文章目录
- 前言
- 一、本地缓存和分布式缓存
- 二、redis客户端缓存机制
- 1.客户端缓存实现原理
- 普通模式
- 广播模式
- 重定向模式redirect
- 2.优势和误区
- 3.客户端缓存机制请求流程
- 三、项目实战
- 1.引入依赖
- 2.redis连接属性配置
- 3.开启客户端缓存
- 4.使用本地缓存
- 5.测试
- 总结
前言
采用缓存一直是我们提高项目响应速度的利器,而在一些高并发项目中还会引入多级缓存机制来进一步提高查询效率。那么怎么实现多级缓存,怎么保证多级缓存之间的数据一致性呢?
本文将介绍通过redis客户端缓存机制来实现本地缓存。
一、本地缓存和分布式缓存
缓存是存储在内存中的Key-Value数据结构,一般可以分为远程缓存和本地缓存。
-
远程缓存方案中,一般应用进程和缓存进程不在同一台服务器,通过RPC或HTTP进行通信,可以实现应用服务和缓存的完全解耦,支持大量的数据存储,分布式缓存常见有redis,memcache等。
注意:只要需要进行网络请求的缓存,都是远程缓存,并不是Redis服务和应用服务器部署在同一台服务器商就是本地缓存。 -
本地缓存方案中的应用进程和缓存进程在同一个进程,没有网络开销,访问速度快,但受限于内存,不适合存储大量数据。本地缓存主要有Guava cache,Caffeine,Encache等,还可以通过HashMap自实现一套本地缓存机制。
在高并发场景下,我们可以采用 本地缓存 + 远程缓存构建多级缓存架构来进一步提高缓存的稳定性和性能。多级缓存请求流程如下:
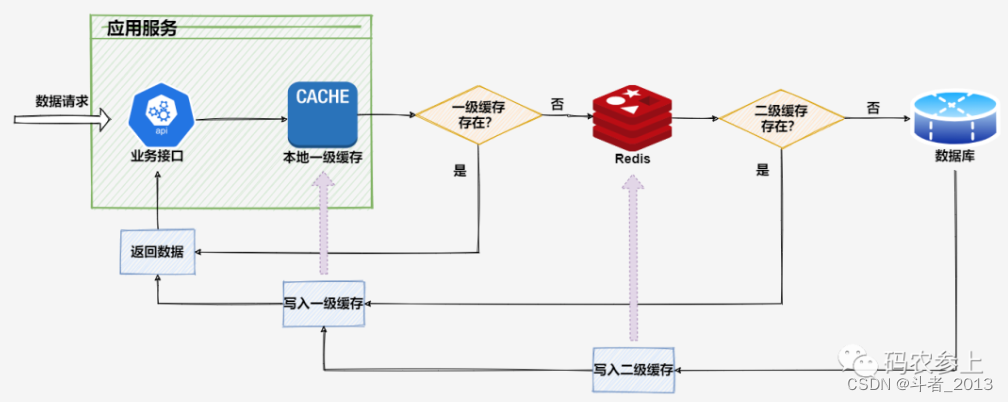
那么,使用两级缓存相比单纯使用远程缓存,具有什么优势呢?
- 本地缓存基于本地环境的内存,访问速度非常快,对于一些变更频率低、实时性要求低的数据,可以放在本地缓存中,提升访问速度
- 使用本地缓存能够减少和Redis类的远程缓存间的数据交互,减少网络I/O开销,降低这一过程中在网络通信上的耗时
- 减少了第三方进程的依赖,稳定性更高
但是在设计中,还是要考虑一些问题的,例如数据一致性问题。首先,两级缓存与数据库的数据要保持一致,一旦数据发生了修改,在修改数据库的同时,本地缓存、远程缓存应该同步更新。
另外,如果是分布式环境下,一级缓存之间也会存在一致性问题,当一个节点下的本地缓存修改后,需要通知其他节点也刷新本地缓存中的数据,否则会出现读取到过期数据的情况,这一问题可以通过类似于Redis中的发布/订阅功能解决。
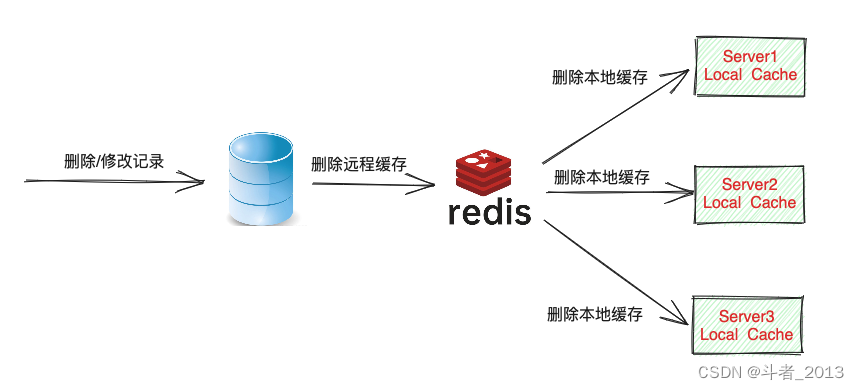
此外,缓存的过期时间、过期策略以及多线程访问的问题也都需要考虑进去。
二、redis客户端缓存机制
官方文档:Client-side caching in Redis
客户端缓存是Redis6众多新特性中比较实用的一项新功能,官网说明如下:
客户端缓存是一种用于创建高性能服务的技术,它可以利用应用服务器上的可用内存(这些服务器通常是一些不同于数据库服务器的节点),在应用服务端商直接存储数据库中的一些信息。与访问数据库等网络服务相比,访问本地内存所需要的时间消耗要少得多,因此这个模式可以大大缩短应用程序获取数据的延迟,同时也能减轻数据库的负载压力。
那么redis客户端缓存机制相比其他本地缓存Guava、Caffeine,除了少引入一个中间件外,还有哪些优势呢?
在分布式模式下,需要保证各个主机下的一级缓存的一致性问题,回想一下我们原先的解决方案,可以使用redis本身的发布/订阅功能来实现:
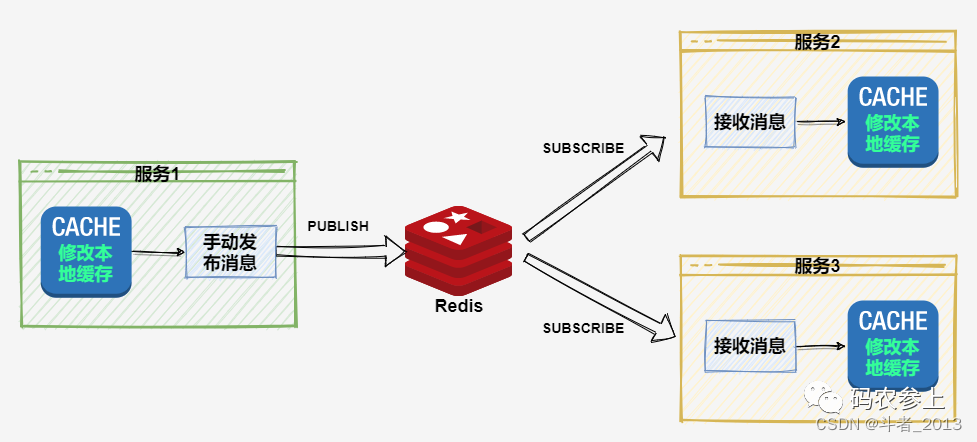
而客户端缓存的出现,大大简化了这一过程。我们以默认模式为例,看一下使用了客户端缓存后的操作过程:
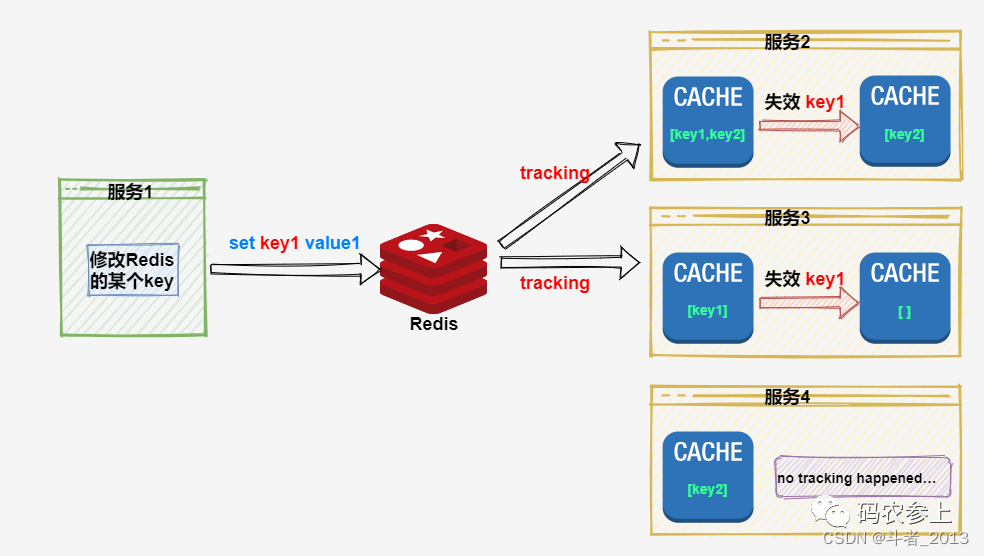
相比原先的发布/订阅模式,我们可以看到明显的优势,使用客户端缓存功能后,我们只需要单纯的修改redis中的数据就可以了,手动处理发布/订阅消息的这一过程可以完全被省略。
1.客户端缓存实现原理
Redis的客户端缓存支持被称为tracking。客户端缓存的命令是:
CLIENT TRACKING ON|OFF [REDIRECT client-id] [PREFIX prefix] [BCAST] [OPTIN] [OPTOUT] [NOLOOP]
Redis 6.0 实现 Tracking 功能提供了两种模式解决这个问题,分别是使用RESP3 协议版本的普通模式和广播模式,以及使用 RESP2 协议版本的转发模式。
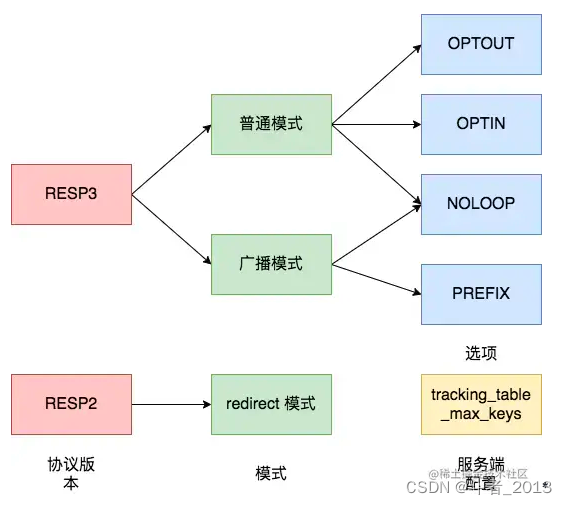
普通模式
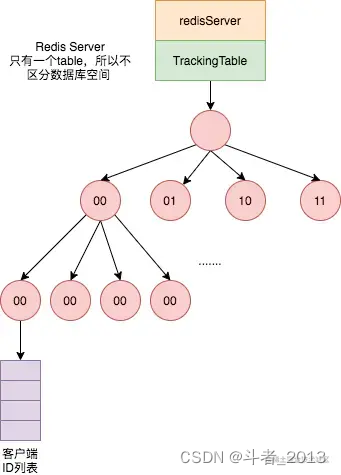
当tracking开启时, Redis会「记住」每个客户端请求的 key,当 key的值发现变化时会发送失效信息给客户端 (invalidation message)。失效信息可以通过 RESP3协议发送给请求的客户端,或者转发给一个不同的连接 (支持 RESP2 + Pub/Sub) 的客户端。
- Server 端将 Client 访问的 key以及该 key 对应的客户端 ID 列表信息存储在全局唯一的表(
TrackingTable),当表满了,回移除最老的记录,同时触发该记录已过期的通知给客户端。 - 每个 Redis 客户端又有一个唯一的数字 ID,TrackingTable 存储着每一个 Client ID,当连接断开后,清除该 ID 对应的记录。
- TrackingTable 表中记录的 Key 信息不考虑是哪个 database 的,虽然访问的是 db1 的 key,db2 同名 key 修改时会客户端收到过期提示,但这样做会减少系统的复杂性,以及表的存储数据量。
Redis 用TrackingTable存储键的指针和客户端 ID 的映射关系。因为键对象的指针就是内存地址,也就是长整型数据。客户端缓存的相关操作就是对该数据的增删改查:
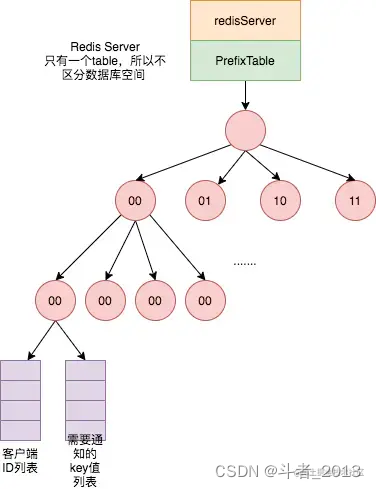
广播模式
当广播模式 (broadcasting) 开启时,服务器不会记住给定客户端访问了哪些键,因此这种模式在服务器端根本不消耗任何内存。
在这个模式下,服务端会给客户端广播所有 key 的失效情况,如果 key 被频繁修改,服务端会发送大量的失效广播消息,这就会消耗大量的网络带宽资源。
所以,在实际应用中,我们设置让客户端注册只跟踪指定前缀的 key,当注册跟踪的 key 前缀匹配被修改,服务端就会把失效消息广播给所有关注这个 key前缀的客户端。
client tracking on bcast prefix user
这种监测带有前缀的 key 的广播模式,和我们对 key 的命名规范非常匹配。我们在实际应用时,会给同一业务下的 key 设置相同的业务名前缀,所以,我们就可以非常方便地使用广播模式。
重定向模式redirect
普通模式与广播模式,需要客户端使用 RESP 3 协议,他是 Redis 6.0 新启用的协议。
对于使用 RESP 2 协议的客户端来说,实现客户端缓存则需要另一种模式:重定向模式(redirect)。
RESP 2 无法直接 PUSH 失效消息,所以 需要另一个支持 RESP 3 协议的客户端 告诉 Server 将失效消息通过 Pus/Sub 通知给 RESP 2 客户端。
在重定向模式下,想要获得失效消息通知的客户端,就需要执行订阅命令 SUBSCRIBE,专门订阅用于发送失效消息的频道 _redis_:invalidate。
同时,再使用另外一个客户端,执行 CLIENT TRACKING 命令,设置服务端将失效消息转发给使用 RESP 2 协议的客户端。
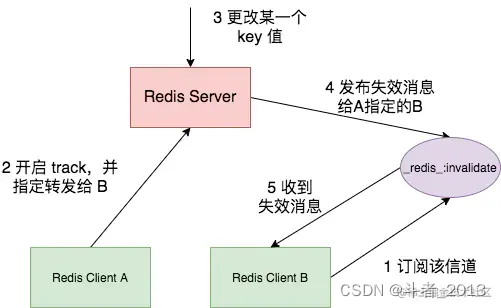
假设客户端 B 想要获取失效消息,但是客户端 B 只支持 RESP 2 协议,客户端 A 支持 RESP 3 协议。我们可以分别在客户端 B 和 A 上执行 SUBSCRIBE 和 CLIENT TRACKING,如下所示:
//客户端B执行,客户端 B 的 ID 号是 606
SUBSCRIBE _redis_:invalidate
//客户端 A 执行
CLIENT TRACKING ON BCAST REDIRECT 606
B 客户端就可以通过 _redis_:invalidate 频道获取失效消息了。
2.优势和误区
了解了客户端缓存的实现原理后,我们来对比一下,和传统的只使用redis做远程缓存、以及使用整合后的两级缓存相比较,客户端缓存具有什么样的优势。
-
优势
当应用的服务端存在缓存时,会直接读取本地缓存,能够减少网络访问上造成的延迟,从而加快访问速度,同时也能减少访问redis服务端的次数,降低redis的负载压力。
在分布式环境下,不再需要通过发布订阅来通知其他主机更新本地缓存,来保证数据的一致性。使用客户端缓存后,它所具有的原生的消息通知功能,能很好地支持作废本地缓存,保证之后访问时能取到更新后的新数据。 -
误区
虽然这个新特性被称为客户端缓存,但是redis本身不提供在应用服务端缓存数据的功能,这个功能要由访问redis的客户端自己去实现。
简单来说redis服务端只负责通知你,你缓存在应用服务本地的这个key已经作废了,至于你本地如何缓存的这些数据,redis并不关心,也不负责处理。
在Lettuce中封装的本地缓存实现CacheFrontend中,帮我们实现了本地缓存的处理操作:收到redis服务端的缓存失效后,本地缓存执行删除操作。
3.客户端缓存机制请求流程
- Client 1 -> Server: CLIENT TRACKING ON (客户端1开启
tracking机制) - Client 1 -> Server: GET foo (客户端1获取foo信息)
- (The server remembers that Client 1 may have the key “foo” cached) redis服务端记录客户端1拥有foo缓存信息
- (Client 1 may remember the value of “foo” inside its local memory) 客户端1记录foo信息到本地缓存
- Client 2 -> Server: SET foo SomeOtherValue (客户端2修改foo缓存信息)
- Server -> Client 1: INVALIDATE “foo” (redis服务端通知客户端2缓存的foo失效)
三、项目实战
1.引入依赖
redis6.x才开始支持客户端缓存功能,我们的lettuce依赖也需要使用6.x的版本才能支持客户段缓存特性。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<version>3.1.0</version>
<exclusions>
<exclusion>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
<version>6.2.4.RELEASE</version>
</dependency>
2.redis连接属性配置
#redis连接信息
spring.redis.host=127.0.0.1
spring.redis.port=6379
spring.redis.password=123456
#最大连接数 cpu*2
spring.redis.lettuce.pool.max-active = 8
#最大空闲连接数 cpu*2
spring.redis.lettuce.pool.max-idle = 8
#最小空闲连接数
spring.redis.lettuce.pool.min-idle = 0
#最长等待时间
spring.redis.lettuce.pool.max-wait = 5s
#空闲等待时间
spring.redis.lettuce.pool.time-between-eviction-runs = 1s
3.开启客户端缓存
@Configuration
public class RedisConfig {
@Bean
public CacheFrontend cacheFrontend(RedisProperties redisProperties){
RedisURI redisURI = RedisURI.builder()
.withHost(redisProperties.getHost())
.withPort(redisProperties.getPort())
.withPassword(redisProperties.getPassword())
.build();
StatefulRedisConnection<String, String> connect = RedisClient.create(redisURI).connect();
Map<String, String> clientCache = new ConcurrentHashMap<>();
return ClientSideCaching.enable(
CacheAccessor.forMap(clientCache),
connect,
//开启Tracking
TrackingArgs.Builder.enabled());
}
}
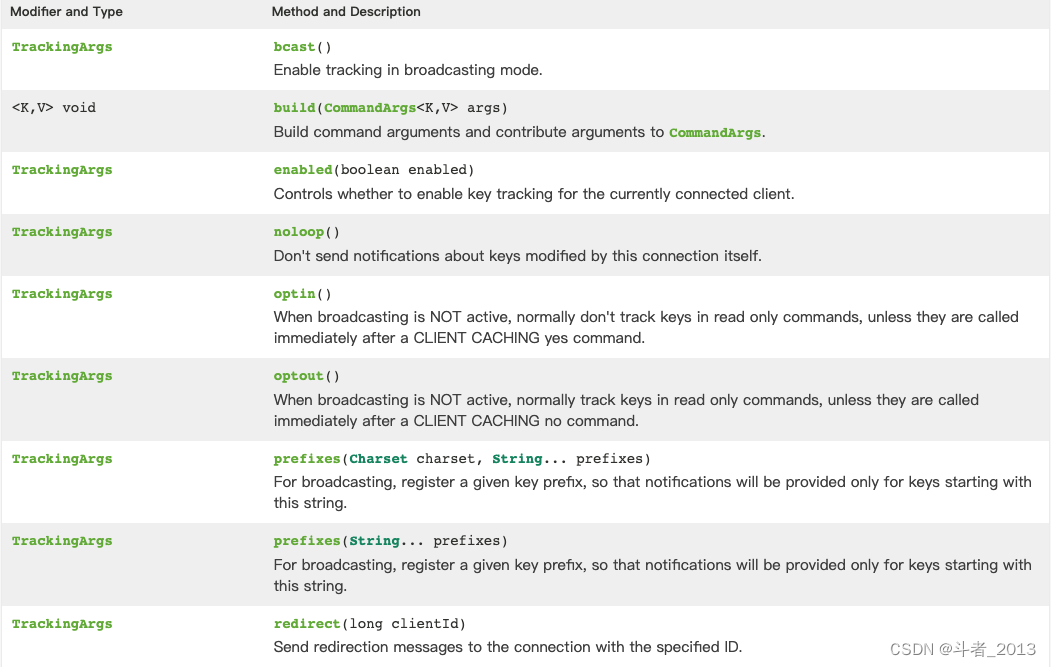
TrackingArgs参数介绍:官方文档
4.使用本地缓存
@Component
@Slf4j
public class CommandLineRunnerImpl implements CommandLineRunner {
@Autowired
private CacheFrontend cacheFrontend;
@Override
public void run(String... args) throws Exception {
log.info("打印user的本地缓存值:");
String key="user";
while (true){
String value = (String) cacheFrontend.get(key);
System.out.println(value);
TimeUnit.SECONDS.sleep(5);
}
}
}
CacheFrontend源码解析:
1、创建本地缓存CacheFrontend
private static <K, V> CacheFrontend<K, V> create(CacheAccessor<K, V> cacheAccessor, RedisCache<K, V> redisCache) {
ClientSideCaching<K, V> caching = new ClientSideCaching(cacheAccessor, redisCache);
//redis服务端监听到缓存失效后,通知本地缓存caching
redisCache.addInvalidationListener(caching::notifyInvalidate);
//本地缓存caching监听到失效,执行evict清除命令
caching.addInvalidationListener(cacheAccessor::evict);
return caching;
}
2、CacheFrontend中只有简单的get方法,用来获取本地缓存。
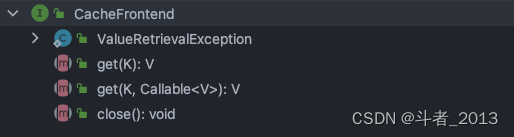
查看CacheFrontend的get方法的实现:
public V get(K key) {
//从本地缓存中查询,
V value = this.cacheAccessor.get(key);
if (value == null) {
//从redis远程缓存中查询
value = this.redisCache.get(key);
if (value != null) {
//保存到本地缓存
this.cacheAccessor.put(key, value);
}
}
return value;
}
5.测试
启动多个项目,然后通过redis客户端工具修改key= user的value值,可以发现本地缓存的信息可以实时更新;如果删除key= user的数据,本地缓存信息也删除。
打印user的本地缓存值:
laozhang
laozhang
laozhang
laowan
laowan
null
null
总结
基于redis6.x新增的客户端缓存机制我们轻松实现了本地缓存,并且不用去关心本地缓存和远程缓存之间的数据同步的细节。
- redis6.x版本新增客户端缓存机制(
Client-side caching),底层是通过tracking机制实现,需要RESP3协议支持。老版本中只能通过Pub/Sub通知本地缓存过期。 - 客户端缓存机制有两种模式:
普通模式与广播模式,普通模式Redis会「记住」每个客户端请求的 key,会占用redis服务端一定内存;广播模式服务器不会记住给定客户端访问了哪些键,在服务器端不消耗任何内存,但服务端会发送大量的失效广播消息,会消耗大量的网络带宽资源。 - lettuce6.x版本才能支持客户端缓存特性
Redis 6.0 绝绝子新特性:客户端缓存让性能更上一层楼
引入『客户端缓存』,Redis6算是把缓存玩明白了…
Redis+Caffeine两级缓存,让访问速度纵享丝滑









![[LitCTF 2023]Flag点击就送!(cookie伪造)](https://img-blog.csdnimg.cn/d5efae44feeb4ee68a05b93ca4e744b9.png)