论文地址:End-to-End Object Detection with Transformers
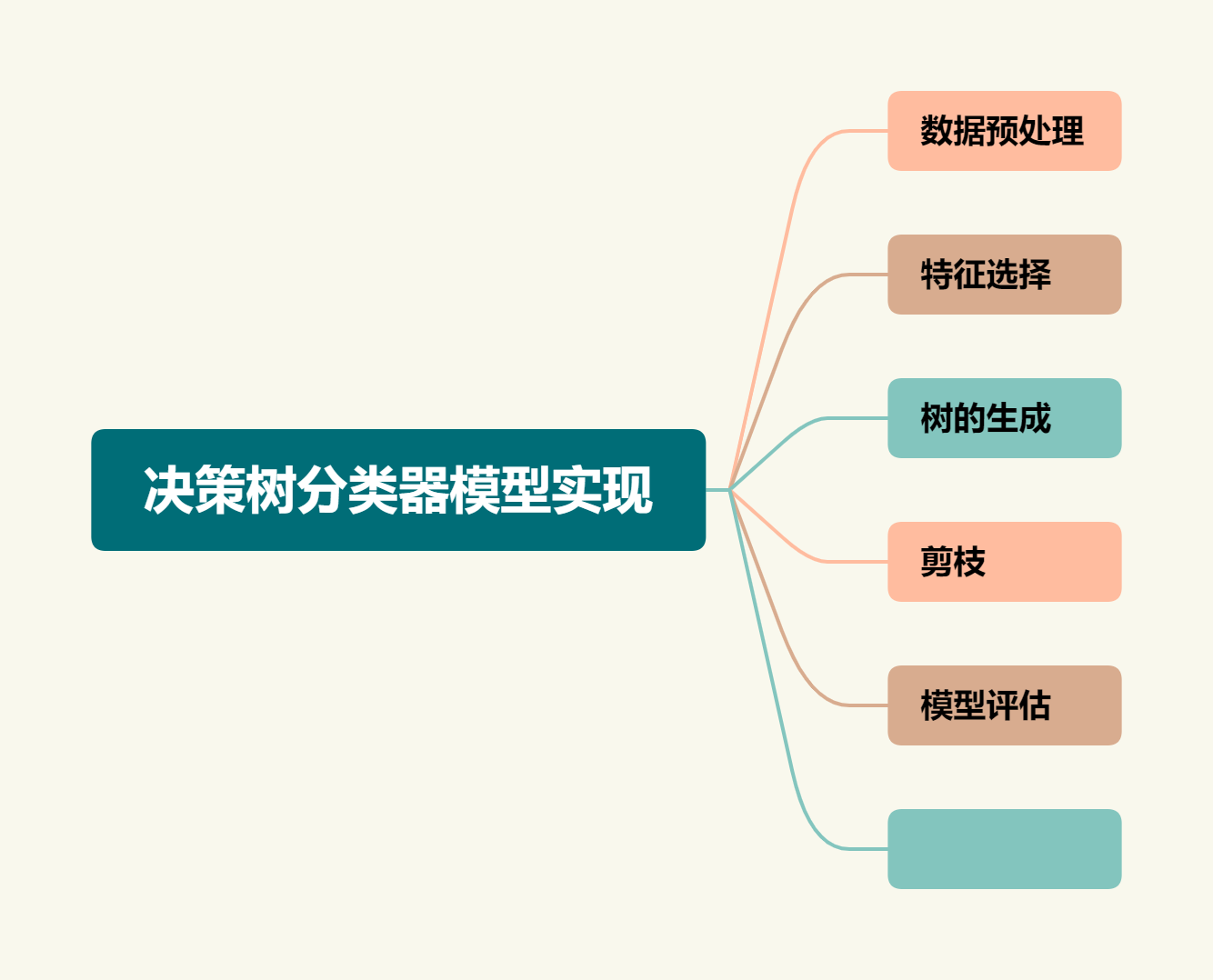
1. 解决了什么问题?
现有的目标检测算法需要大量的人为先验的设计,如 anchor 和 NMS,整体架构并不是端到端的。现有的检测方法为了去除重叠框,一般会利用 proposals, anchors 或中心点来定义回归和分类问题,然后通过后处理去除。
2. 提出了什么方法?
DETR 对目标检测流程做了改进,不再需要 NMS 和生成 anchors。它使用一个基于集合的全局损失,通过二分匹配法实现 one-to-one 预测;此外,使用了一个 encoder-decoder transformer 结构。DETR 中的 self-attention 机制对目标和图像全局信息之间的关系做推理,直接输出检测结果,排除重复预测。
2.1 Set prediction loss
DETR 预测 N N N个边框, N N N大于图像中可能出现的目标个数。设 ground-truth 目标集合为 y y y, y y y会用 ∅ \varnothing ∅(表示“没有目标”)进行填充,保证其元素个数为 N N N;预测目标集合为 y ^ = { y ^ i } i = 1 N \hat{y}=\{\hat{y}_i\}_{i=1}^N y^={y^i}i=1N。
第一步,为了在
y
y
y和
y
^
\hat{y}
y^这两个集合之间实现二分匹配,我们需要找到代价最低的排列组合
σ
∈
Π
N
\sigma \in \Pi_N
σ∈ΠN:
σ
^
=
arg min
σ
∈
Π
N
∑
i
N
L
match
(
y
i
,
y
^
σ
(
i
)
)
\hat{\sigma}=\argmin_{\sigma\in \Pi_N}\sum_{i}^N \mathcal{L}_{\text{match}}(y_i, \hat{y}_{\sigma(i)})
σ^=σ∈ΠNargmini∑NLmatch(yi,y^σ(i))
L match ( y i , y ^ σ ( i ) ) \mathcal{L}_{\text{match}}(y_i, \hat{y}_{\sigma(i)}) Lmatch(yi,y^σ(i))是 ground-truth 边框 y i y_i yi和索引是 σ ( i ) \sigma(i) σ(i)的预测框 y ^ σ ( i ) \hat{y}_{\sigma(i)} y^σ(i)之间的匹配代价。然后用 Hungarian 算法完成最优分配。与那些匹配 anchors 或 proposals 的目标检测方法相比,DETR 实现的是 one-to-one 对应,没有重复框。匹配代价包含了类别预测和边框重叠度:
L match ( y i , y ^ σ ( i ) ) = − I { c i ≠ ∅ } p ^ σ ( i ) ( c i ) + I { c i ≠ ∅ } L box ( b i , b ^ σ ( i ) ) \mathcal{L}_{\text{match}}(y_i, \hat{y}_{\sigma(i)})=-\mathbb{I}_{\{c_i\neq \varnothing\}}\hat{p}_{\sigma(i)}(c_i) + \mathbb{I}_{\{c_i\neq \varnothing\}}\mathcal{L}_{\text{box}}(b_i, \hat{b}_{\sigma(i)}) Lmatch(yi,y^σ(i))=−I{ci=∅}p^σ(i)(ci)+I{ci=∅}Lbox(bi,b^σ(i))
p ^ σ ( i ) ( c i ) \hat{p}_{\sigma(i)}(c_i) p^σ(i)(ci)是索引为 σ ( i ) \sigma(i) σ(i)的预测框对于 c i c_i ci类别的置信度, b i , b ^ σ ( i ) ∈ [ 0 , 1 ] 4 b_i, \hat{b}_{\sigma(i)}\in [0,1]^4 bi,b^σ(i)∈[0,1]4分别是 ground-truth 边框和预测框的坐标。
第二步,针对上面得到的所有的匹配对,计算 Hungarian loss:
L
Hungarian
(
y
,
y
^
)
=
∑
i
=
1
N
[
−
log
p
^
σ
^
(
i
)
(
c
i
)
+
I
{
c
i
≠
∅
}
L
box
(
b
i
,
b
^
σ
^
(
i
)
)
]
\mathcal{L}_{\text{Hungarian}}(y, \hat{y})=\sum_{i=1}^N \left[-\log\hat{p}_{\hat\sigma(i)}(c_i) + \mathbb{I}_{\{c_i\neq \varnothing\}}\mathcal{L}_{\text{box}}(b_i, \hat{b}_{\hat\sigma(i)})\right]
LHungarian(y,y^)=i=1∑N[−logp^σ^(i)(ci)+I{ci=∅}Lbox(bi,b^σ^(i))]
L box ( b i , b ^ σ ( i ) ) = λ iou L iou ( b i , b ^ σ ( i ) ) + λ L1 ∥ b i − b ^ σ ( i ) ∥ 1 \mathcal{L}_{\text{box}}(b_i, \hat{b}_{\sigma(i)})=\lambda_{\text{iou}}\mathcal{L}_{\text{iou}}(b_i, \hat{b}_{\sigma(i)}) + \lambda_{\text{L1}}\| b_i-\hat{b}_{\sigma(i)}\|_1 Lbox(bi,b^σ(i))=λiouLiou(bi,b^σ(i))+λL1∥bi−b^σ(i)∥1
其中 σ ^ \hat\sigma σ^是第一步得到的最优匹配。 λ iou , λ L1 ∈ R \lambda_{\text{iou}},\lambda_{\text{L1}}\in \mathbb{R} λiou,λL1∈R分别是平衡L1损失和 IOU 损失的超参数,L1损失和 IOU 损失会用 batch 的目标个数做归一化。
2.2 网络结构

DETR 包括了3个组成部分:特征提取的 CNN 主干、encoder-decoder transformer 以及一个进行预测的 FFN。
2.2.1 主干网络
输入图像是 x img ∈ R 3 × H 0 × W 0 x_{\text{img}}\in \mathbb{R}^{3\times H_0\times W_0} ximg∈R3×H0×W0,主干网络提取的特征图是 f ∈ R C × H × W f\in \mathbb{R}^{C\times H\times W} f∈RC×H×W, C = 2048 , H = H 0 32 C=2048, H=\frac{H_0}{32} C=2048,H=32H0, W = W 0 32 W=\frac{W_0}{32} W=32W0。
2.2.2 Transformer Encoder
首先,使用 1 × 1 1\times 1 1×1卷积将特征图 f f f的通道维度从 C C C降为 d d d,得到新特征图 z 0 ∈ R d × H × W z_0\in\mathbb{R}^{d\times H\times W} z0∈Rd×H×W。Encoder 的输入为一个序列,所以将 z 0 z_0 z0的空间维度降为一维, z 0 ∈ R d × H W z_0\in\mathbb{R}^{d\times H W} z0∈Rd×HW。每个 encoder 层都有一个 self-attention 模块和 FFN。此外,在每个 attention 层的输入里面加入 positional encodings。
2.2.3 Transformer Decoder
使用 multi-head 的 self-attention 和 cross-attention 对 N N N个 d − d- d−维的 embedding 做变换,这 N N N个 embeddings 就是学到的 positional encodings,叫做 object queries,它们会被加到 attention 层的输入里面。Decoder 对这 N N N个 object queries 做变换,得到一个输出 embedding,然后再通过 FFN 解码为边框坐标和类别标签,即 N N N个预测框。
2.2.4 Feed-forward Networks
FFN 由一个三层感知机及 ReLU 激活函数组成,隐藏层维度是 d d d。此外,还有一个 linear projection 层通过 softmax 函数预测类别。FFN 预测边框归一化的中心点坐标、高度和宽度。使用了一个共享的 layer norm 操作来归一化 FFN 的输入。
2.2.5 Auxiliary Decoding Losses
训练时,使用了一个辅助损失,帮助模型输出各类别正确个数的目标。在每个 decoder 层后是 FFNs 和 Hungarian loss。这些 FFNs 共享参数,使用了一个共享的 layer norm 来归一化 FFNs 的输入(即 decoder 的输出)。
2.3 Single-head Attention
一个注意力 head 的张量记做 attn ( X q , X k v , T ′ ) \text{attn}(X_q,X_{kv}, T') attn(Xq,Xkv,T′),其权重为 T ′ ∈ R 3 × d ′ × d T'\in \mathbb{R}^{3\times d'\times d} T′∈R3×d′×d,query 的 positional encoding 是 P q ∈ R d × N q , P_q\in\mathbb{R}^{d\times N_q}, Pq∈Rd×Nq, key 和 values 的 positional encoding 是 P k v ∈ R d × N k v P_{kv}\in \mathbb{R}^{d\times N_{kv}} Pkv∈Rd×Nkv,先计算 query, key 和 value embeddings:
[
Q
;
K
;
V
]
=
[
T
1
′
(
X
q
+
P
q
)
;
T
2
′
(
X
k
v
+
P
k
v
)
;
T
3
′
X
k
v
]
\left[ Q; K; V \right]=\left[T'_1(X_q+P_q);\quad T'_2(X_{kv}+P_{kv});\quad T'_3X_{kv}\right]
[Q;K;V]=[T1′(Xq+Pq);T2′(Xkv+Pkv);T3′Xkv]
T
′
T'
T′是将
T
1
′
,
T
2
′
,
T
3
′
T'_1,T'_2,T'_3
T1′,T2′,T3′ concat 后的结果。Attention weights
α
\alpha
α计算过程如下:
α i , j = exp ( 1 d ′ Q i T K j ) ∑ j = 1 N k v exp ( 1 d ′ Q i T K j ) \alpha_{i,j}=\frac{\exp(\frac{1}{\sqrt{d'}}Q_i^TK_j)}{\sum_{j=1}^{N_{kv}}\exp(\frac{1}{\sqrt{d'}}Q_i^TK_j)} αi,j=∑j=1Nkvexp(d′1QiTKj)exp(d′1QiTKj)
第 i i i个 attention 层的输出就是:
attn i ( X q , X k v , T ′ ) = ∑ j = 1 N k v α i , j V j . \text{attn}_i(X_q,X_{kv},T')=\sum_{j=1}^{N_{kv}}\alpha_{i,j}V_j. attni(Xq,Xkv,T′)=j=1∑Nkvαi,jVj.
2.4 Detailed Structure

将 CNN 主干网络计算的特征图输入 transformer encoder,spatial positional encoding 加入 multi-head self-attention 层的 keys 和 queries 中。Decoder 接收 object queries、encoder 计算的特征图,最终输出预测框的坐标和类别。
2.5 计算复杂度
- Encoder 中每个 self-attention 的计算复杂度是 O ( d 2 H W + d ( H W ) 2 ) \mathcal{O}(d^2HW+d(HW)^2) O(d2HW+d(HW)2),前者是计算 query/key/value embeddings 的复杂度,后者是计算 attention weight 的复杂度。
- Decoder 中每个 self-attention 的计算复杂度是 O ( d 2 ( N + H W ) + d N H W ) \mathcal{O}(d^2(N+HW)+dNHW) O(d2(N+HW)+dNHW)。
2.6 Experiments
作者在 COCO 2017 检测与全景分割数据集(包括11.8万张训练图片、5000张验证图片)上做了实验。每张图片都包括边框和全景分割标注,平均每张图片有7个实例,最多的有63个实例。
使用了 AdamW 训练 DETR,主干网络的初始学习率是
1
0
−
5
10^{-5}
10−5,transformer 的是
1
0
−
4
10^{-4}
10−4,weight decay 是
1
0
−
4
10^{-4}
10−4。所有的 transformer 权重用 Xavier 初始化,主干网络使用了在 ImageNet 上预训练的 ResNet-50 和 ResNet-101 模型。
使用了 scale augmentation,图像短边最小是480,最大是800,图像长边最多是1333。训练过程中,也使用了随机裁剪策略,涨了约 1 AP。在消融实验中,每次训练 300 个 epochs,在第 200 个 epoch 时学习率乘以 0.1。使用了 16 张 V100 GPUs,每个 GPU 训练 4 张图片,batch size 就是 64。

2.7 Ablations
DETR 的主干网络为 ResNet-50,有6个 encoder,6个 decoder,宽度为 256。模型共有 4130 万个参数,300 个训练 epochs 得到的 AP 是 40.6,速度是 28 FPS,与 Faster R-CNN-FPN 相当。
2.7.1 Encoder 层数

从上表可看出,若没有 encoder 层,整体 AP 会下降 3.9,大目标会下降 6.0 AP。
Encoder 对全局场景做推理,能够区分开各个目标。从下图可看出,最后一层 encoder 关注于图像上的一些点。Encoder 似乎已经区分开各实例,简化了 decoder 目标提取和定位的工作。

2.7.2 Decoder 层数
从下图可以看出,decoder 层能明显提升
A
P
AP
AP和
A
P
50
AP_{50}
AP50,增加了
+
8.2
/
9.5
A
P
+8.2/9.5 AP
+8.2/9.5AP。DETR 使用了 set-based loss,不再需要 NMS。如图,在第一个 decoder 后添加 NMS 能提升表现,是因为单个的 decoder 无法计算输出元素之间的相互关系,有可能会对同一个目标产生多个预测。随着 decoder 增多,自注意力机制就能抑制重复的预测框。

如下图,用不同的颜色表示注意力图里面的每个目标。Decoder 注意力要更加关注在目标局部区域的极点,如腿和头。Encoder 通过全局注意力区分开实例,decoder 只需关注这些极点来提取类别和边界信息。

2.7.3 Positional Encodings
DETR 共有2种 positional encodings,空间位置编码和输出位置编码(object queries)。输出位置编码是不能移除的,因而作者试验了将其加到 decoder 输入,或者加到 decoder 注意力层的 queries 两种情形。如下表,
- 在第一个实验中,完全去除了空间位置编码,将输出位置编码加到 decoder 输入,模型仍取得了 32 A P 32 AP 32AP。
- 然后输入固定的 sine 空间位置编码,将输出位置编码加到 decoder 输入,降低了 1.4 A P 1.4 AP 1.4AP。
- 不对 encoder 输入空间位置编码只会降低 1.3 A P 1.3 AP 1.3AP。
进入注意力层的 encodings 会在所有的层之间共享,并且总能学习到输出位置编码(object queries)。

3. 有什么优点?
- 得益于 transformer 的 non-local 机制,DETR 对大目标检测效果优于 Faster R-CNN。
- 整体流程是端到端的,无需人为的先验知识如 NMS 和 anchor 机制。
- 拓展到其它任务上比较容易,如全景分割。
4. 存在什么问题?
- 训练时间非常长,epochs 数约是 Faster R-CNN 的 10 到 20 倍。模型初始化时,注意力模块给特征图上所有的像素点分配的权重是平权的,就需要较长的训练 epochs 使注意力权重学习关注到稀疏的、有意义的像素位置。
- 计算量高,transformer encoder 中的注意力权重的计算量关于像素个数是二次的,计算量和内存占用就非常高。
- 对小目标识别表现不好。