前情提要 可以跳过
我在Ubuntu18.04上安装了pytorch的相关环境,配置如图。

Ubuntu18.04+RTX3060显卡配置pytorch、cuda、cudnn和miniconda_Toblerone_Wind的博客-CSDN博客之前已经安装成功了,也发了篇博客梳理了整套流程如下。ubuntu18.04安装pytorch、cuda、cudnn和miniconda_Toblerone_Wind的博客-CSDN博客_ubuntu18.04安装pytorchhttps但后续发现tensor变量不能转移到cuda上,即执行下面的语句会卡死。卡死也没报错信息,后来调试了很久发现是原先的cuda10.2版本太低了,不持支我的3060显卡。装了cuda11.4发现又没有对应的pytorch,导致cuda无法和torch正常通讯。.........https://blog.csdn.net/qq_42276781/article/details/125523817这个环境跑pytorhc代码没有什么问题,但是最近我要复现一个基于Keras的论文方法。Keras是一个基于TensorFlow的深度学习框架,可以用简单的四五行代码构建一个深度学习模型。
下面给出了一个示例,创建了一个序列模型,接着向里面添加了嵌入层,LSTM层,全剧最大池化层和全连接层,最后设置模型的损失函数和优化方法。
from tensorflow.python.keras.models import Sequential
from tensorflow.python.keras.layers import Embedding, Dense, GlobalMaxPooling1D, LSTM
def create_model(input_dim, input_length, latent_dim, drop_prob):
model = Sequential()
model.add(Embedding(input_dim=input_dim, output_dim=latent_dim, input_length=input_length))
model.add(LSTM(units=latent_dim, return_sequences=True, dropout=drop_prob, recurrent_dropout=drop_prob))
model.add(GlobalMaxPooling1D())
model.add(Dense(units=1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
return model由于Ubuntu18.04是安装的是Cuda11.1,我就在Miniconda下创建了一个Python3.6的虚拟环境,使用下面的命令安装了适配的tensorflow。
pip install tensorflow_gpu=2.5.0安装完成之后,我运行代码确实可以使用GPU加速,但是我切换成纯CPU版的Tensorflow运行时,发现速度是GPU版本的3倍。查阅了相关资料,发现是LSTM的效率太低导致的,众所周知LSTM是长短期记忆模型,当前时刻的状态会受到上一时刻状态的影响,这就导致必须计算完成上一时刻的状态,才能计算这一时刻的状态,也就是说LSTM是顺序执行的,GPU的并行加速在这里并不能体现优势,而GPU的顺序计算是弱于CPU的,至少在我的机器上(i9-10850k和RTX3060)。
解决的办法也是有的,可以使用CuDNNLSTM替换普通的LSTM,CuDNNLSTM借助CuDNN对LSTM的运算进行了加速,可以极大提升效率(我理解的是利用矩阵乘法在损失小部分精度的情况下,进行并行运算)
修改后代码如下
from tensorflow.python.keras.models import Sequential
from tensorflow.python.keras.layers import Embedding, Dense, GlobalMaxPooling1D, CuDNNLSTM
def create_model(input_dim, input_length, latent_dim, drop_prob):
model = Sequential()
model.add(Embedding(input_dim=input_dim, output_dim=latent_dim, input_length=input_length))
model.add(CuDNNLSTM(units=latent_dim, return_sequences=True))
model.add(GlobalMaxPooling1D())
model.add(Dense(units=1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
return model但是运行的时候却报错了,说我系统中的CuDNN版本是8.0.5,keras使用的CuDNNLSTM需要8.1.0。于是卸载了系统中的CuDNN8.0.5,安装了支持Cuda11.1的CuDNN8.1.0,虽然这次没有报错说CuDNN版本不一致,但是报了一个CuDNN和Cuda不协同的错误,我明明找到是相适配的CuDNN啊!重启了也没有解决不适配的问题。
鉴于现在Cuda和CuDNN并不适配,我切换回了原有的Pytorch虚拟环境,测试代码发现可以正常运行。这说明一般情况下,Cuda和CuDNN并不一定需要适配,除非你的代码需要使用CuDNN。
言归正传,之后我就不停的安装CuDNN,不停的安装TensorFlow,企图让CuDNN,TensorFlow和Cuda三者完美统一。但都失败了。直到我福至心灵地创建了一个python3.8的虚拟环境,在里面使用这个命令安装Tensorflow时,Pip报错,说不需要添加后缀gpu。
pip install tensorflow_gpu=2.5.0于是我就直接使用了下面这个命令,Pip自动给我安装了tensorflow-2.12.0
pip install tensorflow运行代码,提示我tensorflow支持的CuDNN是8.6.0,而我系统中CuDNN的是8.0.5。
我选择了适配Cuda11.x的CuDNN 8.6.0

TensorFlow 1.12.0
python版本是3.8,使用下面的命令安装
pip install tensorflow=2.12.0虽然可以使用清华镜像,但是下载一会之后开始会断开,推荐使用专门的下载器,下载链接在此
下载完成之后进入文件所在目录,使用下面的命令就可以直接安装
pip install tensorflow-2.12.0-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whlCuda 11.1
见我的这篇博客
Ubuntu18.04+RTX3060显卡配置pytorch、cuda、cudnn和miniconda_Toblerone_Wind的博客-CSDN博客之前已经安装成功了,也发了篇博客梳理了整套流程如下。ubuntu18.04安装pytorch、cuda、cudnn和miniconda_Toblerone_Wind的博客-CSDN博客_ubuntu18.04安装pytorchhttps但后续发现tensor变量不能转移到cuda上,即执行下面的语句会卡死。卡死也没报错信息,后来调试了很久发现是原先的cuda10.2版本太低了,不持支我的3060显卡。装了cuda11.4发现又没有对应的pytorch,导致cuda无法和torch正常通讯。.........https://blog.csdn.net/qq_42276781/article/details/125523817
CuDNN 6.5.0
下载链接在此如果不能下载可能是要注册账号,网页放在这里
nullExplore and download past releases from cuDNN GPU-accelerated primitive library for deep neural networks.https://developer.nvidia.com/rdp/cudnn-archive下载完成后需要安装,这里我找到了官方的安装文档
Installation Guide - NVIDIA Docs![]() https://docs.nvidia.com/deeplearning/cudnn/install-guide/index.html
https://docs.nvidia.com/deeplearning/cudnn/install-guide/index.html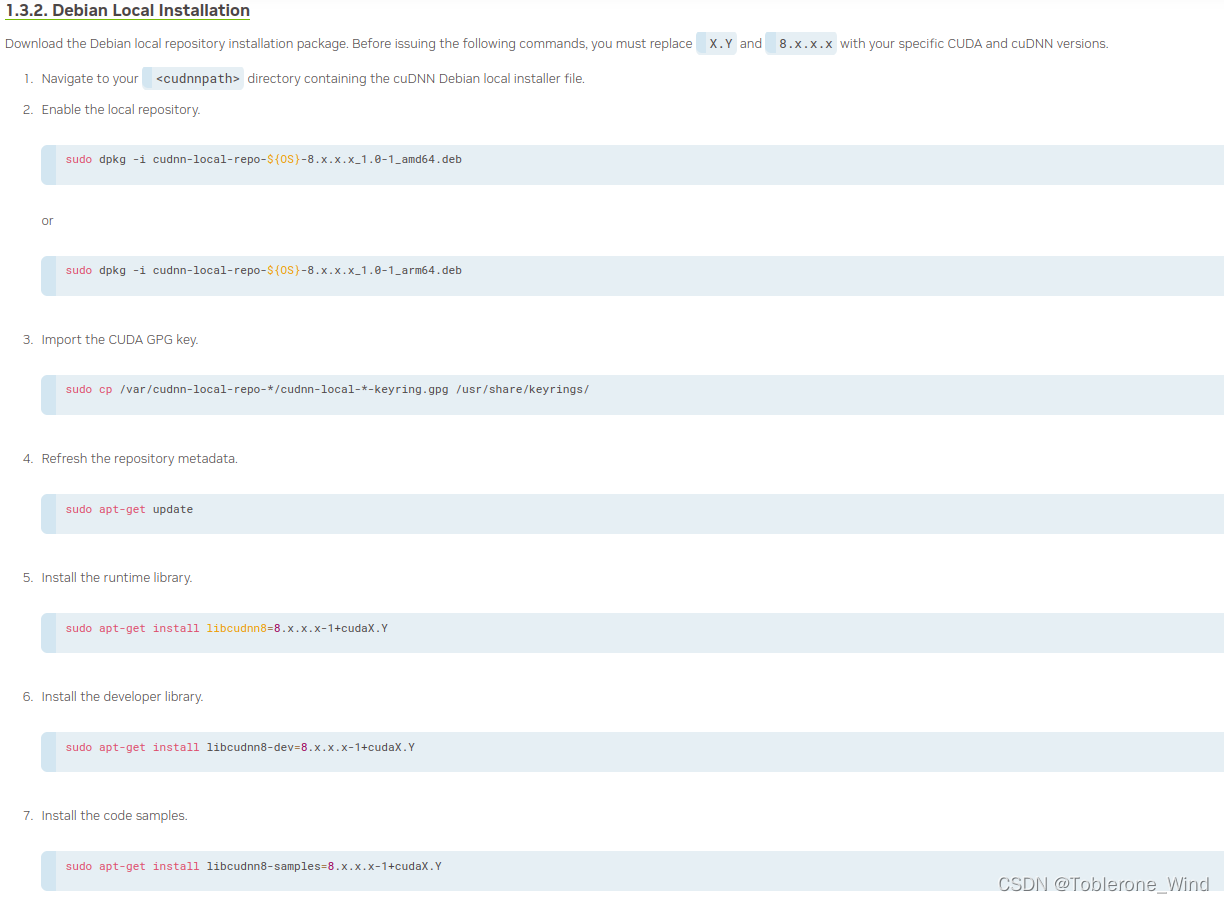
但是他提供的有点问题,567步的指令缺少了安装文件后缀.deb,sudo apt-get update好像也没有必要。
这里就提供一个我的安装步骤
首先是进入cudnn-local-repo-ubuntu1804-8.6.0.163_1.0-1_amd64.deb文件所在的目录,打开命令行输入下面的指令
sudo dpkg -i cudnn-local-repo-ubuntu1804-8.6.0.163_1.0-1_amd64.deb接着移动CUDA的GPG钥匙
sudo cp /var/cudnn-local-repo-ubuntu1804-8.6.0.163/cudnn-local-77B32ECB-keyring.gpg /usr/share/keyrings/
接着进入/var目录
cd /var输出该目录的所有文件
ls会发现有一个叫cudnn-local-repo-ubuntu1804-8.6.0.163的文件夹,进入
cd cudnn-local-repo-ubuntu1804-8.6.0.163/输出该目录的所有文件
ls会发现libcudnn8_8.6.0.163-1+cuda11.8_amd64.deb,libcudnn8-dev_8.6.0.163-1+cuda11.8_amd64.deb和libcudnn8-samples_8.6.0.163-1+cuda11.8_amd64.deb
这时候依次执行下面三个安装命令
sudo dpkg -i libcudnn8_8.6.0.163-1+cuda11.8_amd64.deb
sudo dpkg -i libcudnn8-dev_8.6.0.163-1+cuda11.8_amd64.deb
sudo dpkg -i libcudnn8-samples_8.6.0.163-1+cuda11.8_amd64.deb 顺便提一下Cudnn的卸载方法
首先显示安装的CuDNN
sudo dpkg -l | grep cudnn再根据显示的名字卸载,如
dpkg -r cudnn-local-repo-ubuntu1804-8.6.0.163