1 Lucene准备
Lucene可以在官网上下载:Apache Lucene - Welcome to Apache Lucene。我们使用的是7.7.2版本,文件位置如下图:
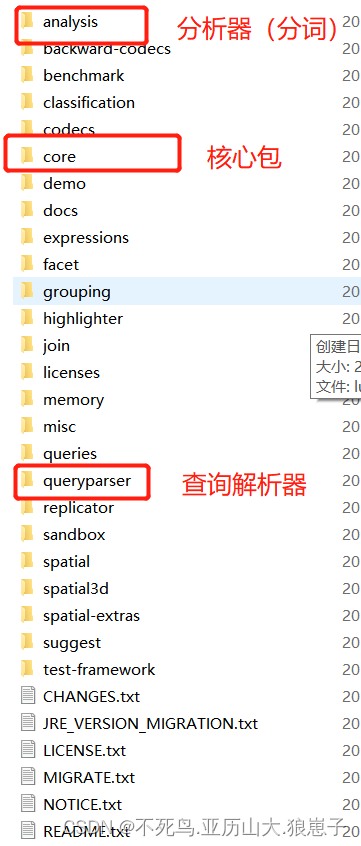
使用这三个文件的jar包,就可以实现lucene功能
2 开发环境准备
JDK: 1.8 (Lucene7以上,必须使用JDK1.8及以上版本)
数据库: MySQL
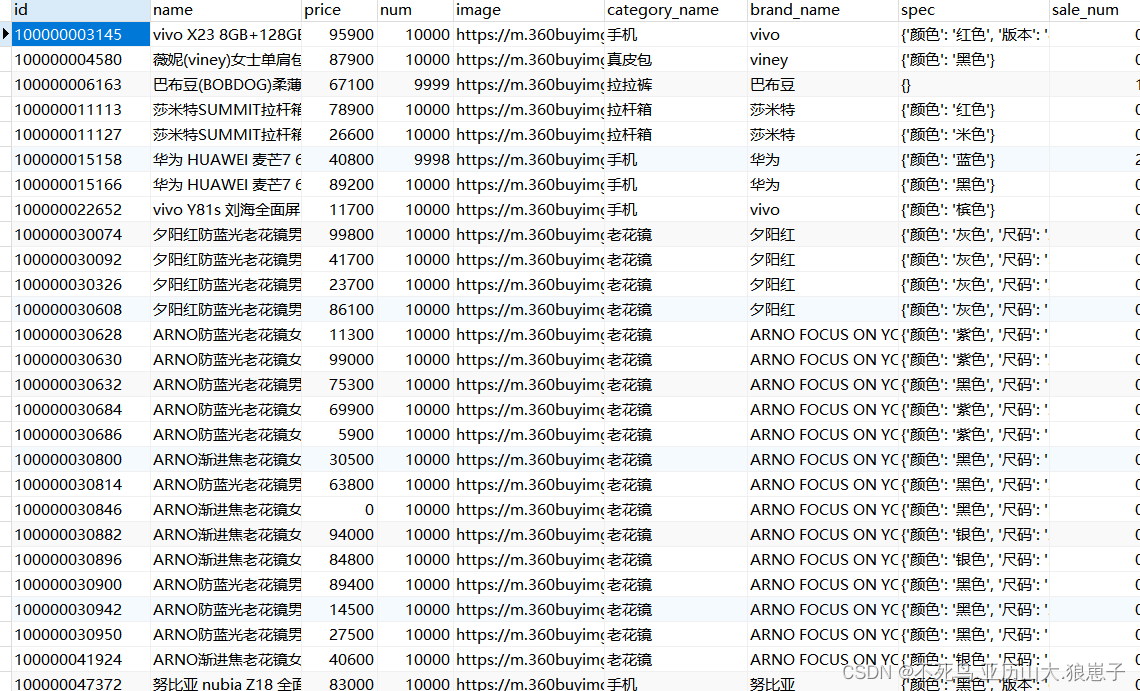
数据库脚本:https://download.csdn.net/download/u013938578/87806726
导入结果如下:
3 创建java工程
创建maven工程不依赖骨架, 测试即可,效果如下:
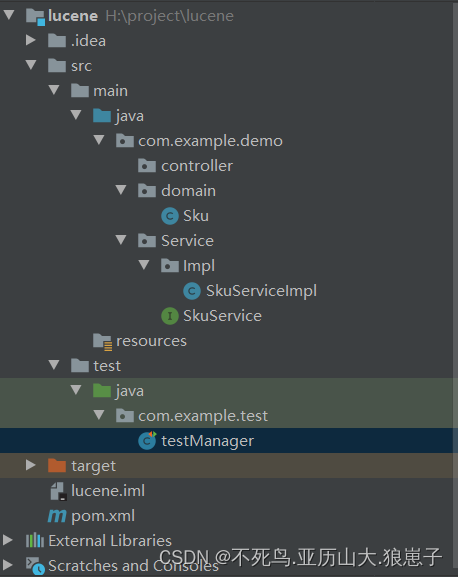
引用maven
<dependencies>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>7.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>7.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>7.7.2</version>
</dependency>
<!-- 测试 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<!-- mysql数据库驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.48</version>
</dependency>
<!-- IK中文分词器 -->
<dependency>
<groupId>org.wltea.ik-analyzer</groupId>
<artifactId>ik-analyzer</artifactId>
<version>8.1.0</version>
</dependency>
<!--web起步依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- 引入thymeleaf -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-thymeleaf</artifactId>
</dependency>
<!-- Json转换工具 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.51</version>
</dependency>
</dependencies>4 索引流程
4.1 数据采集
在电商网站中,全文检索的数据源在数据库中,需要通过jdbc访问数据库中tb_sku 表的内容。
4.1.1 创建数据持久层
package com.example.demo.domain;
public class Sku {
//商品主键id
private String id;
//商品名称
private String name;
//价格
private Integer price;
//库存数量
private Integer num;
//图片
private String image;
//分类名称
private String categoryName;
//品牌名称
private String brandName;
//规格
private String spec;
//销量
private Integer saleNum;
public Sku(String id, String name, Integer price, Integer num, String image, String categoryName, String brandName, String spec, Integer saleNum) {
this.id = id;
this.name = name;
this.price = price;
this.num = num;
this.image = image;
this.categoryName = categoryName;
this.brandName = brandName;
this.spec = spec;
this.saleNum = saleNum;
}
public Sku() {
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getPrice() {
return price;
}
public void setPrice(Integer price) {
this.price = price;
}
public Integer getNum() {
return num;
}
public void setNum(Integer num) {
this.num = num;
}
public String getImage() {
return image;
}
public void setImage(String image) {
this.image = image;
}
public String getCategoryName() {
return categoryName;
}
public void setCategoryName(String categoryName) {
this.categoryName = categoryName;
}
public String getBrandName() {
return brandName;
}
public void setBrandName(String brandName) {
this.brandName = brandName;
}
public String getSpec() {
return spec;
}
public void setSpec(String spec) {
this.spec = spec;
}
public Integer getSaleNum() {
return saleNum;
}
public void setSaleNum(Integer saleNum) {
this.saleNum = saleNum;
}
}
4.1.2 创建Service接口
package com.example.demo.Service;
import com.example.demo.domain.Sku;
import java.util.List;
public interface SkuService {
/**
* 查询所有的Sku数据
* @return
**/
public List<Sku> querySkuList();
}
4.1.3 创建DAO接口实现类
使用jdbc实现
package com.example.demo.Service.Impl;
import com.example.demo.Service.SkuService;
import com.example.demo.domain.Sku;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.ArrayList;
import java.util.List;
public class SkuServiceImpl implements SkuService {
public List<Sku> querySkuList() {
// 数据库链接
Connection connection = null;
// 预编译statement
PreparedStatement preparedStatement = null;
// 结果集
ResultSet resultSet = null;
// 商品列表
List<Sku> list = new ArrayList<Sku>();
try {
// 加载数据库驱动
Class.forName("com.mysql.jdbc.Driver");
// 连接数据库
connection = DriverManager.getConnection("jdbc:mysql://192.168.222.132:3306/lucene?useUnicode=true&characterEncoding=utf-8&useSSL=false", "root","123456");
// SQL语句
String sql = "SELECT * FROM tb_sku";
// 创建preparedStatement
preparedStatement = connection.prepareStatement(sql);
// 获取结果集
resultSet = preparedStatement.executeQuery();
// 结果集解析
while (resultSet.next()) {
Sku sku = new Sku();
sku.setId(resultSet.getString("id"));
sku.setName(resultSet.getString("name"));
sku.setSpec(resultSet.getString("spec"));
sku.setBrandName(resultSet.getString("brand_name"));
sku.setCategoryName(resultSet.getString("category_name"));
sku.setImage(resultSet.getString("image"));
sku.setNum(resultSet.getInt("num"));
sku.setPrice(resultSet.getInt("price"));
sku.setSaleNum(resultSet.getInt("sale_num"));
list.add(sku);
}
} catch (Exception e) {
e.printStackTrace();
}
return list;
}
}
4.2 实现索引流程
- 采集数据
- 创建Document文档对象
- 创建分析器(分词器)
- 创建IndexWriterConfig配置信息类
- 创建Directory对象,声明索引库存储位置
- 创建IndexWriter写入对象
- 把Document写入到索引库中
- 释放资源
package com.example.test;
import com.example.demo.Service.Impl.SkuServiceImpl;
import com.example.demo.Service.SkuService;
import com.example.demo.domain.Sku;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.junit.Test;
import java.nio.file.Paths;
import java.util.ArrayList;
import java.util.List;
public class testManager {
@Test
public void createIndexTest() throws Exception {
// 1. 采集数据
SkuService skuDao = new SkuServiceImpl();
List<Sku> skuList = skuDao.querySkuList();
// 2. 创建Document文档对象
List<Document> documents = new ArrayList<Document>();
for (Sku sku : skuList) {
Document document = new Document();
// Document文档中添加Field域
// 商品Id
// Store.YES:表示存储到文档域中
document.add(new TextField("id", sku.getId(), Field.Store.YES));
// 商品名称
document.add(new TextField("name", sku.getName(), Field.Store.YES));
// 商品价格
document.add(new TextField("price", sku.getPrice().toString(),
Field.Store.YES));
// 品牌名称
document.add(new TextField("brandName", sku.getBrandName(),
Field.Store.YES));
// 分类名称
document.add(new TextField("categoryName", sku.getCategoryName(),
Field.Store.YES));
// 图片地址
document.add(new TextField("image", sku.getImage(),
Field.Store.YES));
// 把Document放到list中
documents.add(document);
}
// 3. 创建Analyzer分词器,分析文档,对文档进行分词
Analyzer analyzer = new StandardAnalyzer();
// 4. 创建Directory对象,声明索引库的位置
Directory directory = FSDirectory.open(Paths.get("E:\\dir"));
// 5. 创建IndexWriteConfig对象,写入索引需要的配置
IndexWriterConfig config = new IndexWriterConfig(analyzer);
// 6.创建IndexWriter写入对象
IndexWriter indexWriter = new IndexWriter(directory, config);
// 7.写入到索引库,通过IndexWriter添加文档对象document
for (Document doc : documents) {
indexWriter.addDocument(doc);
}
// 8.释放资源
indexWriter.close();
}
}
执行效果:
代码里面设置了索引库的位置,如下:
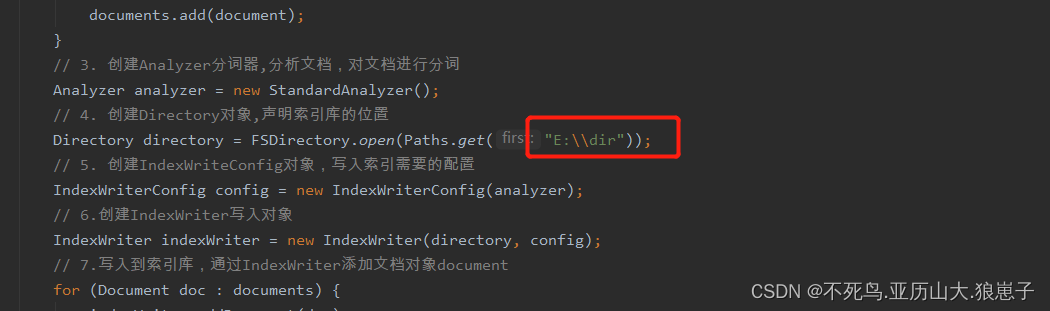
在索引库中出现了以下文件,表示创建索引成功
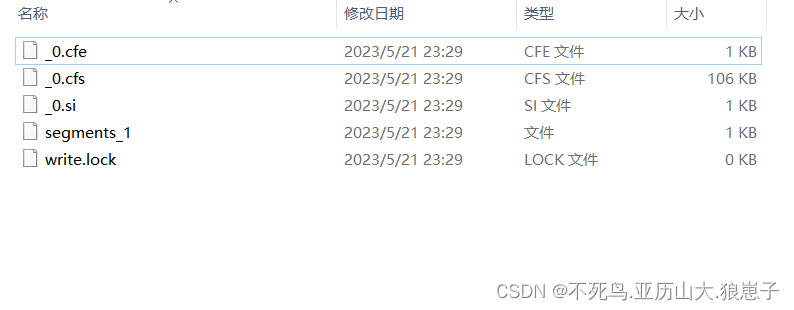
4.5 使用Luke查看索引
Luke作为Lucene工具包中的一个工具(http://www.getopt.org/luke/),可以通过界面来进行索引文件的查询、修改。
将luke-swing-8.0.0里面的内容, 放到一个硬盘根目录的文件夹下, 不能有空格和中文名称。
运行luke.bat
打开后,使用如下图:
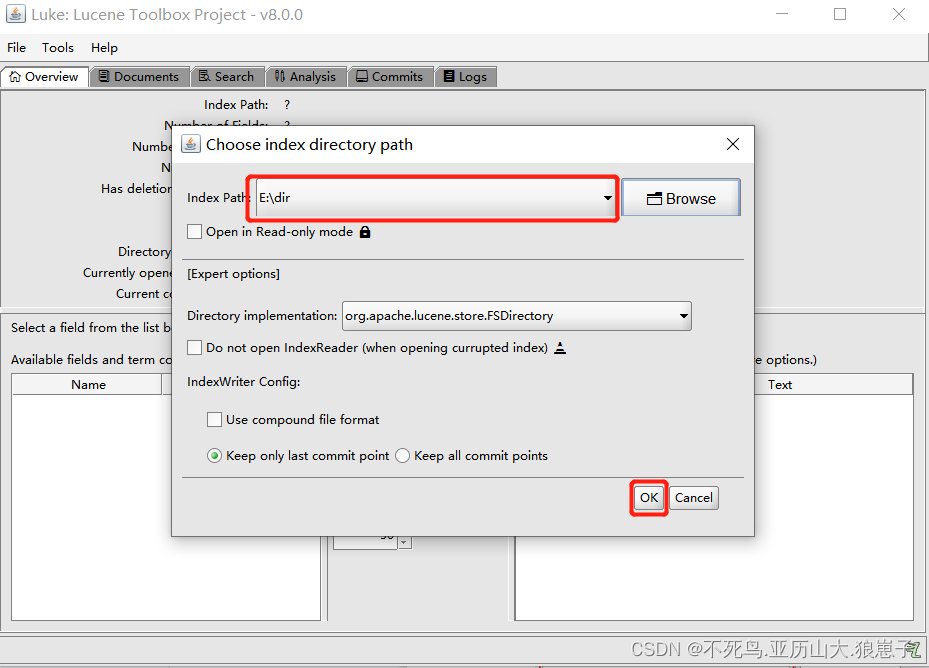
下图是索引域的展示效果:
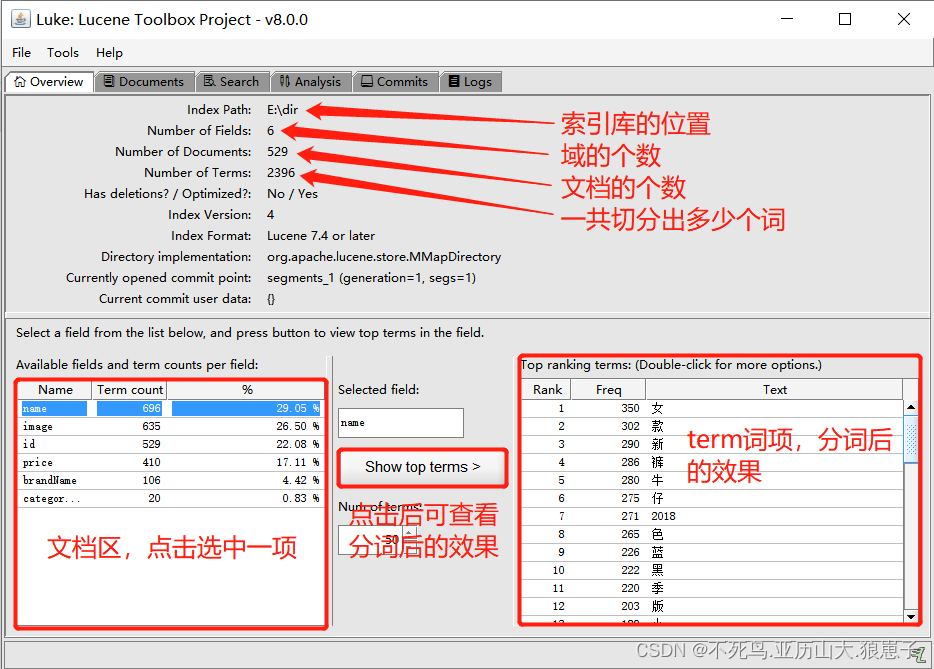
下图是文档域展示效果
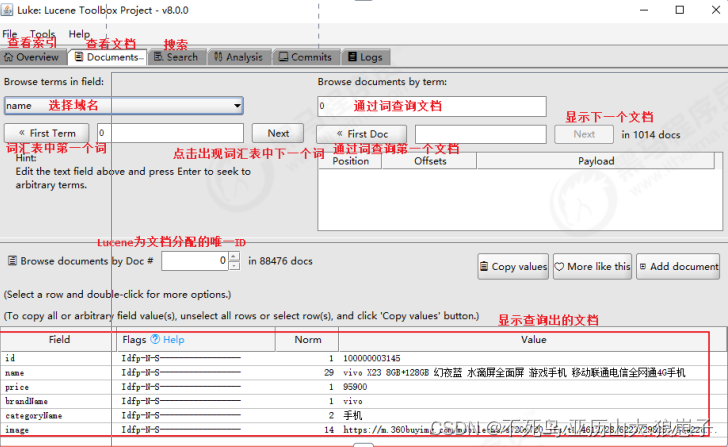
4.6 搜索流程
4.6.1 输入查询语句
Lucene可以通过query对象输入查询语句。同数据库的sql一样,lucene也有固定的查询语法:
最基本的有比如:AND, OR, NOT 等(必须大写)
举个栗子:
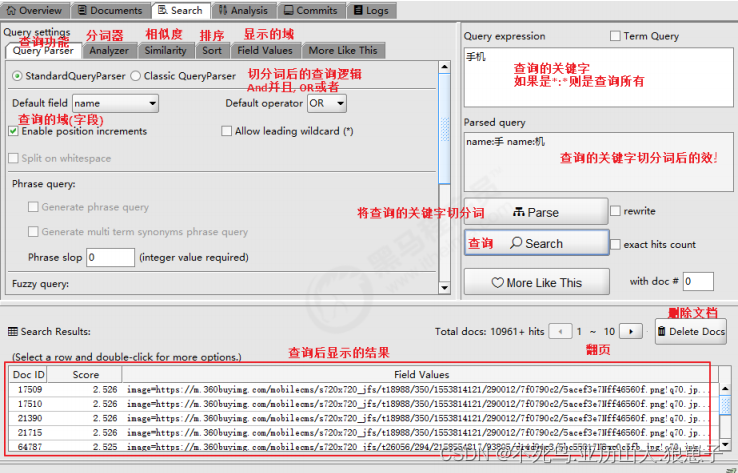
用户想找一个 name 域中包括 手 或 机 关键字的文档。
它对应的查询语句:name:手 OR name:机
如下图是使用luke搜索的例子:
搜索分词
和索引过程的分词一样,这里要对用户输入的关键字进行分词,一般情况索引和搜索使用的分词器一致。
比如:输入搜索关键字“java学习”,分词后为java和学习两个词,与java和学习有关的内容都搜索出来了,如下:
4.6.2 代码实现
- 创建Query搜索对象
- 创建Directory流对象,声明索引库位置
- 创建索引读取对象IndexReader
- 创建索引搜索对象IndexSearcher
- 使用索引搜索对象,执行搜索,返回结果集TopDocs
- 解析结果集
- 释放资源
IndexSearcher搜索方法如下:
| 方法 | 说明 |
| indexSearcher.search(query, n) | 根据Query搜索,返回评分最高的n条记录 |
| indexSearcher.search(query, filter, n) | 根据Query搜索,添加过滤策略,返回评分最高的n条记录 |
| indexSearcher.search(query, n, sort) | 根据Query搜索,添加排序策略,返回评分最高的n条记录 |
| indexSearcher.search(booleanQuery,filter,n, sort) | 根据Query搜索,添加过滤策略,添加排序策略,返回评分最高的n条记录 |
代码实现
package com.example.test;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.IntPoint;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.queryparser.classic.MultiFieldQueryParser;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.*;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.junit.Test;
import org.wltea.analyzer.lucene.IKAnalyzer;
import java.nio.file.Paths;
import java.util.HashMap;
import java.util.Map;
/**
* 测试搜索过程
*/
public class TestSearch {
@Test
public void testIndexSearch() throws Exception {
//1. 创建分词器(对搜索的关键词进行分词使用)
//注意: 分词器要和创建索引的时候使用的分词器一模一样
Analyzer analyzer = new StandardAnalyzer();
//2. 创建查询对象,
//第一个参数: 默认查询域, 如果查询的关键字中带搜索的域名, 则从指定域中查询, 如果不带域名则从, 默认搜索域中查询
//第二个参数: 使用的分词器
QueryParser queryParser = new QueryParser("name", analyzer);
//3. 设置搜索关键词
//华 OR 为 手 机
Query query = queryParser.parse("华为手机");
//4. 创建Directory目录对象, 指定索引库的位置
Directory dir = FSDirectory.open(Paths.get("E:\\dir"));
//5. 创建输入流对象
IndexReader indexReader = DirectoryReader.open(dir);
//6. 创建搜索对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
//7. 搜索, 并返回结果
//第二个参数: 是返回多少条数据用于展示, 分页使用
TopDocs topDocs = indexSearcher.search(query, 10);
//获取查询到的结果集的总数, 打印
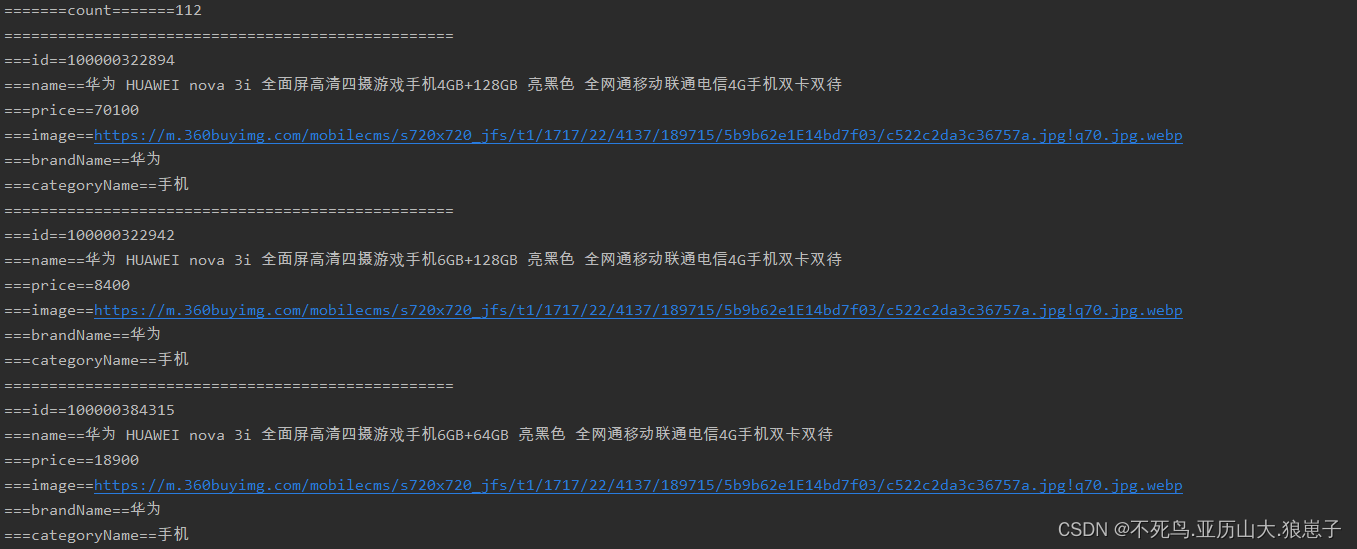
System.out.println("=======count=======" + topDocs.totalHits);
//8. 获取结果集
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
//9. 遍历结果集
if (scoreDocs != null) {
for (ScoreDoc scoreDoc : scoreDocs) {
//获取查询到的文档唯一标识, 文档id, 这个id是lucene在创建文档的时候自动分配的
int docID = scoreDoc.doc;
//通过文档id, 读取文档
Document doc = indexSearcher.doc(docID);
System.out.println("==================================================");
//通过域名, 从文档中获取域值
System.out.println("===id==" + doc.get("id"));
System.out.println("===name==" + doc.get("name"));
System.out.println("===price==" + doc.get("price"));
System.out.println("===image==" + doc.get("image"));
System.out.println("===brandName==" + doc.get("brandName"));
System.out.println("===categoryName==" + doc.get("categoryName"));
}
}
//10. 关闭流
}
/**
* 数值范围查询
* @throws Exception
*/
@Test
public void testRangeQuery() throws Exception {
//1. 创建分词器(对搜索的关键词进行分词使用)
//注意: 分词器要和创建索引的时候使用的分词器一模一样
Analyzer analyzer = new StandardAnalyzer();
//2. 创建查询对象,
Query query = IntPoint.newRangeQuery("price", 100, 1000);
//4. 创建Directory目录对象, 指定索引库的位置
Directory dir = FSDirectory.open(Paths.get("E:\\dir"));
//5. 创建输入流对象
IndexReader indexReader = DirectoryReader.open(dir);
//6. 创建搜索对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
//7. 搜索, 并返回结果
//第二个参数: 是返回多少条数据用于展示, 分页使用
TopDocs topDocs = indexSearcher.search(query, 10);
//获取查询到的结果集的总数, 打印
System.out.println("=======count=======" + topDocs.totalHits);
//8. 获取结果集
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
//9. 遍历结果集
if (scoreDocs != null) {
for (ScoreDoc scoreDoc : scoreDocs) {
//获取查询到的文档唯一标识, 文档id, 这个id是lucene在创建文档的时候自动分配的
int docID = scoreDoc.doc;
//通过文档id, 读取文档
Document doc = indexSearcher.doc(docID);
System.out.println("==================================================");
//通过域名, 从文档中获取域值
System.out.println("===id==" + doc.get("id"));
System.out.println("===name==" + doc.get("name"));
System.out.println("===price==" + doc.get("price"));
System.out.println("===image==" + doc.get("image"));
System.out.println("===brandName==" + doc.get("brandName"));
System.out.println("===categoryName==" + doc.get("categoryName"));
}
}
//10. 关闭流
}
/**
* 组合查询
* @throws Exception
*/
@Test
public void testBooleanQuery() throws Exception {
//1. 创建分词器(对搜索的关键词进行分词使用)
//注意: 分词器要和创建索引的时候使用的分词器一模一样
Analyzer analyzer = new StandardAnalyzer();
//2. 创建查询对象,
Query query1 = IntPoint.newRangeQuery("price", 100, 1000);
QueryParser queryParser = new QueryParser("name", analyzer);
//3. 设置搜索关键词
//华 OR 为 手 机
Query query2 = queryParser.parse("华为手机");
//创建布尔查询对象(组合查询对象)
/**
* BooleanClause.Occur.MUST 必须相当于and, 也就是并且的关系
* BooleanClause.Occur.SHOULD 应该相当于or, 也就是或者的关系
* BooleanClause.Occur.MUST_NOT 不必须, 相当于not, 非
* 注意: 如果查询条件都是MUST_NOT, 或者只有一个查询条件, 然后这一个查询条件是MUST_NOT则
* 查询不出任何数据.
*/
BooleanQuery.Builder query = new BooleanQuery.Builder();
query.add(query1, BooleanClause.Occur.MUST);
query.add(query2, BooleanClause.Occur.MUST);
//4. 创建Directory目录对象, 指定索引库的位置
Directory dir = FSDirectory.open(Paths.get("E:\\dir"));
//5. 创建输入流对象
IndexReader indexReader = DirectoryReader.open(dir);
//6. 创建搜索对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
//7. 搜索, 并返回结果
//第二个参数: 是返回多少条数据用于展示, 分页使用
TopDocs topDocs = indexSearcher.search(query.build(), 10);
//获取查询到的结果集的总数, 打印
System.out.println("=======count=======" + topDocs.totalHits);
//8. 获取结果集
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
//9. 遍历结果集
if (scoreDocs != null) {
for (ScoreDoc scoreDoc : scoreDocs) {
//获取查询到的文档唯一标识, 文档id, 这个id是lucene在创建文档的时候自动分配的
int docID = scoreDoc.doc;
//通过文档id, 读取文档
Document doc = indexSearcher.doc(docID);
System.out.println("==================================================");
//通过域名, 从文档中获取域值
System.out.println("===id==" + doc.get("id"));
System.out.println("===name==" + doc.get("name"));
System.out.println("===price==" + doc.get("price"));
System.out.println("===image==" + doc.get("image"));
System.out.println("===brandName==" + doc.get("brandName"));
System.out.println("===categoryName==" + doc.get("categoryName"));
}
}
//10. 关闭流
}
/**
* 测试相关度排序
* @throws Exception
*/
@Test
public void testIndexSearch2() throws Exception {
//1. 创建分词器(对搜索的关键词进行分词使用)
//注意: 分词器要和创建索引的时候使用的分词器一模一样
Analyzer analyzer = new IKAnalyzer();
//需求: 不管是名称域还是品牌域或者是分类域有关于手机关键字的查询出来
//查询的多个域名
String[] fields = {"name", "categoryName", "brandName"};
//设置影响排序的权重, 这里设置域的权重
Map<String, Float> boots = new HashMap<>();
boots.put("categoryName", 10000000000f);
//从多个域查询对象
MultiFieldQueryParser multiFieldQueryParser = new MultiFieldQueryParser(fields, analyzer, boots);
//设置查询的关键词
Query query = multiFieldQueryParser.parse("手机");
//4. 创建Directory目录对象, 指定索引库的位置
Directory dir = FSDirectory.open(Paths.get("E:\\dir"));
//5. 创建输入流对象
IndexReader indexReader = DirectoryReader.open(dir);
//6. 创建搜索对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
//7. 搜索, 并返回结果
//第二个参数: 是返回多少条数据用于展示, 分页使用
TopDocs topDocs = indexSearcher.search(query, 10);
//获取查询到的结果集的总数, 打印
System.out.println("=======count=======" + topDocs.totalHits);
//8. 获取结果集
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
//9. 遍历结果集
if (scoreDocs != null) {
for (ScoreDoc scoreDoc : scoreDocs) {
//获取查询到的文档唯一标识, 文档id, 这个id是lucene在创建文档的时候自动分配的
int docID = scoreDoc.doc;
//通过文档id, 读取文档
Document doc = indexSearcher.doc(docID);
System.out.println("==================================================");
//通过域名, 从文档中获取域值
System.out.println("===id==" + doc.get("id"));
System.out.println("===name==" + doc.get("name"));
System.out.println("===price==" + doc.get("price"));
System.out.println("===image==" + doc.get("image"));
System.out.println("===brandName==" + doc.get("brandName"));
System.out.println("===categoryName==" + doc.get("categoryName"));
}
}
//10. 关闭流
}
}
运行结果如下: