RLHF中的PPO算法原理及其实现
ChatGPT是基于InstructGPT实现的多轮对话生成式大模型。ChatGPT主要涉及到的技术包括:
- 指令微调(Instruction-tuning);
- 因果推断(Causal Language Modeling);
- 人类对齐(Human Alignment)
博主在之前的文章中已经介绍过关于指令微调以及相关Prompting技术的原理(可以详见:Prompt-Tuning——深度解读一种新的微调范式)以及关于GPT等因果语言模型的相关介绍:【预训练语言模型】GPT: Improving Language Understanding by Generative Pre-Training。那么除了如何训练一个基本的生成式模型外,大模型还需要关注于如何让生成式大模型更加符合人类价值观。
在之前的文章InstructGPT原理讲解及ChatGPT类开源项目中已经介绍了ChatGPT以及最近开源的一些类ChatGPT模型是如何实现对齐的,这里我们也详细介绍一下InstructGPT中进行人类对齐的核心算法——RLHF(人类对齐的强化学习)PPO算法。
本篇文章主要参考下面两个参考资料:
【1】强化学习极简入门:通俗理解MDP、DP MC TC和Q学习、策略梯度、PPO
【2】基于DeepSpeed训练ChatGPT
一、RLHF PPO 算法原理
PPO算法是一种具体的Actor-Critic算法实现,比如在对话机器人中,输入的prompt是state,输出的response是action,想要得到的策略就是怎么从prompt生成action能够得到最大的reward,也就是拟合人类的偏好。
PPO算法涉及到两个策略:
- 近端策略优化惩罚(PPO-penalty);
- 近端策略优化裁剪PPO-clip。
重要性采样
因为在Actor-Critic训练时,策略函数参数进行优化后,上一轮策略采样的动作-状态序列就不能用了,因此需要进行重要性采样,来避免每次更新策略函数后的重复采样问题。当不能在分布p中采样数据,而只能从另外一个分布q中去采样数据时(q可以是任何分布)。
重要性采样的原理:

KL散度约束:
重要性采样中,p和q分布不能查得太远,所以需要有KL散度施加约束。
Advantage:
Actor-Critic算法中,需要定义advantage,最简单的就是定义Reward-baseline,也可以定义为。其中 V π ( s ) V_{\pi}(s) Vπ(s)可以理解为当前状态 s s s下所有动作执行后得到的奖励的期望,而 Q π ( s , a ) Q_{\pi}(s, a) Qπ(s,a)表示当前状态 s s s下指定某一个动作 a a a得到的奖励。所以如果 A π ( s , a ) > 0 A_{\pi}(s, a)>0 Aπ(s,a)>0,则说明当前动作 a a a所获的奖励是大于整体期望的,所以应该极大化这个动作的概率。
总的来说,Advantage旨在通过正负值来告诉策略什么动作可以是可以得到正反馈,避免仅有Reward作为绝对值时所带来的高方差问题。
Advantage+重要性采样:
Advantage可以认为是重要性采样中的 f ( x ) f(x) f(x)。由于其在优化过程中参数是在变的,所以需要进行重要性采样,因此优化目标变为:
J θ ′ = E s t , a t ∼ π θ ′ [ p θ ( a t ∣ s t ) p θ ′ ( a t , s t ) A θ ′ ( s t , a t ) ] J^{\theta'}=\mathbb{E}_{s_t, a_t}\sim\pi_{\theta'}\bigg[\frac{p_{\theta}(a_t|s_t)}{p_{\theta'}(a_t, s_t)}A^{\theta'}(s_t, a_t)\bigg] Jθ′=Est,at∼πθ′[pθ′(at,st)pθ(at∣st)Aθ′(st,at)]
近端策略优化惩罚(PPO-penalty)
PPO算法之近端策略优化惩罚的原理如下图所示:

近端策略优化裁剪PPO-clip
优化目标改为下面:
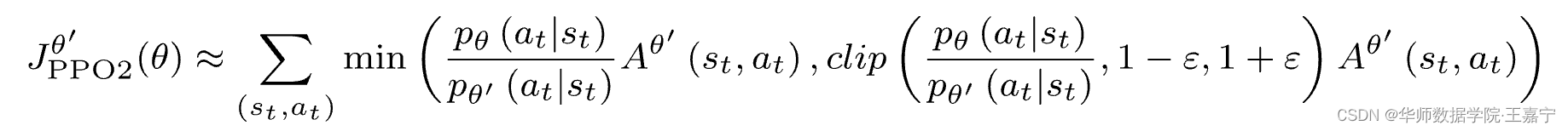
公式的理解:
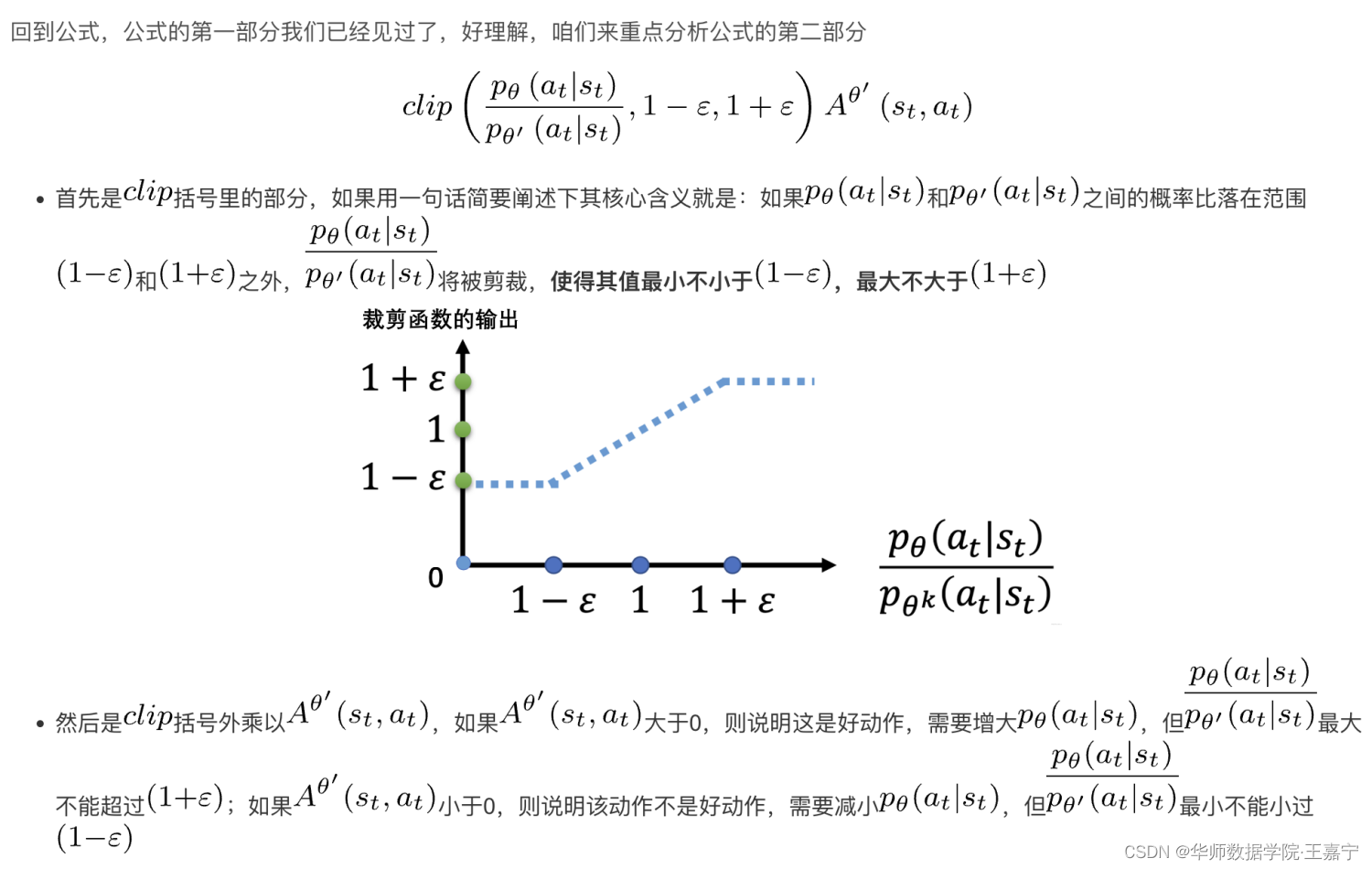
所以说,clip本质上也是约束两个分布不要差的太远,其相比KL散度来说,KL散度是在两个分布的输出logits上进行约束,而clip方法则是直接在概率比上做约束。
二、RLHF PPO算法实现
(1)首先初始化RLHF类和PPOTrainer
rlhf_engine = DeepSpeedRLHFEngine(
actor_model_name_or_path=args.actor_model_name_or_path,
critic_model_name_or_path=args.critic_model_name_or_path,
tokenizer=tokenizer,
num_total_iters=num_total_iters,
args=args)
ppo_trainer = DeepSpeedPPOTrainer
trainer = ppo_trainer(rlhf_engine, args)
初始化过程中,加载4个模型,包括Actor、SFT、Critic和Reward:
代码中的self.ref其实就是SFT模型
class DeepSpeedRLHFEngine():
def __init__(self, actor_model_name_or_path, critic_model_name_or_path,
tokenizer, args, num_total_iters):
self.args = args
self.num_total_iters = num_total_iters
self.tokenizer = tokenizer
# 用训练好的SFT模型初始化Actor模型
self.actor = self._init_actor(
actor_model_name_or_path=actor_model_name_or_path)
# 用训练好的SFT模型初始化SFT模型
self.ref = self._init_ref(
actor_model_name_or_path=actor_model_name_or_path)
self.actor_ema = None
if self.args.enable_ema:
self.actor_ema = self._init_ema(
actor_model_name_or_path=actor_model_name_or_path)
# 用训练好的RW初始化Critic模型
self.critic = self._init_critic(
critic_model_name_or_path=critic_model_name_or_path)
# 用训练好的RW初始化reward模型
self.reward = self._init_reward(
critic_model_name_or_path=critic_model_name_or_path)
if self.args.critic_gradient_checkpointing:
self.critic.gradient_checkpointing_enable()
(2)加载用于RLHF的训练数据
prompt_train_dataloader, num_total_iters = create_datasets(
args=args, tokenizer=tokenizer, train_phase=3)
(3)RLHF整体训练过程如下
具体的流程可以详看代码注释,总的来说,主要流程包括:
- 遍历每个epoch,每个epoch里遍历每个batch;
- 对于每个batch,先采样一堆经验数据;
- 根据经验数据,训练Actor和Critic模型
# 训练的总Epoch数
for epoch in range(args.num_train_epochs):
# 遍历每一个Batch
for step, (batch_prompt) in enumerate(prompt_train_dataloader):
batch_prompt = to_device(batch_prompt, device)
prompts = batch_prompt['prompt'] # prompt
length = prompts.size(-1)
# 进行采样,并加入到经验池,详见(3.1)
out = trainer.generate_experience(prompts)
exp_dataset = exp_mini_dataset.add(out)
if exp_dataset is not None:
inner_iter = 0
critic_loss, actor_loss = 0, 0
average_reward = 0
if args.actor_gradient_checkpointing:
rlhf_engine.actor.gradient_checkpointing_enable()
# 从经验池中进行学习Epoch轮
for ppo_ep in range(args.ppo_epochs):
for i, (exp_data) in enumerate(exp_dataset):
# 得到actor和critic loss,详见(3.2)
actor_loss, critic_loss = trainer.train_rlhf(exp_data)
critic_loss += actor_loss.item()
actor_loss += critic_loss.item()
average_reward += exp_data["rewards"].mean()
inner_iter += 1
if args.enable_ema:
moving_average(rlhf_engine.actor,
rlhf_engine.actor_ema,
zero_stage=args.actor_zero_stage)
# 每一轮结束后打乱经验池
random.shuffle(exp_dataset)
average_reward = get_all_reduce_mean(average_reward).item()
if args.actor_gradient_checkpointing:
rlhf_engine.actor.gradient_checkpointing_disable()
这个训练过程主要包括两个核心步骤:
- 采样Experience数据;
- 根据采样的数据训练Actor和Critic模型。
下面详细分析一下这两个核心步骤,理解了这两个核心步骤也就差不多理解了RLHF PPO算法了。
Experience采样

图来自这里。
实现细节详见代码及注释:
def generate_experience(self, prompts):
self.eval() # 开启eval模式
# 输入instruct prompt,由Actor生成seq,上图中红色步骤(1),seq由instruct和response组成
seq = self._generate_sequence(prompts)
self.train() # 恢复训练模型
pad_token_id = self.tokenizer.pad_token_id
attention_mask = seq.not_equal(pad_token_id).long()
with torch.no_grad():
# 将seq喂入actor中得到action_logits,上图中棕色步骤(2)
output = self.actor_model(seq, attention_mask=attention_mask)
# 将seq喂入SFT中得到sft_logits,上图中黑色步骤(5)
output_ref = self.ref_model(seq, attention_mask=attention_mask)
# 将seq喂入reward模型中打分,得到r(x, y),上图绿色步骤(4)
reward_score = self.reward_model.forward_value(
seq, attention_mask,
prompt_length=self.prompt_length)['chosen_end_scores'].detach(
)
# 将seq喂入critic,获得critic的value,上图蓝色步骤(3)
values = self.critic_model.forward_value(
seq, attention_mask, return_value_only=True).detach()[:, :-1]
logits = output.logits
logits_ref = output_ref.logits
# 获得经验数据
return {
'prompts': prompts,
'logprobs': gather_log_probs(logits[:, :-1, :], seq[:, 1:]),
'ref_logprobs': gather_log_probs(logits_ref[:, :-1, :], seq[:, 1:]),
'value': values,
'rewards': reward_score,
'input_ids': seq,
"attention_mask": attention_mask
}
获得Advantage,并更新Actor和Critic参数
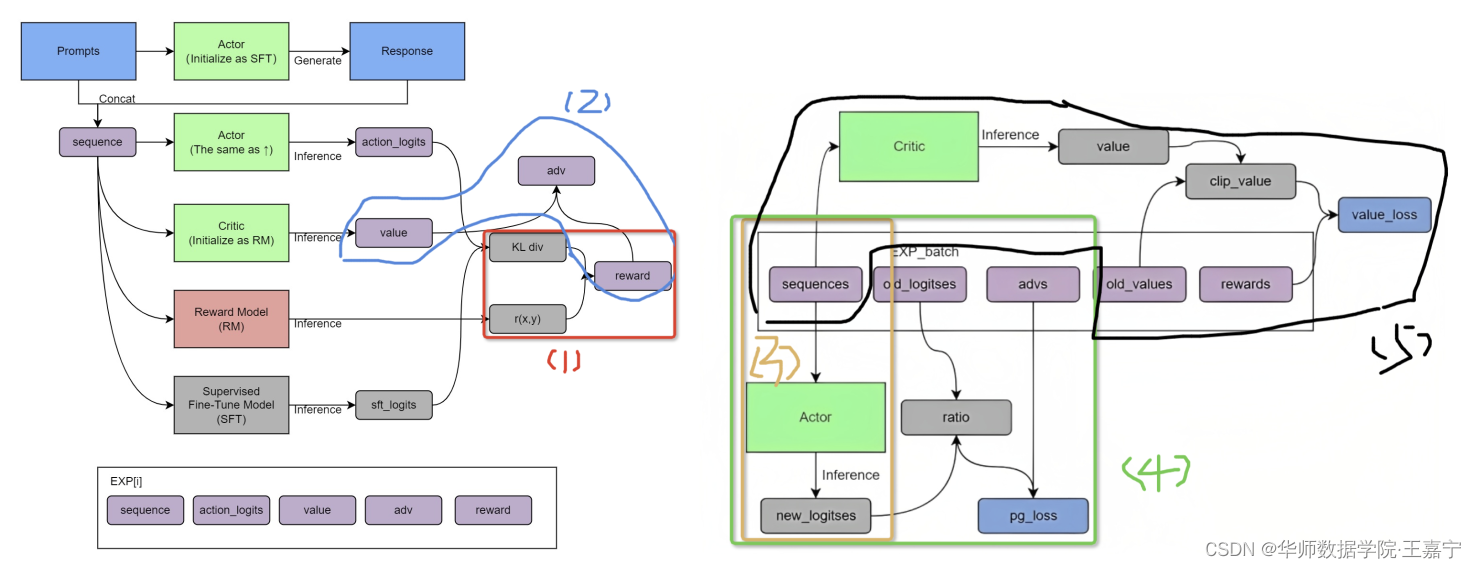
def train_rlhf(self, inputs):
# 当前RLHF轮次最初采样的经验池中采样一批数据
prompts = inputs['prompts'] # instruct prompt
log_probs = inputs['logprobs'] # actor模型生成response对应的action_logist
ref_log_probs = inputs['ref_logprobs'] # SFT模型生成response对应的sft_logits
reward_score = inputs['rewards'] # reward模型预测的奖励r(x, y)
values = inputs['value'] # critic模型预测的奖励
attention_mask = inputs['attention_mask']
seq = inputs['input_ids']
start = prompts.size()[-1] - 1
action_mask = attention_mask[:, 1:]
### 根据经验数据,接下来计算相应的reward和advantage
old_values = values # RLHF训练之前的critic给的value值
with torch.no_grad():
# 根据SFT的sft_logits和Actor的action_logist,计算KL散度;
# 并根据KL散度与reward模型预测的奖励r(x, y),获得最终奖励
# 上图中红色步骤(1)
old_rewards = self.compute_rewards(prompts, log_probs,
ref_log_probs, reward_score,
action_mask)
"""
def compute_rewards(self, prompts, log_probs, ref_log_probs, reward_score,
action_mask):
# self.kl_ctl = 0.02
kl_divergence_estimate = -self.kl_ctl * (log_probs - ref_log_probs)
rewards = kl_divergence_estimate
start = prompts.shape[1] - 1
ends = start + action_mask[:, start:].sum(1)
reward_clip = torch.clamp(reward_score, -self.clip_reward_value,
self.clip_reward_value)
batch_size = log_probs.shape[0]
for j in range(batch_size):
rewards[j, start:ends[j]][-1] += reward_clip[j]
"""
# 由critic或的的value与前面根据KL散度和r(x, y)得到的reward,从而计算得到advantage
# 上图蓝色步骤(2)
advantages, returns = self.get_advantages_and_returns(
old_values, old_rewards, start)
"""
def get_advantages_and_returns(self, values, rewards, start):
# Adopted from https://github.com/CarperAI/trlx/blob/main/trlx/models/modeling_ppo.py#L134
lastgaelam = 0
advantages_reversed = []
length = rewards.size()[-1]
for t in reversed(range(start, length)):
nextvalues = values[:, t + 1] if t < length - 1 else 0.0
delta = rewards[:, t] + self.gamma * nextvalues - values[:, t]
lastgaelam = delta + self.gamma * self.lam * lastgaelam
advantages_reversed.append(lastgaelam)
advantages = torch.stack(advantages_reversed[::-1], dim=1)
returns = advantages + values[:, start:]
return advantages.detach(), returns
"""
### 根据经验数据以及得到的advatage,下面开始获得一系列的loss
batch = {'input_ids': seq, "attention_mask": attention_mask}
# 将这一批经验数据的seq(instruct prompt+response)再一次喂入actor得到logits
# 因为现在是在更新actor和critic,而经验数据所采用的actor和critic早已经是之前的了,所以
# 现在正在更新的actor和critic与当时进行经验采样时的actor、critic的参数已经有差异了;
# 所以需要重新获得当前最新的actor输出的logits
# 上图中棕色步骤(3)
actor_prob = self.actor_model(**batch, use_cache=False).logits
actor_log_prob = gather_log_probs(actor_prob[:, :-1, :],
inputs['input_ids'][:, 1:])
# 根据新的actor logits以及经验数据中的logits,以及advantage,计算actor loss
# 上图中绿色步骤(4)
actor_loss = self.actor_loss_fn(actor_log_prob[:, start:],
log_probs[:, start:], advantages,
action_mask[:, start:])
"""
def actor_loss_fn(self, logprobs, old_logprobs, advantages, mask):
## policy gradient loss
log_ratio = (logprobs - old_logprobs) * mask
ratio = torch.exp(log_ratio)
pg_loss1 = -advantages * ratio
pg_loss2 = -advantages * torch.clamp(ratio, 1.0 - self.cliprange,
1.0 + self.cliprange)
pg_loss = torch.sum(torch.max(pg_loss1, pg_loss2) * mask) / mask.sum()
return pg_loss
"""
# 更新actor模型参数
self.actor_model.backward(actor_loss)
self.actor_model.step()
# 经验数据中的seq(instruct prompt+response)再一次喂入critic得到value
# 同理,由于当前的critic和当初进行经验数据采样时的critic相差很远;所以需要重新获得value
# 上图中黑色步骤(5)
value = self.critic_model.forward_value(**batch,
return_value_only=True,
use_cache=False)[:, :-1]
# 根据最新的critic的value,经验数据的old_value,以及advatage,计算得到critic loss
critic_loss = self.critic_loss_fn(value[:, start:], old_values[:,
start:],
returns, action_mask[:, start:])
"""
def critic_loss_fn(self, values, old_values, returns, mask):
## value loss
values_clipped = torch.clamp(
values,
old_values - self.cliprange_value,
old_values + self.cliprange_value,
)
vf_loss1 = (values - returns)**2
vf_loss2 = (values_clipped - returns)**2
vf_loss = 0.5 * torch.sum(
torch.max(vf_loss1, vf_loss2) * mask) / mask.sum()
return vf_loss
"""
# 更新critic参数
self.critic_model.backward(critic_loss)
self.critic_model.step()
return actor_loss, critic_loss
博主会不断更新关于大模型方面更多技术,相关文章请见:
【1】详谈大模型训练和推理优化技术
【2】Prompt-Tuning——深度解读一种新的微调范式
【3】InstructGPT原理讲解及ChatGPT类开源项目
【4】基于DeepSpeed训练ChatGPT
【5】【HuggingFace轻松上手】基于Wikipedia的知识增强预训练
【6】Pytorch单机多卡GPU的实现(原理概述、基本框架、常见报错)









![[LitCTF 2023]Flag点击就送!(cookie伪造)](https://img-blog.csdnimg.cn/d5efae44feeb4ee68a05b93ca4e744b9.png)