提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 一、awk编辑器
- 1.工作流程
- 3.常用选项
- 二、awk的基础用法
- 1.输出文件中的某一列
- 2.根据特定条件筛选数据
- 3.按照分隔符进行切割
- 4.在匹配到特定字符串时执行操作
- 5.BEGIN打印模式
- 6.awk的分隔符用法
- 三、示例演示
一、awk编辑器
AWK是一种优良的文本处理工具。它不仅是 Linux 中也是任何环境中现有的功能最强大的数据处理引擎之一。这种编程及数据操作语言的最大功能取决于一个人所拥有的知识
可以进行样式装入、流控制、数学运算符、进程控制语句甚至于内置的变量和函数。它具备了一个完整的语言所应具有的几乎所有精美特性
1.工作流程
逐行读取文本,默认以空格或tab键为分隔符进行分隔,将分隔所得的各个字段保存到内建变量中,并按模式或者条件执行编辑命令。
sed命令常用于一整行的处理,而awk比较倾向于将一行分成多个“字段”然后再进行处理。awk信息的读入也是逐行读取的,执行结果可以通过print的功能将字段数据打印显示。
在使用awk命令的过程中,可以使用逻辑操作符“&&”表示“与”、“||”表示“或”、“!”表示“非”;还可以进行简单的数学运算,如+、-、*、/、%、^分别表示加、减、乘、除、取余和乘方。
3.常用选项
命令格式:
awk 选项 '模式或条件 {操作}' 文件 1 文件 2 …
awk -f 脚本文件 文件 1 文件 2 …
awk常见的内建变量(可直接用)如下所示:
| 选项 | 说明 |
|---|---|
| FS: | 列分割符。指定每行文本的字段分隔符,默认为空格或制表位。与"-F"作用相同 |
| NF: | 当前处理的行的字段个数。 |
| NR: | 当前处理的行的行号(序数)。 |
| $0: | 当前处理的行的整行内容。 |
| $n: | 当前处理行的第n个字段(第n列)。 |
| FILENAME: | 被处理的文件名。 |
| RS: | 行分隔符。awk从文件上读取资料时,将根据RS的定义把资料切割成许多条记录,而awk一次仅读入一条记录,以进行处理。预设值是’\n’ |
二、awk的基础用法
1.输出文件中的某一列
awk '{print $n}' 文件

2.根据特定条件筛选数据
awk '条件 {print}' 文件
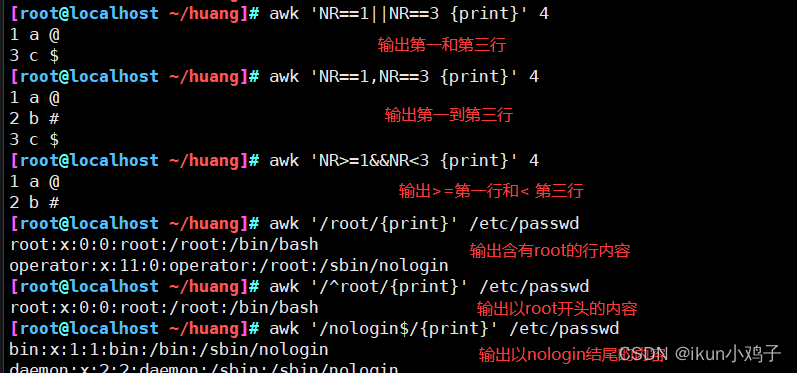
3.按照分隔符进行切割
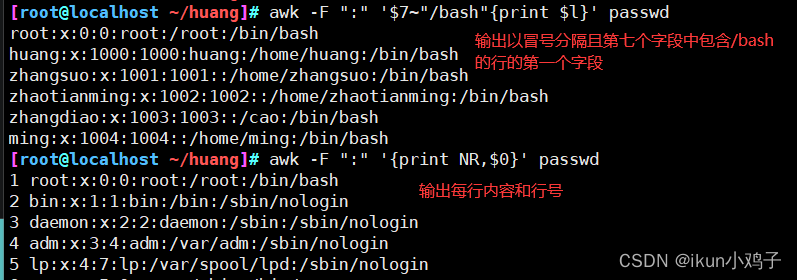
4.在匹配到特定字符串时执行操作
awk '/匹配条件/ {print}' 文件

5.BEGIN打印模式
awk 'BEGIN{...};{...};END{...}' 文件
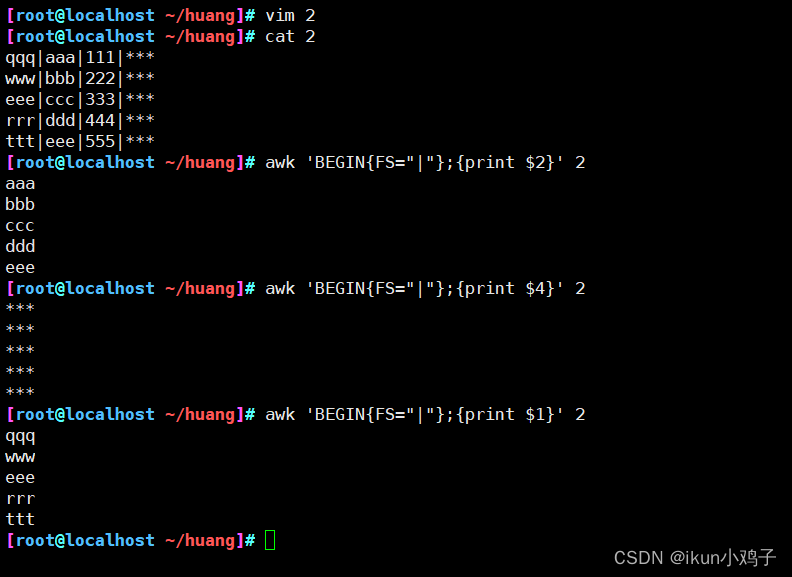
6.awk的分隔符用法
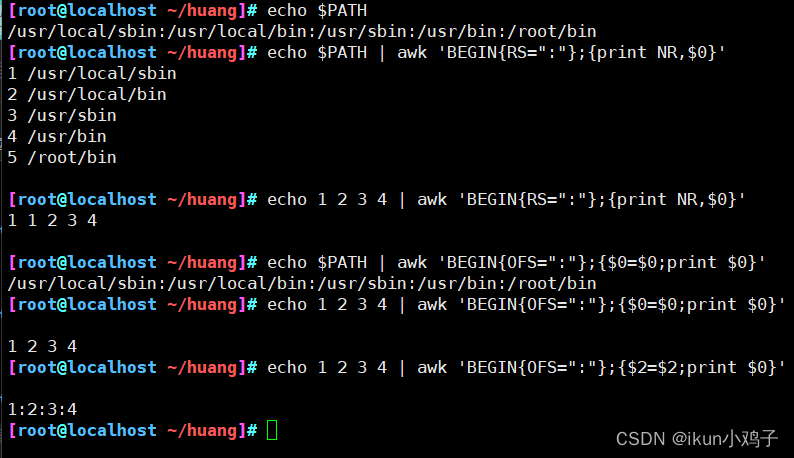
三、示例演示
示例一:
获取本机上一次开机时间
date -d "$(awk -F "." '{print $1}' /proc/uptime) second ago" +"%F %H:%M:%S"

示例二:
检测本机cpu 15分钟内的平均负载
uptime | awk '{print $NF}'

示例三:
获取本机IP地址
ifconfig ens33|awk '/inet /{print $2}'