- 什么是块设备?
系统中能够随机访问固定大小数据片的设备被称为块设备,这些数据片称作块,最常见的块设备是硬盘。 - 什么是字符设备?
字符设备按照字符流的方法被有序访问,像串口和键盘就都属于字符设备。 - 这两种设备的区别是什么?
区别在于是否可以随机访问,就是能否在访问设备时随意地从一个位置跳转到另一个位置。
1、解刨一个块设备
- 什么是扇区?
- 扇区是块设备最小的可寻址单元。
- 扇区的大小是设备的物理属性,扇区大小一般是2的整数倍。
- 扇区是所有块设备的基本单元,块设备无法对比扇区还小的单元进行寻址和操作。
- 什么是块?
- 块是文件系统的一种抽象,只能基于块来访问文件系统。
- 虽然物理磁盘寻址是按照扇区级进行的,但是内核执行的所有磁盘操作都是按照块进行的。
- 对块大小的最终要求是,必须是扇区大小的2的整数倍,并且要小于页面大小。
2、缓冲区和缓冲区头(*)
- 当一个块被调入内存时,它要存储在一个缓冲区。每个缓冲区与一个块对应,前面提到过,块包含一个或多个扇区,但大小不能超过一个页面,所以一个页可以容纳一个或多个内存中的块。由于内核在处理数据时需要一些相关的控制信息,所以每一个缓冲区都有一个对应的描述符,该描述符用
buffer_head表示,被称作缓冲区头,在文件linux/buffer_head.h中定义,它包含了内核操作缓冲区所需要的全部信息。
/*
* Keep related fields in common cachelines. The most commonly accessed
* field (b_state) goes at the start so the compiler does not generate
* indexed addressing for it.
*/
struct buffer_head {
/* First cache line: */
unsigned long b_state; /* buffer state bitmap (see above) */
struct buffer_head *b_this_page;/* circular list of page's buffers */
struct page *b_page; /* the page this bh is mapped to */
atomic_t b_count; /* users using this block */
u32 b_size; /* block size */
sector_t b_blocknr; /* block number */
char *b_data; /* pointer to data block */
struct block_device *b_bdev;
bh_end_io_t *b_end_io; /* I/O completion */
void *b_private; /* reserved for b_end_io */
struct list_head b_assoc_buffers; /* associated with another mapping */
};
- 缓冲区头的目的在于描述磁盘块和物理内存缓冲区之间的映射关系。这个结构体在内核中只扮演一个角色,说明从缓冲区到块的映射关系。
- 在2.6内核以前,缓冲区头的作用比现在还重要。因为缓冲区头作为内核的I/O操作单元,不仅仅描述了从磁盘块到物理内存的映射,而且还是所有块I/O操作的容器。可是,将缓冲区头作为I/O操作单元带来了两个弊端。
- 首先,缓冲区头是一个很大且不易控制的数据结构体,而且缓冲区头对数据的操作既不方便,也不清晰。
- 仅能描述单个缓冲区,当作为所有I/O的容器使用时,缓冲区头会迫使内核打断对大块数据的I/O操作,使其成为对多个
buffer_head结构体进行操作。这样做必然会造成不必要的负担和空间浪费。
- 所以2.5开发版内核的主要目标就是为块I/O操作引入一种新型、灵活并且轻量级的容器,也就是下面要介绍的
bio结构体。
3、bio结构体
- 目前内核中块I/O操作的基本容器由
bio结构体表示,它定义在文件linux/bio.h中,该结构体代表了正在现场的以片断链表形式组织的I/O操作。一个片段是一小块连续的内存缓存区。这样的话,就不需要保证单个缓冲区一定要连续。所以通过片段来描述缓冲区,即使一个缓冲区分散在内存的多个位置上,bio结构体也能对内核保证I/O操作的执行。 - 下面给出bio结构体和和各个域的描述。
/* * main unit of I/O for the block layer and lower layers (ie drivers and * stacking drivers) */ struct bio { sector_t bi_sector; struct bio *bi_next; /* request queue link */ struct block_device *bi_bdev; unsigned long bi_flags; /* status, command, etc */ unsigned long bi_rw; /* bottom bits READ/WRITE, * top bits priority */ unsigned short bi_vcnt; /* how many bio_vec's */ unsigned short bi_idx; /* current index into bvl_vec */ /* Number of segments in this BIO after * physical address coalescing is performed. */ unsigned short bi_phys_segments; /* Number of segments after physical and DMA remapping * hardware coalescing is performed. */ unsigned short bi_hw_segments; unsigned int bi_size; /* residual I/O count */ /* * To keep track of the max hw size, we account for the * sizes of the first and last virtually mergeable segments * in this bio */ unsigned int bi_hw_front_size; unsigned int bi_hw_back_size; unsigned int bi_max_vecs; /* max bvl_vecs we can hold */ struct bio_vec *bi_io_vec; /* the actual vec list */ bio_end_io_t *bi_end_io; atomic_t bi_cnt; /* pin count */ void *bi_private; bio_destructor_t *bi_destructor; /* destructor */ }; - 使用
bio结构体的目的主要是代表正在现场执行的I/O操作,所以该结构体中的主要域都是用来管理相关信息的,其中最重要的几个域是bi_io_vecs、bi_vcnt和bi_idx。

bi_io_vecs域指向一个bio_vec结构体数组,该结构体链表包含一个特定I/O操作所需要使用的所有片段。每个bio_vec结构都是一个形式<page,offset,len>的向量,它描述的是一个特定的片段:**片段所在的物理页、块在物理页中的偏移位置、从给定偏移量开始的块长度。**整个bio_io_vec结构体数组表示了一个完整的缓冲区。bio_vec结构体定义在linux/bio.h文件中。/* * was unsigned short, but we might as well be ready for > 64kB I/O pages */ struct bio_vec { struct page *bv_page; /* 指向这个缓冲区所驻留的物理页 */ unsigned int bv_len; /* 这个缓冲区以字节为单位的大小 */ unsigned int bv_offset; /* 缓冲区所驻留的页中以字节为单位的偏移量 */ };- 在每个给定的块I/O操作中,
bi_vcnt域用来描述bi_io_vec所指向的bio_vec数组中的向量数目,当块I/O操作执行完毕后,bi_idx域指向数组的当前bio_vec片段。bi_cnt域记录bio结构体的使用计数,如果该域值减为0,就应该销毁该bio结构体,并释放它所占用的内存。 - 缓冲区头和
bio结构体的比较bio结构体代表的是I/O操作,它可以包括内存中的一个或多个页buffer_head结构体代表一个缓冲区,它描述的是磁盘中的一个块。因为缓冲区头关联的是单独页中的单独磁盘块,所以它可能会引起不必要的分割,将请求按块为单位划分,只能靠以后才能再重新组合bio结构是轻量级的,它描述的块可以不需要连续存储区,并且不需要分割I/O操作。- 并不是说要取消缓冲区头这个概念,毕竟它还负责描述磁盘块到页面的映射。内核通过这两种结构分别保存各自的信息,可以保证每种结构所含的信息量尽可能减少。
4、请求队列
- 请求队列如何产生?
块设备将他们挂起的块I/O请求保存在请求队列(request_queue)中,通过内核中像文件系统这样的高层代码将请求插入到队列,只要请求队列不为空,队列对应的块设备驱动程序就会从队列头获取请求并送入对应块设备。 - 请求队列结构是什么?
请求队列表中的每一项都是一个单独的请求,由request表示。因为一个请求可能要操作多个连续的磁盘块,所以每个请求可以由多个bio结构组成。(注意,虽然磁盘块必须连续,但内存中这些块不一定要连续,每个bio结构体可以描述多个片段,片段是内存中连续的小区域)
5、I/O调度程序
- 内核中负责提交I/O请求的子系统称为I/O调度程序。IO调度程序的工作是管理块设备的请求队列。
- I/O调度程序通过两种方法减少磁盘寻址时间:合并和排序。
- Linux内核2.6开始引入了全新的IO调度子系统,IO调度器的总体目标是希望让磁头能够总是往一个方向移动,移动到底了再往反方向走,这恰恰就是现实生活中的电梯模型,所以IO调度器也被叫做电梯 (elevator)。而相应的算法也就被叫做电梯算法。而Linux中IO调度的电梯算法有好如下几种:
as(Anticipatory)、cfq(Complete Fairness Queueing)、deadline、noop(No Operation)。具体使用哪种算法我们可以在启动的时候通过内核参数elevator来指定,默认使用的算法是cfq。
-
linus电梯
- 如果队列中已存在一个对相邻磁盘扇区操作的请求,那么新请求将和这个已经存在的请求合并
- 如果队列中存在一个驻留时间过长的请求,那么新请求将被插入队列尾部
- 如果队列中以扇区方向为序存在合适的插入位置,那么新请求插入此位置,保证队列中请求是以被访问磁盘物理位置为序排列
- 如果队列中不存在合适的请求插入位置,插入到队列尾部。
-
空操作的I/O调度程序(
NOOP)- 空操作的I/O调度程序只会将任一相邻的请求合并。专门为随机访问设备而设计。
NOOP算法的全写为No Operation。该算法实现了最最简单的FIFO队列,所有IO请求大致按照先来后到的顺序进行操作。之所以说“大致”,原因是NOOP在FIFO的基础上还做了相邻IO请求的合并,并不是完完全全按照先进先出的规则满足IO请求。- 假设有如下的io请求序列:
100,500,101,10,56,1000 NOOP将会按照如下顺序满足:100(101),500,10,56,1000NOOP是在Linux2.4或更早的版本的使用的唯一调度算法。由于该算法比较简单,减了IO占用CPU中的计算时间最少。不过容易造成IO请求饿死。关于IO饿死的描述如下:因为写请求比读请求更容易。写请求通过文件系统cache,不需要等一次写完成,就可以开始下一次写操作,写请求通过合并,堆积到I/O队列中。读请求需要等到它前面所有的读操作完成,才能进行下一次读操作。在读操作之间有几毫秒时间,而写请求在这之间就到来 ,饿死了后面的读请求 。其适用于SSD或Fusion IO环境下。
- 假设有如下的io请求序列:
-
完全公正的排队I/O调度程序(
CFQ)- 该算法的特点是按照IO请求的地址进行排序,而不是按照先来后到的顺序来进行响应。
CFQ为每个进程/线程,单独创建一个队列来管理该进程所产生的请求,也就是说每个进程一个队列,各队列之间的调度使用时间片来调度,以此来保证每个进程都能被很好的分配到I/O带宽。假设有如下的io请求序列:- 假设有如下的io请求序列:
100,500,101,10,56,1000 CFQ将会按照如下顺序满足:100,101,500,1000,10,56- 在传统的SAS盘上,磁盘寻道花去了绝大多数的IO响应时间。
CFQ的出发点是对IO地址进行排序,以尽量少的磁盘旋转次数来满足尽可能多的IO请求。在CFQ算法下,SAS盘的吞吐量大大提高了。但是相比于NOOP的缺点是,先来的IO请求并不一定能被满足,也可能会出现饿死的情况,不过其作为最新的内核版本和发行版中默认的I/O调度器,对于通用的服务器也是最好的选择。CFQ是deadline和as调度器的折中,CFQ对于多媒体应用(video,audio)和桌面系统是最好的选择。
- 假设有如下的io请求序列:
- 该算法的特点是按照IO请求的地址进行排序,而不是按照先来后到的顺序来进行响应。
-
最终期限I/O调度程序(
DEADLINE)DEADLINE在CFQ的基础上,解决了IO请求饿死的极端情况。除了CFQ本身具有的IO排序队列之外,DEADLINE额外分别为读IO和写IO提供了FIFO队列。读FIFO队列的最大等待时间为500ms,写FIFO队列的最大等待时间为5s。FIFO队列内的IO请求优先级要比CFQ队列中的高,而读FIFO队列的优先级又比写FIFO队列的优先级高。优先级可以表示如下:FIFO(Read) > FIFO(Write) > CFQDeadline确保了在一个截止时间内服务请求,这个截止时间是可调整的,而默认读期限短于写期限。这样就防止了写操作因为不能被读取而饿死的现象。Deadline对数据库环境(ORACLE RAC,MYSQL等)是最好的选择。
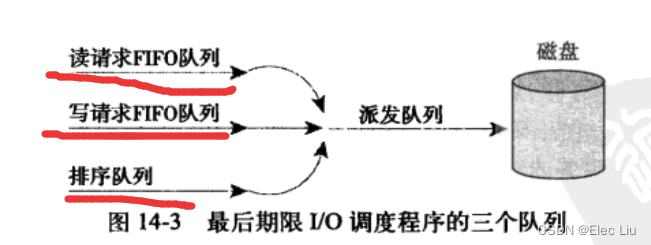
-
预测I/O调度程序(
ANTICIPATORY)CFQ和DEADLINE考虑的焦点在于满足零散IO请求上。对于连续的IO请求,比如顺序读,并没有做优化。为了满足随机IO和顺序IO混合的场景,Linux还支持ANTICIPATORY调度算法。ANTICIPATORY在DEADLINE的基础上,为每个读IO都设置了6ms的等待时间窗口。如果在这6ms内OS收到了相邻位置的读IO请求,就可以立即满足。- 本质上与
Deadline一样,但在最后一次读操作后,要等待6ms,才能继续进行对其它I/O请求进行调度。可以从应用程序中预订一个新的读请求,改进读操作的执行,但以一些写操作为代价。它会在每个6ms中插入新的I/O操作,而会将一些小写入流合并成一个大写入流,用写入延时换取最大的写入吞吐量。AS适合于写入较多的环境,比如文件服务器,但对对数据库环境表现很差。