中,消息格式(Message Format)是定义消息结构和内容的协议规范,直接影响系统的互操作性、序列化效率及扩展能力。
消息头(Header)
元数据字段:
- 消息ID(唯一标识)
- 源地址/目标地址(如进程ID、网络坐标)
- 时间戳(用于排序/超时处理)
- 消息类型(如请求/响应/事件)
- 版本号(支持协议升级)
消息体(Payload)
数据表示方式:
- 结构化数据(如JSON/XML)
- 二进制数据(如Protocol Buffers)
- 混合类型(如Thrift支持多语言映射)
定长消息格式 vs 变长消息格式
(3)进程同步方式
- 发送进程阻塞,接收进程阻塞
- 发送进程不阻塞,接收进程阻塞
- 发送进程和接收进程均不阻塞
5.4、消息缓冲队列通信机制
(1)消息缓冲队列通信机制中的数据结构
1)消息缓冲区(Message Buffer)
type message buffer=record
sender : 发送者进程标识符
size:消息长度
text:消息正文
next:指向下一个消息缓冲区的指针
end
2)PCB中有关通信的数据项
- 消息队列标识符(mqid)
作用:唯一标识进程关联的消息队列
实现:通过系统调用msgget()获取 - 消息缓冲区地址(msg_buf)
作用:指向进程接收/发送消息的缓冲区
实现:通过系统调用msgrcv()/msgsnd()操作 - 消息类型掩码(msg_type)
作用:过滤特定类型的消息
实现:支持优先级或分类处理 - 消息长度限制(msg_max)
作用:防止缓冲区溢出
实现:由系统参数MSGMNB定义 - 消息队列状态(mq_state)
作用:跟踪队列的可用性(如是否已满)
实现:通过原子操作维护状态
type processcontrol blcok=record
...
mq:消息队列队首指针
mutex:消息队列互斥信号量
sm:消息队列资源信号量
...
end
(2)发送原语

procedure send(receiver, a)
begin
getbuf(a.size, i); 根据 a.size 申请缓冲区
i.sender:=a.sender; 将发送区 a 中的信息赋值到消息缓冲区 i 中
i.size:=a.size;
i.text:=a.text;
i.next:=0;
getid(PCB set, receiver.j); 获得接收进程内部标识符
wait(j.mutex);
inser(j.mq,i); 将消息缓冲区插入消息队列
signal(j.mutex);
signal(j.sm);
end
(3)接收原语
procedure receive(b)
begin
j:=internal name; j为接收进程内部标识符
wait(j.sm);
wait(j.mutex)
remove(j.mq,i); 将消息队列中第一个消息移出
signal(j.mutex);
b.sender:=i.sender; 将消息缓冲区 i 中的信息复制到接受区 b
b.size:=i.size;
b.text:=i.text;
end
6、线程(Threads)
线程(Threads) 是进程中的一个执行单元,是CPU调度和分派的基本单位。
线程共享进程的资源(如内存、文件描述符等),但有独立的执行栈和程序计数器(PC)。
6.1、线程的基本概念
(1)线程的引入
在计算机程序设计中,进程是操作系统分配资源的基本单位,每个进程都有独立的内存空间和系统资源。然而,随着计算机性能的提升和用户对程序并发性需求的增加,传统基于进程的并发模型暴露出以下问题:
-
资源开销大:每个进程需要独立的内存空间和资源(如文件描述符、网络连接等),导致系统资源浪费。
-
切换成本高:进程切换需要保存和恢复整个进程的上下文(如寄存器、内存映射等),导致性能开销较大。
-
通信复杂:进程间通信(IPC)需要借助操作系统提供的机制(如管道、消息队列、共享内存等),实现复杂且效率较低。
为了解决这些问题,线程被引入到操作系统中。
线程引入的目的
- 降低资源开销
- 提高并发性
- 简化通信
(2)线程与进程的比较
进程:一个独立的工厂,拥有自己的仓库和生产线。
线程:工厂中的多个工人,共享仓库和生产线,但各自负责不同的任务。
线程具有许多传统进程所具有的特征,所以又称为轻型进程(Light-Weight Process),相应的把传统进程称为重型进程(Heavy-Weight Process)

1)调度

类比:
进程切换:像搬家(需要打包整个家的物品,耗时耗力)。
线程切换:像换房间(只需带个人物品,快速方便)。
2)并发性

在引入线程的操作系统中,不仅进程之间可以并发执行,而且在一个进程中的多个线程之间亦可并发执行
3)拥有资源

示例:
进程A和进程B各自拥有独立的内存空间,无法直接访问对方的变量。
线程T1和T2共享进程的内存空间,T1修改全局变量x,T2可直接访问。
4)系统开销

在一些操作系统中,线程的切换、同步和通信都无须操作系统内核的干预
(3)线程的属性
线程是操作系统中能够进行独立调度和分派的基本单位,具有轻型实体、可并发执行以及共享进程资源等属性。
轻型实体
- 资源占用少
- 创建和切换开销低
- 管理成本低
独立调度和分派的基本单位
- 响应性高:由于线程的调度粒度更细,程序的响应性更高。例如,在图形用户界面(GUI)程序中,主线程可以处理用户输入,而工作线程可以执行后台任务,两者互不干扰。
可并发执行
- 甚至允许一个进程中的所有线程都能并发执行,不同进程中的线程也可能并发执行
共享进程资源
- 共享地址空间
- 共享文件描述符
- 共享全局变量
- 共享其他资源(如信号处理程序、当前工作目录等)
(4)线程的状态
1)状态参数
- 寄存器状态
- 堆栈
- 线程运行状态
- 优先级
- 线程专有寄存器
- 信号屏蔽
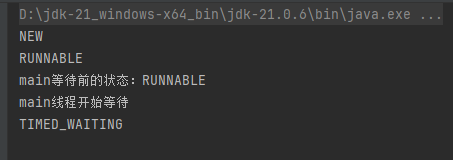
eg Java 中线程状态的枚举类 Thread.State 的参数

2)线程运行状态
eg:
- 执行状态
- 就绪状态
- 阻塞状态
eg:
[NEW] -> [RUNNABLE] -> [RUNNING] -> [TERMINATED]
|
v
[BLOCKED]
|
v
[WAITING] / [TIMED_WAITING]
- NEW:线程已创建,但未启动。
- RUNNABLE:线程已启动,正在等待 CPU 执行。
- RUNNING:线程正在执行代码。
- BLOCKED、WAITING、TIMED_WAITING:线程处于等待状态。
- TERMINATED:线程执行完毕。
(5)线程的创建和终止
在多线程 OS 环境下,应用程序在启动时,通常仅有一个线程在执行,该线程被人们称为“初始化线程”
根据需要可以再去创建若干个线程。
eg java 中
创建线程
- 使用 Thread 类或 Runnable 接口创建线程。
- 调用 start() 方法启动线程。
终止线程
- 自然终止:run() 方法执行完毕。
- 优雅终止:使用标志位让线程主动退出。
- 避免使用 Thread.stop()(强制终止,可能导致资源泄露、死锁或数据不一致。)
(6)多线程 OS 中的进程
多线程 OS 中的进程有以下属性
1)作为系统资源分配的基本单位
独立资源空间:每个进程拥有独立的地址空间、全局变量、文件描述符等资源。进程间的资源互不共享,保证了进程的隔离性和安全性。
资源管理:操作系统为每个进程分配独立的资源,例如内存、文件句柄、I/O设备等。进程间的通信需要通过进程间通信(IPC)机制实现。
2)可包括多个线程
线程共享进程资源:同一进程中的多个线程共享进程的地址空间、全局变量、文件描述符等资源。线程间的通信更加高效,因为它们可以直接访问共享内存。
独立执行路径:每个线程有自己的程序计数器(PC)、寄存器集合和栈空间,用于保存线程的执行上下文。线程可以独立调度,执行不同的代码路径。
3)进程不是一个可执行的实体
是把线程作为独立运行的基本单位
进程可以处于就绪、运行、阻塞等状态。线程的状态变化会影响进程的状态,例如,当进程中的所有线程都阻塞时,进程可能进入阻塞状态。
反之,把某个进程挂起时,该进程中所有线程也都将被挂起
6.2、线程间的同步和通信
在多线程编程中,线程间的同步和通信是确保程序正确性和高效性的关键。同步用于协调线程对共享资源的访问,避免竞争条件(Race Condition)和数据不一致性;通信则用于线程之间交换信息,协调它们的执行顺序。
(1)互斥锁(Mutex)
定义:
- 互斥锁(Mutex,Mutual Exclusion)是一种用于保护共享资源的同步机制。它确保同一时间只有一个线程可以访问被保护的代码块或资源。
工作原理:
- 当一个线程需要访问共享资源时,它首先尝试获取互斥锁。
- 如果锁未被其他线程持有,则该线程成功获取锁并访问资源。
- 如果锁已被其他线程持有,则该线程将被阻塞,直到锁被释放。
- 访问完资源后,线程释放锁,允许其他线程获取。
特点:
- 互斥性:保证同一时间只有一个线程可以访问受保护的资源。
- 简单易用:适用于保护小块代码或简单数据结构。
示例(伪代码):
pthread_mutex_t mutex;
pthread_mutex_init(&mutex, NULL);
void* thread_function(void* arg) {
pthread_mutex_lock(&mutex);
// 访问共享资源
pthread_mutex_unlock(&mutex);
return NULL;
}
注意事项:
- 避免死锁:确保锁的获取和释放顺序一致,避免循环等待。
- 减少锁的持有时间:长时间持有锁会降低并发性。
(2) 条件变量(Condition Variable)
每一个条件变量通常都与一个互斥锁一起使用
定义:
- 条件变量用于线程间的通信,允许一个或多个线程等待某个条件成立,而另一个线程在条件成立时通知等待的线程。
工作原理:
- 条件变量通常与互斥锁结合使用。
- 线程在等待某个条件时,释放互斥锁并进入等待状态。
- 当条件发生变化时,另一个线程通知等待的线程,等待的线程被唤醒并重新获取互斥锁。
特点:
- 线程通信:允许线程协调执行顺序。
- 减少忙等待:避免线程不断检查条件,浪费CPU资源。
比喻:
- 想象你在餐厅排队等位,服务员(线程)会告诉你“有空桌时通知你”(条件变量)。
- 你(线程)先挂起(进入等待状态),当有空桌时,服务员(线程)喊一声“有空桌了”(发出信号),你(线程)被唤醒,继续执行(比如去就座)。
(3)信号量(Semaphore)
定义:
- 信号量是一种用于控制对共享资源访问的同步机制,它可以用于实现互斥和同步。
工作原理:
- 信号量维护一个计数器,表示可用资源的数量。
- 线程在访问资源前,尝试对信号量执行wait操作(P操作),如果计数器大于0,则计数器减1,线程继续执行;否则,线程被阻塞。
- 线程在释放资源时,对信号量执行signal操作(V操作),计数器加1,并可能唤醒一个等待的线程。
特点:
- 灵活性:可以用于实现更复杂的同步场景,如生产者-消费者问题。
- 计数功能:允许同时有多个线程访问资源。
示例:
sem_t semaphore;
sem_init(&semaphore, 0, 3); // 初始化信号量,允许3个线程同时访问
void* thread_function(void* arg) {
sem_wait(&semaphore); // 尝试访问资源
// 访问共享资源
sem_post(&semaphore); // 释放资源
return NULL;
}
注意事项:
- 信号量的初始值决定了同时可以访问资源的线程数。
- 避免信号量值溢出或下溢。
实际应用中的选择
- 互斥锁:适用于需要保护小块代码或简单数据结构的场景。
- 条件变量:适用于线程间需要协调执行顺序的场景,如生产者-消费者问题。
- 信号量:适用于需要控制多个线程同时访问共享资源的场景,如资源池管理。
6.3、线程的实现方式
线程的实现方式主要分为三种:内核支持线程(KST, Kernel Supported Threads)、用户级线程(ULT, User Level Threads)以及组合方式(前两种方式的结合)。
(1)内核支持线程(KST, Kernel Supported Threads)
定义:
- 内核支持线程是在内核的支持下运行的线程,其创建、阻塞、撤销和切换等操作都在内核空间内完成。
特点:
- 内核管理:内核为每个线程设置一个线程控制块(TCB),通过TCB来感知和控制线程。
- 并发执行:在多处理器系统中,内核能够同时调度同一进程中的多个线程并发执行。
- 阻塞处理:当一个线程阻塞时,内核可以调度该进程中的其他线程继续执行,从而提高系统的并发性。
- 切换开销:由于线程的切换需要在内核态和用户态之间进行,因此切换开销相对较大。
优点:
- 能够充分利用多处理器系统的优势,提高系统的并发性。
- 内核对线程的管理更加直接和高效。
缺点:
- 线程切换开销较大,因为需要经历用户态到内核态的切换。
- 内核需要为每个线程分配资源,可能增加系统的资源消耗。
(2)用户级线程(ULT, User Level Threads)
定义:
- 用户级线程是在用户空间中实现的线程,其创建、撤销、同步和通信等操作都在用户空间中完成,无需内核的直接支持。
特点:
- 用户管理:用户级线程的调度通常以进程为单位进行,但具体的调度算法可以由用户自定义。
- 切换开销小:由于线程的切换在用户空间中进行,因此切换开销相对较小。
- 阻塞影响:当一个线程阻塞时,其他所有线程都可能被阻塞(这取决于具体的实现和调度策略),因为操作系统感知不到用户级线程的存在。
优点:
- 线程切换开销小,提高了系统的响应速度(不需要转换到内核空间)。
- 用户可以根据具体需求自定义线程调度算法。
缺点:
- 当一个线程阻塞时,可能影响其他线程的执行。
- 无法充分利用多处理器系统的优势,因为用户级线程的调度以进程为单位。
eg:进程 A 中包含了一个用户级线程,进程 B 包含有 100 个用户级线程,设置了用户级线程的系统,调度以进程为单位进行,在采用轮转调度算法时,A中线程运行时间将是 B 中各线程运行时间的 100 倍
假如系统中设置的是内核支持线程,则调度便是以线程为单位进行的,在采用轮转法调度时,进程 B 可获得的 CPU 时间是进程 A 的 100 倍
(3)组合方式
定义:
- 组合方式是内核支持线程和用户级线程的结合,旨在充分利用两者的优点。
实现方式:
- 多对一模型:将多个用户级线程映射到一个内核支持线程上。这种方式的优点是开销小、效率高,但缺点是当一个线程阻塞时,整个进程都会被阻塞。
- 一对一模型:每个用户级线程都映射到一个内核支持线程上。这种方式的优点是当一个线程阻塞时,允许其他线程继续运行,且允许多个线程并行地运行在多处理机系统上。但缺点是开销较大。
- 多对多模型:将多个用户级线程映射到同样数量或者更少数量的内核支持线程上。这种方式结合了上述两种模型的优点,可以根据实际情况调整内核控制线程数目。
优点:
- 充分利用了内核支持线程和用户级线程的优点。
- 提高了系统的并发性和响应速度。
缺点:
- 实现复杂度较高。
- 可能需要更多的系统资源来支持多种线程模型。
6.4、线程的实现
不论是进程还是线程,都必须直接或间接地取得内核的支持
(1)内核支持线程(Kernel-Level Threads)
实现方式:
- 内核级线程由操作系统内核直接管理。
- 每个线程在内核中都有对应的线程控制块(TCB),内核负责线程的调度、切换和管理。
应用场景:
- 适用于需要充分利用多核处理器、对线程管理要求较高的应用,如服务器、数据库等。
在仅设置了内核支持线程的 OS 中,一种可能的线程控制方法是,系统在创建一个新进程时,便为它分配了一个任务数据区 PTDA(Per Task Data Area),用于存储与该进程相关的资源信息。PTDA 包含若干个线程控制块(TCB)空间,用于管理进程中的线程。

(2)用户级线程(User-Level Threads)
实现方式:
- 用户级线程由用户空间的线程库管理,内核并不知道用户级线程的存在。
- 线程切换在用户空间完成,不需要内核介入。
应用场景:
- 适用于对性能要求较高、线程阻塞较少的应用,如某些高性能计算、实时系统等。
用户线程是在用户空间实现的,所有用户级线程都具有相同的结构,它们都运行在一个中间系统的上面。当前有两种方式实现中间系统
- 运行时系统(Running System)
- 内核控制线程,这种线程又称为轻型进程 LWP(Light Weight Process)
LWP(Light Weight Process) 是操作系统中一种实现多任务的方法,属于线程调度的核心机制。与普通进程相比,LWP 共享内存地址空间和文件资源,但拥有独立的任务执行流。


(3)用户级线程和内核控制线程的连接

一对一模型适用于需要高效并行执行且对线程数量要求不高的场景。eg:Windows线程
多对一模型适用于轻量级、高并发的场景,但无法利用多核CPU。eg:Green Threads:早期Java虚拟机(如旧版JVM)使用的用户级线程实现。
多对多模型结合了前两者的优点,是现代操作系统和编程语言的主流选择,如Go语言的Goroutines。
更多有趣的计算机知识和代码示例,可参考【Programming】